Accessibility Policy
Skip to content
Oracle
Data Integration
Search
Exit Search Field
Clear Search Field
Menu
Blogs Home
RSS
Data Integration
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
Data Integration
Real-Time Embedding with Oracle GoldenGate: A Step-by-Step Guide
Alex Porcescu
5 minute read
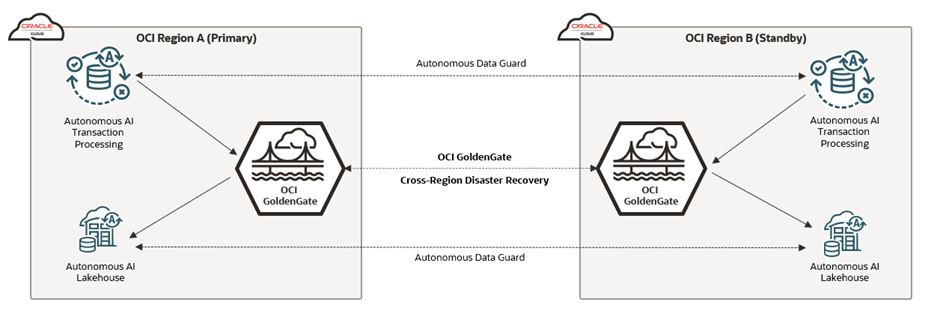
Keep data moving: Cross‑region disaster recovery for OCI GoldenGate
Julien TESTUT
4 minute read
ZeroETL everywhere: OCI GoldenGate ZeroETL Mirror pipelines now ...
Julien TESTUT
3 minute read
How to obtain the latest Oracle GoldenGate Microservices Architecture ...
Nick Wagner
3 minute read
Using Parameters in Oracle Cloud Infrastructure (OCI) Data Integration
Aditya Duvuri
10 minute read
Improve productivity with Oracle Cloud Infrastructure Data ...
Aditya Duvuri
5 minute read
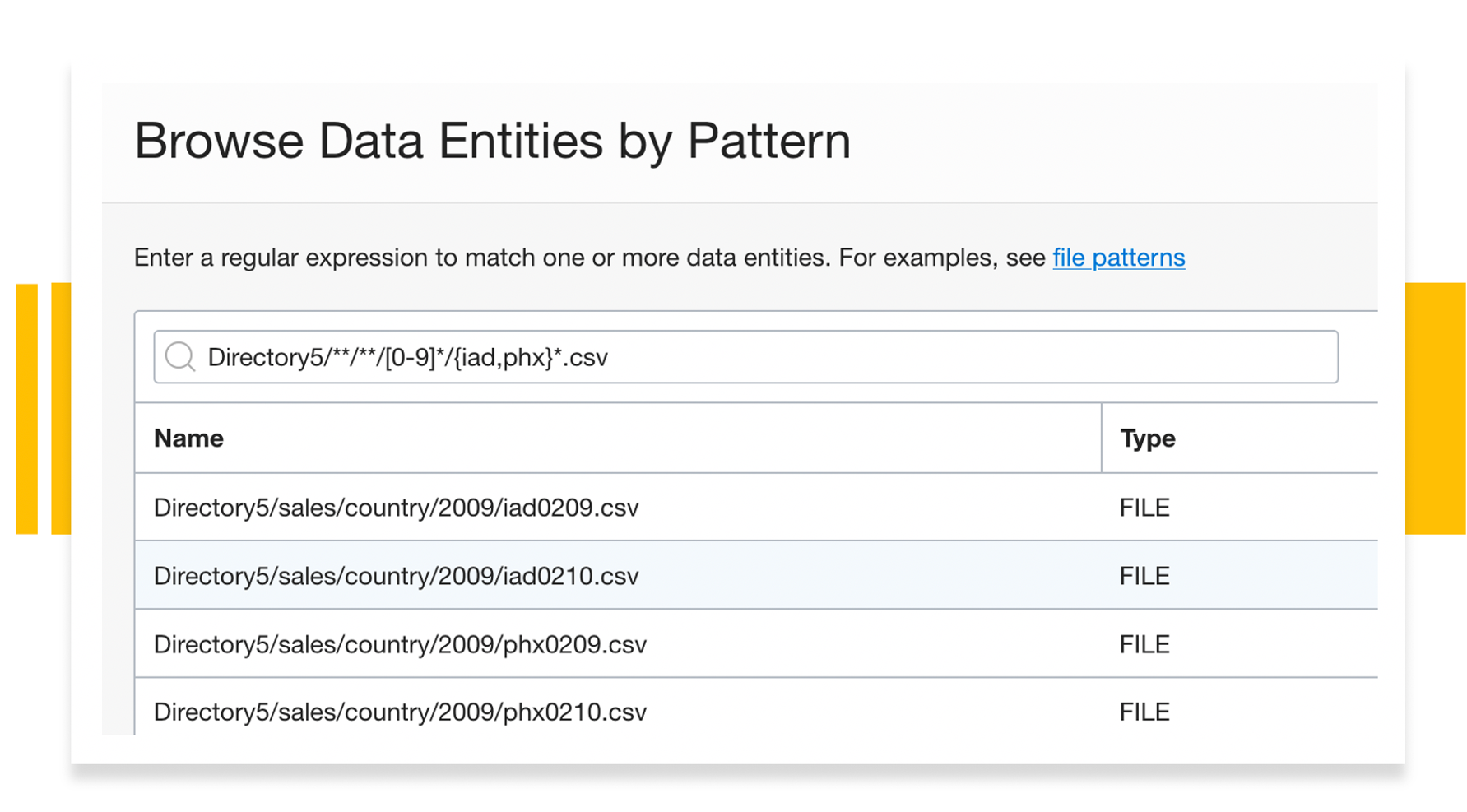
File patterns in Oracle Cloud Infrastructure (OCI) Data Integration
Aditya Duvuri
3 minute read
Introduction to CLI, API for Oracle Cloud Infrastructure (OCI) Data ...
