Introduction
InfStones is an enterprise-grade Platform as a Service (PaaS) blockchain infrastructure provider that is trusted by top blockchain companies around the world. The Oracle Autonomous JSON Database (AJD) is a fully managed OCI service for building and deploying scalable applications that primarily need to store JSON data (aka JSON documents) in the Cloud. In this, post we will describe how InfStones was able to leverage AJD to build a low-latency query service over billions of blockchain records.
InfStones’ AI-based infrastructure provides developers worldwide with a rugged, powerful node management platform alongside an easy-to-use API. With over 15,000 nodes supported on over 60 blockchains, InfStones gives developers all the control they need – reliability, speed, efficiency, security, and scalability – for cross-chain DeFi, NFT, GameFi, and decentralized application development. InfStones is trusted by the biggest blockchain companies in the world including Binance, CoinList, BitGo, OKX, Chainlink, Polygon, Harmony, and KuCoin, among a hundred other customers. InfStones is dedicated to developing the next evolution of a better world through limitless Web3 innovation.
When building a new set of query services, InfStones had the following database requirements:
-
Low-management: They wanted a managed database solution where they would not have to manually do administrative tasks like database backups, patching, and other server maintenance. And they wanted a secure-by-default database where they would not have to configure certificates, encryption settings, or worry if their database configuration was secure enough.
-
Low-latency: The service provided to their end-users needs to support ad-hoc queries that return in milliseconds. Their end-users may use the results to support interactive, real-time applications so response time is critical.
-
Scalable: The data sets backing their service contain billions of documents and new data is ingested continuously. At the same time, the InfStones platform continues to grow as new users access their platform. They needed a database that could automatically scale both storage and compute capacity as they grew.
-
Flexible development options: The engineering team was primarily writing application code using Google Go and they preferred to interact with this dataset as a simple JSON collection using the MongoDB Go Driver.
AJD was an obvious choice as it met all requirements while significantly reducing database compute costs. After only a few months of development, the new InfStones query processing services are now in production and executing millions of requests each day.
Architecture

The above diagram describes the main components of the InfStones query processing service. This architecture is used for several different block chains including BSC, OKC, and Ethereum. Historical transactions were initially loaded into AJD using mongoimport. For BSC, for example, this resulted in a starting collection with about 2 billion JSON documents. The Data Manager is a background process that periodically loads new transactions as they occur. In the case of BSC, it loads about 100 rows every three seconds. Each transaction document is roughly 100 bytes and has the following structure:
{
"_id": "6275561be8e4de7b67280cf7",
"blockNumber": 14090932,
"address": "5C15e82yIRvkFj+n",
"data": "0x00000000000000000000000080372346523562456342345634562341534511",
"transactionIndex": "0x4",
"transactionash": "0xdedcb68e1023982345129C306d85768ee579f",
"blockHash": "0x69387e811a0a442e1574ac05d783e42c7c73627d22342b39435089296",
"removed": true,
"logIndex": "0x0",
"topic0": "0x000000000000000000000000803734dddb64c4392910b5ae0a2923733ab1c6b0",
"topic1": "0x00000000000000000000000016d1160c4dddb64c4733b5ae0a2923733ab1c6b0",
"topic2": "0x000000000000000000000000935a2252803734d682b8f64cfbf0fdb17797f586"
}
SQL was used to create function-based indexes like the following:
CREATE INDEX ADDR_BLOCK_IDX ON collectionTable (
json_value(data, '$.address.string()' ERROR ON ERROR) asc,
json_value(data, '$.blockNumber.number()' ERROR ON ERROR) desc
);
CREATE INDEX BLOCK_IDX ON collectionTable (
json_value(data, '$.blockNumber.number()' ERROR ON ERROR) desc
);
These indexes support queries on address, blockNumber, or both address and blockNumber. The “ERROR ON ERROR” clause causes an error to be raised if incoming data doesn’t match the expected type (in this case string or number). The ONLINE option could have been added when creating these indexes but it was not necessary as the indexes were created in advance.
The distributed query service is written in Google Go and it issues filter expressions against the collection using the Oracle API for MongoDB and the MongoDB Go driver. For example:
filter := bson.M{"blockNumberInt": bson.M{"$gte": fromBlock, "$lte": toBlock}}
filter["address"] = bson.M{"$in": userRequest.Address}
findOptions.SetHint(indexName)
findOptions.SetBatchSize(BATCH_SIZE + 1)
cursor, _ := collection.Find(context.TODO(), filter, findOptions)
The query service exposes a REST interface to InfStones end users, allowing them to submit ad-hoc queries against the dataset. Examples of queries include:
- Select transactions with blockNumber values within a specified range
- Select transactions with blockNumber values within a specified range, having a specific address value.
- Select transactions with a matching topic
Because the dataset is so large, these queries must be index driven as scanning the entire dataset serially can take hours or even days. The result size of the queries is limited to 10,000 rows in order to limit the amount of data that is sent to the end user to around 7 mb. Overall, InfStones executes around 75 million requests across their databases each month.
Lessons Learned
Working with billions of documents while supporting fast range queries with large result sets created a unique set of challenges that are typically not encountered with smaller datasets. Additionally, a goal was to use the database as efficiently as possible: just throwing more hardware at a problem is an easy but expensive solution. The remainder of this post, therefore, shares some of the techniques used while developing the InfStones query processor. Most of the techniques shared here are not only relevant to AJD but also to Oracle Database in general.
Creating indexes
Operations that need to process all 2 billion rows, such as adding a new index, can take hours or even days if done using a single processor. InfStones relied on the ability of AJD to scale up compute capacity temporarily and use parallel processing to greatly reduce the time required to create indexes. That is, for normal operations, only 2 OCPUs are needed to support the workload described above, but when creating an index, the database would be temporarily scaled up to 40-100 OCPUs. This was done manually from the AJD Console and without incurring any database downtime.
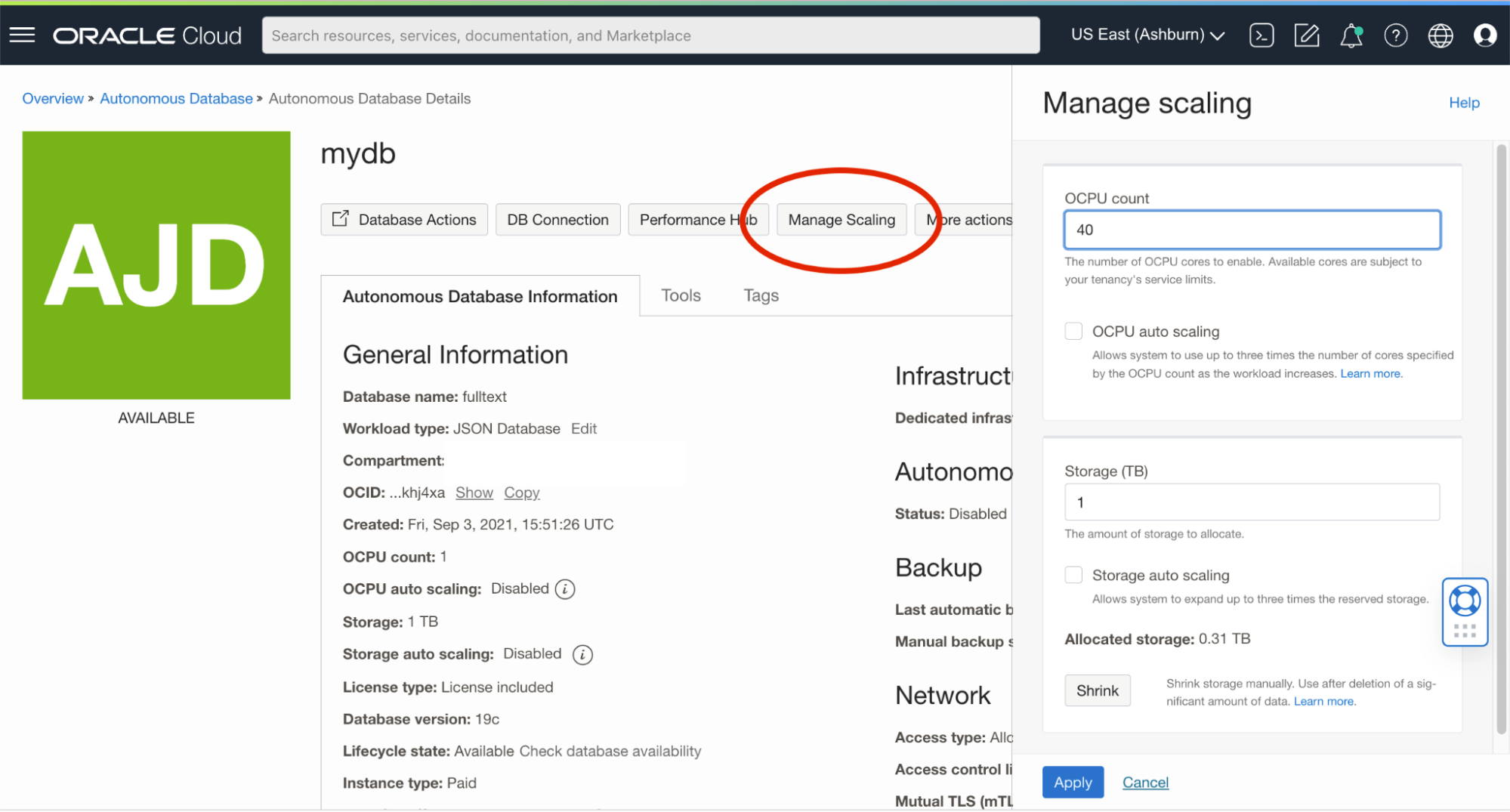
This screenshot shows where the scale can be changed in the database console (this can also be changed programmatically). Once the database is scaled up to use more OCPUs, the index is created from SQL using the HIGH consumer group.
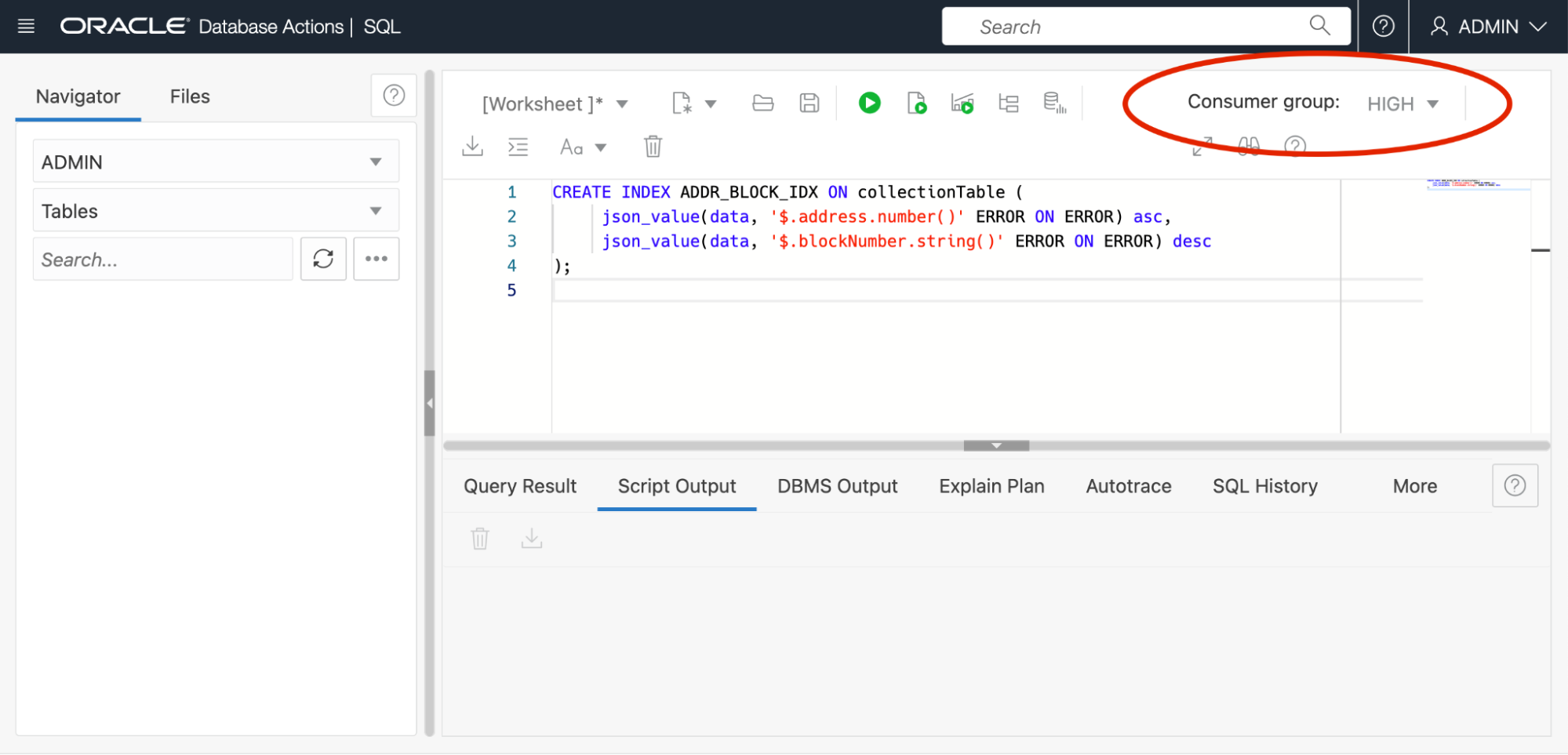
This screenshot shows where the consumer group can be selected in Database Actions. Using the HIGH consumer group ensures that the index is created in parallel. Once the index has been created, the database is scaled back down. Billing increases for the additional OCPUs only for the time they are allocated. See more on consumer group settings here: https://docs.oracle.com/en/cloud/paas/autonomous-database/adbsa/service-names-tranaction-processing.html
