Accessibility Policy
Skip to content
Oracle
Data Integration
Search
Exit Search Field
Clear Search Field
Menu
Blogs Home
RSS
Data Integration
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
Data Integration
Announcing OCI GoldenGate on Oracle Database@Google Cloud
Nick Wagner
4 minute read
Introducing the Oracle GoldenGate 26ai Advanced Configuration Course
Alex Lima
3 minute read
Trail File Routing Without Opening the Door: Target‑Initiated Paths
Volker Kuhr
6 minute read
Real-time Data Replication to Google BigLake Metastore with Oracle ...
Deniz Sendil
9 minute read
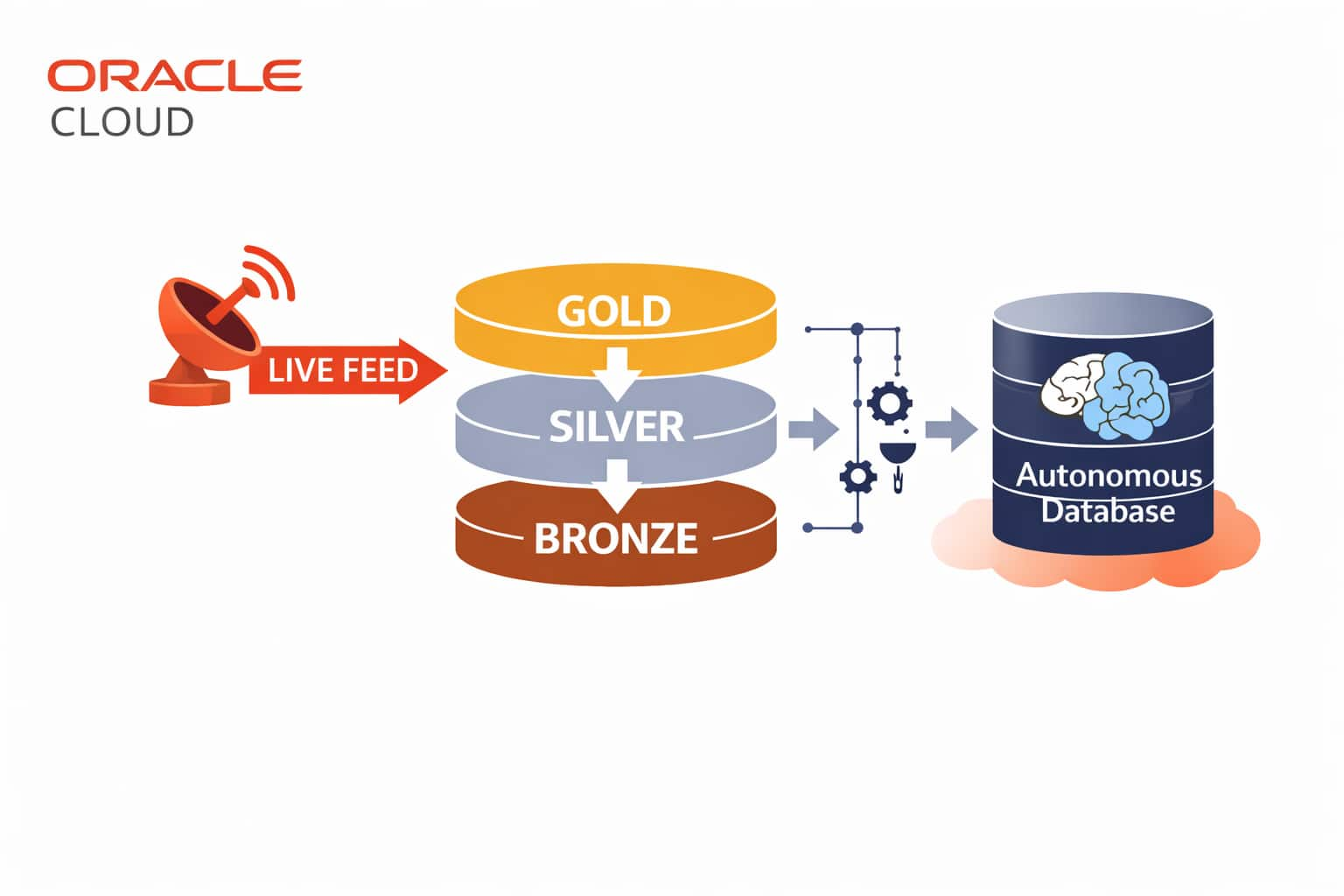
Designing an Event-Driven Medallion Architecture Using Live Feed and ...
