If you google “rag knowledge graphs” you will find numerous articles and videos extolling the benefit of combining RAG and “Knowledge Graphs”. This benefit mainly comes from making relationships EXPLICIT rather than implicit. We will see how a graph data model can help represent explicit relationships and examine how that can be done with two popular graph models, Property Graphs and RDF Knowledge Graphs. Oracle Graph supports both models.
To make things confusing, in the fast moving world of genAI people call Property Graphs as Knowledge Graphs but they don’t mean RDF Knowledge Graphs. Many Property Graph vendors highlight how Property Graphs can represent Knowledge Graphs.
Almost all corporations store data in relational databases as tables like this,
| MOVIE_GENRE Table |
||
| ID |
Title |
Genre |
| M1 |
The bird cage |
Comedy |
| M2 |
Oliver |
Musical |
A better database design for this would be to have two tables, one for movies and one for genres like this,
| MOVIE Table |
||
| ID |
Title |
Genre |
| M1 |
The bird cage |
G1 |
| M2 |
Oliver |
G2 |
| GENRE Table |
|
| ID |
Type |
| G1 |
Comedy |
| G2 |
Musical |
In these two tables, there is a relationship between a movie and its genre, and that relationship is captured IMPLICITLY by the Genre column in the movie table. Data and implicit relationships can be stored in relational databases in this way.
We will see how to define relationships explicitly using Property Graphs (with the SQL/PGQ standard) and RDF Knowledge Graphs and the pros and cons of each. But more importantly, we will see that modeling concepts in addition to explicit relationships will be necessary for a proper integration of RAG and Knowledge Graphs. The future still holds a lot of changes for this area, best not to lock yourself into a single solution too early.
1. GenAI RAG and Graphs
What if instead of using tables, we stored data using nodes and edges like this,
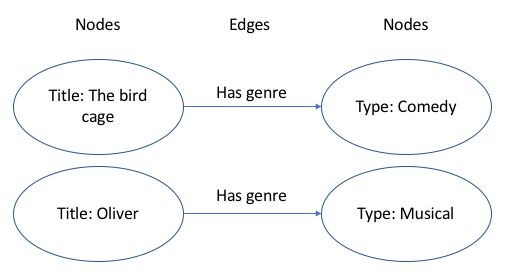
Now the genre relationship is EXPLICIT as a “Has genre” edge. This is what genAI RAG likes, explicit relationships, especially long chains of explicit relationships, which are very difficult to deal with in relational databases. Data and EXPLICIT relationships can be stored in what is called a Property Graph database. It can also be stored in an RDF Knowledge Graph database.
2. GenAI RAG and SQL/PGQ
In 2023 an ISO standard for Property Graphs called SQL/PGQ (SQL/Property Graph Query) was defined, see here and here. The great thing about SQL/PGQ is that it makes a relational database look like a Property Graph, which means existing data doesn’t need to be moved into a separate database in order to expose explicit relationships to genAI RAG. In the Oracle Database implementation, the Property Graph is like a view on existing tables, so the data doesn’t even have to be moved to a separate schema. Here’s how it works.
Assume we have the two tables (Movie and Genre) shown at the beginning of this blog. Using SQL/PGQ define the explicit relationships as follows:
- create property graph explicit_relationship_pg
- vertex tables (
- movie
- key (id)
- label movie
- properties all columns,
- genre
- key (id)
- label genre
- properties all columns
- )
- edge tables (
- movie as gives_genre
- key (id)
- source key (id) references movie (id)
- destination key (has_genre) references genre (id)
- label has_genre
- properties all columns
- );
Lines 2 – 11 define the nodes (vertexes), lines 12 – 19 defines the edges. Now a query like the following can be used in a genAI prompt,
- select ‘Movie’ as label, t.*
- from graph_table (explicit_relationship_pg
- match
- (m is movie) -[c is has_genre]-> (g is genre)
- columns (m.title as title,g.type as type)
- ) t
- order by 1;
Lines 3- 5 are similar to the pattern specification syntax in any graph language, here they are wrapped inside a SQL query.
Oracle Database has the first implementation of SQL/PGQ.
The problems with this approach are:
- GenAI doesn’t understand SQL/PGQ yet, as it is a new standard.
- Explicit relationships can’t be inserted using SQL, as the standard does not yet include INSERT/UPDATE/DELETE for graphs. GenAI would need to be trained for this also.
3. GenAI RAG and RDF Knowledge Graphs
There is another standard, the W3C Resource Description Framework (RDF) that can be used for implementing explicit relationships. Here’s how the movie example would be defined in an RDF Knowledge Graph. (For something more complete, see the family tree example in the Oracle RDF Graph documentation.)
- :M1 rdf:type :Movie .
- :M1 :name “The bird cage” .
- :G1 rdf:type :Genre .
- :G1 :type “Comedy” .
- :M1 :has_genre :G1
Line 1 creates an M1 entity as a type (instance_of) Movie.
Line 2 adds a name attribute with a value of “The bird cage” to the M1 entity.
Line 3 creates a G1 entity as a type (instance_of) Genre.
Line 4 adds a type attribute with a value of “Comedy” to the G1 entity.
Line 5 creates an explicit relationship named “has_genre” between M1 and G1.
Now a query like the following can be used in a genAI prompt (this query uses the W3C SPARQL language),
SELECT ?movie ?title ?type
WHERE
{?movie :has_genre ?genre .
?movie :title ?title .
?genre :type ?type .
}
This query returns,
Movie Title Type
M1 The bird cage Comedy
In contrast to Property Graphs and SQL/PGQ, RDF benefits from having been a standard for 20 years and the existence of plenty of linked data on the internet for training. GenAI can generate decent SPARQL queries if prompted with an ontology in a standard RDF serialization, and it seems to already be trained on public datasets like DBPedia.
Oracle Database has a complete implementation of RDF, which means you get RDF plus all of the enterprise features of an Oracle Database like transactional support, performance, security and reliability in a converged database. Oracle’s implementation is unique in that it is tightly integrated with SQL. This means an RDF database can be made to look like an SQL database as demonstrated in Building Rule-Based OLTP Systems Using Oracle RDF.
Although the approach outlined above requires the RDF data to be stored in native RDF format, Oracle Database also provides a way of viewing and querying relational data as RDF using a mapping specified using the W3C RDB2RDF mapping standard. The need to convert relational data to RDF when presenting as output of SPARQL queries may introduce some performance overhead, however, for more complex queries.
4. GenAI RAG and using RDF Knowledge Graphs to Model Concepts
Explicit relationships are sometimes not enough to model data. The use of Classes and Subclasses, as in the following figure, adds more context.
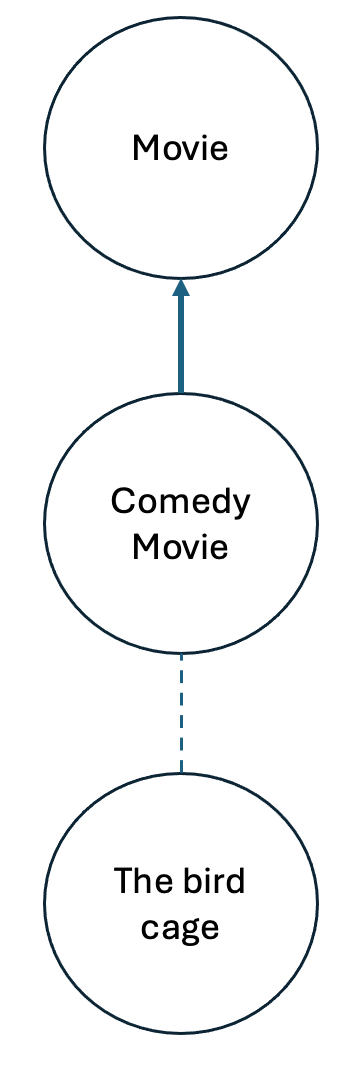
Here ComedyMovie is a subclass of Movie and “The bird cage” is in instance of ComedyMovie. This can be done in an RDF Knowledge Graph as follows.
