Oracle Text and Oracle Globally Distributed Database can be combined to provide a scalable, distributed full-text search solution for JSON documents. This is critical for large volumes of Documents that need to be searched quickly and efficiently while also providing the capability to scale out and distribute the document store across servers.
The advantages of using Oracle Globally Distributed Database as your repository and engine for full-text search include:
- Oracle Database can remain the source of record for data that requires textual search capabilities with the use of Oracle Text, without extracting and continually reconciling data with a third-party search platform.
- Oracle customers using third-party JSON-based search indexes can potentially reduce overall costs by transitioning these indexes into Oracle Database.
- Oracle Globally Distributed Database provides a distributed horizontal scalable database platform that can grow with your document collection and application/service performance needs.
All of this can be achieved with the Oracle Database native JSON support combined with Oracle Text for indexing and search capabilities, along with Oracle Globally Distributed Database to achieve horizontal scalability and help you meet data sovereignty requirements.
In this post, we will outline some of the basic components of this architecture and how a sample deployment would work.
For more detailed guidance and a walkthrough on how to build the Distributed Database, design the schema, load the data and construct the search queries, please refer to a recently published Tech Brief titled: JSON Full-Text Search with Oracle Globally Distributed Database 23ai.
Technologies
This solution combines three Oracle technologies: Oracle Globally Distributed Database, Oracle Text and Oracle’s native JSON support.
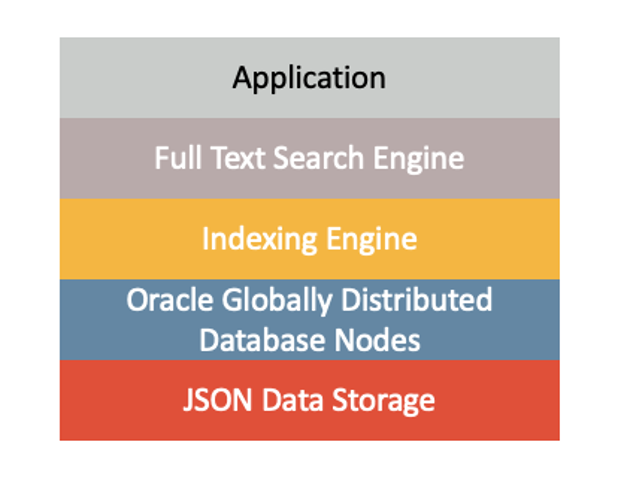
Oracle Database support for JavaScript Object Notation (JSON)
Oracle Database supports JSON natively with relational database features, including transactions, indexing, declarative querying, and views.
Business documents can be stored as JSON documents in a relational table. Each row represents a document with all the content inside the document stored in a column with the JSON datatype.
Oracle Text
External text engines are widely available, but most of them only work with file-based text stores. If your text is in the database to start with, it makes much more sense to use the integrated text engine within the Oracle Database, which supports Text that is stored both within and outside the Oracle Database. Oracle Text is part of all editions of the Oracle Database. Because text is stored in the database, users can get an integrated, holistic view of all their data. Additionally, the database chooses the fastest plan to execute queries that involve both text and structure content.
Oracle Text supports JSON documents. This means that;
- Oracle Text understands and can parse the structure of the documents.
- Oracle Text can use the names and values of the JSON elements within each row’s JSON column data, not just the raw text.
- It provides the ability to score and rank search results and render a “snippet” of the document contents in HTML, with term highlighting to provide context and relevance when the results of the query are processed by the application for display.
Oracle Globally Distributed Database
Oracle Globally Distributed Database enables the deployment of hyperscale globally distributed converged databases. It is the Oracle Database feature that supports application requirements for linear scalability, elasticity, fault tolerance and isolation, and geographic distribution of data for data sovereignty. Oracle Database implements these capabilities by distributing chunks of a data set across independent Oracle databases (shards). Shards can be deployed in the cloud or on-premises and require no specialized hardware or software.
The example we will walk through in this document, uses the “system-managed sharding” method to distribute the data evenly across the shards. There are other data distribution methods available to distribute sharded table data across the sharded database to meet various requirements: User-Defined, Directory-Based, and Composite sharding. These methods provide additional features when the data set needs to be sharded in more purposeful ways, such as to support data residency and other business or regulatory requirements.
Multiple ways to access your Data
Oracle Text supports indexing and search of a variety of document formats. Oracle provides full support for JSON and integrates it into a relational environment. This allows customers to take advantage of consuming and maintaining data already in JSON format as well as using the capabilities of a relational database.
JSON Data Set
Oracle stores JSON within a JSON datatype column of a database table. The JSON documents within this column are fully indexable and searchable. Standard SQL queries can include filter predicates using JSON functions to perform searches within the JSON documents directly.
We assume that all JSON records are stored in the database as individual rows in a large table. Each table is partitioned across the shards but remains one logical table.
Virtual Columns
The advantage of a virtual column is that we can create a column in a relational table as a column derived from the evaluation of an expression on the JSON field in our table.
For example, the Title of a document may be stored as an element within the JSON document stored in the JSON column. The title data can also appear in a standard relational column, perhaps named “title”, with the value automatically derived from the JSON element value. We can use this virtual column in purely relational expressions with the JSON-specific function call details abstracted at the schema level instead of in every query.
Sharded Data Distribution Methods
There are multiple methods for partitioning the data across the sharded databases in your topology.
System-managed sharding requires only that a column be declared as the “sharding key”. Beyond that, the user does not need to specify the mapping of data to shards. Data is automatically distributed across shards using partitioning by consistent hash of the values of the shard key. The partitioning algorithm evenly and randomly distributes data across shards. The distribution used in system-managed sharding is aptly named as it is intended to eliminate hot spots and provide uniform performance across shards and automatically maintain the balanced distribution of the data when shards are added to, or removed from a sharded database.
In our use case:
- The data and use-cases do not include any specific business or technical requirements for correlating and grouping specific records to the same shard.
- Each document record is independent of any other.
- All document records can be re-sharded to any other shard if the sharded database needs to be scaled-out to increase performance.
If there were some correlations, such as a common account with multiple sales invoices, or a requirement for Data Sovereignty where records must be sharded together based on a country code or other regional field value, then other sharding methods would be appropriate.
Example: Wikipedia Articles Full Text Search
Let’s walk through an example of how a JSON data set can be loaded into a schema design and used as a basis for full-text search queries.
The JSON Data Set
For our example, we use a JSON representation of the public Wikipedia Articles English-language data set (“enwiki”). We chose Wikipedia because it provides both a publicly available dataset and the precise full-text search use-case we’re interested in. Although not originally in JSON format, we converted the enwiki articles data file to JSON for use in our example. The latest “enwiki” data dump files in XML format can be downloaded from https://dumps.wikimedia.org/enwiki/latest/.
The converted JSON data file was altered to remove some JSON elements from each record.
Below is a short example document representative of the JSON elements in our sample data set.
Wikipedia enwiki Article – Synthetic Example
{"title": "MAA Demo Intro Article ",
"wikiTitle": "MAA_DEMO_INTRO_ARTICLE",
"wid": 999019999,
"lang": "EN",
"timestamp": "2022-06-21T05:22:00Z",
"paragraphs": [
"This is the first paragraph of the MAA Demo Intro Article test document for database sharding. This is the second sentence of the first paragraph",
"This is the second paragraph. There are multiple lines each with multiple sentences.\nA second line in the second paragraph.",
"With Regards to the Data structure of each document:\n",
"The .wid element is unique per article and extracted for use as the shard key and primary key in the Articles table.",
"There may be hundreds of strings in the .paragraphs array with up to 4kb per string.",
"The longest article is over 440kb.",
"The .categories array .id element contains the actual category term with spaces replaced with underscore and prefixed with the phrase: Category:."
"The .templates array contains various metadata about the article with each .name element being the key and corresponding .description array containing the value."
],
"categories": [
{
"id": "Category:Database_Sharding",
"anchor": "database sharding", "start": 71, "end": 88, "type": "CATEGORY"
},
{
"id": "Category:MAA_Demo_Article",
"anchor": "", "start": 0, "end": 0, "type": "CATEGORY"
},
{
"id": "Category:Facet B",
"anchor": "", "start": 0, "end": 0, "type": "CATEGORY"
}
]
}
Analyzing the JSON Data for Schema and Query Design
Let us look at the JSON fields in order to evaluate how they might be used in constructing our associated database table. Certainly, one option is to load the JSON-as-is into a JSON datatype and begin constructing queries. But the power of the Oracle database is that we can also convert some of the JSON fields into columns in a relational table.
wid
This JSON element contains the unique ID for each article consisting of a 1 to10-digit number. We will be using this value as the basis for the Article_ID column which will be the Primary Key for the Articles table and the Shard Key for the table family.
Title
The title JSON element value for each article is useful for both search filtering and results presentation. Implementing a virtual column allows us to include this value in the select clause without the complexity of additional JSON_VALUE() function calls in every query. From a search query filter predicate perspective, we will use the JSON_TEXTCONTAINS() function using the JSON column directly to perform the full-text search using the Oracle Text index.
Paragraph[] Array Data
The JSON document’s paragraph array contains comma-separated quoted strings. This comprises the bulk of the article content and is used along with Title in the main search results query as primary source data fields for the requested keywords string search predicates. The paragraph array is searched using the JSON_TEXTCONTAINS() function, and the execution of this function is optimized to use the available Oracle Text search index.
The paragraph JSON element value is also used with an Oracle Text function called ctx_doc.policy_snippet() in the SELECT clause of our main search results query to return a short section of contextually relevant document text with the search terms highlighted in HTML format.
Categories[] Array Data
In Wikipedia, the category assignments to articles are a many-to-many relationship.
The categories data serves as a useful example to demonstrate how to perform a faceted search aggregation query using JSON array-based values. In the full-text search user experience, presenting a faceted search capability includes querying for an aggregation, or count, of results based on an associated value that provides a meaningful grouping. These groupings are referred to as “buckets” and the collection of buckets for a given piece of associated data or metadata is called a “facet”.
Typically, the user is presented with a list of buckets for one or more facets and allowed to refine their search parameters by choosing a subset of buckets to use as a filter for the search results.
Lang
This JSON element contains the ISO 639-1 short code for a 2-char regional language name.
To allow the use of simple relational search predicates and efficient query of these values, we chose to implement a Virtual Column for this element in our relational schema. This avoids repeated use of the JSON function calls in application code, simplifies the query syntax, and allows the database to efficiently optimize the SQL execution.
Timestamp
This element contains the last-modified date string for each article document. The “timestamp” format in article data does not directly match an Oracle Timestamp format but is easily cast to the timestamp_tz data type.
This is a perfect example of the efficiency provided by virtual columns. The data type conversion can be configured once in the schema definition rather than in every client-side query needing the last-modified timestamp value.
Designing and Creating the Database Schema
With all of the above in mind, we create a single table named “Articles” as the parent table in our sharded table family. The Articles table contains an ID column as the primary key and sharding key, the Article_JSON column, and four virtual columns based on the Articles_JSON column content as described above.
The following SQL statement creates a sharded table with a column to store our JSON as well as the virtual columns Title, Wiki_Title and Lang described earlier.
Example: Create Sharded Articles Table
SQL> CREATE SHARDED TABLE Articles
(
Article_JSON JSON NOT NULL,
Article_ID VARCHAR(10) NOT NULL,
Date_Loaded TIMESTAMP(6) DEFAULT SYS_EXTRACT_UTC(SYSTIMESTAMP) NOT NULL,
Title VARCHAR(512) AS ( JSON_VALUE(Article_JSON, '$.title'
returning varchar(512)
null on error null on empty) ),
Wiki_Title VARCHAR(512) AS ( JSON_VALUE(Article_JSON, '$.wikiTitle' title'
returning varchar(512) )
null on error null on empty) ),
Lang VARCHAR(2) AS ( JSON_VALUE(Article_JSON, '$.lang'
returning varchar(2)
null on error null on empty) ),
Last_Modified TIMESTAMP(0) WITH TIME ZONE
AS ( TO_TIMESTAMP_TZ(
JSON_VALUE(Article_JSON, '$.timestamp'
null on error null on empty),
'YYYY-MM-DD"T"HH24:MI:SS TZH:TZM') ),
PRIMARY KEY (Article_ID)
)
TABLESPACE SET tsp_set_wikip
PARTITION BY CONSISTENT HASH (Article_ID) PARTITIONS AUTO;
Oracle Text Index
To enable full text searching of the JSON content, we create an Oracle Text search index on our JSON column. First, we create the text preferences as desired, before creating the index. Oracle Text indexes can be tuned to meet your specific needs by setting any necessary preference attributes. Oracle Text preferences are defined once and applied consistently across all shards.
For full documentation, see the JSON Search Index for Ad Hoc Queries and Full-Text Search section of the JSON Developers Guide, and the Creating Oracle Text Indexes section of the Oracle Text Application Developer’s Guide.
Example: SQL for creating the Oracle Text Preferences
-- sys.exec_shard_plsql() is called to propagate the pl/sql to each shard
begin
sys.exec_shard_plsql('ctxsys.ctx_ddl.create_preference(''wl'', ''BASIC_WORDLIST'')');
sys.exec_shard_plsql('ctxsys.ctx_ddl.set_attribute(''wl'', ''FUZZY_MATCH'', ''ENGLISH'')');
sys.exec_shard_plsql('ctxsys.ctx_ddl.set_attribute(''wl'', ''FUZZY_SCORE'', ''60'')');
sys.exec_shard_plsql('ctxsys.ctx_ddl.set_attribute(''wl'', ''FUZZY_NUMRESULTS'', ''5000'')');
sys.exec_shard_plsql('ctxsys.ctx_ddl.set_attribute(''wl'', ''WILDCARD_INDEX'', ''TRUE'')');
end;
/
Once the Oracle Text wordlist preferences are set, create the Oracle Text search index.
Example: SQL for creating an Oracle Text Index
SQL> create search index articles_idx on Articles(article_json) for json
parameters (' wordlist wl
search_on text_value_string
memory 170M
maintenance auto
optimize (auto_daily parallel 1)
')
parallel 6
local;
Search Query Design and Example
A fully realized text search application might include several capabilities for filtering and refining search requests. In this example, we outline some use-cases, a mock-up of a UI design, and discuss some of the user-experience that would feed into the design of the SQL queries necessary for implementation.
Use-Cases
Here are some example application text search use-case scenarios
- Basic Search Terms Only
Submit a simple text search phrase without any additional filters.
- Date Filtering
Configure one or both date filters in addition to the search term and submit.
- Faceted Search
Refine the search parameters by selecting from lists of available Categories and/or Languages
- Paging through results
Click the search results page navigation links to change the page of results displayed.
- Results page size customization
Update the preferred page size in the search results panel.
- Document View
Click on a search result link for a specific document to be presented with a rendered view of the JSON document.
Example Search Form
An example search form prototype is shown below. This design includes basic text search functionality, date filtering, and faceted search based on the categories and languages for the documents. The aggregated facet selection lists should only populate after an initial search by keyword is submitted. Any submitted dates would limit both the search results and the faceted search. Pagination parameters are provided for customization. The page size and current page number are used in the search results query to limit the data retrieved per request.
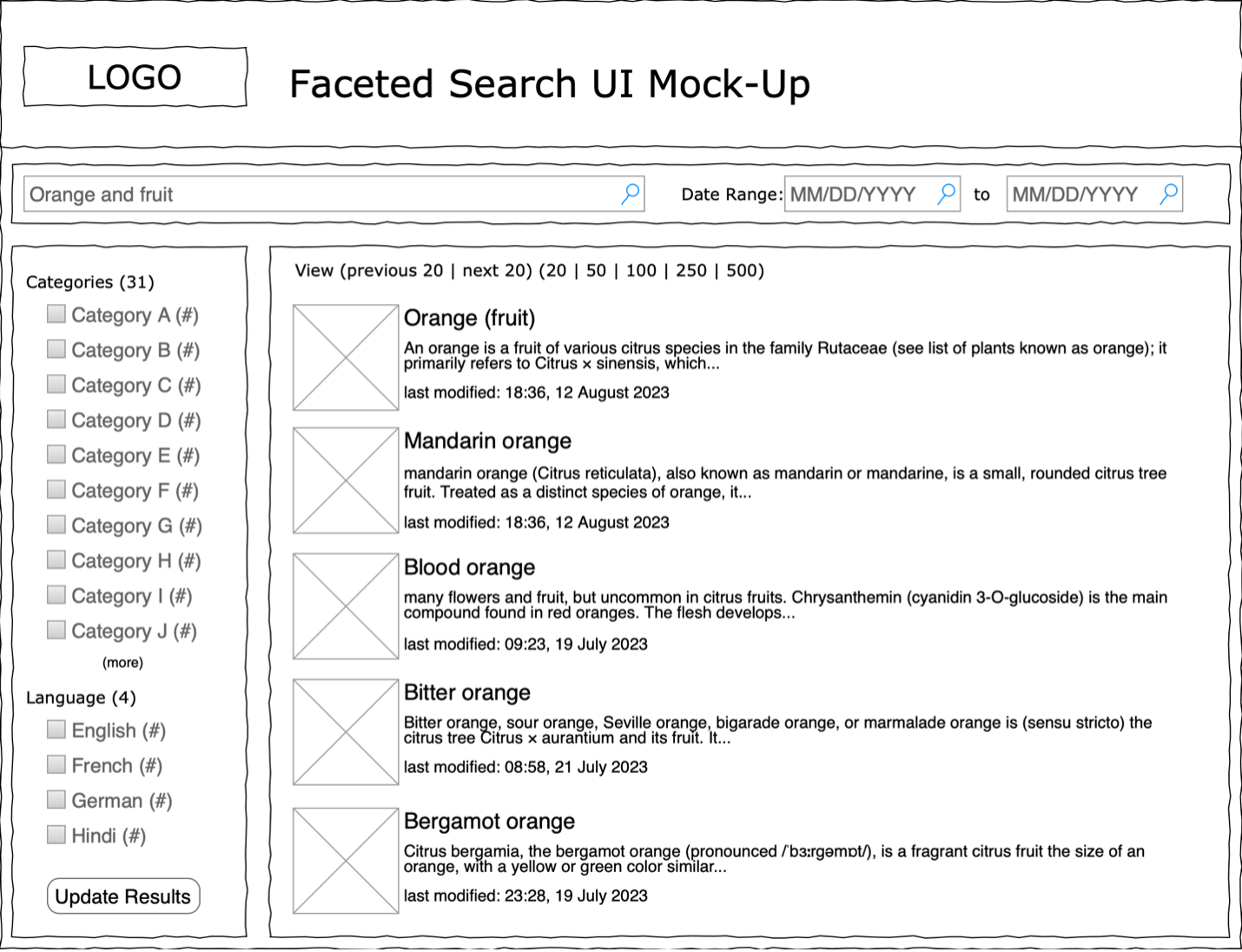
Search Form Layout and Parameters:
The UI contains three panels with several form parameters.
- Horizontal search bar with three form elements: the search term, and the start and end dates
- Left-hand search filter panel, containing form elements for two ‘faceted’ search filters:
- By Categories, for example ‘Orange Cultivars’
- By Language, for example ‘English’
- Right-hand search results panel
- Displays a partial list of search results sorted by the Oracle Text “score” ranking
- Each search result may display:
- Title
- Text Snippet containing the search term(s)
- Last Modified date
- The search results score (optional, not shown here, use for sorting only)
Sample SQL
When the user submits a query in the above search UI form, this drives a fixed SQL query with bind variables based on user input. The initial search query is a “multi-shard query” that searches for results across the entire sharded database. All multi-shard queries are submitted to the Coordinator that accesses the Shard Catalog database.
Our example search query selects data from both the virtual columns and from the JSON column, using Oracle Text to retrieve the required results. In addition to the basic selection of the article ID and title (virtual column) data, the query returns ranked search scores and a relevant short snippet of HTML of each document’s contents for each search result.
The query includes filter predicates using JSON functions that parse the paragraph and title JSON element values from the JSON column data to match the keyword search terms and score each result. This processing is optimized for use with the Oracle Text search index. This offloads much of the result set processing from the application, allowing the query to return the relevant rows with a short contextually relevant snippet of the document content, properly ranked and sorted directly within the database.
There are two sections to the query below:
- The inner SELECT statement returns all matching rows, sets the search rank scores, and constructs the document snippet content. These “inner” query operations are sent in parallel to each shard for processing from the Coordinator.
- After the inner query operations are completed and data returned to the Coordinator, the outermost SELECT statement operations for the final sorting and filtering of the result set are executed on the combined data set from all of the shards for paging purposes.
Example: Scored Search Results Query – simple text search only
SELECT /*+ QB_NAME(qb_searchres_pg) */
article_id,
title,
doc_snippet,
search_score
FROM (
SELECT /*+ QB_NAME(qb_searchres) DOMAIN_INDEX_SORT FIRST_ROWS(100) PARALLEL(4) */
a.article_id,
a.title,
greatest(score(1),score(2)) AS search_score,
ctx_doc.policy_snippet('articles_idx',
json_serialize(a.article_json.paragraphs RETURNING clob),
'&s_searchterm') AS doc_snippet
FROM articles a
WHERE
JSON_TEXTCONTAINS(a.article_json, '$.title', '&s_searchterm', 1)
OR JSON_TEXTCONTAINS(a.article_json, '$.paragraphs', '&s_searchterm', 2)
ORDER BY
GREATEST(score(1),score(2)) DESC
)
OFFSET &n_pgoffset ROWS FETCH NEXT &n_pgrows ROWS ONLY;
Example: Scored Search Results Data Returned
ARTICLE_ID TITLE DOC_SNIPPET SEARCH_SCORE
---------- ------------------------ ---------------------------------------------------- ------------
191214 Mandarin orange Short_description, Small citrus <b>fruit</b>]\nTEMPL 100
ATE[speciesbox, name = Mandarin <b>orange</b>, image
= Citrus reticulata April<b>...</b>mandarine, is a
small citrus tree <b>fruit</b>. Treated as a distinc
t species of <b>orange</b>, it is usually eaten plai
n or in <b>fruit</b> salads.TEMPLATE[cite
58875 Maclura pomifera Osage <b>orange</b>, image<b>...</b>caption = Foliag 100
e and [[multiple <b>fruit</b>]], genus = Maclura, sp
ecies<b>...</b>commonly known as the Osage <b>orange
</b>, horse apple, hedge, or hedge<b>...</b>15, m, f
t, -1] tall. The distinctive <b>fruit</b>, a multipl
e <b>fruit</b>, is roughly spherical, bumpy
68763241 Worldwide breakfast and fresh <b>fruit</b>, including<b>...</b>accompani 100
ed by coffee, tea and <b>orange</b> juice. A typical
Israeli meal<b>...</b>and drink milk, hot chocolate
or <b>fruit</b> juice. Japanese adults (especially
younger<b>...</b>They often drink coffee or <b>orang
e</b> juice. Traditional Japanese inns
Conclusion
This solution demonstrates how Oracle Database can natively provide full-text search at massive scale using Oracle’s native query capabilities through the combination of OracleText Indexes, JSON Search capabilities and Oracle’s Globally Distributed Database architecture. The power of this solution provides the opportunity to:
- Reduce application complexity with a single connection model for data and search requests.
- Reduce operational costs by eliminating requirements for other third-party document stores and search engines
- Meet data sovereignty requirements and scale-out to support massive data sets and extreme workloads
- Leverage the High Availability inherent to Oracle Database solutions.
In this post, we have briefly outlined the basics of how to construct an Oracle Full-Text JSON Search engine on Oracle Globally Distributed Database. For detailed guidance, tips, and a complete walkthrough of this solution from the ground up, including: building the distributed database, designing the schema, loading the JSON data, and constructing the search queries, please refer to the Tech Brief titled: JSON Full-Text Search with Oracle Globally Distributed Database 23ai.


