For more details on Oracle Database 23ai please follow this link: https://blogs.oracle.com/database/post/oracle-23ai-now-generally-available.
The In-Memory Deep Vectorization Framework was first introduced in Oracle Database 21c. The first feature to take advantage of the new framework was In-Memory vectorized joins. In Oracle Database 23ai In-Memory Deep Vectorization has been expanded to support the following additional join types:
• Multi-level hash joins
• Multi join key
• Semi joins
• Outer joins
• Full group by aggregation
This enhancement enables additional performance by leveraging Single Instruction, Multiple Data (SIMD) vector instructions. I used Oracle Database 23ai Free for the examples that follow along with the SSB schema.
One more detail. Similar to Join Groups, In-Memory Deep Vectorization is a run-time decision captured by SQL Monitor. The use of In-Memory Deep Vectorization can be displayed in a SQL Monitor active report by clicking on the binoculars of a hash join operation. For example:
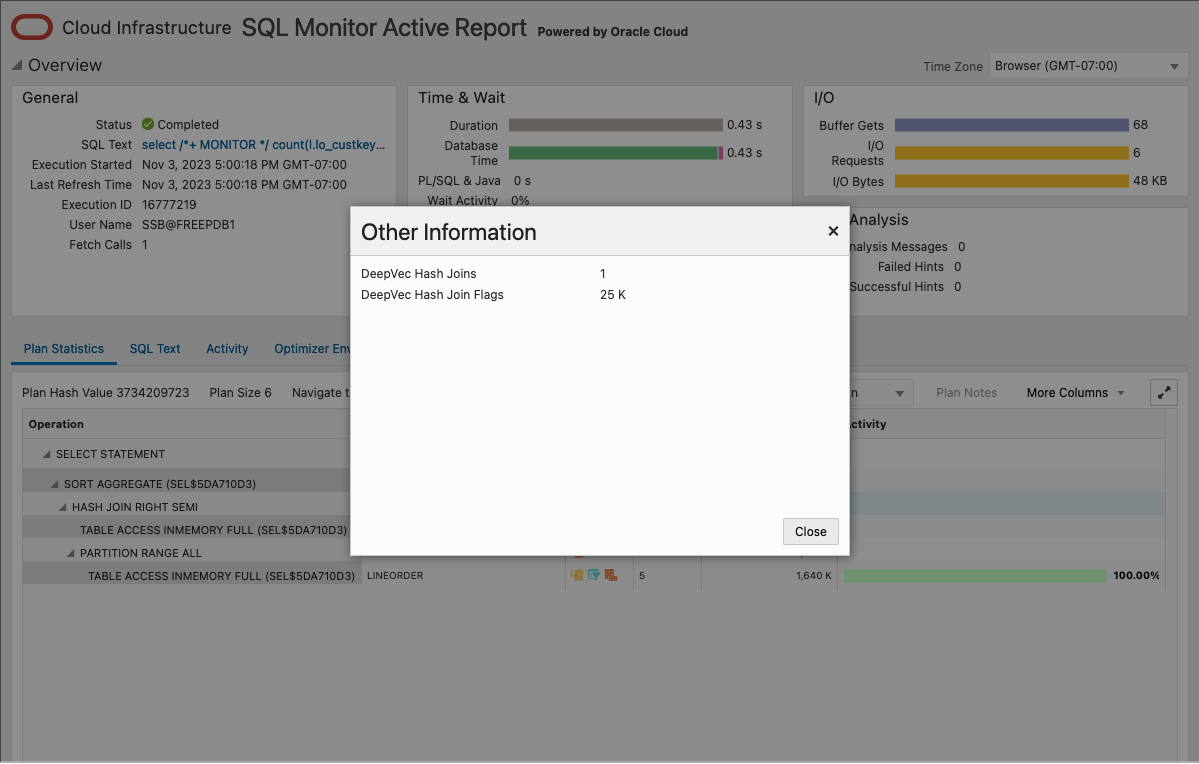
Note the first statistic “DeepVec Hash Joins” is set to 1. This means a deep vector join was performed. There is a second way to display the same information using SQL. The following SQL statement will display the same information from the underlying SQL Monitor tables:
set echo off
set trimspool on
set trim on
set pages 0
set linesize 1000
set long 1000000
set longchunksize 1000000
PROMPT Deep Vectorization Usage: ;
PROMPT ------------------------- ;
PROMPT ;
SELECT
' ' || deepvec.rowsource_id || ' - ' row_source_id,
CASE
WHEN deepvec.deepvec_hj IS NOT NULL
THEN
'deep vector hash joins used: ' || deepvec.deepvec_hj ||
', deep vector hash join flags: ' || deepvec.deepvec_hj_flags
ELSE
'deep vector HJ was NOT leveraged'
END deep_vector_hash_join_usage_info
FROM
(SELECT EXTRACT(DBMS_SQL_MONITOR.REPORT_SQL_MONITOR_XML,
q'#//operation[@name='HASH JOIN' and @parent_id]#') xmldata
FROM DUAL) hj_operation_data,
XMLTABLE('/operation'
PASSING hj_operation_data.xmldata
COLUMNS
"ROWSOURCE_ID" VARCHAR2(5) PATH '@id',
"DEEPVEC_HJ" VARCHAR2(5) PATH 'rwsstats/stat[@id="11"]',
"DEEPVEC_HJ_FLAGS" VARCHAR2(5) PATH 'rwsstats/stat[@id="12"]') deepvec;
This will display in the following format:
Deep Vectorization Usage: ------------------------- 2 - deep vector hash joins used: 1, deep vector hash join flags: 24576
The following is an example of a semi-join that now takes advantage of In-Memory Deep Vectorization:
select /*+ MONITOR */ count(l.lo_custkey) from lineorder l where l.lo_partkey IN (select p.p_partkey from part p) and l.lo_quantity <= 3;
The above query resulted in the following execution plan in my 23ai Free database:
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 5113 (100)| | | |
| 1 | SORT AGGREGATE | | 1 | 18 | | | | | |
|* 2 | HASH JOIN RIGHT SEMI | | 1640K| 28M| 12M| 5113 (8)| 00:00:01 | | |
| 3 | TABLE ACCESS INMEMORY FULL | PART | 800K| 3906K| | 73 (3)| 00:00:01 | | |
