Oracle Database’s JSON capabilities allows native JSON support with the JSON data type which also supports relational database features, including transactions, indexing, declarative querying, and views. Oracle Sharding is a database technology that allows data to scale to massive data and transactions volume, provide fault isolation, and supporting data sovereignty.
Often JSON applications will need to distribute their data across multiple instances or shards, either for reasons of scalability or of geographical distribution. In this two part blog we will look at different options on how to configure JSON in a sharded environment, including how to choose a shard key, how to distribute JSON data and all with code snippets in Java and Python which show how data is queried and inserted.
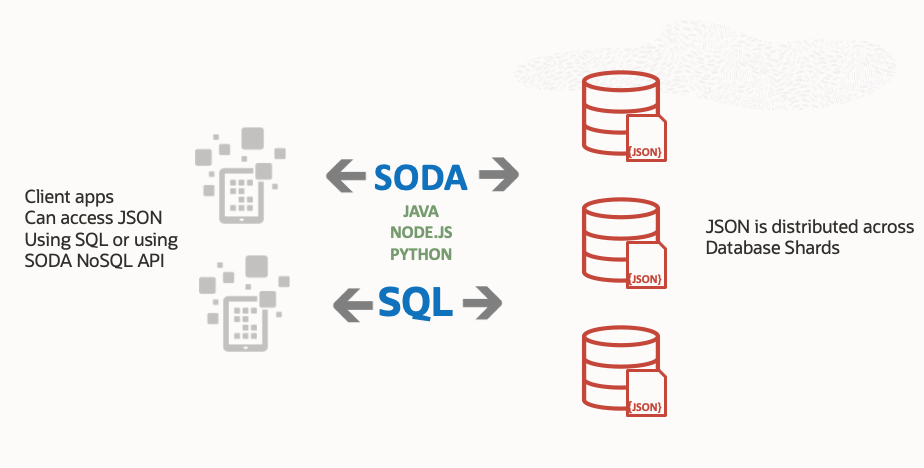
Included are examples in both Java and Python which show how data is queried and inserted from an application.
This walk-through was developed on Oracle Database 21c which introduced the JSON data type.
Part 1: Sharding Oracle JSON and how to choose sharding keys for data distribution
Part 2: Using Oracle SODA for simplified JSON data queries and retrieval
Introducing Oracle SODA
In Part 1: Sharding Oracle JSON and how to choose sharding keys for data distribution we walked through how to create sharded JSON tables and then how to construct queries and updates using Java and Python applications.
In Part 2, we will walk through how to configure and use Simple Oracle Document Access (SODA) to be able to access and search for JSON data without the use of SQL.
Planning SODA with Sharding
As in Part 1, there are a couple options for how to distribute your JSON data. We will run through the same two usecases that we ran through in Part 1. With SODA, however there are some subtle differences in how we configure our data and how we access it.
Simple Oracle Document Access (SODA) is a set of NoSQL-style APIs that let you create and store collections of documents (in particular JSON) in Oracle Database, retrieve them, and query them, without needing to know Structured Query Language (SQL) or how the documents are stored in the database.
Usecase 1: Independent Shard Keys
As in Part 1, we create our sharded table to hold our data. This will form the basis of our SODA Collection:
/* Create the sharded table */ CREATE SHARDED TABLE CUSTOMERS ( "ID" VARCHAR2(255) NOT NULL, "CREATED_ON" timestamp default sys_extract_utc(SYSTIMESTAMP) NOT NULL, "LAST_MODIFIED" timestamp default sys_extract_utc(SYSTIMESTAMP) NOT NULL, "VERSION" varchar2(255) NOT NULL, "CUSTPROFILE" JSON, PRIMARY KEY (ID) ) TABLESPACE SET TSP_SET_1 PARTITION BY CONSISTENT HASH (ID) PARTITIONS AUTO;
The difference with Part 1 is that we have added a few columns which we can later use with SODA. SODA works with Collections which have an underlying table. Now that we have created our table, we can create a mapped SODA collection on top of this table. Continuing as the Sharding user named APP_SCHEMA:
GRANT SODA_APP TO PROCEDURE APP_SCHEMA.COLLECTION_PROC_CUSTOMERS;
create or replace procedure COLLECTION_PROC_CUSTOMERS AS
METADATA varchar2(8000);
COL SODA_COLLECTION_T;
begin METADATA := '{"tableName":"CUSTOMERS",
"keyColumn":{"name":"ID","assignmentMethod" : "CLIENT"},
"contentColumn":{"name":"CUSTPROFILE","sqlType":"JSON"},
"versionColumn":{"name":"VERSION","method":"UUID"},
"lastModifiedColumn":{"name":"LAST_MODIFIED"},
"creationTimeColumn":{"name":"CREATED_ON"},
"readOnly":false}';
-- Create a collection using "map" mode, based on
-- the table you've created above and specified in
-- the custom metadata under "tableName" field.
COL := dbms_soda.create_collection('CUSTOMERS',METADATA,DBMS_SODA.CREATE_MODE_MAP);
end ;
/
exec sys.exec_shard_plsql('app_schema.collection_proc_customers()',4+1);
The code above creates a mapping and then creates a SODA Collection that is visible on all shards.
Note that the assignmentMethod for the ID column is specified as CLIENT. That means that we will be supplying the value for this column instead of letting SODA auto-generate it.
Now that we have created the SODA Collection we can begin working with it.
Single-Shard Queries
The Java code below works similarly to that of Example 1 in Part 1. We are connecting to a specific Shard and inserting a JSON Document. However, in the example below we assume we have already created and configured a Pool DataSource
Example 1: Inserts with Independent Shard Keys (Java)
// Connection Pool has been created
// But we cannot get the connection itself until we have the Shard key
// which is part of the SQL
//We first set the sharding key or document id explicitly as a UUID
UUID uuid=UUID.randomUUID{};
String shardingKeyVal=uuid.toString{};
// Now we build the connection using this shard key
OracleShardingKey sdkey = pds.createShardingKeyBuilder().subkey(shardingKeyVal, OracleType.VARCHAR2).build();
System.out.println("Creating Connection...");
Connection conn = pds.createConnectionBuilder().shardingKey(sdkey).build();
// Enable the SODA Shared Metadata cache
Properties props = new Properties();
props.put("oracle.soda.sharedMetadataCache", "true");
OracleRDBMSClient cl = new OracleRDBMSClient(props);
// Get a DB Connection for use in SODA
OracleDatabase db = cl.getDatabase(conn);
// Print all the Collections in this DB
List<String> names = db.admin().getCollectionNames();
for (String name : names)
System.out.println ("Collection name: " + name);
// Open up the CUSTOMERS Collection
OracleCollection col = db.openCollection("CUSTOMERS");
//For a collection configured with client-assigned document keys,
//you must provide the key for the input document. Build a document with JSON.
OracleDocument cKeyDoc = db.createDocumentFromString(shardingKeyVal, "{\"name\": \"Matilda\", \"State\": \"CA\", \"ZIP\":\"94065\"}");
// Insert the document above
//If the key already identifies a document in the collection
//then this will replace the existing doc.
OracleDocument savedDoc = col.saveAndGet(cKeyDoc);
// Get the document back assuming we only know the key
// We are still connected to the same shard
OracleDocument doc = col.find().key(shardingKeyVal).getOne();
String content = doc.getContentAsString();
System.out.println("Retrieved content is: " + content);
// We are done, so close the connection to the shard
conn.close();
// At this point we could open up a new shard connection using a different sharding key
The example shows how to use SODA to browse Collections in the Database, how to open up a SODA Collection and then how to create a new Document and, finally, how to search for and retrieve Documents. We did all this using SODA and not SQL!
It should be emphasized that we could only retrieve the document because we were already connected to the same shard where we had inserted it. For general searches, across shards, we need to connect to the catalog database. We cover this in our next example.
Multi-Shard Queries
To search for a Document across all shards, we connect to the Shard Catalog. In the previous example we showed how to retrieve a document when we know the shard key. But what if we want to perform a general query on a JSON field. Below, we show how this is done with SODA explicitly, starting with the database connection this time. So first, connect to the shard catalog service. We can connect to one of the GSMs or shard directors:
Example 2: Queries across Shards (Java)
// This connection is to the shard director using the catalog service name.
final String DB_URL="jdbc:oracle:thin:@dbcat?TNS_ADMIN=/home/opc/dbhome/";
// Update the Database Username and Password to the Shard User
final String DB_USER = "app_schema";
String DB_PASSWORD = "<user_password>" ;
// Get the PoolDataSource for UCP
PoolDataSource pds = PoolDataSourceFactory.getPoolDataSource();
// Set the connection factory first before all other properties
pds.setConnectionFactoryClassName(OracleDataSource.class.getName());
pds.setURL(DB_URL);
pds.setUser(DB_USER);
pds.setPassword(DB_PASSWORD);
pds.setConnectionPoolName("JDBC_UCP_POOL");
// Now we get a direct connection to the shard catalog
System.out.println("Creating Connection...");
Connection conn = pds.getConnection();
We have our connection to the Catalog. Now we configure and initialize the SODA connection.
// Enable the SODA Shared Metadata cache
Properties props = new Properties();
props.put("oracle.soda.sharedMetadataCache", "true");
OracleRDBMSClient cl = new OracleRDBMSClient(props);
// Get a DB Connection
OracleDatabase db = cl.getDatabase(conn);
The first thing we want to do is open up the JSON Collection that we want to work with:
// Open up the CUSTOMERS Collection
OracleCollection col = db.openCollection("CUSTOMERS");
Now, we initiate and execute our query. This comes in the form of a filter specification.
// Do a search across ALL Shards. In this case all users named Matilda
// Setup the specification and open a cursor
OracleDocument filterSpec = db.createDocumentFromString("{ \"name\" : \"Matilda\"}");
OracleCursor c = col.find().filter(filterSpec).getCursor();
// Print the results of the query
while (c.hasNext()) {
OracleDocument resultDoc = c.next();
// Print the document key and document content
System.out.println ("Document key: " + resultDoc.getKey() + "\n" +
" document content: " + resultDoc.getContentAsString());
}
// Close the cursor
c.close();
At this point, we could initiate another multi-shard query if desired. Or we can look through our results and decide to initiate a connection to a specific shard. If we are done, then we just close the connection.
// We are done, so close the connection conn.close();
Usecase 2: Sharding on JSON Fields
As in Part 1, we now look at how we would configure our database to shard using a JSON field and also use SODA to insert, update and read that data.
/* Create the sharded table */ CREATE SHARDED TABLE CUSTOMERS ( "ID" VARCHAR2(255) NOT NULL, "CREATED_ON" timestamp default sys_extract_utc(SYSTIMESTAMP) NOT NULL, "LAST_MODIFIED" timestamp default sys_extract_utc(SYSTIMESTAMP) NOT NULL, "VERSION" varchar2(255) NOT NULL, "ZIP" VARCHAR2(60) NOT NULL, "CUSTPROFILE" JSON, PRIMARY KEY (ID,ZIP)) TABLESPACE SET TSP_SET_1 PARTITION BY CONSISTENT HASH (ZIP) PARTITIONS AUTO;
Again, we add the columns for SODA and our extra ZIP column, which will be our sharding column. As before, the Primary key must be unique but it also must include the (non-unique) sharding key so we include the ID. Now, we proceed with the mapping:
GRANT SODA_APP TO PROCEDURE APP_SCHEMA.COLLECTION_PROC_CUSTOMERS;
create or replace procedure COLLECTION_PROC_CUSTOMERS AS
METADATA varchar2(8000);
COL SODA_COLLECTION_T;
begin
METADATA := '{"tableName":"CUSTOMERS",
"keyColumn":{"name":"ID"},
"contentColumn":{"name":"CUSTPROFILE","sqlType":"JSON"},
"versionColumn":{"name":"VERSION","method":"UUID"},
"lastModifiedColumn":{"name":"LAST_MODIFIED"},
"creationTimeColumn":{"name":"CREATED_ON"},
"readOnly":false}';
-- Create a collection using "map" mode, based on
-- the table you've created above and specified in
-- the custom metadata under "tableName" field.
COL := dbms_soda.create_collection('CUSTOMERS',METADATA,DBMS_SODA.CREATE_MODE_MAP);
end ;
/
exec sys.exec_shard_plsql('app_schema.collection_proc_customers()',4+1);
Note that the keyColumn is ID, the key used by SODA to insert and retrieve collections.
There is no reference to the ZIP column because it is not used by SODA in the mapping.
We now have a new SODA Collection.
As in Part 1, we have to also define how our ZIP column relates to the JSON data. As before, we run a database trigger to enforce this relationship. Consult Appendix B in Part 1 for other options aside from a database trigger:
alter session enable shard ddl
create or replace procedure COLLECTION_BF_ZIP_CUSTOMERS AS
begin
EXECUTE IMMEDIATE 'alter session enable shard operations';
EXECUTE IMMEDIATE q'%
Create or Replace TRIGGER CUST_BF_TRIG
BEFORE INSERT or UPDATE on CUSTOMERS
FOR EACH ROW
begin
:new.ZIP := JSON_VALUE(:NEW.CUSTPROFILE, '$.ZIP' error on error error on empty);
end;
%';
end;
/
exec sys.exec_shard_plsql('app_schema.collection_bf_zip_customers()',4+1+2);
In the example above, ZIP is assumed to be a top-level field in the JSON document. If the value is in a nested field, for example under an ADDRESS field, you must include the field hierarchy, for example ‘$.ADDRESS.ZIP’.
Also, the returned JSON_VALUE must match the type of the JSON field, in this case it defaults to VARCHAR. If we wanted to have ZIP be a NUMBER for example, then the statement above would have a RETURNING NUMBER clause in addition to the error clause.
The name of the procedure and the name of the trigger are chosen here to provide clarity. There is no requirement on the names of these objects.
Single-Shard Queries
Now, we show how we would perform direct shard operations, when the sharding is by JSON field. And, of course, we will use SODA to accomplish this.
We start by assuming we already have a pooled connection to the shard director (GSM):
Example 3: Inserts with JSON Shard Keys (Java)
// We cannot get the connection until we have the Shard key which is part of the SQL
//We first set the sharding key which in our case is the value of the ZIP code field
String shardingKeyVal="94065";
// Now we build the connection using this shard key
OracleShardingKey sdkey = pds.createShardingKeyBuilder().subkey(shardingKeyVal, OracleType.VARCHAR2).build();
System.out.println("Creating Connection...");
Connection conn = pds.createConnectionBuilder().shardingKey(sdkey).build();
// Enable the SODA Shared Metadata cache
Properties props = new Properties();
props.put("oracle.soda.sharedMetadataCache", "true");
OracleRDBMSClient cl = new OracleRDBMSClient(props);
// Get a DB Connection
OracleDatabase db = cl.getDatabase(conn);
// Open up the CUSTOMERS Collection
OracleCollection col = db.openCollection("CUSTOMERS");
//We do not provide an SODA ID column.
//This is provided by SODA when the document is created
// Note that the ZIP field MUST match what we have specified already as the key
OracleDocument cDoc = db.createDocumentFromString("{\"name\": \"Matilda\", \"State\": \"CA\", \"ZIP\":\"94065\"}");
// Insert the document above
OracleDocument insertedDoc = col.insertAndGet(cDoc);
// Get the document key
String dockey = insertedDoc.getKey();
// Get the document back by key
// We are still connected to the same shard
OracleDocument doc = col.find().key(dockey).getOne();
String content = doc.getContentAsString();
System.out.println("Retrieved content is: " + content);
// We are done, so close the connection to the shard
conn.close();
// At this point we could open up a new shard connection using a different sharding key
The main thing to note in the above example, is that our shard key is now ZIP code and so we have to know that value in advance of obtaining our collection. Above we have just set it explicitly but it could also be retrieved from the JSON object for example that is to be inserted.
We also no longer provide the ID column when performing the Insert. This is because we are letting SODA do this for us. This is not something we could allow SODA to do earlier because we were using the ID to get our database connection in the first place so we had to have it created BEFORE we performed the insert. Now, the ID is no longer our shard key.
Multi-Shard Queries
Catalog queries work the same as they do in Example 2. The reason is that connecting to the Catalog and performing Catalog operations does not require a shard key. And so, this is independent of any shard key choices we may have made.
Conclusion
In these last two articles we have shown the range of choices available for combining the native JSON support of Oracle databases with the horizontal scaling features of Oracle Sharding. Depending on the application requirements, the data can be sharded by a key external to JSON or by a field within the JSON. In addition, JSON can be accessed via SQL or through a Simple Oracle Document Access (SODA) interface.
Appendix: Python Examples
We conclude by posting Python equivalents of the Java code snippets in this post. The SQL is the same in creating the database objects but the equivalent application code is below:
Independent Shard Keys
Example 4: Inserts with Independent Shard keys (Python)
# import the cx_Oracle module for Python
import cx_Oracle
# Create a connection pool that will be used for connecting to all shards
# The components of the dsn are hostname (shard director),
# port (usually 1522), global service (created with GDSCTL)
# The pool is then created and SODA metadata caching is enabled.
dsn=cx_Oracle.makedsn("shard_director_host",1522,service_name="service_name")
pool=cx_Oracle.SessionPool("app_schema","password",dsn, soda_metadata_cache=True)
# Connect to a specific shard by using the sharding key, which in this example is
# set explicitly as a UUID
shrdkey=uuid.uuid4();
connection=pool.acquire(shardingkey=[shrdkey]);
# Set autocommit and open the CUSTOMERS collection
connection.autocommit = True
soda = connection.getSodaDatabase()
collection = soda.openCollection("CUSTOMERS")
# Insert a document
# Because you are specifying the shard key, you must pass that in
# with the document
content = {'name': 'Matilda', 'State': 'CA', 'ZIP':'94065'}
idcontent=soda.createDocument(content, key=sodaid)
doc = collection.insertOneAndGet(idcontent)
# Fetch the document back by key
doc = collection.find().key(sodaid).getOne()
content = doc.getContent()
print('Retrieved SODA document dictionary is:')
print(content)
# After you have finished, release this connection back into the pool
pool.release(connection)