Transforming Data
At some point after the initial collection was loaded, a decision was made to change the structure of the JSON data – fields were renamed and an unnecessarily nested object was eliminated. To perform bulk transformations on the data, the most efficient way found was to make a modified copy of the collection using the SQL/JSON function JSON_TRANSFORM.
First, an empty collection was created using the JSON page in Database Actions.
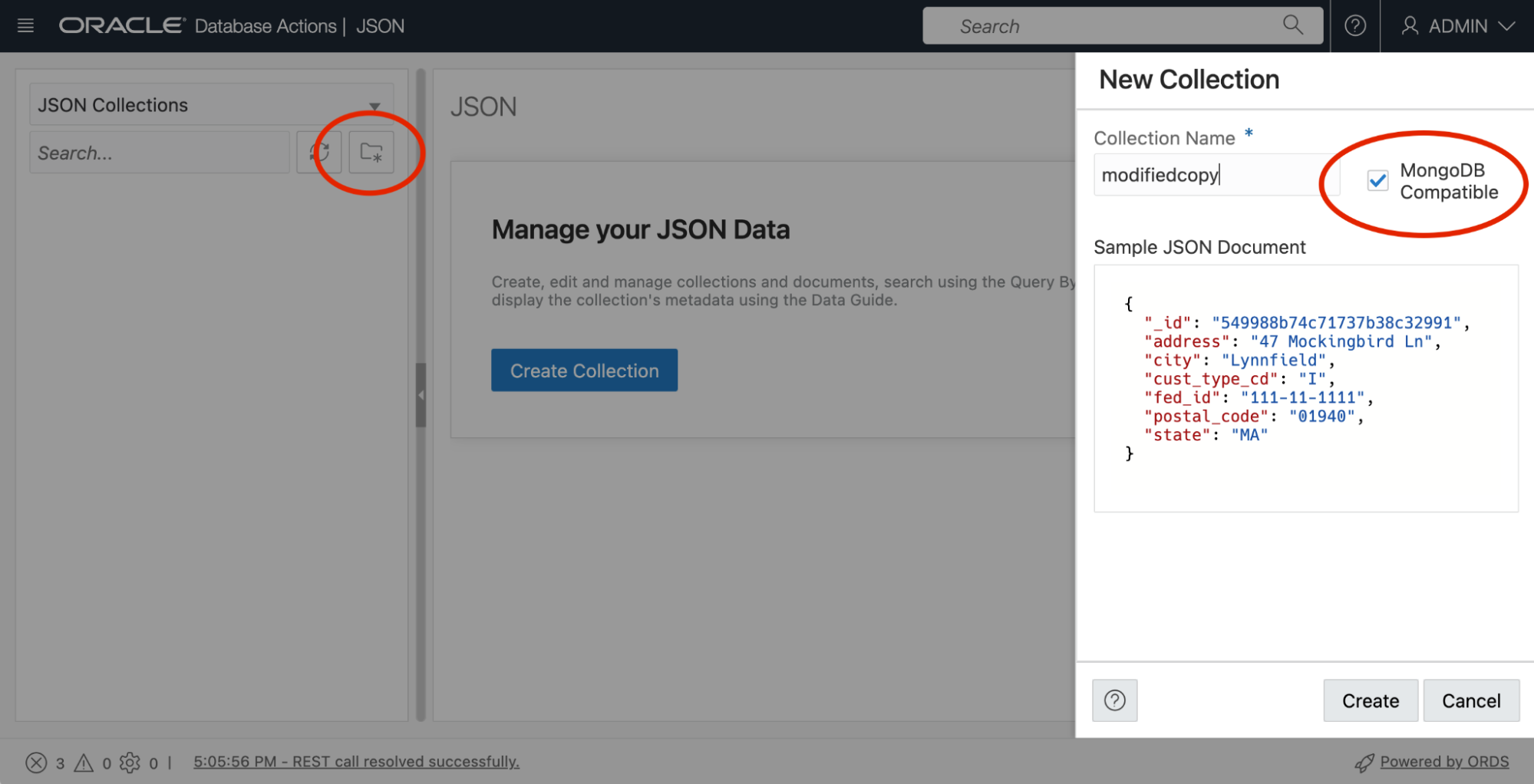
This screenshot shows the JSON page where a new empty collection can be created. The empty collection could alternatively be created from a MongoDB client or tool. After creating the empty collection and scaling up the database, a SQL “insert as select” was executed, again using the HIGH consumer group for optimal parallel execution.
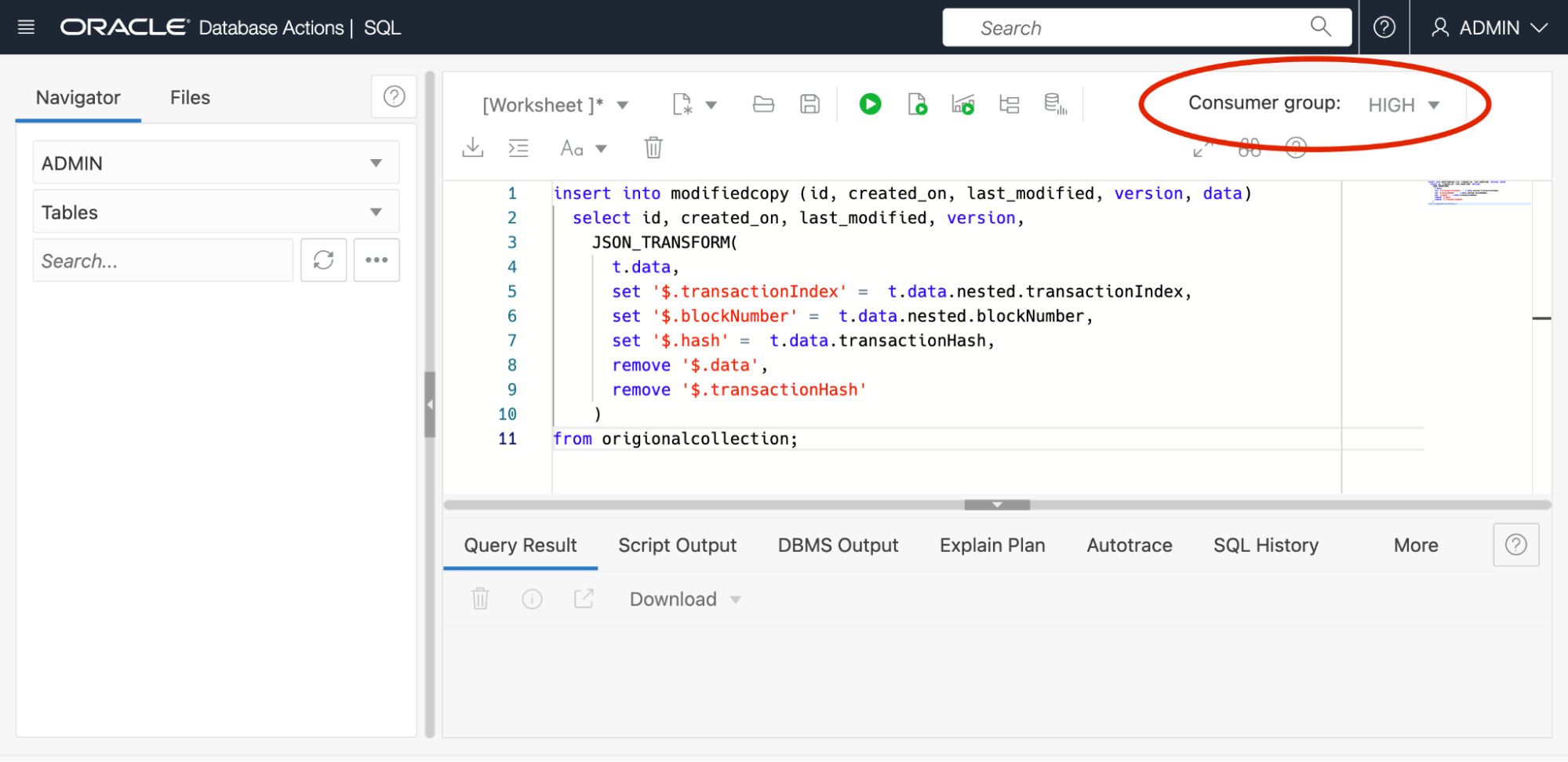
The query in the screenshot above shows a JSON_TRANSFORM query that is used to insert a modified copy of the data into a second collection. Then the application is then updated to refer to the new collection and the old one is dropped. Creating a modified copy in this manner was more efficient than attempting to update the data in-place.
Using SQL Monitoring and Hints
The query service mainly interacts with the database using the Oracle API for MongoDB. However, at a lower level, all MongoDB commands received are translated into Oracle SQL statements. Database Actions includes a Performance Hub page that allows you to monitor the execution and performance of any SQL statement, including those executed as a result of commands sent using the Oracle API for MongoDB.
The InfStones query processor must support many concurrent users and queries at once. At this data scale, these operations need to be index driven or use parallel query processing in order to execute quickly. During the development, occasionally either a SQL statement or a MongoDB command would be executed serially that wasn’t able to use an existing index. Even with Exadata Smart Scan and OSON in-place query evaluation, the operation would still seem to hang as it scanned all 2 billion rows, potentially taking hours or days depending on the operation. The Performance Hub was used in such cases to see the query plan being used and potentially kill the long-running operation.
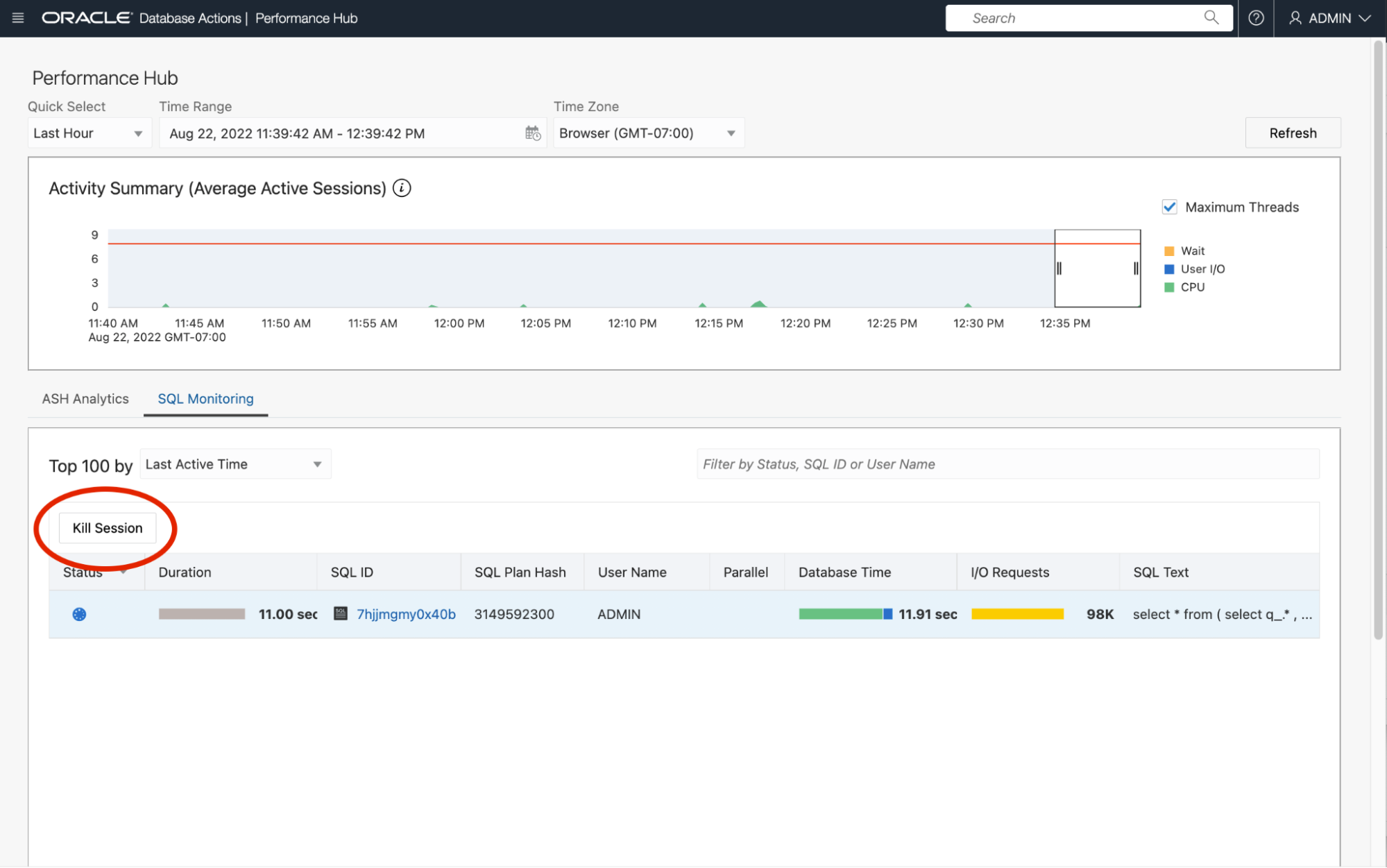
This screenshot shows the Performance Hub page of Database Actions. In this case, one SQL statement is actively being monitored. Statements will be picked up by SQL monitoring if the MONITOR hint is used or the query takes longer than three seconds to execute. From the Mongo API, the $native hint can be used to pass the MONITOR hint to the commands that run in less than 5 seconds.
filter := bson.M{"blockNumber": bson.M{"$gte": fromBlock, "$lte": toBlock}}
filter["address"] = bson.M{"$in": userRequest.Address}
findOptions := options.Find()
findOptions.SetLimit(RESULT_LIMIT + 1)
findOptions.SetHint(bson.M{"$native": "MONITOR"})
