Part 1: Sharding Oracle JSON and how to choose sharding keys for data distribution
Oracle’s JSON capabilities allow native JSON support with the JSON data type which also supports relational database features, including transactions, indexing, declarative querying, and views. Often JSON applications need to distribute their data across multiple instances or shards, either for scalability or geographical distribution.
Oracle Sharding is a database technology that allows data to scale to massive data and transactions volume, provides fault isolation, and supports data sovereignty.
In this two part blog we look at different options to configure JSON in a sharded environment, including how to choose a sharding key and how to distribute JSON data.
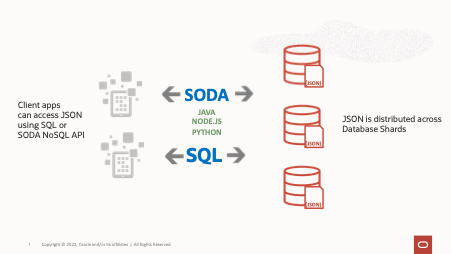
Included are examples in both Java and Python which show how data is queried and inserted from an application.
This walk through was developed on Oracle 21c, which first supports the JSON data type.
Introduction
Motivations for sharding JSON as with other types of data are:
- For scaling, scaling horizontally provides support for large volumes of transactions as well as large volumes of data.
- For availability reasons, application data spread across multiple instances limits the impact of an outage of any one instance or node.
- For data sovereignty, you can provide geographical isolation to a subset of data while ensuring it is part of the same database.
Planning JSON and Sharding
There are many different options when choosing how to shard JSON. We will cover two common use cases here.
The first use case is simply the ability to distribute data across multiple instances. Sharding requires a sharding key, but the sharding key does not necessarily need to be a field within the JSON document. In the first example we show how you can use an external key to distribute and query and access data across shards.
In the second example we use a JSON field as a sharding key with a non-unique sharding key. This allows us a bit more control over data distribution because documents with the same sharding key are kept together in the same shard.
In both of these examples we use the system-managed sharding method. This method defers the placement of data to a system provided hash function.
If you need even greater control, you could opt for the user-managed sharding or composite sharding method. Those options are not described in this blog series, but more information and examples are available in the documentation referenced at the end of this post.
Use Case 1: Independent Sharding Keys
After setting up a system-managed sharding environment, we create an all shard user. When the environment is available we can begin to create the necessary schemas.
The simplest schema is a table which holds both the sharding key and the JSON data. Connecting to the shard catalog database as the sharding user, we can create this table as follows:
/* Create the sharded table */
CREATE SHARDED TABLE CUSTOMERS
(
"ID" VARCHAR2(255) NOT NULL,
"CUSTPROFILE" JSON,
PRIMARY KEY (ID)
)
TABLESPACE SET TSP_SET_1
PARTITION BY CONSISTENT HASH (ID) PARTITIONS AUTO;
Our sharding key is the column ID. Note that the ID we are using for each document is unique and so we are setting this here as the primary key. A sharding key, however, does not need to be unique. But if it is not, then it needs to be part of the primary key. We will revisit this in more detail in Part 2 when we discuss SODA. For now, we will use a unique sharding key.
We have several options for loading data into the new table. We can of course seed the table with externally loaded data. We can also insert data with an application.
In the following code samples we show how to
1) Insert and retrieve data from our JSON table by initiating a direct connection to the shard where the data resides, and then
2) Connect to the shard catalog to issue a query across all data
Single-Shard Queries
For single-shard queries or operations, the recommended way of accessing data is Direct Query Routing.
Oracle Sharding allows you to connect directly to a shard to process queries by providing a sharding key along with the database connection request. In the example below, we set up a UCP connection pool first.
In Java, we would have:
Example 1: Inserts with Independent Sharding Keys (Java)
// Get the PoolDataSource for UCP
PoolDataSource pds = PoolDataSourceFactory.getPoolDataSource();
// Set the connection factory and other properties. The connection is to the Global
// Service Manager (GSM) instance
pds.setConnectionFactoryClassName(OracleDataSource.class.getName());
pds.setURL(DB_URL);
pds.setUser(DB_USER);
pds.setPassword(DB_PASSWORD);
pds.setConnectionPoolName(“JDBC_UCP_POOL”);
// We cannot get the connection until we have the Shard key which is part of the SQL
// We first set the sharding key or document id. We can set it explicitly
// for example shardingKeyVal=’10’; but if we are
// just using it for hashing we can also set it as a UUID
UUID uuid=UUID.randomUUID{};
String shardingKeyVal=uuid.toString{};
// Now we build the connection using this shard key
OracleShardingKey sdkey = pds.createShardingKeyBuilder().subkey(shardingKeyVal, OracleType.VARCHAR2).build();
System.out.println(“Creating Connection…”);
Connection conn = pds.createConnectionBuilder().shardingKey(sdkey).build();
Now we have a connection to a specific shard.
From here we proceed with our operations, whether it be insert, or update, or select.
PreparedStatement pstmt = conn.prepareStatement(“INSERT INTO CUSTOMERS VALUES (:1,:2)”);
String str = “{\”name\”:\”Jean\”, \”job\”: \”Intern\”, \”salary\”:20000}”;
Pstmt.setString(1, shardingKeyVal);
pstmt.setObject(2, str, OracleType.JSON);
pstmt.execute();
system.out.println(“Document inserted.”);
Note that to insert another document, we do have to set a new UUID and then create a new connection so that the document is inserted into the correct shard.
In Oracle 21c, we have a Sharding Data Source which allows the connection to use the sharding key in the query without the need to specify it explicitly. The previous exercise, however, is useful, however, both because the Sharding Data Source is only supported in Oracle 21c and is only supported for JDBC UCP. In Part 2, where we discuss SODA access, we will also return to this topic.
Multi-Shard Queries
Direct shard connections are great for when we want to work with individual documents, but what if we want to search across all documents?
For this, we can run queries against the shard catalog database, which automatically farms out the query across the shards.
We create a connection to the shard catalog and then run our query.
For example, again using UCP:
Example 2: Queries Across Shards (Java)
// Get the PoolDataSource for UCP
PoolDataSource pds = PoolDataSourceFactory.getPoolDataSource();
// Set the connection factory first before all other properties
// Our connection here is to the Shard catalog
pds.setConnectionFactoryClassName(OracleDataSource.class.getName());
pds.setURL(DB_URL);
pds.setUser(DB_USER);
pds.setPassword(DB_PASSWORD);
pds.setConnectionPoolName(“JDBC_UCP_POOL”);
// Now we get a direct connection to the shard catalog
System.out.println(“Initiating UCP and Creating Connection…”);
Connection conn = pds.getConnection();
And then we issue our query as usual:
PreparedStatement stmt = conn.prepareStatement(
“SELECT c.custprofile FROM CUSTOMERS c WHERE c.data.salary.number() > :1”);
stmt.setInt(1, 30000);
ResultSet rs = stmt.executeQuery();
while (rs.next()) {
OracleJsonObject obj = rs.getObject(1, OracleJsonObject.class);
String name = obj.getString(“name”);
String job = obj.getString(“job”);
System.out.println(name + ” – ” + job);
}
rs.close();
stmt.close();
The results are JSON objects which match the query regardless of which shard they reside on.
In an application you may want to also retrieve the ID in the above query and then use that to perform further work on specific objects, and update them directly on the shard that they reside on.
Use Case 2: Sharding on JSON Fields
In the first use case, we looked at how to simply distribute JSON data across shards using a simple but unrelated unique ID. In this example, we take a look at how to shard JSON using fields in the JSON document.
This has some unique benefits:
- Because sharding keys do not have to be unique, JSON objects with the same shard key value are clustered together. For example, everyone with the same US ZIP code will reside on the same shard. This can make queries on a single shard possible, lowering the number of cross-shard queries.
- Physical placement (mapping data to physical shards) becomes easier and may be used when considering data governance issues or other issues where there is a relationship between the field value and physical access.
It is important to choose the correct sharding key. Consult the Oracle documentation on sharding key choice and limitations. In particular, a sharding key is a field in the data that should rarely, if ever, change.
As before, we create a table but add one more field that will hold the value of the field that we intend to use in sharding. Let’s use the ZIP code example as mentioned before. So we create the table as:
/* Create the sharded table */
CREATE SHARDED TABLE CUSTOMERS
(
“ID” VARCHAR2(255) NOT NULL,
“ZIP” VARCHAR2(60) NOT NULL,
“CUSTPROFILE” JSON,
PRIMARY KEY (ID,ZIP))
TABLESPACE SET TSP_SET_1
PARTITION BY CONSISTENT HASH (ZIP) PARTITIONS AUTO;
There are two differences to note here:
Firstly, we added the column (ZIP) that will hold the JSON field.
Secondly, we have created a Primary Key that includes ID and ZIP. We will continue to use ID both because it provides us a unique ID to use to build a Primary Key, and also because it will make it easier to access this table using SODA in the next installment of this series. The Primary Key however must be unique AND it must include the sharding key, so we make it a combination of the two fields.
It is not possible to shard directly from JSON fields, thus the need to create a column to use for the sharding key. But we also have to keep this column in sync. To enforce these requirements we can use a database trigger.
These requirements to both create the column and keep the column in sync can also be enforced by the application. See Appendix B for more details.
As the sharding user, on the shard catalog database, we can issue the following commands to create the trigger:
alter session enable shard ddl
create or replace procedure COLLECTION_BF_ZIP_CUSTOMERS AS
begin
EXECUTE IMMEDIATE ‘alter session enable shard operations’;
EXECUTE IMMEDIATE q’%
Create or Replace TRIGGER CUST_BF_TRIG
BEFORE INSERT or UPDATE on CUSTOMERS
FOR EACH ROW
begin
:new.ZIP := JSON_VALUE(:NEW.CUSTPROFILE, ‘$.ZIP’ error on error error on empty);
end;
%’;
end;
/
exec sys.exec_shard_plsql(‘app_schema.collection_bf_zip_customers()’,4+1+2);
In the example above, ZIP is assumed to be a top-level field in the JSON document. If the value is in a nested field, for example under an ADDRESS field, you must include the field hierarchy, for example ‘$.ADDRESS.ZIP’.
Also, the returned JSON_VALUE must match the type of the JSON field, in this case it defaults to VARCHAR. If we wanted to have ZIP be a NUMBER for example, then the statement above would have a RETURNING NUMBER clause in addition to the error clause.
The exact name of the procedure is only chosen for convenience. The important parts are the appropriate column to update and which JSON field it maps to.
The procedure above wraps a trigger that is then created locally on each shard. The purpose of the trigger is to allow the application to add or update JSON and have the shard field (ZIP in this case) kept in sync automatically.
Now, as in the previous examples we will demonstrate how to perform queries using direct routing, as well as proxy routing via the shard catalog.
Single-Shard Queries
Again, the shard we need to connect to is determined by the data we need to work with. In this case, the ZIP field, which is the sharding key, is being used to determine the correct shard to connect to.
We build the UCP Connection as in Example 1, but then:
Example 3: Inserts with JSON Sharding Keys (Java)
…
// We will still set the document id since we still need it as a unique key.
// Later, when using SODA we will allow SODA to set this for us so we do not need to
// provide it.
UUID uuid=UUID.randomUUID{};
String documentid=uuid.toString{};
// To get the connection as before we need the sharding key but this time it is ZIP, which is
// part of our JSON. We can set it explicitly for example as shardingKeyVal=”94065” or
// if we have an OracleJsonObject all ready to insert then we can grab the ZIP from there as
// below
String shardingKeyVal = object.getString(“ZIP“);
// Now we build the connection using this sharding key as before
OracleShardingKey sdkey = pds.createShardingKeyBuilder().subkey(shardingKeyVal, OracleType.VARCHAR2).build();
System.out.println(“Creating Connection…”);
Connection conn = pds.createConnectionBuilder().shardingKey(sdkey).build()
PreparedStatement pstmt = conn.prepareStatement(“INSERT INTO CUSTOMERS (ID, CUSTPROFILE) VALUES (:1,:2)”;
Pstmt.setString(1, documentid);
pstmt.setObject(2, obj, OracleType.JSON);
pstmt.execute();
system.out.println(“Document inserted.”);
We have created a new document in a specific shard, and the ZIP field will be populated automatically.
To insert more documents we have to establish a new database connection. But note that if the next document we want to work with has the same ZIP then we do not need to establish a new database connection. We are already connected to the correct shard.
Multi-Shard Queries
Queries across shards work the same way as in Example 2. The only thing to add, as before, is that if the query involves an equality on the sharding key (ZIP in this case) then the connection can also be made directly to the shard instead of to the shard catalog.
For example, if our query is to find all customers named ‘SMITH’ within one specific ZIP code, then we can connect to the shard that holds that data and issue the query.
Conclusion
In this post we have demonstrated how we can distribute JSON data across Database Shards. If the intent is primarily to distribute the data evenly, then a key can be generated, unique to each Document, to act as a document identifier. This ID is then hashed in order to distribute the documents equally across available shards.
We can also tie the sharding key to a specific field within the JSON document. This allows us to set up a meaningful document ID that can be used as the basis for retrieval and update of the document. The major consideration, however, is that this field is a static field, not one that is updated.
So far, we have used code samples that use SQL in order to work with and search for documents. In Part 2, we will show you how Simple Oracle Document Access (SODA) can be used instead of SQL in the application code to work with JSON documents in a sharded database configuration.
Appendix A: Python Examples
The following are Python equivalents of the above Java code snippets in this post. The SQL is the same in creating the database objects but the equivalent application code is below:
Independent Shard Keys
Example 4: Inserts with independent shard keys (Python)
# import the cx_Oracle module for Python
import cx_Oracle
# Create a connection pool that will be used for connecting to all shards
# The components of the dsn are hostname (shard director),
# port (usually 1522), global service (created with GDSCTL)
dsn=cx_Oracle.makedsn(“shard_director_host”,1522,service_name=”service_name”)
pool=cx_Oracle.SessionPool(“app_schema”,”password”,dsn, soda_metadata_cache=True)
# Connect to a specific shard by using the sharding key, which in this example is
# set explicitly as a UUID
shrdkey=uuid.uuid4();
connection=pool.acquire(shardingkey=[shrdkey]);
# Setup our JSON
data = dict(name=”Jean”, job=”intern”, country=”Germany”)
inssql = “insert into CUSTOMERS values (:1, :2)”
#Insert the document
cursor.setinputsizes(None, oracledb.DB_TYPE_JSON)
cursor.execute(inssql, [shrdkey, data])
# After you have finished, release this connection back into the pool
pool.release(connection)
# If you want to add or work with more customers, start with another connection
# For example: connection=pool.acquire(shardingkey=[“123”]) and so on.
#When you are completely finished working with customers you can shut down the pool
pool.close()
As in the Java example, we need to generate a new UUID and grab a new connection from the pool in order to insert another document
Example 5: Queries across Shards (Python)
