The introduction of Persistent Memory (PMEM) marks the beginning of a revolution in the computing industry. There has always been a separation between system memory where the contents are ephemeral and byte addressable, and storage where the data is persistent and block oriented. Persistent Memory (such as Intel Optane DC Persistent Memory) blurs the line between storage and memory by being both byte addressable as well as persistent.
This new class of Non-Volatile Memory is fast enough to operate alongside conventional (volatile) DRAM in a DIMM (Dual In-Line Memory Module) form factor. Integrating into systems in DIMM slots means that Persistent Memory is able to play a vastly different role than conventional block-oriented storage such as Hard Disk Drives (HDD) or Solid State Disk (SSD).
In this first of a multi-part series on Persistent Memory, we will cover the fundamentals of Persistent Memory and how this technology works under the covers.
3D XPoint Non-Volatile Memory
3D XPoint is the underlying silicon of Intel Optane products and is a new form of non-volatile memory that is different from the Flash-based solutions that have become prevalent in storage products. NAND Flash or simply Flash is named after the NAND logic gate and is primarily used in memory cards, in USB Flash drives, and in Solid State Drives (SSD) for general purpose storage. 3D XPoint is also available as memory DIMMs as well as in an SSD format branded as Intel Optane SSD.

3D XPoint is faster than NAND Flash, but slower than DRAM. 3D XPoint is also more expensive (by capacity) than Flash but less expensive than DRAM. These 2 factors of cost and speed place 3D XPoint between Flash and DRAM. There is also a set of API and programming standards for Persistent Memory that will support other Non-Volatile (NV) Memory technologies beyond 3D XPoint. Persistent Memory documentation is published at http://pmem.io.
This blog post is focused on Intel Optane DC Persistent Memory, but as previous mentioned, Intel Optane is also available in an SSD form. Optane SSD is faster than NAND Flash SSD and can be used in the conventional manner as storage. For more information on Optane SSD, please see Intel for more information here.
Speed!
Put plainly, Persistent Memory is fast! It’s dramatically faster than spinning disk or Flash SSD, but still a bit slower than volatile memory (DRAM). To put this in perspective, consider the following time measures:
- Millisecond = 1/1,000 second
- Microsecond = 1/1,000,000 second
- Nanosecond = 1/1,000,000,000 second
Data access times (often referred to as latency) for current generation DRAM is in the range of 80-100 nanoseconds, while spinning disk when configured properly should perform in the range of single-digit (1-9) milliseconds. Persistent Memory access times for 64-bytes is around 300 nanoseconds. While this is about 3 times slower than DRAM, it’s more than 3,000 times faster than spinning disk.
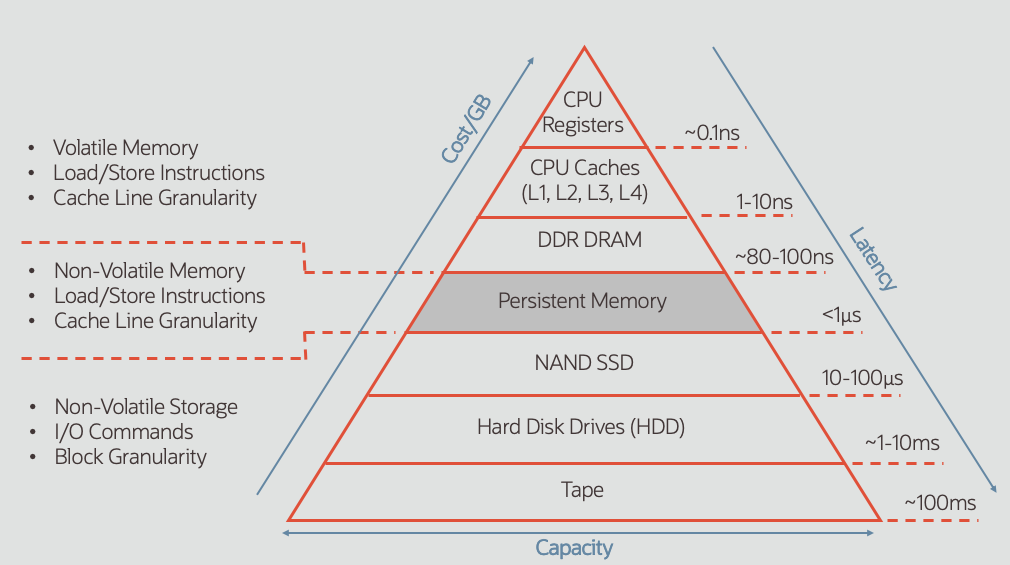
Performance of Flash SSD falls between these two extremes, and varies based on the configuration and workload. For example, local Flash SSD attached directly to a server will deliver lower latency (faster access) than a server accessing Flash SSD contained in a storage array, although it isn’t sharable by multiple servers. Performance also depends on the amount of system load (such as number of users) as well as the type of application (such as OLTP vs. Data Analytics), so performance results will vary.
In a Flash SSD shared storage configuration delivering 200 microsecond I/O latency (0.2 milliseconds), data access is at least 5X faster than spinning disk (assuming 1 millisecond disk access time). However, Persistent Memory data access (64 bytes) at 300 nanoseconds, is more than 600 times faster than Flash SSD (such as an all-flash array).
PMEM vs. Disk Performance
Using traditional disk (HDD) as a baseline, we can clearly see the dramatic performance increases that have come with new technologies, as well as the difference between shared and direct attached storage. The following table shows typical I/O response (or latency) with different technologies. The specific performance on any given system will vary, but this table illustrates the general performance characteristics.
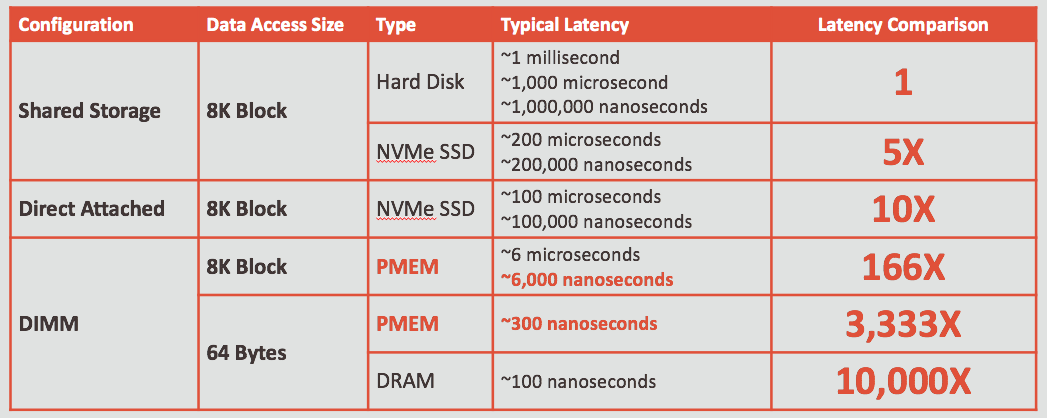
Notice that memory performance is measured in nanoseconds (one billionth of a second), while hard disk drive performance has typically been measured in milliseconds (one thousandth of a second) which is a 10,000X difference in performance. Notice also that memory is accessed at the byte level, whereas storage (HDD and SSD) is typically accessed in terms of blocks (8K in this example).
Persistent Memory might also be used with a block-oriented application, but it’s quite easy to see this doesn’t take full advantage of the performance benefits. It’s only when the application is specifically designed to work at the byte level that we see the full performance advantages of PMEM. The main challenge in developing applications (such as databases!) to work with PMEM is the granularity of atomicity, which refers to how PMEM persists data as we will see later. Of course the order in which writes occur is also critical to ensuring data integrity. Before we delve into the finer details, it is important to understand the multiple configuration options are that are available.
PMEM Configuration Options
Persistent Memory can be used in multiple configurations, each of which suits a particular need. The two major configuration options for configuring PMEM are known as “AppDirect Mode” and “Memory Mode”, and there are multiple options within AppDirect.

Memory Mode
Persistent Memory can be used in what is known as Memory Mode, where the system uses a combination of PMEM and DRAM and the O/S automatically migrates “hot” blocks to the faster DRAM and “colder” blocks to larger but slower PMEM. The PMEM is essentially used for its larger capacity rather than for purposes of data persistence. Memory Mode operates transparently to the application, and is supported for running Oracle Databases. The majority of this blog is focused on AppDirect, which enables applications to use the Persistent Memory directly rather than simply using it as a larger system memory.
AppDirect Mode
PMEM configured in AppDirect mode begins with a Namespace configuration, which is similar to a logical volume manager for Persistent Memory. Namespaces are configured on Linux systems using the “ndctl” utility, with 4 options of fsdax, sector, devdax, and raw. File systems can then be mounted on fsdax or sector namespaces. There are 2 layers to understand, which are the Namespace or device configuration, as well as the filesystem layer that is mounted on top of the device.
Namespace Configuration
The ndctl utility is used to configure non-volatile memory devices on the Linux Platform. The command “ndctl list -N” will display a listing of configured namespaces. The following graphic shows fsdax and sector namespaces and their configuration details.

Direct Access (or DAX) refers to the ability to directly access Persistent Memory contents without copying data into buffers in DRAM. The fsdax configuration uses an 8-byte atomicity, whereas sector can use 512 byte or 4,096 byte atomicity. Once the device level is configured, a file system can be mounted on the device.
File System Configuration
On the Linux platform, XFS and ext4 file systems can be mounted for DAX operation on fsdax or sector Namespaces using the -o dax option of the mount command. There are 3 configuration options for filesystems on top of Namespaces as follows:
- fsdax namespace with DAX filesystem (8-byte atomicity)
- fsdax namespace with non-DAX filesystem (8-byte atomicity)
- sector namespace with non-DAX filesystem (512-byte or 4,096-byte sector atomicity)
The Direct Access (DAX) operation is important for performance, and the application must tolerate the level of atomicity provided by the Persistent Memory device.
8-Byte Atomicity
Persistent Memory (such as Intel Optane DC Persistent Memory) natively operates byte-by-byte rather than in blocks of data like conventional storage. Data is persisted in chunks of 8-bytes at most in Persistent Memory (again, using the default behavior). For applications (like databases) that are based on a BLOCK construct, the 8-byte atomicity of Persistent Memory can be an issue. Writing 8,192 bytes of data (an 8K block) will get persisted in 1,024 chunks of 8-bytes each. Power failure or other abnormal condition can leave blocks of data “fractured” or “torn” into pieces, with portions of the block containing old data and other portions with new data. Applications (such as databases) need to be changed to tolerate this sort of fracturing or tearing of blocks. Otherwise, these are effectively corrupted blocks of data. Continue reading for more information on the topic of corruption and especially how this relates to Oracle databases.
Sector Atomicity
Persistent Memory can be configured for sector level atomicity by defining Namespaces with the “sector” option, which is also known as BTT (Block Translation Table) mode. Tearing of blocks can still occur if the application (i.e. database) block size does not match the block size defined in the Namespace or if there is a misalignment between database block and Persistent Memory sector boundaries. While conventional Disk and Flash SSD devices might have a different block size than the application, there is often a battery-backed controller cache that eliminates the block fracturing problem.
It’s interesting to note that applications often use the word “block”, conventional disk devices use what are known as “sectors” (sectors of spinning disk), while in an O/S context we often use the word “page” to refer to a unit of storage or memory. These are all 3 terms that essentially refer to the same concept, and they converge when we are talking about Persistent Memory. Blocks of data in an application (or database) map to O/S pages, map to sectors on storage.
In cases with a mismatch of application block size and Namespace sector size, we would still expect some degree of block fracturing (or tearing in the PMEM terminology) because of the lack of controller cache. Ideally, the application (such as a database) should be made tolerant of 8-byte atomicity because it would be very simple to mis-configure the application block size and Namespace sector size or have a misalignment of blocks to sectors that causes tearing or corruption. Data integrity is paramount for a company such as Oracle, so please continue reading this article for more information.