GuruDixit Chepuri
12 minute read
Oracle named a Leader in 2025 Forrester Wave™: Data Fabric Platforms
Donna Cooksey
2 minute read
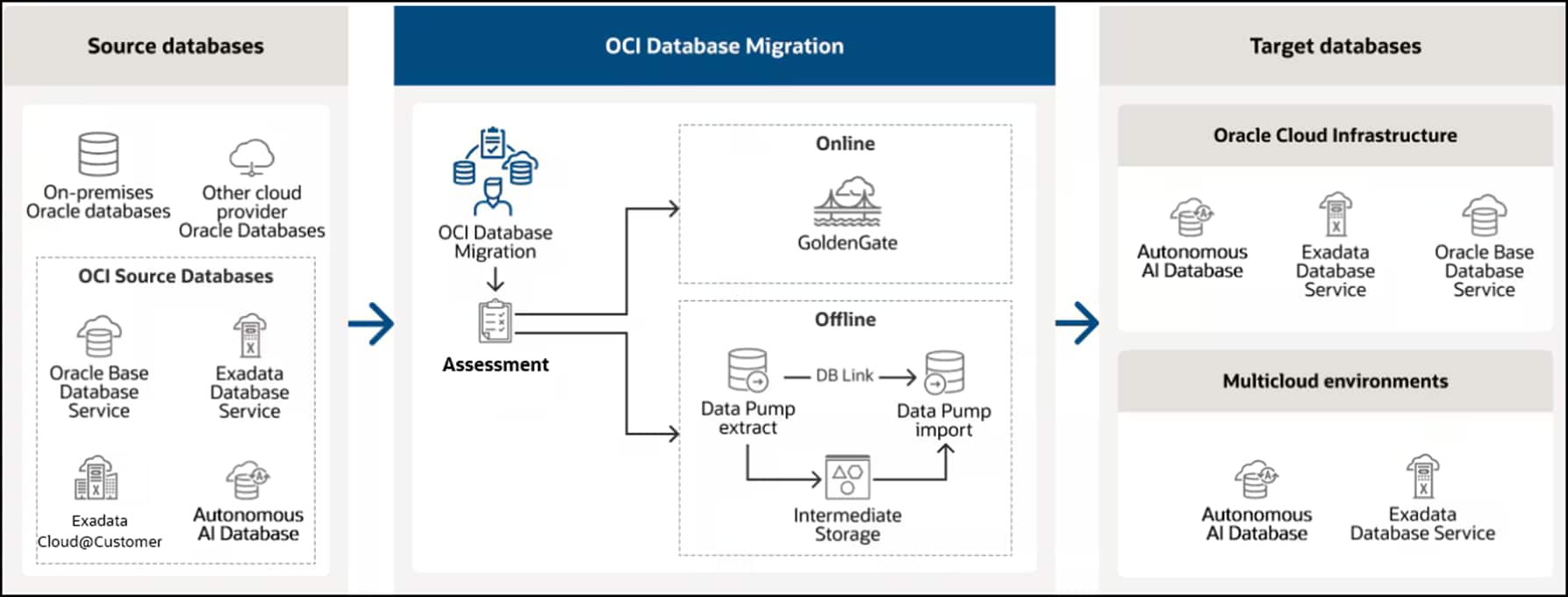
Announcing DMS Assessment: Simplifying Your Database Migration Journey
Jorge Martinez
2 minute read
Announcing Oracle GoldenGate Veridata 26c: Advancing Continuous Data ...
Alex Lima
5 minute read
Oracle named a Leader in 2025 Gartner® Magic Quadrant™ for Data ...
Donna Cooksey
3 minute read
Revolutionizing Data Replication: AI-Powered Vector Embeddings in ...
Volker Kuhr
6 minute read
Announcing Oracle GoldenGate 26ai smarter automation, broader ...
Alex Lima
7 minute read
GoldenGate Best Practices: A Blueprint for Stability, Integrity and ...
Michael Papio
8 minute read
View more
Receive the latest blog updates
Subscribe to Oracle Connect email updates
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers