Would you like your Java programs to continue running without errors if your Oracle Real Application Clusters (RAC) database is temporarily unavailable, if a node fails intentionally or unintentionally? Do you want this to be uncomplicated and without complex, own code for error handling ? For reading and writing transactions aborted in the middle ? For local and distributed transactions ? Then use the JDBC driver 21c and the Universal Connection Pool (UCP) from Oracle. In the following posting show you an example with current frameworks, how this could look like.
A lot has happened in Oracle clients since Oracle RAC became available with database version 10. Oracle Fast Application Notification (FAN) and Fast Connection Failover (FCF), later with Application Continuity (AC) in version 12c and Transparent Application Continuity (TAC) in 18c (with further features in version 19c and 21c) each represented the current state of development and offered more and more possibilities and automatisms, more and more transparency in case of a problem in the cluster. TAC offers all-round protection with fast notification of an Oracle Connection Pool, which cleans up invalid unused connections. Connections, which are currently in use by the program, not only read, but also write open transactions are transparently taken over and played back on the surviving database node until the last command shortly before the hopefully intended failure.
Not only on the Oracle database side,but also in the JDBC or Java client a lot has changed. The latest APIs are always supported and frameworks such as Spring Boot and application servers such as WildFly are provided with plugins and howtos.
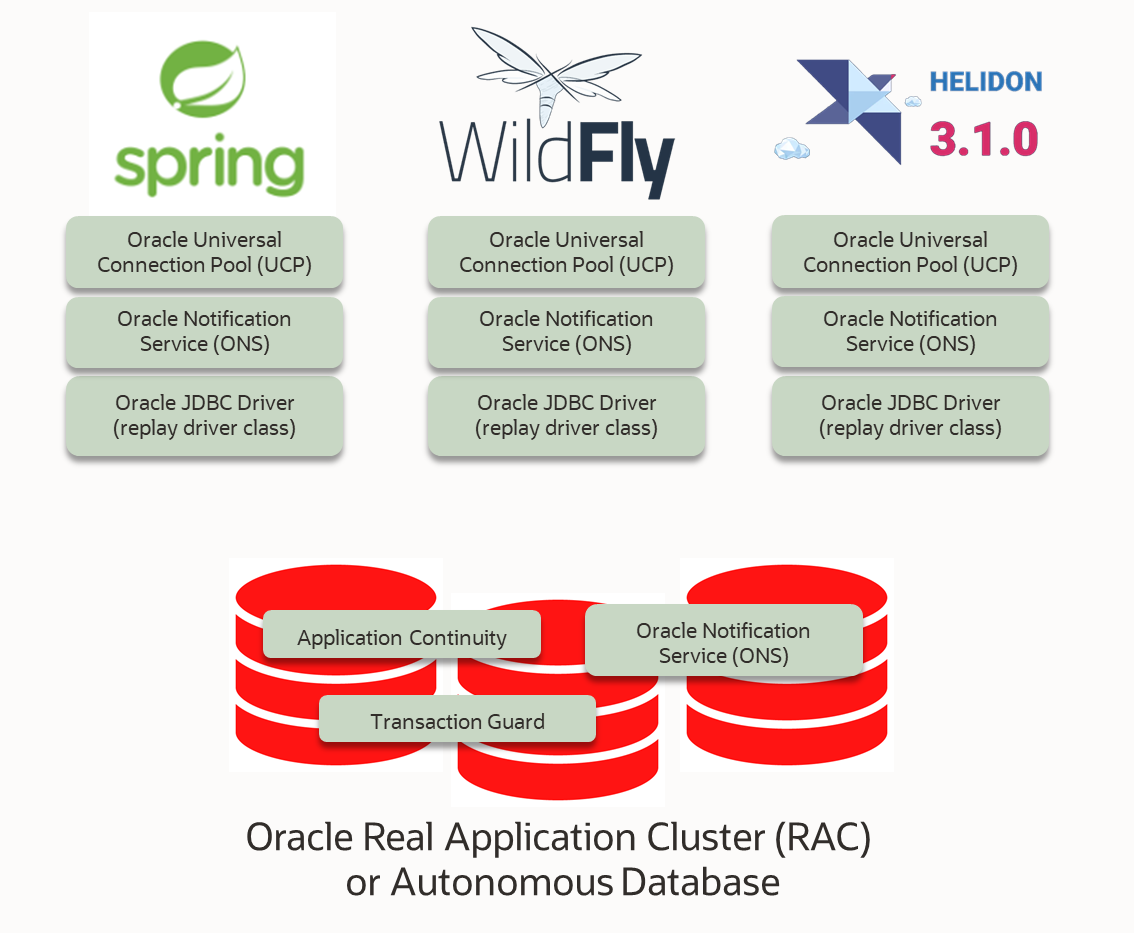
Our example uses the Java Microprofile 5.0 specification in addition to Java 17, which means among other things the use of Jakarta EE 9.1 libraries for distributed transactions and for the Java Persistence API, here with EclipseLink implementation. Everything together was poured into the OpenSource Framework Helidon 3.1 of the Oracle Enterprise Java team. We will go into the differences when using SpringBoot or WildFly at the appropriate places. The complete executable Helidon sample project with configuration files and complete Java code is available for download or via “git clone” at github.com/ilfur/tac_helidon_jpa.