| 4 | PARTITION RANGE ALL | | 1640K| 20M| | 2448 (15)| 00:00:01 | 1 | 3 |
|* 5 | TABLE ACCESS INMEMORY FULL| LINEORDER | 1640K| 20M| | 2448 (15)| 00:00:01 | 1 | 3 |
-------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("L"."LO_PARTKEY"="P"."P_PARTKEY")
5 - inmemory("L"."LO_QUANTITY"<=3)
filter("L"."LO_QUANTITY"<=3)
25 rows selected.
SQL>
SQL> set echo off
Deep Vectorization Usage:
-------------------------
2 - deep vector hash joins used: 1, deep vector hash join flags: 24576
Note that in the Deep Vectorization Usage section that operation 2, a HASH JOIN RIGHT SEMI was identified as using a deep vector hash join.
As I mentioned earlier, one of the key ways that a deep vector join achieves higher performance is in the ability to leverage Single Instruction, Multiple Data (SIMD) vector processing. We can see this difference if we compare the statistics from running with In-Memory vectorization disabled and then enabled. Unfortunately, starting in 21c the IM SIMD statistics are only available at the system level. I talked about this problem in an Ask TOM Office Hours session we did on In-Memory Vector Joins in 21c. You can go back and watch the video here. The workaround was to use a modified version of Tom Kyte’s old runstats utility to compare the system level statistics rather than session level statistics. You can see the old runstats utility and the modified run_sysstats utility on my Github site here.
A word of caution. System level statistics are aggregated across all database sessions. In this experiment I was running my 23ai Free database as essentially a single user system in my own virtual machine. This approach won’t work very well if you have multiple users running in-memory queries.
The following is the output from two executions of the previous query, the first with In-Memory Deep Vectorization disabled (i.e., inmemory_deep_vectorization = false) and then with In-Memory Deep Vectorization enabled (i.e., inmemory_deep_vectorization = true):
Name Run1 Run2 Diff STAT...CPU used by this session 5 41 36 STAT...IM scan rows projected 2,440,148 51 -2,440,097 STAT...IM simd KV add calls 0 795 795 STAT...IM simd KV add rows 0 800,000 800,000 STAT...IM simd KV probe calls 0 51 51 STAT...IM simd KV probe chain_buckets 0 7,437 7,437 STAT...IM simd KV probe keys 0 1,640,148 1,640,148 STAT...IM simd KV probe rows 0 1,640,148 1,640,148 STAT...IM simd KV probe serial_buckets 0 420 420 STAT...IM simd decode symbol calls 3,126 2 -3,124 STAT...IM simd decode unpack calls 0 2 2 STAT...IM simd decode unpack selective calls 0 2 2 STAT...IM simd hash calls 0 53 53 STAT...IM simd hash rows 0 2,440,148 2,440,148 STAT...physical reads 28 13 -15 STAT...session logical reads 214,127 214,005 -122 STAT...session pga memory -524,288 0 524,288
Notice that there is a substantial difference in the use of SIMD in the Run2 column where the statement was run with In-Memory Deep Vectorization enabled.
There is one more really important enhancement that was made. The ability to support a multi-level join. Why is this such an important enhancement? Because it enables the ability to operate on a join between a row source, or the result of a previous join, and a table. Hence, the multi-level join.
We will use the following query to show a multi-level join:
select /*+ MONITOR NO_VECTOR_TRANSFORM */ d_year, c_nation, s_region, lo_shipmode , sum(lo_extendedprice) from part p, customer c, lineorder l, supplier s, date_dim d where s.s_suppkey = l.lo_suppkey and l.lo_custkey = c.c_custkey and l.lo_partkey = p.p_partkey and l.lo_orderdate = d.d_datekey group by d_year, c_nation, s_region, lo_shipmode;
This query produced the following execution plan, and notice from the “Deep Vectorization Usage” section that a deep vector join was performed up through each hash join in the execution plan!
----------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
----------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 145K(100)| | | |
| 1 | HASH GROUP BY | | 2166 | 203K| | 145K (2)| 00:00:06 | | |
|* 2 | HASH JOIN | | 27M| 2485M| | 145K (1)| 00:00:06 | | |
| 3 | PART JOIN FILTER CREATE | :BF0000 | 2556 | 30672 | | 1 (0)| 00:00:01 | | |
| 4 | TABLE ACCESS INMEMORY FULL | DATE_DIM | 2556 | 30672 | | 1 (0)| 00:00:01 | | |
|* 5 | HASH JOIN | | 27M| 2175M| | 145K (1)| 00:00:06 | | |
| 6 | TABLE ACCESS INMEMORY FULL | SUPPLIER | 20000 | 351K| | 3 (0)| 00:00:01 | | |
|* 7 | HASH JOIN | | 27M| 1719M| 9672K| 144K (1)| 00:00:06 | | |
| 8 | TABLE ACCESS INMEMORY FULL | CUSTOMER | 300K| 6152K| | 33 (7)| 00:00:01 | | |
|* 9 | HASH JOIN | | 27M| 1172M| 12M| 70700 (2)| 00:00:03 | | |
| 10 | TABLE ACCESS INMEMORY FULL | PART | 800K| 3906K| | 73 (3)| 00:00:01 | | |
| 11 | PARTITION RANGE JOIN-FILTER| | 27M| 1042M| | 2701 (23)| 00:00:01 |:BF0000|:BF0000|
| 12 | TABLE ACCESS INMEMORY FULL| LINEORDER | 27M| 1042M| | 2701 (23)| 00:00:01 |:BF0000|:BF0000|
----------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("L"."LO_ORDERDATE"="D"."D_DATEKEY")
5 - access("S"."S_SUPPKEY"="L"."LO_SUPPKEY")
7 - access("L"."LO_CUSTKEY"="C"."C_CUSTKEY")
9 - access("L"."LO_PARTKEY"="P"."P_PARTKEY")
37 rows selected.
SQL>
SQL> set echo off
Deep Vectorization Usage:
-------------------------
2 - deep vector hash joins used: 1, deep vector hash join flags:
5 - deep vector hash joins used: 1, deep vector hash join flags: 8192
7 - deep vector hash joins used: 1, deep vector hash join flags: 8192
9 - deep vector hash joins used: 1, deep vector hash join flags: 24576
This is a very exciting enhancement. Notice that a Bloom filter was not required, and I did disable vector transformation for this query to show how the multi-level join works. Deep vector joins do not support vector transformation directly, but other hash joins in the same plan can take advantage of deep vector joins. One other thing to note. Multi-level deep vector joins support left deep, right deep and some types of bushy joins.
There are two other Database In-Memory features that also improve deep vector joins. Join Groups and In-Memory Dynamic Scans (IMDS). Join Groups help by synchronizing dictionary values for columns in the same or different tables, making joins faster on columns in a join group. IMDS provides scan improvement since it parallelizes scans at the IMCU level. Join Groups must be explicitly defined or may be defined by Automatic In-Memory (AIM) in 23ai. On systems with excess CPU capacity and CPU counts greater than 24 the Resource Manager will automatically enable IMDS. Neither of these features were used in the previous examples but can provide substantial additional performance improvements for larger databases.