# If you want to add or work with more customers, start with another connection
# For example: connection=pool.acquire(shardingkey=["123"]) and so on.
#When you are completely finished working with customers you can shut down the pool
pool.close()
Example 5: Queries across Shards (Python)
# import the cx_Oracle module for Python
import cx_Oracle
# Create an unpooled connection to the shard catalog
# In general, pooled connections should be used for all connections.
# This is shown here only as an example.
# The connect string connects to the shard director,
# but uses the catalog service, e.g. GD$catalog.oradbcloud
connection = cx_Oracle.connect("app_schema","password","db_connect_string")
# Open the CUSTOMERS collection
connection.autocommit = True
soda = connection.getSodaDatabase()
collection = soda.openCollection("CUSTOMERS")
# Now query the collection
# It is important to note that this is a query across ALL shards
# In other words, you will get ALL users whose names start with M
documents = collection.find().filter({'name': {'$like': 'M%'}}).getDocuments()
for d in documents:
content = d.getContent()
print(content["name"])
# Close the connection
connection.close()
Sharding JSON Fields
Example 6: Inserts with JSON Shard Keys (Python)
# import the cx_Oracle module for Python
import cx_Oracle
# Create a connection pool that will be used for connecting to all shards
# The components of the dsn are hostname (shard director),
# port (usually 1522), global service (created using GDSCTL)
# We also enable SODA metadata caching
dsn=cx_Oracle.makedsn("shard_director_host",1522,service_name="service_name")
pool=cx_Oracle.SessionPool("app_schema","password",dsn,soda_metadata_cache=True)
# Connect to a specific shard by using the shard key, a ZIP code. which in this
# example is set explicitly as '94065', but this might be passed in or part of a loop
# You must know beforehand whether you are creating or working with a document
# with a specific ZIP code value.
connection=pool.acquire(shardingkey=["94065"])
# set autocommit and open the CUSTOMERS collection
connection.autocommit = True
soda = connection.getSodaDatabase()
collection = soda.openCollection("CUSTOMERS")
# Insert a document
# A system generated SODA key is created by default.
content = {'name': 'Matilda', 'STATE': 'CA', 'ZIP': '94065'}
doc = collection.insertOneAndGet(content)
# The SODA key can now be used to work with this document directly
# We can retrieve it immediately
key = doc.key
print('The key of the new SODA document is: ', key)
# Fetch the document back by this same SODA key.
# This only works because we are still connected to the same shard
doc = collection.find().key(key).getOne()
content = doc.getContent()
print('Retrieved SODA document dictionary is:')
print(content)
# Next, add another customer. We are in the shard containing 94065, so we can add a customer with the same ZIP code '94065'
content = {'name': 'Mildred', 'STATE': 'CA', 'ZIP: '94065'}
doc = collection.insertOneAndGet(content)
# Now do a query.
# It is important to note that this query is ONLY executed within this one shard,
# the shard which contains the part of the sharded table with 94065 ZIP codes.
# In other words, the actual query has the additional bound of customers whose names start with 'M' in 94065
# and any other ZIPs stored on this shard. This is unlikely to be a useful query for system-managed sharding.
documents = collection.find().filter({'name': {'$like': 'M%'}}).getDocuments()
for d in documents:
content = d.getContent()
print(content["name"])
# After you have finished, release this connection back into the pool
pool.release(connection)
# If you want to add or work with more customers with a different
# shard key start with another connection
# For example: connection=pool.acquire(shardingkey=["10012"]) and so on.
# When you are completely finished working with customers, shut down the pool.
pool.close()
Further References/Reading:
Oracle Sharding:
https://docs.oracle.com/en/database/oracle/oracle-database/21/shard/index.html
Oracle JSON Developer’s Guide:
https://docs.oracle.com/en/database/oracle/oracle-database/21/adjsn/index.html
Simple Oracle Document Access:
https://docs.oracle.com/en/database/oracle/simple-oracle-document-access/index.html
Oracle JDBC Developer’s Guide and Reference:
https://docs.oracle.com/en/database/oracle/oracle-database/21/jjdbc/index.html

