One of the new features in Oracle Database 19c is Memoptimized Rowstore – Fast Ingest. This functionality was added to enable fast data inserts into Oracle Database. The intent was to be able to support applications that generate lots of informational data that has important value in the aggregate but that doesn’t necessarily require full ACID requirements. Applications like Internet of Things (IoT) where a rapid “fire and forget” type workload makes sense. For example sensor data, smart meter data or even traffic camera data might be collected and written to the database in high volumes for later analysis.
The following diagram shows how this might work with the Memoptimized Rowstore – Fast Ingest feature:
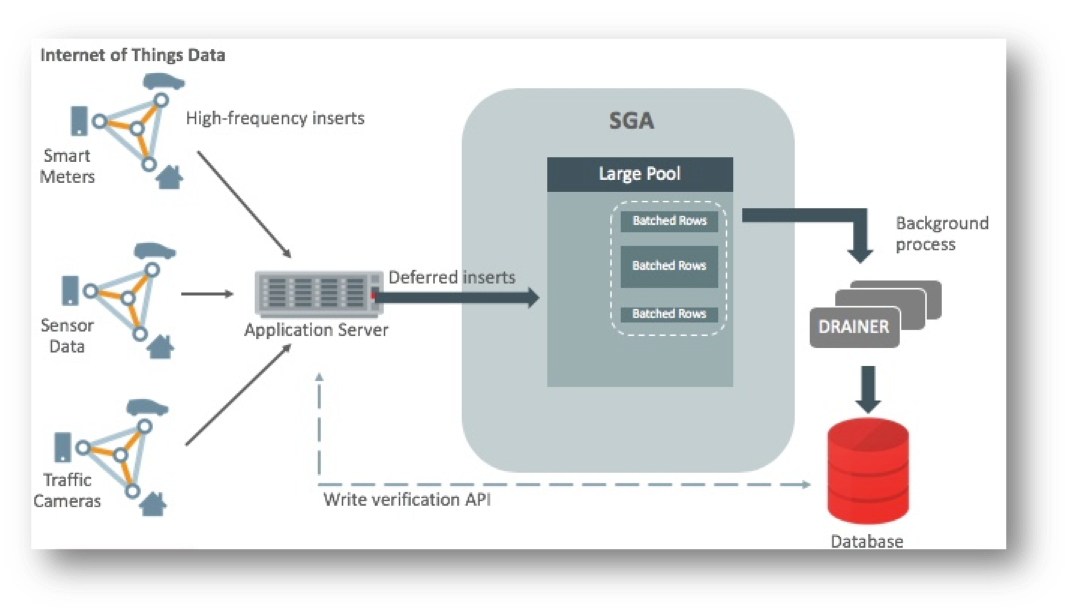
The key point to highlight is that since the ingested data is batched in the database in the large pool and is not immediately written the ingest process is very fast. This is how very large volumes of data can be ingested efficiently without having to process individual rows. However, it is possible to lose data should the database go down before the ingested data is written out to database files. This is very different from normal Oracle Database transaction processing where data is logged and never lost once “written” to the database (i.e. committed). That is also why there is a dashed arrow with a label titled “Write verification API”. In order to achieve the maximum ingest throughput, the normal Oracle transaction mechanisms are bypassed and it is the responsibility of the application to check to see that all data was indeed written to the database. Special APIs have been added that can be called to check if the data has been written to the database.
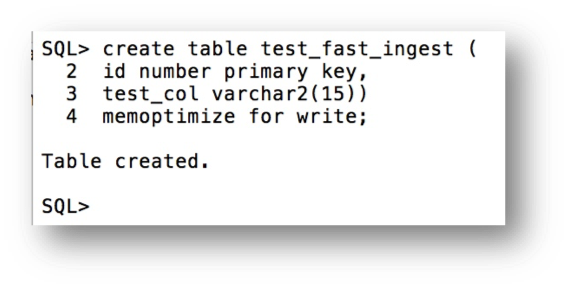
To get started with the Memoptimized Rowstore – Fast Ingest feature you must first enable one or more tables for fast ingest by adding the clause MEMOPTIMIZE FOR WRITE to a CREATE TABLE or ALTER TABLE statement. The following is an example:
To use fast ingest for inserts the MEMOPTIMIZE_WRITE hint must be added to the insert statement. Let’s insert a couple of rows using the MEMOPTIMIZE_WRITE hint:
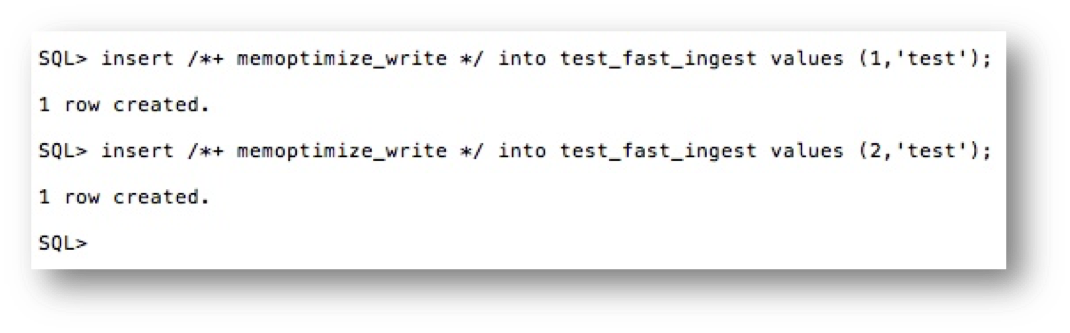
A rather silly example but it shows the mechanism. However this really isn’t the way the feature was meant to be used. Since the purpose of Memoptimized Rowstore – Fast Ingest feature is to support high performance data streaming, a more realistic architecture would involve having one or more application or ingest servers collecting data and batching inserts to the database. For the purposes of illustration though we will continue with our individual insert example.
Also note that the first time an insert is run the fast ingest area will be allocated from the large pool. How much memory is allocated will be written to the alert.log in the format:
2018-09-04T15:43:43.667014-07:00
Memoptimize Write allocated 884M from large pool
The result of these two inserts has been to write data to the ingest buffer in the large pool in the SGA. At some point that data will be flushed to the TEST_FAST_INGEST table. Until that happens the data is not durable. If the database were to crash any data not flushed to disk from the fast ingest buffers will be lost. I think this is an important distinction to make.
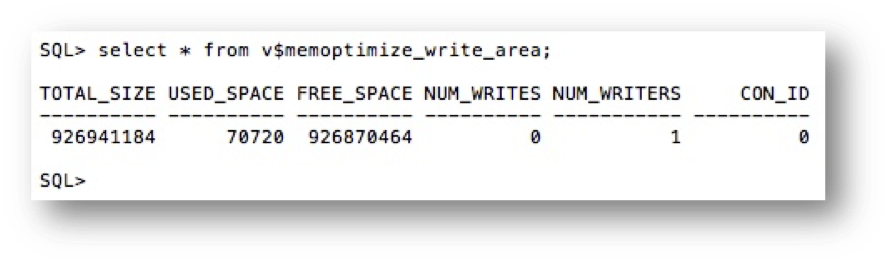
What about commits? In the context of fast ingest inserts, commits have no meaning since it’s not a transaction in the traditional Oracle sense. There is no ability to rollback the inserts. You also cannot query the data until it has been flushed from the fast ingest buffers to disk. You can see some administrative information about the fast ingest buffers by querying the view V$MEMOPTIMIZE_WRITE_AREA. The following shows an example of querying the fast ingest data in the large pool after inserting the rows above:
You can also use the packages DBMS_MEMOPTIMIZE and DBMS_MEMOPTIMIZE_ADMIN to perform functions like flushing fast ingest data from the large pool and determining the sequence id of data that has been written.
Index operations and constraint checking is done only when the data is written from the fast ingest area in the large pool to disk. If primary key violations occur when the background processes write data to disk then the database will not write those rows to the database. Assuming that all inserted data needs to be written to the database, and this may not be a valid assumption for some applications, this is why it is critical that the application insert process checks to see that the data it inserted has actually been written to the database before destroying that data. Only when that confirmation has occurred can the data be deleted from the inserting process.
The bottom line is that the Memoptimized Rowstore – Fast Ingest feature provides the ability to ingest data into Oracle Database in a rapid, “fire and forget” manner that allows applications to process extremely high volumes of data where that data is valuable in the aggregate, but it is not necessary that every transaction is captured.
