The latest Innovation release of the world’s most popular database, Oracle Database 21c, is now generally available “cloud first” in the Oracle Cloud Database Service Virtual Machine (for RAC and single instance) and Bare Metal Service (single instance). It’s also available in the Autonomous Database Free Tier Service in Ashburn (IAD), Phoenix (PHX), Frankfurt (FRA) and London (LHR) regions. General availability of Oracle Database 21c on other platforms including Exadata, Linux, Windows and the free Express Edition (XE) has since followed therafter.
Enabling a Data-Driven Future
Oracle has consistently taken the approach that storing and managing data in a converged database is more efficient and productive than breaking up into multiple single-use engines – which inevitably results in data integrity, consistency and security issues. Simply put, a converged database is a multi-model, multi-tenant, multi-workload database. Oracle Database fully supports multiple data models and access methods, simplifies consolidation while ensuring isolation, and excels in typical database workload use cases – both operational and analytical. Click the image below for a video introduction to Oracle’s converged database.
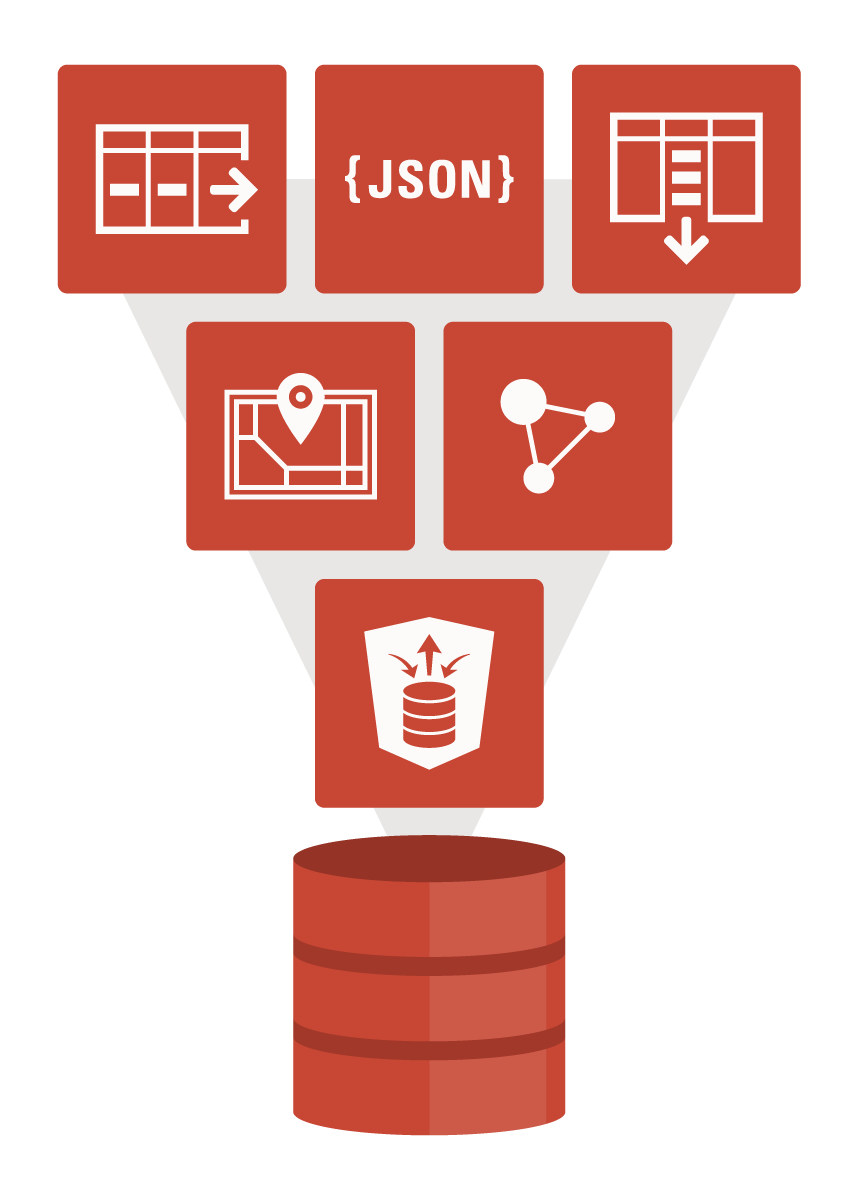
The 21c generation of Oracle’s converged database therefore offers customers: best of breed support for all data types (e.g. relational, JSON, XML, spatial, graph, OLAP, etc.), and industry-leading performance, scalability, availability and security for all their operational, analytical and other mixed workloads. Oracle’s converged strategy also ensures that developers benefit from all Oracle Database 21c key capabilities (e.g. ACID transactions, read consistency, parallel scans and DML, online backups, etc.) – freeing them to focus on developing applications without having to worry about data persistence.
New in Oracle Database 21c
This latest Innovation release introduces a number of new features and enhancements that further extend database use cases, improves developer, analyst and data scientist productivity, and increases query performance. Listed below is a subset of what’s new in Oracle Database 21c. For a more comprehensive review please refer to the New Features Guide or the Database Features & Licensing App. Or, try for yourself with the Oracle Database 21c new features LiveLab workshop!
Blockchain Tables
Blockchain as a technology has promised much in terms of solving many of the problems associated with the verification of transactions. While considerable progress has been made in bringing this technology to the enterprise, a number of problems exist. Arguably, the largest being the complex nature of building applications that can support a distributed ledger. Oracle Database 21c addresses this problem with the introduction of Blockchain Tables. These tables operate like any normal heap table, but with a number of important differences. The most notable of these being that rows are cryptographically hashed as they are inserted into the table, ensuring that the row can no longer be changed at a later date.
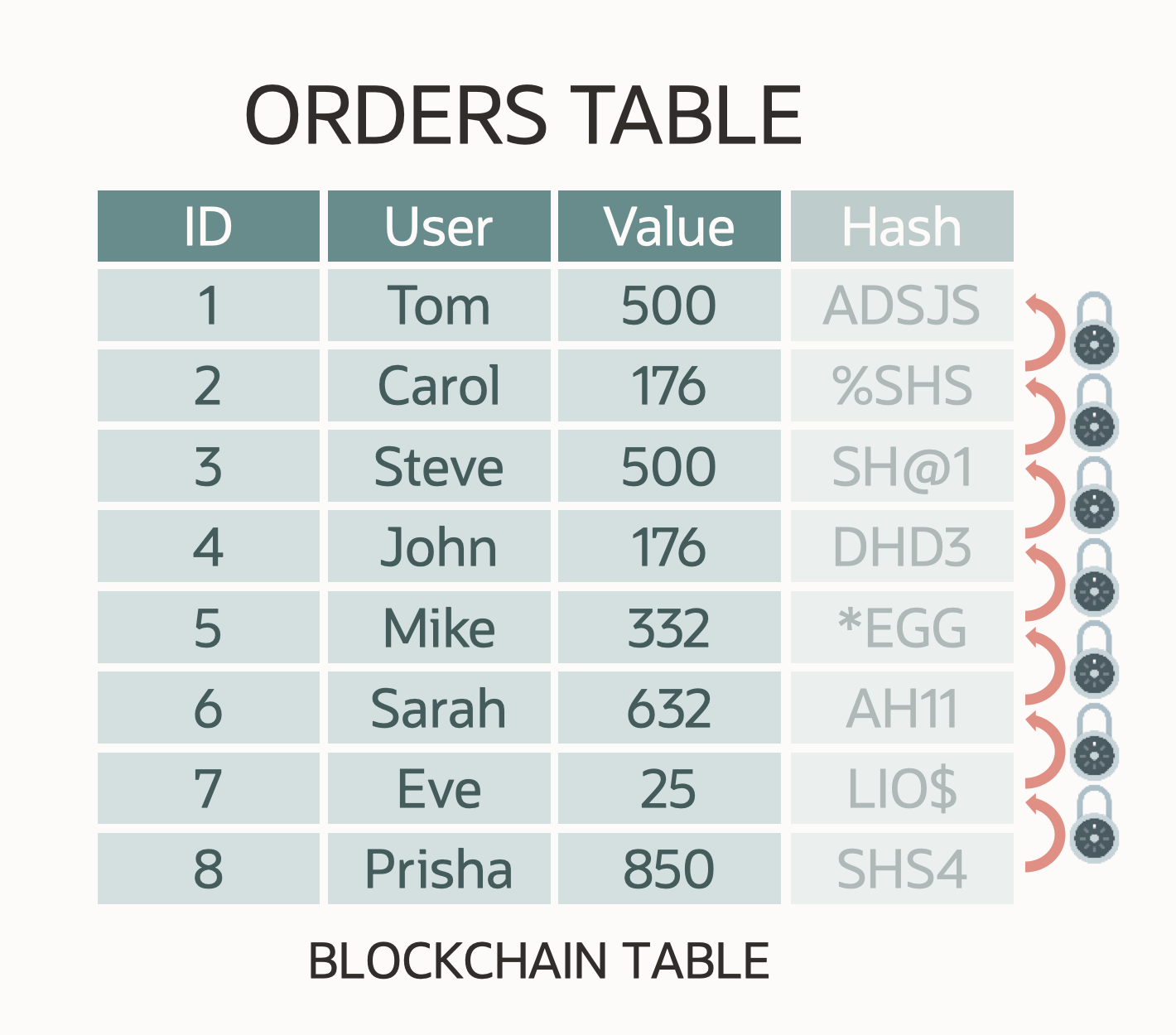
This essentially creates an insert only table, and users are unable to update or delete Blockchain Table rows. In addition, users are also prevented from truncating data, dropping partitions or dropping Blockchain Tables within certain time limits. These important capabilities mean that other users can trust that the data held in a Blockchain Table is an accurate record of events.
Native JSON Datatype
Oracle introduced support for JSON in Oracle Database 12c, storing JSON data as a VARCHAR2 or a LOB (CLOB or BLOB). This enabled developers to build applications with the flexibility of a schemaless design model, with all the power of Oracle Database. For example, users could query JSON documents using standard SQL, take advantage of advanced analytics, index individual attributes or whole documents, and process billions of JSON documents in parallel. Oracle also provided tools to discover what attributes make up the JSON documents, and thereby trivially create relational views on top of the collections. It was also possible for developers to treat their Oracle Database as if it were a NoSQL database by accessing it with the SODA (Simple Object Data API) APIs available for Java, Node.js, Python, C and REST.
In Oracle Database 21c, JSON support is further enhanced by offering a native data type, “JSON”. This means that instead of having to parse JSON on read or update operations, the parse only happens on an insert and the JSON is then held in an internal binary format which makes access much faster. This can result in read and update operations being 4 or 5 times faster and updates to very large JSON documents being 20 to 30 times faster.
CREATE TABLE j_order
(
id INTEGER PRIMARY KEY,
po_doc JSON
); The new data type wasn’t the only change that got introduced for JSON in Oracle Database 21c, Oracle also added a new JSON function JSON_TRANSFORM which makes it much simpler to update and remove multiple attributes in a document in a single operation.
UPDATE j_order SET po_doc = JSON_TRANSFORM( po_doc,
SET '$.address.city' = 'Santa Cruz',
REMOVE'$.phones[*]?(@.type == "office")'
)
WHERE id = 555;
Oracle has also added compatibility for the new JSON datatype to integration drivers and utilities like Datapump and GoldenGate.
Executing JavaScript inside Oracle Database
JavaScript is a ubiquitous scripting language that, among its many uses, enables richer user interaction in web applications and mobile apps. It’s one of the few languages that runs in a web browser, and can be used to develop both client-side and server-side code. There is a large collection of existing JavaScript libraries for implementing complex programs, and JavaScript works in conjunction with popular development technologies such as JSON and REST.
In Oracle Database 21c, developers can now execute JavaScript code snippets inside the database, where the data resides. This allows them to execute short computational tasks easily expressed in JavaScript, without having to move the data to a mid-tier or browser. The Multilingual Engine (MLE) in Oracle Database 21c, powered by GraalVM, automatically maps JavaScript data types to Oracle Database data types and vice versa so that developers don’t have to deal with data type conversion themselves. Additionally, the JavaScript code itself can execute PL/SQL and SQL through a built-in JavaScript module. All this also enables APEX developers to use JavaScript as a first-class language within their APEX apps, without having to sacrifice the power of PL/SQL and SQL. Here is some sample code that uses the DBMS_MLE PL/SQL package to execute JavaScript code:
set serveroutput on;
DECLARE
ctx dbms_mle.context_handle_t;
source CLOB;
greeting VARCHAR2(100);
BEGIN
ctx := dbms_mle.create_context(); -- Create execution context for MLE execution
dbms_mle.export_to_mle(ctx, 'person', 'World'); -- Export value from PL/SQL
source := q'~
var bindings = require("mle-js-bindings");
var person = bindings.importValue("person"); // Import value previously exported from PL/SQL
var greeting = "Hello, " + person + "!";
bindings.exportValue("greeting", greeting); // Export value to PL/SQL
~';
dbms_mle.eval(ctx, 'JAVASCRIPT', source); -- Evaluate the source code snippet in the execution context
dbms_mle.import_from_mle(ctx, 'greeting', greeting); -- Import value previously exported from MLE
dbms_output.put_line('Greetings from MLE: ' || greeting);
dbms_mle.drop_context(ctx); -- Drop the execution context once no longer required
END;
/SQL Macros
It is not unusual for a SQL statement to grow in complexity as the number of joins increase, or the operations performed on the retrieved data becomes more involved. It is also not uncommon for developers to try and solve this problem by using stored procedures and table functions to simplify these commonly used operations. This works extremely well to simplify code, but can potentially sacrifice performance as the SQL engine switches context with the PL/SQL Engine. In Oracle Database 21c, SQL Macros solve this problem by allowing SQL expressions and table functions to be replaced by calls to stored procedures which return a string literal to be inserted in the SQL we want to execute. It’s an incredibly simple concept and one that C and Rust programmers will be familiar with. The following trivial example shows it in action.
First, let’s create a table and insert a few rows.
CREATE TABLE line_items
(
id NUMBER,
name VARCHAR2(30),
item_type VARCHAR2(30),
price FLOAT
);
INSERT INTO line_items VALUES (1, 'Red Red Wine', 'ALCOHOL', 15.6);
INSERT INTO line_items VALUES (2, 'Its Cold Out There Heater', 'RADIATOR', 200.49);
INSERT INTO line_items VALUES (3, 'How Sweet It Is Cake', 'FOOD', 4.56);
COMMIT;
The SQL below calculates the value added tax on rows in our LINE_ITEMS table
SELECT id,
CASE
WHEN item_type = 'ALCOHOL' THEN ROUND(1.2 * price, 2)
WHEN item_type = 'SOLAR PANEL' THEN ROUND(1.05 * price, 2)
WHEN item_type = 'RADIATOR' THEN ROUND(1.05 * price, 2)
ELSE price
END AS total_price_with_tax
FROM line_items; However, Oracle Database 21c can simplify by creating a function with the new SQL_MACRO keyword and returning a string.
CREATE OR REPLACE FUNCTION total_price_with_tax(the_price FLOAT, the_item_type VARCHAR2)
RETURN VARCHAR2 SQL_MACRO(SCALAR) IS
BEGIN
RETURN q'[CASE
WHEN the_item_type = 'ALCOHOL' THEN ROUND(1.2 * the_price, 2)
WHEN the_item_type = 'SOLAR PANEL' THEN ROUND(1.05 * the_price, 2)
WHEN the_item_type = 'RADIATOR' THEN ROUND(1.05 * the_price, 2)
ELSE the_price END]';
END;
/
Developers then simply reference the SQL Macro inside a select statement. The SQL that’s executed is exactly the same as the original SQL Statement without the overhead of a context switch each time the row is fetched to execute this function.
SQL> SELECT id, total_price_with_tax(price, item_type) AS total_price_with_tax
FROM line_items;
ID TOTAL_PRICE_WITH_TAX
---------- --------------------
1 18.72
2 210.51
3 4.56
It’s also worth noting that developers can use the same approach when creating Parameterized Views and Polymorphic Tables.
In-Memory Enhancements
Analyzing data using a columnar model can result in massive performance improvements as compared to using a row-based model. However, updating data is significantly faster when using data held in rows. Oracle Database In-Memory is unique in that it allows users to benefit from both approaches. With this capability users can run their applications unchanged and Oracle Database In-Memory will maintain a columnar store supporting blazingly fast real-time analytical queries. The Oracle Database In-Memory Blog is a fantastic resource for finding out more about this powerful technology.
Oracle Database 21c introduces three major improvements to enhance performance and ease of use when using Oracle Database In-Memory:
- Database In-Memory Vector Joins : Through the use of its newly enhanced Deep Vectorization SIMD Framework, Oracle Database In-Memory can accelerate operations like hash joins on columns held inside of the in-memory column store. In the case of a hash join, the join is broken down into smaller operations that can be passed to the vector processor. The key-value table used is SIMD optimized and used to match rows on the left and right-hand sides of the join. This approach can result in join performance improvements of up to 10 times over traditional methods.
- Self-Managing In-Memory Column Store : When Oracle Database In-Memory was first released, users had to explicitly declare which columns were to be populated into the In-Memory Column Store. This gave users a high degree of control if memory was tight. Oracle Database 18c introduced functionality that would automatically place objects in the Column Store if they are actively used and removed objects that weren’t. However, users still had to indicate the objects to be considered. In Oracle Database 21c setting INMEMORY_AUTOMATIC_LEVEL to HIGH, ensures that all objects are considered – thereby simplifying the job of managing the in-memory column store.
- In-Memory Hybrid Columnar Scans : It is often not possible to have every column of every table populated in the Column Store because memory is limited. In many instances, this isn’t an issue but every once in a while users may encounter a query which needs data(columns) from the Column Store and data that’s only available in the row store. In previous releases of Oracle Database In-Memory, such querys would simply run against the row store. In Oracle Database 21c users can now use both! The optimizer can now elect to scan the In-Memory Column Store and fetch projected column values from the row store if needed. This can result in a significant improvements in performance.
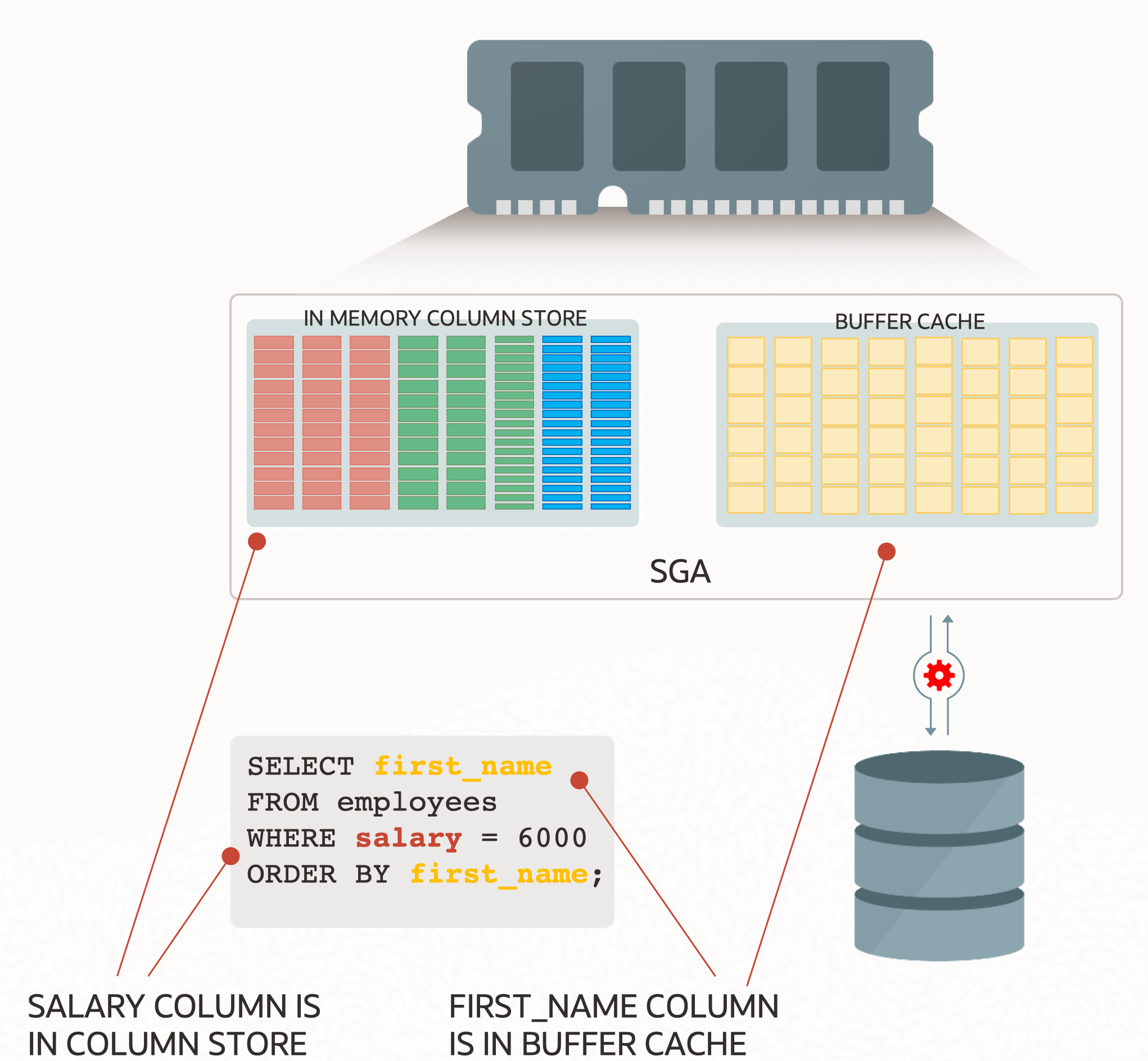
Hybrid Columnar Scan
Other Notable Enhancements
Please refer to the Oracle Database 21c New Features Guide for complete (long) list, but here are a few more notable enhancements that will be of interest to DBAs, developers, analysts and data scientists:
- Expression based init.ora parameters : It’s now possible to base database parameters (init.ora) on calculations made on the configuration of the system, i.e. set the database parameter CPU_COUNT on half the number of CPUs available to the operating system.
- Automatic Zone Maps : Oracle Database 21c on Exadata can now automatically create Zone Maps based on the predicates used in queries. Previously, this was a manual operation requiring users to understand how the data would be accessed. Automatic zone maps can dramatically reduce the number of blocks that need to be scanned.
- In-Database Machine Learning (ML) algorithms built into Oracle Database enables data scientists to leverage the power of Oracle Database to build predictive models (using over 30 ML algorithms) running directly on data held in database tables (as opposed to extracting data into a file system or specialist database for ‘sandbox’ analysis). Oracle’s approach of moving ML algorithms to the underlying data minimizes data movement, achieves scalability, preserves data security, and accelerates time-to-model deployment for predictive-type analytics Oracle Database 21c adds support for the MSET-SPRT and XGBoost algorithms, and the Adam Optimization solver for the Neural Network Algorithm.
- AutoML : Oracle Database 21c makes it even simpler for data scientists and analysts to take advantage of in-database machine learning by providing a Python machine learning interfaces to the database. This new client tool compliments existing R and SQL interfaces already available. AutoML simplifies the development of predictive machine learning models by automating the model selection, feature selection and parameter tuning processes required for building accurate models
- Optimized Graph Models : Graphs can consist of millions or even billions of edges and vertices and so the storage optimizations we’ve made to the graph capabilities in Oracle Database 21c preview release can result in big space and performance improvements for your models.
- Sharding Enhancements : Oracle Sharding enables linear scalability, fault isolation and geo-distribution for hyperscale applications while retaining the flexibility of SQL. To make it easier to develop Java applications against Oracle Sharding we’ve introduced a new Java Data Source that makes it simple to obtain connections without having to define the shard key or manage the connection key explicitly. We have also made sharding more fault-tolerant by automatically looking for alternates if the shard you are working on fails during execution.
- Persistent Memory (PMEM) Support : Oracle Database 21c includes support for PMEM file systems that can offer significant latency and bandwidth improvements over traditional file systems that use SSD or spinning disks. However, the applications using them need to understand how to safely write to them and the most efficient way to use them in conjunction with other OS resources. Oracle Database 21c’s implementation provides atomic writes, safe guarding against partial writes during unexpected power outages. It also offers Fast I/O operations using memory copy. In addition, it efficiently uses database buffer cache by bypassing and reading directly from PMEM storage.
Innovation and Long Term Releases
Oracle Database 21c is an Innovation release for customers to innovate faster with new and enhanced functionality on workload use cases and applications that could benefit accordingly. Customers should be aware that unlike Long Term releases, Innovation releases have a limited support window (typically ~2-years). Therefore, in the interests of maintaining business continuity, customers still running on prior releases (e.g. 11gR2, 12cR1, 12cR2, 18c) are encouraged to upgrade to Oracle Database 19c – the current Long Term release with support through to April 2027.
For the latest Oracle Database 21c availability and support windows on all on-premise platforms (including Exadata) and in Oracle Cloud (including Autonomous Database Services) please refer to MyOracle Support (MOS) note 742060.1.