Aditya Duvuri
8 minute read
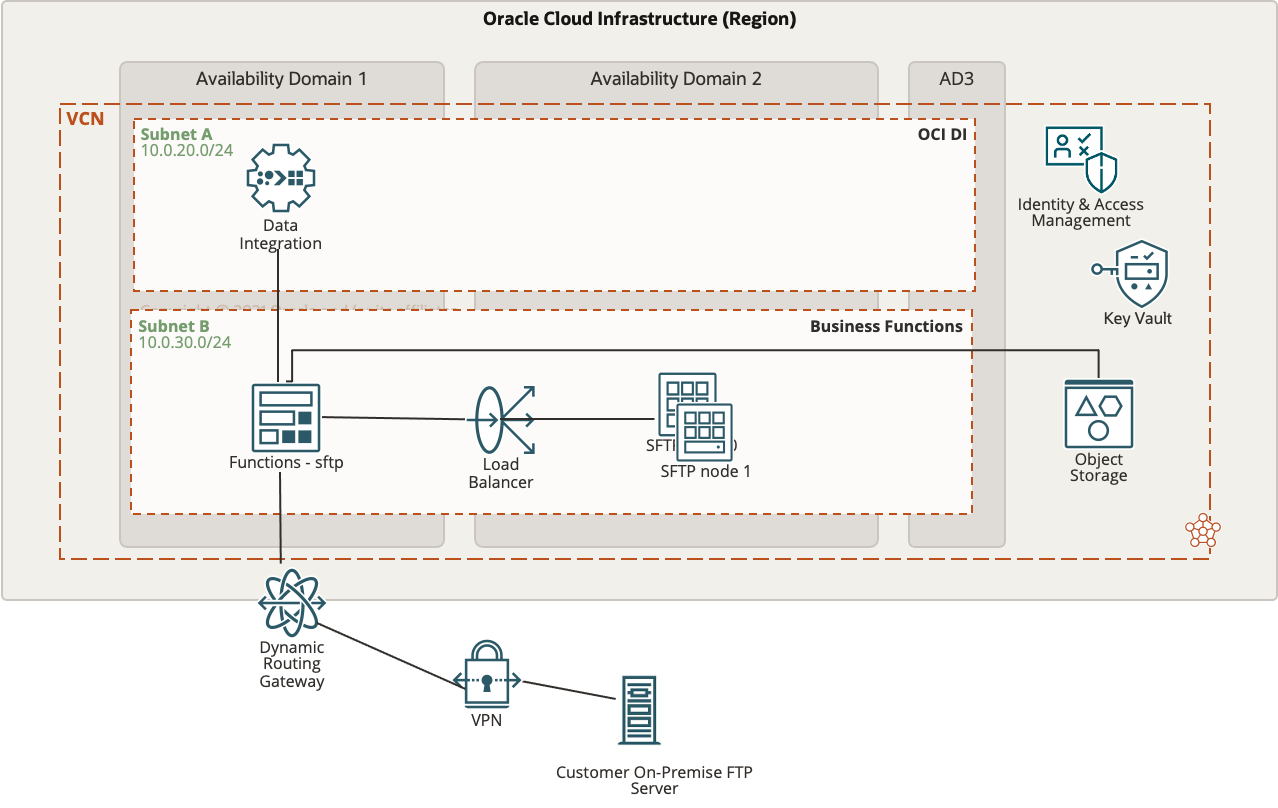
Data Integration and sFTP
David Allan
10 minute read
Workspace in Oracle Cloud Infrastructure (OCI) Data Integration
Aditya Duvuri
5 minute read
Fast-track data discovery with new release of Oracle Cloud ...
Sandrine Riley
5 minute read
Applications in Oracle Cloud Infrastructure (OCI) Data Integration
Aditya Duvuri
6 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2025 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers