Part 1: How to Start Continuous Integration with the Oracle Database
What is CI/CD
Continuous Integration (CI) and Continuous Delivery/Deployment (CD) are a set of principles or methodologies that empower development teams to deliver code faster, more reliably, and with fewer bugs compared to traditional software development such as the waterfall model. Teams that use CI/CD also usually adhere to some version of the Agile Methodology, working on smaller features as part of a larger overarching requirement in sprints rather than monolithic tasks spanning months or years.
We also have the emergence of DevOps (Developer Operations) as the Agile Methodology collided with the ability to quickly create infrastructure as code in the cloud. As these teams surveyed their new development landscape, it became apparent that they could no longer work in a vacuum, living in their own worlds as they had done in the past. As traditional job roles blurred and more work was done by fewer people, order needed to rise from the chaos of this new complexity.
So, what is CI/CD? What does it do to help with this mess of developers, operations, and stakeholders who need to get features and functions into their software? To answer this, let’s start with the CI of CI/CD, Continuous Integration.
Continuous Integration brings us the ability to have multiple development and operations teams working on different features on a single project simultaneously without stepping all over each other. While this premise sounds too good to be true, there is some truth to be had here.
To have a common thread we can always refer to, this set of posts will be using a common example with real code behind it to illustrate the concepts and processes we will be talking about. So, let’s jump right into it with an example we can reference as we build upon our development process.
Here is our scenario: we have a team of developers working on an application that tracks local trees in a community via a web interface on the city’s web site. A citizen can access this app and enter the information for a historic tree they find in the city. Now this team also uses the Agile Methodology and it’s time for the next sprint. We have a few features we need to get in, mainly the ability to see these trees on a map and the ability to upload a picture with the tree entry form. The tasks are assigned to the developers and the sprint starts.
When does Continuous Integration start? When the tasks are handed out, each developer will copy the code from the latest release in a repository and create their own copy or branch. This latest code release is an exact copy of the code that is currently deployed and running in production. Each developer will also be given a personal development database, more on this later. As the developers finish the tasks they were assigned, they commit their code branch to the repository. Before they create a pull request/merge, they check the current main branch of code in the repository for any changes from other developers merging clean code branches. If found, they will pull these changes down and commit their code again. One of these changes might have affected their code in a negative way and the build process that occurs when a pull request/merge happens will catch this. A code review is scheduled and if accepted, the developer can now create the pull request/merge into the main branch. There is also a build process that occurs every time code is merged into main to catch any bugs or issues that may show up or issues that other developers code may have caused. If so, the issues are addressed, a pull request/merge is created, and the automated testing again happens. Once the testing comes back clean, the code can be merged into the main branch.
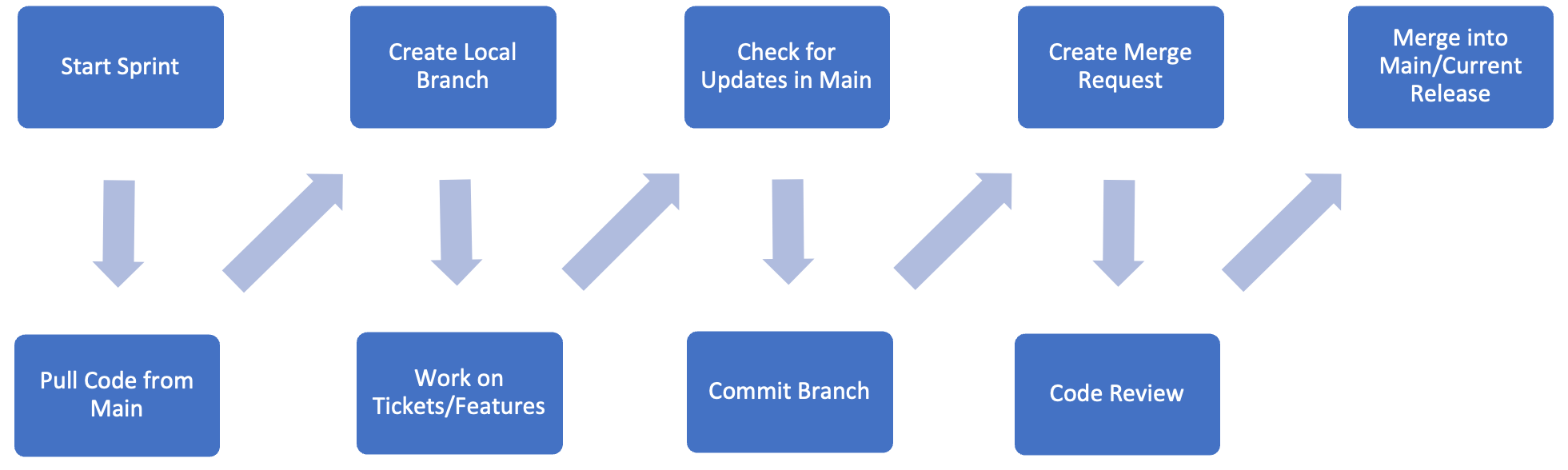
Summary Points:
- Start Sprint
- Pull Code from Main
- Create Local Branch
- Work on Tickets/Features
- Check for Updates in Main
- Commit Branch
- Create Merge Request
- Code Review
- Merge into Main/Current Release
What advantages do we gain from this process? First, as we can see throughout this process, we can catch issues before they get into production. By running automated tests on code changes, we can simulate what is going to happen at deployment time and eliminate surprises. This leads to better releases, more confidence in the development team by stakeholders and end users, as well as a higher standard of code from our developers.
Accountability is another advantage. We can see through code commits, merges and reviews exactly what is being put into our code repository and by whom. We can catch any code supply chain issues or hacks because each file and line of code can be reviewed upon a merge. Modern code repositories also track these changes with who and when, so a historical record is always present.
Stateless vs. Stateful
Continuous Integration works very well with stateless files and deployments; static files such as java classes or JavaScript combined with a stateless container deployment; in with the new and out with the old. It very easy to create a new deployment in a docker container with the latest code and replace the old container if working with stateless files.
We see this with blue-green deployment models. In this model, you have your running application container, the blue. The green is your idle newly deployed application container. As some point you switch to the green and all traffic is now using the new version while the blue one is idle. If you need to roll or switch back, you just change back to the idle blue container.
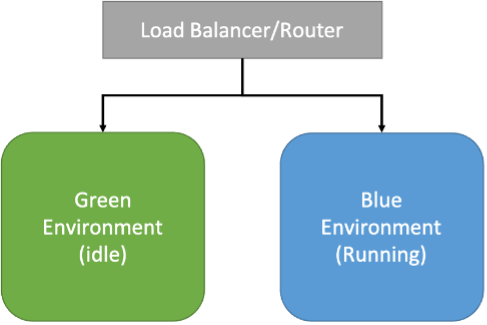
We quickly see these models are not going to work for database deployments. The database has state, transactions are being committed all the time so unless we can afford downtime to copy the entire database, deploy the changes and then resume operations, this poses a challenge. And because of this challenge, DBA’s and database developers are all too often blamed for these deployment bottlenecks. They are often told that databases can never do DevOps let alone CI/CD, it’s too legacy. Where does this leave the DBA and Database Developer? They will be branded with a legacy stigma and seen as a roadblock to CI/CD.
Tools of the Trade
While we wish there was a magic wand to make all database deployments easy and drop right into stateless CD/CD flows, we do have to accept that there is some truth with these DevOps concerns. But not all hope is lost! Oracle Database CI/CD can be a reality, but it requires some shifts in traditional methodologies and processes as well as some new tricks using features and functions of the Oracle Database that may have not been used before.
Let’s refer to our process flow and see where we can add database development specific steps:
The sprint starts and we have our database developers pull the latest code from the latest release. Where is this code? What tools can we use to allow developers to have local copies of our database code? We use a Code Repository.
What is a Code Repository?
There are many code repositories available to us such as Git, GitHub, GitLab and BitBucket. These repositories will help us store our files and provide versioning, accountability and visibility into our development process. But we are starting from scratch here, we have no repository or code release to work with. We will need to create a baseline with a Change Management/Tracking tool.
How can I do Change Management/Tracking with Oracle?
SQLcl with Liquibase.
What’s SQLcl?
Oracle SQLcl (SQL Developer Command Line) is a small, lightweight, Java-based command-line interface for Oracle Database. SQLcl provides inline editing, statement completion, command recall, and also supports existing SQL*Plus scripts. You can download SQLcl from oracle.com and it is installed in the OCI Cloud Shell by default.
What’s Liquibase?
Liquibase is an open-source database-independent library for tracking, managing and applying database schema changes.
How do they work together?
The Liquibase feature in SQLcl enables you to execute commands to generate a changelog for a single object or for a full schema (changeset and changelogs). We also add Oracle specific features and enhancements to Liquibase in SQLcl.
What Database?
For this article, the simplest way to get up and running with an Oracle Database is a free OCI account and an always free Autonomous Database. They come up in minutes and are never going to cost you a dime to use. If you do not have an always free OCI account, you can start here. Once you are logged into your account, you can create an always free Autonomous Database by following this guide here. For our purposes, an Autonomous Transaction Processing database is fine. Just remember the password you used when creating the database; we will need it later.
No Really, What Database?
While we will use a single autonomous database for this article’s examples, in the real world you have a few choices but the most important take away is that all developers MUST have personal databases to work in; and this point cannot be stressed enough. This can be tricky due to many factors but here are some suggestions on making this step a reality in your development organization.
1) Use Multi-tenant in the Oracle Database
Did you know that with 19c and later, you can have up to 3 pluggable databases for free? No need for the multi-tenant license, just create and use. PDBs (pluggable databases) also have the ability to clone just the metadata from an origin PDB. This makes it super simple to create copies of a production code database for all developers. It also aids in the testing automation process we will discuss in the next article. Another quick note is that by installing Oracle REST Data Services (ORDS) on a database enables APIs for cloning and creating PDBs via REST calls.
2) The Autonomous Database in OCI
Using ADB in OCI works very similar to multi-tenant where you can create full and metadata only clones of any ADB. And these ADB instances may only need to be up for minutes to weeks.
3) Reusable Instances
There are many features in the Oracle Database that will allow you to recover state so that developers have clean slates to work with in non multi-tenant instances. Features such as Guaranteed Restore Points/Flashback Database, RMAN duplicates/clones and Data Pump allow you to have clean instances for each developer as sprints start.
4) Docker/Virtual Machines
Either cloud based or local, virtualization technologies can also give developers personal instances to work in with copies of our main code repository within. Developers can also create VM instances of databases in OCI based on the lastet backup of our production instance if need be as well to help with the personal database effort.
Hello Repo
Again referring to our process flow and example, we need to create a baseline or main release so that our developers all start with the same code. To do this, we need to use SQLcl and Liquibase.
Setups Needed
For the examples we will be going over, we will be using git at the command line with our SSH keys pre-set, our repository in GitHub and the project name being db-cicd-project.
You have two choices here:
Manually create the repository or fork the repository that has been pre-created for this article. I would suggest forking it from here:
https://github.com/Mmm-Biscuits/db-cicd-project
Next, set up SSH connection via the following document:
Connecting to GitHub with SSH
A GitHub desktop GUIs is also available.
Now we need to clone it to our local machine/computer/laptop. Navigate to a directory where you would like to store your git repositories locally and issue the clone command:
> git clone git@github.com:YOUR_GITHUB_USERNAME/db-cicd-project.git
The above command will create a directory called db-cicd-project for you and pull any code that was in the repository. It is now time to fill this repository with database goodness.
The First Genschema
The following repository directory structure is what the sample repository that you forked contains:
db-cicd-project
- apps
- database
- etc
- presetup
- setup
- postsetup
- static
- css
- html
- images
- js
- ut
- utPLSQL
- README.md
- version.txt
Note: This directory structure assumes a few things (and we all know what assuming does). The assumption is that the apps directory may contain Application Express apps, so sub directories would be f101 for example. If not using APEX, you could consolidate the static directory and apps directory into a single directory.
Using this directory structure, we are going to start to work with the database and SQLcl now. Using our free ADB, we need to download the wallet that contains all the information for SQLcl to connect to the database. You can look here for the steps to download the wallet.
Once the ADB wallet is downloaded, at a command line, change the directory to the database directory in our repository project. We should be at db-cicd-project -> database. Start SQLcl but do not log into a database yet:
> sql /nolog
Next, we have to tell SQLcl where to look for the ADB wallet. First, remember where you downloaded it and we can use the following command to set its location:
SQL> set cloudconfig /DIRECTORY_WHERE_WALLET_IS/WALLET.zip
The naming of the wallet is in the format of Wallet_DB_NAME.zip. So, if I named my database ADB, the wallet name would be Wallet_ADB.zip. And if I put the wallet in my downloads folder and the full command would be:
SQL> set cloudconfig /Users/bspendol/Downloads/Wallet_ADB.zip
Next, we need to connect to the database. The syntax is:
SQL> conn USERNAME@DB_NAME_high/medium/low/tp/tpurgent
The high/medium/low/tp/tpurgent provide different levels of performance for various clients or applications to connect into the database. From the documentation:
- tpurgent: The highest priority application connection service for time critical transaction processing operations. This connection service supports manual parallelism.
- tp: A typical application connection service for transaction processing operations. This connection service does not run with parallelism.
- high: A high priority application connection service for reporting and batch operations. All operations run in parallel and are subject to queuing.
- medium: A typical application connection service for reporting and batch operations. All operations run in parallel and are subject to queuing. Using this service the degree of parallelism is limited to four (4).
- low: A lowest priority application connection service for reporting or batch processing operations. This connection service does not run with parallelism.
For what we want to do, the high-performance service name will be fine. We also want to connect as the admin user so we can setup a schema and permissions on that schema. With our database being named ADB, we would have the following connect command:
SQL> conn admin@ADB_high
And then provide the password you used when creating the ADB at the password prompt:
Password? (**********?)
And we are in. Time to create a schema, give that schema some permissions and then setup a sample for using Liquibase with. Run the following commands:
SQL> create user demo identified by "PAssw0rd11##11" quota unlimited on data; SQL> grant connect, resource to demo;
Now connect as this user:
SQL> conn demo@ADB_high
And then provide the password at the password prompt:
Password? (**********?)
Its time to create some sample datababase object for our repository. Run the following scripts included in the sample repository to create some objects:
SQL > @../demo_scripts/create_table.sql SQL > @../demo_scripts/insert_data.sql SQL > @../demo_scripts/create_logic.sql
This has created us a table, some data in the table, a trigger with some logic and two procedures. Let’s say this is the base of our application we are going to create. Its now time to use Liquibase to create our baseline and commit it to the repository.
At the SQL prompt, issue the following command:
SQL> lb genschema -split
Once this is finished, we can exit out of SQLcl and start to commit our changes to the repository.
SQL> exit
If you take a quick look around the database directory, you will now see folders for indexes, tables, procedures and triggers; all the objects we just created. We also have a controller.xml file. This file is a change log that includes all files in each directory and in the proper order to allow the schema to be deployed correctly to other databases, our CI process.
Time to commit our code to the repository. Change your directory to the top level of the project (the db-cicd-project directory) and run the following command:
> git add .
This command adds our new files to the local staging area. Now we commit the files
> git commit -m "v1.0"
A git commit in takes a snapshot of your local repository or you can think of it as saving the current state. Finally, lets push these files up to the GitHub file repository
> git push
The push command uploads our commit or state to the main repository. Once the push is done, you can see our files in our repository on GitHub. Congratulations, you have just created your code baseline or version 1.0!
Ready, Set, Branch
We have our main code line for our application in the repository. We can now have our developers clone the repository and start their assigned tickets/task in this development cycle or sprint. The issue with this is that they would all be committing to main and probably stepping all over each other. This requires each developer to create a branch of the repository that they can work in and commit their code to.
Let’s pretend we are developer who has been given the URL to clone the repository and start coding. They start by using git to clone to their local machine:
> git clone git@github.com:YOUR_GITHUB_USERNAME/db-cicd-project.git
Now they need to create a personal branch of this code:
> git checkout -b BRANCH_NAME
A good practice is to have the developers name the branch to relate to a ticket or sprint they are working on with their names in the branch. Here are some examples:
> git checkout -b TICKET#_USERNAME > git checkout -b JIRA_TICKET#_USERNAME > git checkout -b SPRINT#_USERNAME
For our example here, let’s use the following (use your name, not mine). Run this command in the top level folder of the project (db-cicd-project)
> git checkout -b sprint1_brian.spendolini
And you will see the response:
> Switched to a new branch 'sprint1_brian.spendolini'
We can now start developing and committing code to the repository without mixing our changes with the main code line. You can always issue a git status to see what branch you are in:
> git status On branch sprint1_brian.spendolini nothing to commit, working tree clean
Only the Changes
Back to our sprint. If you remember from our example scenario, the first ticket says that we need to add a new column to the trees table so that citizens can upload a picture of the tree they are entering. OK, simple enough task.
Once we are in our local git repository for the project db-cicd-project, we move the the database directory. And as before, we use SQLcl to log into our autonomous database:
> sql /nolog
Set the wallet location again (your directory path will be different):
SQL> set cloudconfig /Users/bspendol/Downloads/Wallet_ADB.zip
And connect to the database:
SQL> conn demo@ADB_high
And then provide the password at the password prompt (password is PAssw0rd11##11):
Password? (**********?)
Time to add the column. We can issue the following SQL to add the personal_interest column to the trees table:
SQL> alter table trees add (tree_picture blob); Table TREES altered.
Ticket done, time to generate the schema again using Liquibase.
SQL> lb genschema -split
We can exit SQLcl and go back to the top level of our local git repository. In the db-cicd-project, we issue a git add
> git add .
And then a commit
> git commit -m "ticket1"
Then we push the new code up to our repository. This push will be slightly different because we are pushing to a branch now. If you issue a git push, you will see something similar to below:
> git push
fatal: The current branch sprint1_brian.spendolini has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin sprint1_brian.spendolini
So we need to issues the push with our branch this one time:
> git push --set-upstream origin sprint1_brian.spendolini
If you go into the GitHub web UI, you can see in this repository that a new branch has been created and that only the table file has been updated as expected.
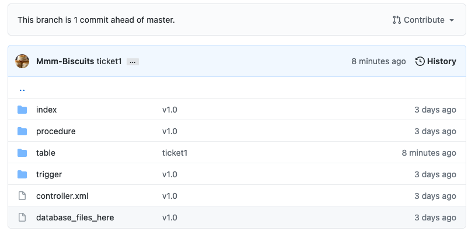
The other files which contain the procedure and trigger code have not been changed. Again, Liquibase is tracking the changes for us, and we can see it in action here.
Apply Yourself
Seeing is believing so let’s do exactly that; let’s apply our master code line into a schema in our database then apply the new branch and see what Liquibase does.
We need to switch back to our master branch in our local code repository on our local machines. Before we do that, we can see what happened when we do this switch. Go into the database directory while still on this branch we just committed to. Take a look at the trees_table.xml file. We should see the new column in the XML as:
<COL_LIST_ITEM>
<NAME>TREE_PICTURE</NAME>
<DATATYPE>BLOB</DATATYPE>
</COL_LIST_ITEM>
</COL_LIST>
Now issue the following git command:
> git checkout master
And look at the trees_table.xml again. You can see that the last column in this file is SUBMISSION_DATE and no longer TREE_PICTURE.
<COL_LIST_ITEM>
<NAME>SUBMISSION_DATE</NAME>
<DATATYPE>TIMESTAMP</DATATYPE>
<SCALE>6</SCALE>
</COL_LIST_ITEM>
</COL_LIST>
Why is that? It’s because you switched branches to the master branch where we have our baseline code. We have yet to merge this code into that main branch so the new column change only exists in our development branch. Let’s use this to our advantage. While on the master branch, start up SQLcl and login as the admin user:
> sql /nolog SQL> set cloudconfig /Users/bspendol/Downloads/Wallet_ADB.zip SQL> conn admin@ADB_high
And we will create a new schema
SQL> create user test identified by "PAssw0rd11##11" quota unlimited on data; SQL> grant connect, resource to test; SQL> conn test@ADB_high Password? (**********?) ************** Connected.
We need to be in the database directory of our local project. We can use some of SQLcl built in functionality to get there if not already there. We can navigate directories with the cd command. If you are in the tables directory under the database directory, you can simply issue a:
SQL> host cd ..
And move up a directory into the database directory in our project home. We can also use the host command with SQLcl to see where we are:
SQL> host pwd /Users/bspendol/git/db-cicd-project/database
Ensure you are in the /db-cicd-project/database directory where mine would be as above:
/Users/bspendol/git/db-cicd-project/database
You can also issue a host ls command to see the files in that directory:
SQL> host ls controller.xml index table database_files_here procedure trigger
we are looking to use the controller.xml file.
Quick checkpoint: We are logged into our database as the test user we just made, we are on the master code branch in the local repository and we are in the database directory in our project home. Once here, we are going to use Liquibase to create the objects from our master branch. Issue the following command:
SQL> lb update -changelog controller.xml
Once you issue this command, you will see all our objects being created in the database.
SQL> lb update -changelog controller.xml ScriptRunner Executing: table/trees_table.xml::96726c6d630653c9a9169df8b67089f2cdee1135::(DEMO)-Generated -- DONE ScriptRunner Executing: procedure/admin_email_set_procedure.xml::9d1175a5b6ca6d0c969a2eb183062e0a873ee226::(DEMO)-Generated -- DONE ScriptRunner Executing: index/tree_id_pk_index.xml::b4dd6c2359e7f1e881b55ba728056510d537967a::(DEMO)-Generated -- DONE ScriptRunner Executing: trigger/set_date_bi_trigger.xml::3b0d8da4c19a11b80f035a748c9b40752f010110::(DEMO)-Generated -- DONE ######## ERROR SUMMARY ################## Errors encountered:0 ######## END ERROR SUMMARY ##################
Now, we can move to our development branch and apply that to this schema. Exit out of SQLcl:
SQL> exit
Change branches (remember your branch will be named different, unless you are a clone of me with the same name..if so email me please):
> git checkout sprint1_brian.spendolini Switched to branch 'sprint1_brian.spendolini' Your branch is up to date with 'origin/sprint1_brian.spendolini'.
And log back into the database as this test user:
> sql /nolog SQL> set cloudconfig /Users/bspendol/Downloads/Wallet_ADB.zip SQL> conn test@ADB_high
And now, using our development branch, we will apply the changes to this schema:
SQL> lb update -changelog controller.xml ScriptRunner Executing: table/trees_table.xml::f81a149311b20a5a1dfe95a35108b8728df33b7f::(DEMO)-Generated -- DONE ######## ERROR SUMMARY ################## Errors encountered:0 ######## END ERROR SUMMARY ##################
There are 2 tables that Liquibase uses to track changes, DATABASECHANGELOG and DATABASECHANGELOG_ACTIONS. There is also a view that combines these tables for a more readable format, DATABASECHANGELOG_DETAILS. If we take a look at the DATABASECHANGELOG_DETAILS view, we can see that only an alter table was done and that the table was not dropped and recreated in the SQL column:
SQL
--------------------------------------------
ALTER TABLE "TREES" ADD ("TREE_PICTURE" BLOB)
This would be not only the behavior you would see in say a production instance, but more importantly the behavior you would expect a change management tool to be executing.
Merge Ahead
You now have the tools to start change management with SQLcl, Liquibase and a git repository for your development group or organization. As with all new processes, start slow. Maybe start with just getting everyone used to committing code to a central repository using git. But once we start adding these building blocks, we can continue down the CICD road to the next stages.
This process also allows you to start combining your database sprint code with stateless application code in the same repository setting the entire development team up for a CICD process. No longer are database developers and DBAs left out in the cold being called legacy when they can now uptake the same change management and repository practices that other development teams have enjoyed.
In part 2, we will be discussing the automated pipelines we should be using for testing this code; in essence, once a commit or merge request happens, we test the code on a new database.