:ComedyMovie rdfs:subClassOf :Movie .
:M1 rdf:type :ComedyMovie .
:M1 :title “The bird cage” .
Here’s one type of query for this database,
SELECT ?movie ?title
WHERE
{?movie rdf:type :ComedyMovie .
?movie :title ?title .
}
This query returns the title of all comedy movies like this,
![]()
What if we want the title of all movies? This query will do it,
SELECT ?movie ?class ?title
WHERE
{?movie rdf:type/rdfs:subClassOf* :Movie .
?movie rdf:type ?class .
?movie :title ?title .
}
Which returns,

This is an extremely important query to be able to do when you have classes and subclasses, i.e., to get instances of the subclasses at the class level.
This is made possible by this syntax “rdf:type/rdfs:subClassOf*”, which is called SPARQL Property Paths. They are defined here. Property paths enable a very flexible and powerful way of navigating possible routes through a graph between two graph nodes
There are many additional types of concepts that are supported by RDF Knowledge Graphs like attribute value inheritance, automatically providing the inverse of a relationship and inferring that one entity is the same as another entity. All of these help represent concepts and are not easily possible with Property Graphs.
These concepts and many more will eventually be needed for genAI RAG.
So, what is the downside of using RDF Knowledge Graphs and for genAI RAG? RDF Knowledge Graphs, while based on formal semantics and a mature standard, can have a steep learning curve. While RDF Knowledge Graphs work best when data is represented in a native RDF format, it is considered verbose and converting existing data into a native RDF format is perceived as a hurdle. The model can also be seen as rigid, while the Property Graph model is perceived as simple and flexible. But what’s discussed in Building Rule-Based OLTP Systems Using Oracle RDF eliminates this problem.
Another potential problem with this approach is that many of the RDF concepts require an extra step called “entailment” as part of the implementation. Entailment adds extra computational requirements and usually requires materialization of the data.
5. Conclusion
At this point in time, are RDF Knowledge Graphs the best choice for RAG Knowledge Graphs because they can be used to provide a much more conceptual meaning to the data? Or are Property Graphs better because of their flexibility, and concepts will be handled by genAI in a different way? These questions are actively debated. It remains to be seen which graph model will best help genAI.
Appendix – Oracle RDF Knowledge Graph Code used in this blog post
BEGIN
SEM_APIS.UPDATE_MODEL(‘movies’,
‘PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX movie: <http://movie.org/>
INSERT DATA {
movie:M1 rdf:type movie:Movie .
movie:M1 movie:name “The bird cage” .
movie:G1 rdf:type movie:Genre .
movie:G1 movie:type “Comdey” .
movie:M1 movie:has_genre movie:G1
}’,
network_owner=>’RDFUSER’,
network_name=>’NET1′);
END;
/
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX movie: <http://movie.org/>
SELECT ?movie ?title ?type
WHERE
{?movie movie:has_genre ?genre .
?movie movie:title ?title .
?genre movie:type ?type .
}
BEGIN
SEM_APIS.UPDATE_MODEL(‘MovieClasses’,
‘PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX movie: <http://movie.org/>
INSERT DATA {
movie:ComedyMovie rdfs:subClassOf movie:Movie .
movie:M1 rdf:type movie:ComedyMovie .
movie:M1 movie:title “The bird cage” .
}’,
network_owner=>’RDFUSER’,
network_name=>’NET1′);
END;
Query 1
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX movie: <http://movie.org/>
SELECT ?movie ?title
WHERE
{?movie rdf:type movie:ComedyMovie .
?movie movie:title ?title .
}
![]()
Query 2
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX movie: <http://movie.org/>
SELECT ?movie ?class ?title
WHERE
{?movie rdf:type/rdfs:subClassOf* movie:Movie .
?movie rdf:type ?class .
?movie movie:title ?title .
}