Application Layer: Block-Based Conventional Storage I/O
Persistent storage such as Disk and Flash SSD has always been block-oriented, and applications (such as databases) have been developed to work in this manner. Applications have traditionally been developed to read and write blocks of data in storage. Applications (or system software) handle buffering of data into memory where it is used and manipulated, then saved (or persisted) back to the storage as blocks once the application is done using it as shown in the diagram below.
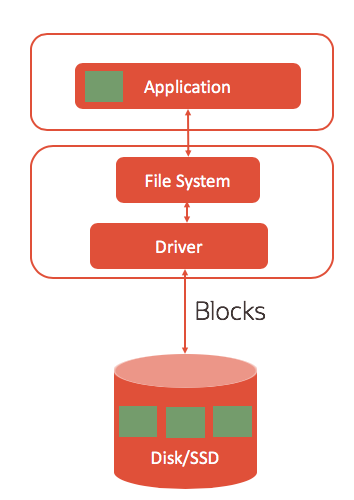
Applications that are block-oriented (such as databases) will typically use C/C++ read() and write() system calls to access data in block-oriented storage. Block oriented applications expect to read complete blocks from storage and they are designed to write entire blocks to storage. The storage normally guarantees atomicity (success or failure) of writing the entire block, and this is normally backed by a non-volatile cache in the disk controller of modern systems.
Application Layer: Byte-Oriented Applications
Memory is fundamentally byte oriented, and Persistent Memory (such as Intel Optane DC Persistent Memory) is designed to be used by applications in a byte-oriented manner as well. Applications can access data directly (in-place) with Persistent Memory just like data that has been placed by the application into DRAM. The C/C++ function mmap() on Linux maps files in Persistent Memory into the application’s address space. If the filesystem is mounted using the DAX option (mount -o dax), system buffers are eliminated and the application operates directly on the data residing in Persistent Memory as shown in the following diagram:
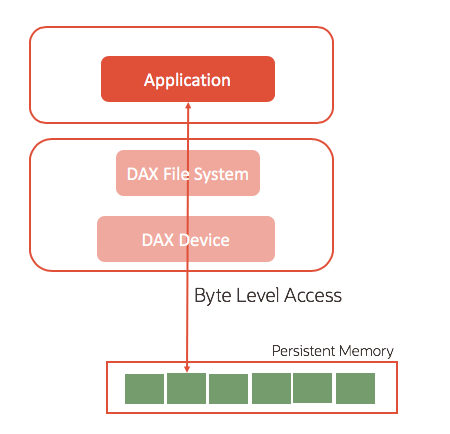
Mapping file contents into the application address space and accessing the data directly on Persistent Memory eliminates the copying of data using C/C++ functions such as memcpy(), which eliminates code-path in the processing of data and therefore improves performance. For example, databases will typically copy data into a shared memory segment (like the Oracle SGA) for access by multiple users on a system. Eliminating copying of data obviously has implications for speed of data access, but also related to the handling of atomicity as well shall see later.
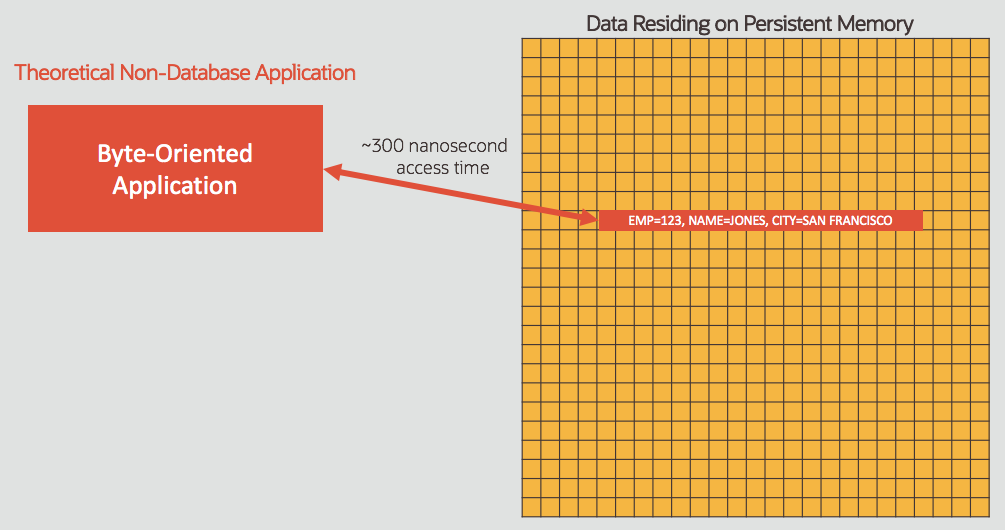
DAX: Direct Access to PMEM
The highest level of performance with Persistent Memory comes when an application is designed to work directly against the data without copying it as shown in the diagram below. Accessing 64 bytes of data takes approximately 300 nanoseconds, which is dramatically faster than reading from Solid State Disk (SSD).