import cx_Oracle
# Create an unpooled connection to the shard catalog
# In general, pooled connections should be used for all connections.
# This is shown here only as an example.
# The connect string connects to the shard director, but uses
# the catalog service, e.g. GD$catalog.oradbcloud
connection = cx_Oracle.connect(“app_schema”,”password”,”db_connect_string”)
# Build the query and execute it with a cursor
# Python supports JSON natively and once retrieved into a JSON object can be manipulated
sql = “SELECT c.custprofile FROM customers c where c.data.salary.number() > :1”“
for j, in cursor.execute(sql, 30000):
print(j)
# Close the unpooled connection
Connection.close()
Sharding on JSON Fields
Example 6: Inserts with JSON Sharding Keys (Python)
# import the cx_Oracle module for Python
import cx_Oracle
# Create a connection pool that will be used for connecting to all shards
# The components of the dsn are hostname (shard director),
# port (usually 1522), global service (created using GDSCTL)
dsn=cx_Oracle.makedsn(“shard_director_host”,1522,service_name=”service_name”)
pool=cx_Oracle.SessionPool(“app_schema”,”password”,dsn,soda_metadata_cache=True)
# Connect to a specific shard by using the shard key, a ZIP code. which in this
# example is set explicitly as ‘94065’, but this might be passed in or part of a loop
# You must know beforehand whether you are creating or working with a document
# with a specific ZIP code value.
connection=pool.acquire(shardingkey=[“94065”])
# Now generate our unique UUID
genuuid=uuid.uuid4();
# Setup our JSON as before
data = dict(name=”Jean”, job=”intern”, country=”Germany”)
inssql = “insert into CUSTOMERS (ID, CUSTPROFILE) values (:1, :2)”
#Insert the document
cursor.setinputsizes(None, oracledb.DB_TYPE_JSON)
cursor.execute(inssql, [genuuid, data])
# After you have finished, release this connection back into the pool
pool.release(connection)
# If you want to add or work with more customers with a different
# shard key start with another connection
# For example: connection=pool.acquire(shardingkey=[“10012”]) and so on.
# When you are completely finished working with customers, shut down the pool.
pool.close()
Appendix B: Enforcing Constraints with Application Logic
In the post above, a database trigger was used to ensure that the database field (ZIP in our example) was in sync with the equivalent field inside the JSON.
There are three options for how to handle this synchronization. We used Option 1 in the text since this requires nothing from the application, but the other two should be considered as well.
Option 1: Database Trigger to enforce Inserts AND Updates
When JSON is inserted or updated, a trigger ensures that the Relational field is updated. This trigger fires even if the relevant field is not itself being updated. An example of this trigger is in the above post.
Sharding keys should not be updated so the effect of the trigger when the shard key field is updated is an error message such as ORA-02672: cannot update sharding key
Option 2: Database Trigger to enforce only Inserts
When JSON is first inserted, this trigger ensures that the Relational field is updated. This trigger does not fire when the JSON field is later updated.
The advantage of this is that the trigger is not fired when most updates are made. Unfortunately, when the field corresponding to the sharding key is updated then the JSON field and the Relational field will be out of sync.
However, because sharding keys should not be updated, we recommend that the application itself enforce the constraint and not allow users to update the JSON field corresponding to the sharding key.
This trigger is created similarly to the one in the main post except instead of “BEFORE INSERT or UPDATE” it should read “BEFORE INSERT” only.
Option 3: No Database Trigger
With no trigger, it is entirely up to the application to enforce the following two constraints:
- When a row is created, the relational field (ZIP in our example) should be inserted as part of the same atomic transaction as the JSON field.
- Updates to the JSON field should not allow the field corresponding to the sharding key/relational field to be updated.
Further References/Reading:
Oracle Sharding: https://docs.oracle.com/en/database/oracle/oracle-database/21/shard/index.html
Oracle JSON Developer’s Guide: https://docs.oracle.com/en/database/oracle/oracle-database/21/adjsn/index.html
Oracle JDBC Developer’s Guide and Reference: https://docs.oracle.com/en/database/oracle/oracle-database/21/jjdbc/index.html