findOptions.SetBatchSize(BATCH_SIZE + 1)
cursor, _ := collection.Find(context.TODO(), filter, findOptions)
This can be useful for diagnosing performance issues that take less than three seconds. The $native hint passes the specified text directly to the underlying statement as a SQL hint.
Hinting can also be used to force index pick-up, as shown in the following example:
filter := bson.M{"blockNumber": bson.M{"$gte": fromBlock, "$lte": toBlock}}
filter["address"] = bson.M{"$in": userRequest.Address}
findOptions := options.Find()
findOptions.SetLimit(RESULT_LIMIT + 1)
indexName := "BLK_IDX"
findOptions.SetHint(indexName)
findOptions.SetBatchSize(BATCH_SIZE + 1)
cursor, _ := collection.Find(context.TODO(), filter, findOptions)
Optimizing Response Time for Large Range Queries
One of the goals of InfStones was to keep query response time well under one second in all cases. However, initially range queries with larger results were sometimes taking longer than a second the first time the query was run. Running exactly the same query again would be much faster but the initial “cold” run was sometimes over a second. We examined the SQL monitoring report for the cold run:
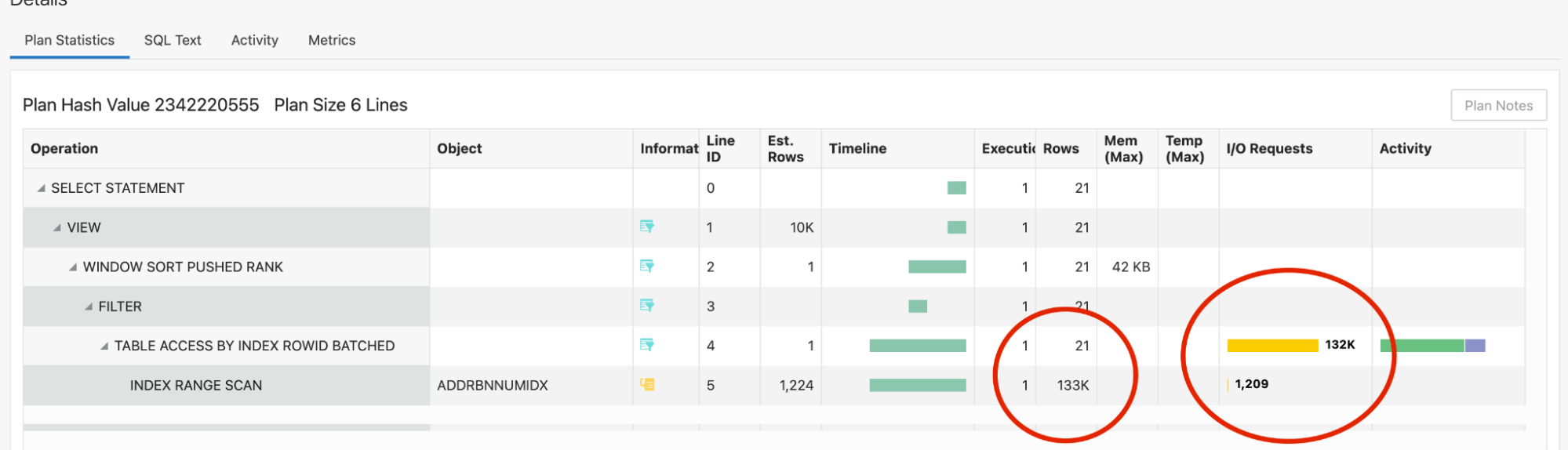
What we observed is that even though the query plan was optimally using an index to perform the range scan, each row retrieved was incurring a physical I/O request. In this particular case, the query produces 133k rows (roughly 13MB of data) and incurs 132K physical IOs (each is IO is 8KB). The rows selected by