Block Oriented Processing
Applications that are designed for block oriented data access will copy data into memory as shown in the diagram below. Users of Persistent Memory should typically see about 6,000 nanosecond access time for 8K of data. While this is much faster than even locally attached Flash SSD, it’s not nearly as fast as DRAM or byte-oriented data access on PMEM.
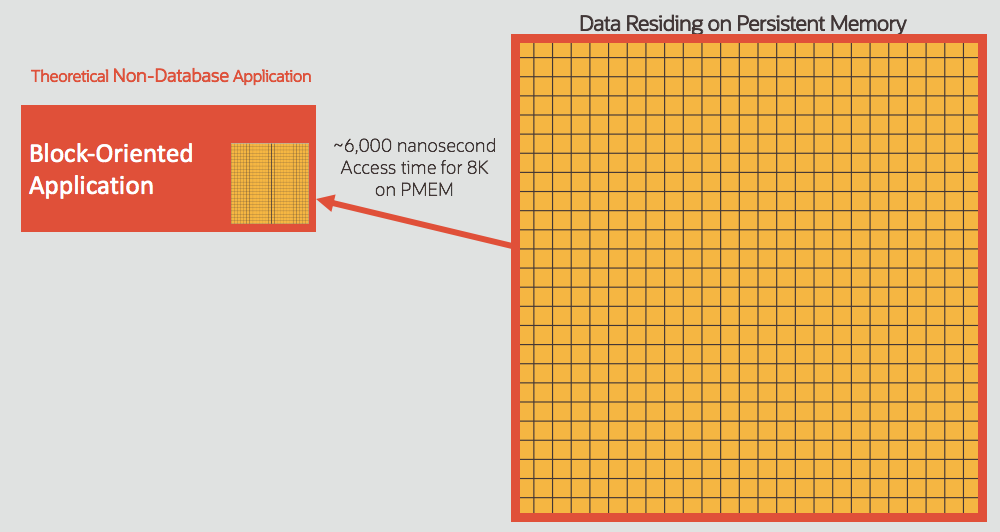
In this diagram, the entire block is being read from PMEM into DRAM, which is functionally the same as Flash SSD or spinning disk from a READ perspective. However, writing of data brings some big data integrity implications for a block-oriented application. Of course databases have traditionally been block-oriented, and this certainly applies to the Oracle database.
