Directory-based data distribution is a new feature introduced in Oracle Database 23ai, enhancing the user-defined sharding method by providing a more flexible approach to data placement and management which lets you control the placement of the data on the shards. Directory-based data distribution provides full control over the mapping of key values to shards, where the location of data records associated with any sharding key is specified dynamically at runtime based on user preferences. The key location information is stored in a directory table, which can hold a large set of key values (in the hundreds of thousands).
You have the flexibility to move individual key values from one location to another, or make bulk movements to scale up or down, or for data and load balancing. The location information can include the shard database information and partition information.
Directory-Based Data Distribution Concepts and Architecture
The following are key concepts for understanding directory-based data distribution.
- Mapping of key values to partitions and shards is stored in a directory table.
- Directory table is automatically created in the catalog and shards when a table sharded by directory is created.
- Shard director (GSM) and client-side connection pools cache the directory for routing purposes. Key values in caches are encrypted.
- Directory is automatically updated when rows are inserted into or deleted from the sharded table.
- Sharded table contains a virtual column with partition information, which is used for partition pruning.
The following figure shows the key components of directory-based data distribution. The directory table is hosted on the catalog, and is duplicated to all of the shards. The sharded tables are distributed across different shards based on the key/partition mappings in the directory table.
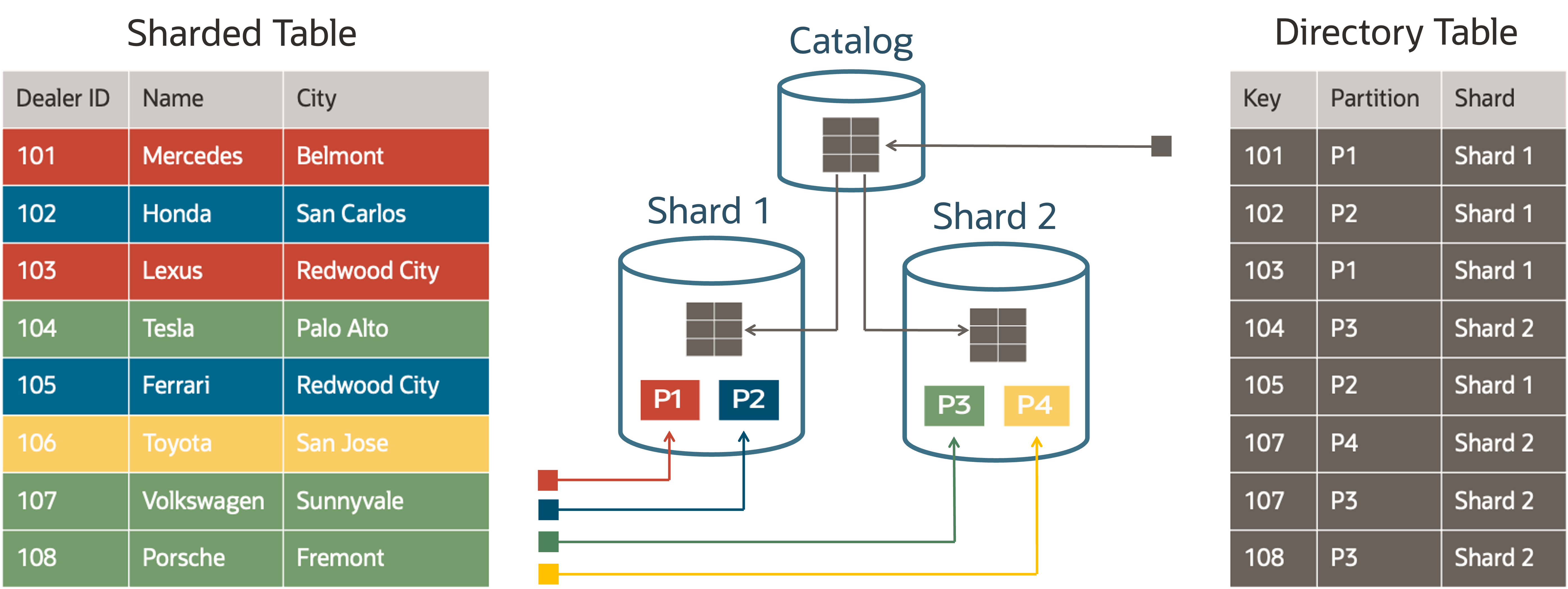
Directory-Based Data Distribution Architecture
Key insert and update operations are performed on the catalog and synchronously duplicated to the shards at commit time.
Client pools fetch the key to chunk/shard mappings from each shard the same way as in other sharding methods. They also subscribe to FAN events that notify them about new key mappings or deletions.
Directory-based Data Distribution Use Case
The following use case illustrates when it would be advantageous to use the directory-based data distribution method in your Globally Distributed database.
Data Sovereignty
Directory-based data distribution can be implemented to achieve data sovereignty by data localization and avoiding privacy violations. Data is stored in shard databases based on defined sharding keys in the directory table assigned to particular partitions. Cross-shard queries can be performed from the catalog database to retrieve data from all shard databases. Therefore, application super users (who require access to the the entire dataset) can get full control of data (read-write permissions) including for reporting purposes from the catalog database. The application can connect to the catalog database or directly to shards based on the requirements.
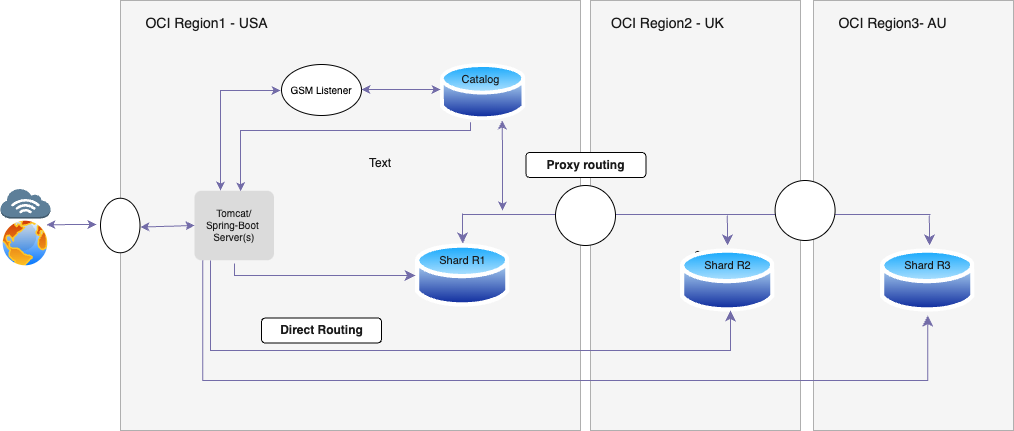
Directory-Based Sharding for Data Sovereignty
How to Implement Directory-Based Data Distribution to Achieve Data-Sovereignty
Let’s learn how you can achieve data sovereignty using multiple sharding keys? With Directory-based data distribution implementations, sharding keys can be defined and managed at run-time.
Directory-based data distribution is a new addition to the User-Defined Sharding; therefore, you can get familiar with user-defined sharing topology. Deploying and Managing a Directory-Based Oracle Globally Distributed Database is a requisite for implementing your directory-based data distribution database schema. With directory-based data distribution “PARTITION BY DIRECTORY” is used whereas “PARTITION BY LIST” is used in user-defined sharing.
After sharding configuration verification, you can refer to Oracle Globally Distributed Database Schema Design, connect to the catalog database using the sharded schema user, and run the following sample DDLs for directory-based data distribution test to make sure it works as expected.
A) Create tablespaces for each shard in shardspaces as defined in GSM topology configuration (this step is similar to User-Defined Sharding):
CREATE TABLESPACE TBS_USA IN SHARDSPACE shardspace_usa; CREATE TABLESPACE TBS_IND IN SHARDSPACE shardspace_ind; CREATE TABLESPACE TBS_CHN IN SHARDSPACE shardspace_chn;
B) To allow multiple modules/schemas integrated in the Globally Distributed Database, an optional root/parent table can be added as a first table in table family. Adding a generic table as parent/root table can allow different modules/schema tables in the same sharding data model as long as its sharding keys are being referred to in the child table. In the following example for creating a root/parent table with directory-based data distribution, we are partitioning it by DIRECTORY and using three sharding keys: id, ctry_cd, and dept_id.
CREATE SHARDED TABLE SHARD_ROOT (
id VARCHAR2(50) NOT NULL,
ctry_cd VARCHAR2(50) NOT NULL,
dept_id VARCHAR2(50) NOT NULL,
CONSTRAINT "PK_SHARD_ROOT" PRIMARY KEY ( id, ctry_cd, dept_id )
) PARTITION BY DIRECTORY( id, ctry_cd, dept_id ) ( PARTITION p1 TABLESPACE tbs_usa,
PARTITION p2 TABLESPACE tbs_ind,
PARTITION p3 TABLESPACE tbs_chn);
Here, “PARTITION BY DIRECTORY” is the clause used for directory-based data distribution.
C) The steps above automatically create a directory table SHARD_ROOT$SDIR. This table SHARD_ROOT$SDIR persists the sharding key combinations allowed for each shard’s partitions.
Below are sample commands to insert data into Directory table SHARD_ROOT$SDIR for different shards (differentiated by PARTITION names).
exec gsmadmin_internal.dbms_sharding_directory.addkeytopartition ('APP_SCHEMA', 'SHARD_ROOT', 'P1’, ‘U0001’, 'USA’, 'USA_DEPT_001' );
exec gsmadmin_internal.dbms_sharding_directory.addkeytopartition ('APP_SCHEMA', 'SHARD_ROOT', ‘P2’, ‘I4001’, ‘IND’, ‘IND_DEPT_401' );
exec gsmadmin_internal.dbms_sharding_directory.addkeytopartition ('APP_SCHEMA', 'SHARD_ROOT', ‘P3, ‘C7001’, ‘CHN’, ‘CHN_DEPT_701' ); commit;
Sharding keys in SHARD_ROOT$SDIR can be added/updated/deleted by the application or manually from the catalog database.
D) To select from the Directory table SHARD_ROOT$SDIR:
SELECT * FROM SHARD_ROOT$SDIR ORDER BY ID;
E) For directory-based data distribution, create a child table that to the parent SHARD_ROOT table.
CREATE SHARDED TABLE CUSTOMERS (
cust_id VARCHAR2(50) NOT NULL,
shard_root_id VARCHAR2(50) NOT NULL,
ctry_cd VARCHAR2(50) NOT NULL,
dept_id VARCHAR2(50) NOT NULL,
status VARCHAR2(10) NOT NULL,
CONSTRAINT PK_SHARD_ROOT PRIMARY KEY (cust_id, shard_root_id, ctry_cd, dept_id),
CONSTRAINT FK_CUSTOMERS FOREIGN KEY (shard_root_id, ctry_cd, dept_id)
REFERENCES SHARD_ROOT(id, ctry_cd, dept_id) ON DELETE CASCADE
) PARTITION BY REFERENCE (FK_CUSTOMERS);
F) Insert into the first sharded table in table-family SHARD_ROOT:
insert into shard_root (id, ctry_cd, dept_id)) values (‘U0001', 'USA’, 'USA_DEPT_001'); commit;
G) Insert into the child table (which is first business related sharded table example):
insert into CUSTOMERS (cust_id, shard_root_id, ctry_cd, dept_id,status) values ('USA_000001', ‘U0001 ', 'USA’, 'USA_DEPT_001','active') ;
insert into CUSTOMERS (cust_id, shard_root_id, ctry_cd, dept_id,status) values ('IND_400001', ‘I4001’', 'IND’, 'IND_DEPT_401','active') ;
insert into CUSTOMERS (cust_id, shard_root_id, ctry_cd, dept_id,status) values ('CHN_700001', ‘C7001’', 'CHN’, 'CHN_DEPT_701','active') ;
commit;
H) Connect to each database e.g., catalog, shard1, shard2, and shard3 and run the following query to validate the records.
Select count(1) from CUSTOMERS;
The catalog query retrieves data from all shards. Therefore, this query will provide a total of 3 records from the catalog database. 1 record will be retrieved from each of the 3 shard databases because data persisted on the shards for matching sharding keys.
This example helps us confirm that data sovereignty can be achieved using directory-based data distribution for persisting data based on the different regions using different sharding key combinations.
Defining sharding keys at run-time by application/batch-program
Directory-based distribution allows you to define sharding keys at run-time by application or a standalone batch program in any language, such as Java, Python, or PL/SQL. Shown here is a Java code snippet that adds five sharding keys in a given partition, which also can be parameterized at run-time.
try {
Connection con = datasource.getConnection();
for (int i = 0; i < 5; i++) {
String addkeytopartitionParams = "begin gsmadmin_internal.dbms_sharding_directory.addkeytopartition(?,?,?,?,?,? ); end;";
CallableStatement callStmtParams = con.prepareCall(addkeytopartitionParams);
callStmtParams.setString(1, "APP_SCHEMA");
callStmtParams.setString(2, "SHARD_ROOT"); callStmtParams.setString(3, "P1");
String id = "U" + 0101 + i; callStmtParams.setString(4, id);
callStmtParams.setString(5, "USA"); callStmtParams.setString(6, "USA_DEPT_001");
callStmtParams.execute();
}
} catch (Exception e) {
e.printStackTrace();
}
In the above code snippet, the “addkeytopartition()” procedure is called to provide parameters at runtime and its format is:
DBMS_SHARDING_DIRECTORY.addKeyToPartition(
(schema_name IN varchar2,
parent_root_table IN varchar2,
partition_name IN varchar2,
sharding_keys_comma_ separated_1,..n … );
Here, sharding_keys can be alphanumeric. This is very helpful to manage sharding keys programmatically.
Additionally, Directory-Based Data Distribution can be used in the following cases:
- B2B application that manages data in large number of business customer accounts.
- An example is a dealership application that hosts and manages data for many dealers. What’s more, the amount of data for different dealerships can be drastically different: some dealers are large operations while others are much smaller. There may also be a need to designate different resources/locations for the different dealerships based on application-specific criteria.
- Applications where you need to group certain key values together into the same location or chunk for affinity purposes, and when needed this group can be moved together in an efficient manner.
- An example is a social network application, where grouping together customers who often exchange messages on the same shard minimizes the cross-shard traffic. The grouping must be preserved when data is moved between shards. On the other hand, if a member of a group starts communicating more with members of another group, their data can be moved to the appropriate group with minimal impact on the application.
Advantages of Directory-Based Data Distribution:
- As long as sharding keys are the same, any number of tables, schemas, and application modules can be integrated because the sharding configuration uses sharding keys to relate tables in a hierarchical data model using directory-based data distribution.
- The same schema model can be used for dealership/vendor applications using different partitions and multiple shards.
- Virtual Private Database (VPD) can be used along with directory-based data distribution for additional security and isolation of data within various countries/regions for data distribution and access.
- Application super users (who require access to the entire dataset) can access data from the catalog database for needs such as scatter/gather or reporting purposes, and non-superusers (who needs access to specific shards based on sharding keys) can be granted access for specific country/region/department, etc. sharding keys based on specific data partitions.
- Reduced database management tasks for day-to-day transactions because data can be distributed and controlled from the application itself instead of data movements over geographically distributed databases.
- Directory-based data distribution enables a globally distributed database implementation that meets various application needs, including scalability, disaster recovery, zero downtime, and zero data loss.
Additional Resources:
Directory-Based Data Distribution
Deploying and Managing a Directory-Based Oracle Globally Distributed Database