the index were each pointing to different data blocks. When the query is run a second time, over exactly the same range of the data, it will be much faster (milliseconds) as the relevant data blocks were already in the buffer cache. For smaller datasets, an option to improve performance in this case would be to increase the available memory so that subsequent queries have a higher likelihood of having the relevant blocks paged into memory already. However, for a dataset this big, it is not feasible to cover enough of the data in memory. Instead, the solution we chose was to organize the data along the index being used. In this case, the range scan was on a composite index on attributes “address” and “blockNumber”. We recreated the dataset so that it would be stored in order of these attributes.
insert into newCollection (id, created_on, last_modified, version, data)
select id, created_on, last_modified, version, data
from oldCollection t
order by t.data.address.string(), t.data.blockNumber.number()
In this new collection, since the data is organized along the attributes of the index, range scans will get roughly 8 documents per physical IO (data blocks are 8k and the blockchain documents are on average 100 bytes). This reduces the overall physical IO by a factor of 8x and consequently keeps query times well under 1 second even when none of the data is in memory at the time the query is executed. Since the blockchain transactions are not modified after they have been inserted, there is no risk of the data becoming unorganized over time.
As new data comes in, we need to ensure that it is stored such that data along this index tends to be co-located in data blocks. Given that blockNumber values are chronologically increasing, we decided to additionally partition the table by the creation timestamp for newly inserted data:
alter table collectiontable modify
partition by range (CREATED_ON)
interval (interval '1' day) (
partition p1 values less than (to_date('2022-06-21','YYYY-MM-DD'))
);
This ensures that data loaded on any given day will be in the same set of data blocks. This design allows the query service to provide millisecond latency for ad-hoc queries over 2 billion rows with minimal database compute and memory resources.
Conclusion
Using modern development techniques and the Autonomous JSON Database, InfStones was able to bring their query processing services from conception to production within only a few months. The Autonomous JSON Database eliminated time-consuming management (DBA) tasks that often distract developers from their core work. From a performance point of view, the InfStones query processor is able to provide millisecond response times for 10s of millions of queries per week over billions of JSON documents with only 2 OCPUs allocated to each database. AJD, therefore, turned out to be a cost-effective solution (OCPU cost of $0.32 X 2 = $0.64 per database per hour). As the data and the number of queries and/or users grow, AJD can easily and gradually scale up both compute and storage without downtime.