Implications for Block Oriented Applications
Persistent Memory is fundamentally different from HDD and SSD because of the way data gets written (or persisted). An application might write a block of data, but this write() operation gets executed in pieces. Any failure during the write (power failure, system kernel panic, abnormal shutdown, etc.) will result in fracturing or tearing (i.e. corruption) of blocks shown in the following diagram:
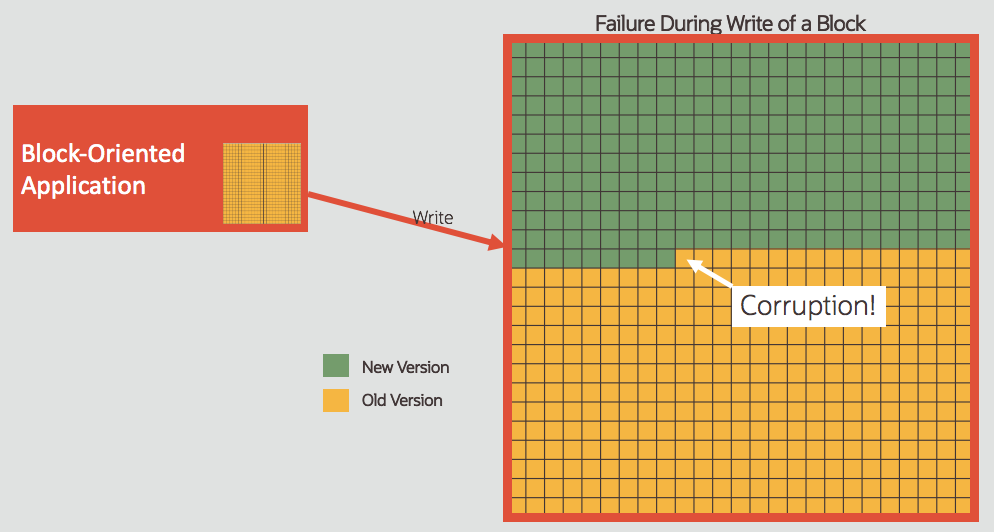
A block of data that’s partially written will typically mean data corruption for an application that is block-oriented. The application (such as a database) expects the storage to either succeed or fail the ENTIRE write operation rather than leaving it partially completed. This behavior of the storage is called “atomicity” and the granularity of atomicity is critical. Any mismatch in the size of write vs. granularity of atomicity will result in corruption. Conventional disk storage has typically gotten around this issue using a disk cache, which ensures block-level atomicity.
Alert: File Systems and Devices on PMEM
All current versions of the Oracle Database as of this writing are susceptible to corruption in these configurations as outlined in this My Oracle Support Note: File Systems and Devices on Persistent Memory (PMEM) in Database Servers May Cause Database Corruption (Doc ID 2608116.1) viewable here: https://support.oracle.com/epmos/faces/DocumentDisplay?id=2608116.1 The issues underlying this document do not apply to Persistent Memory operating in what is known as Memory Mode or in the SSD form-factor.

An upcoming feature of Oracle Database will take full advantage of the performance benefits of PMEM, as well as addressing the data corruption issues discussed above. In addition, an upcoming backport of changes into Oracle Database 19c will address the data corruption issues that are the subject of this MOS note. There are no known file systems, device drivers, or other solutions to this data corruption problem.
The Software Engineering Challenge
As we have seen above, the potential performance gains of Persistent Memory are absolutely stunning, with more than 3,000X faster data access, but taking advantage of those performance gains poses some unique software engineering challenges. The primary “reason for being” of databases is data integrity, so solving these challenges is absolutely fundamental for the Oracle Development organization. While it’s possible to retrofit Persistent Memory into an existing environment, this approach also includes data integrity issues as we have seen above. At Oracle, we believe the best approach is to design the Oracle Database and Exadata software to fully integrate with Persistent Memory to gain the maximum performance benefits AND to achieve our primary goal of protecting customers data.
Persistent Memory in Exadata X8M
Exadata X8M uses Persistent Memory in the storage tier to accelerate database block I/O, as well as to accelerate commit-related process in the database transaction log. Persistent Memory is used in AppDirect mode in Exadata, and the Exadata software is designed to address the data integrity issues mentioned above by incorporating software logic that is compatible with the 8-byte atomicity of Persistent Memory. Exadata storage also keeps 2 or 3 redundant copies of all data (depending on redundancy configuration) across storage servers for fault tolerance.
Summary
Persistent Memory is a revolutionary technology that promises incredible performance increases for data intensive processing such as workloads that rely on Oracle Database. As we have seen in this blog, Persistent Memory presents the potential for incredible database performance gains, but also poses a number of software engineering challenges for developers like Oracle. Oracle has already solved these challenges in Exadata as we shall see in the next blog of this series, and there are more technological advances on the way for the Oracle Database as well.