Preparation of Oracle RAC for transparent application continuity (TAC)
The individual steps and explanations for TAC and its setup are already comprehensively explained in a blog by our esteemed colleague Sinan Petrus Toma: Database Outage? Who cares ???
For our Java example, we used a database environment 19c with SCAN Listener and Transaction Guard and Oracle Notification Service(ONS) on port 6200.
The database cluster received a new service that gets some parameters on the way for the use with TAC:
srvctl add service -db cdb19a -service TACSERVICE -pdb WKAA -preferred cdb19a1,cdb19a2 -available cdb19a3,cdb19a4 -failover_restore AUTO -commit_outcome TRUE -failovertype AUTO -replay_init_time 600 -retention 86400 -notification TRUE -drain_timeout 120 -stopoption IMMEDIATE -role PRIMARY
The parameter “-failovertype AUTO” enables TAC, parameter “-notification TRUE” enables notifications/ONS for this service, and “-commit_outcome TRUE” uses Transaction Guard.
To connect to this service via Java, a connect string was chosen that contains some parameters typical for failover scenarios and load balancing:
jdbc:oracle:thin:@(DESCRIPTION = (CONNECT_TIMEOUT= 3)(RETRY_COUNT=4)(RETRY_DELAY=2)(TRANSPORT_CONNECT_TIMEOUT=3) (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST=hpcexa-scan.de.oracle.com)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME = tacservice.de.oracle.com)))
The CONNECT_TIMEOUT value is preferably selected relatively small with 3 seconds. If a connect attempt fails after 3 seconds, a new connect attempt is started after a RETRY_DELAY of 2 seconds, maximum RETRY_COUNT times. With TRANSPORT_CONNECT_TIMEOUT the timeout is set purely on TCP/IP level, without waiting for feedback from the database instance as with CONNECT_TIMEOUT. The default here is 60 seconds, which is quite long.
Preparation of the Java project for TAC: integration of the UCP
To take full advantage of all the features of TAC and also provide drivers and plugins for SpringBoot and WildFly, the latest JDBC 21c driver should be used (at the time of this writing version 21.8.0.0), which is also certified with an Oracle database 19c. Additionally, the Oracle Universal Connection Pool (UCP) should be used, which offers numerous features in the high availability environment. For example, it reacts automatically and transparently to database Notification Service (ONS) events such as an instance failure or service migration to another host. Other Connection Pool implementations like Hikari do not have these Oracle-specific features, so that error messages in case of instance failure cannot be avoided and have to be intercepted in the own code.
To include the latest Oracle JDBC driver and Universal Connection Pools (UCP) in a Maven project, these two dependencies are required in the project description “pom.xml”:
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc11</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ucp11</artifactId>
<scope>runtime</scope>
</dependency>
The Universal Connection Pool is provided with its own library in the Helidon framework, which is included as a Maven dependency. The use of the UCP is then possible via Dependency Injection (CDI). Furthermore, there are dependencies for Helidon pom.xml not only for the UCP, but also for the JTA Transaction API and also for the JPA Persistence API:
<dependency>
<groupId>io.helidon.integrations.cdi</groupId>
<artifactId>helidon-integrations-cdi-datasource-ucp</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.helidon.integrations.cdi</groupId>
<artifactId>helidon-integrations-cdi-jta-weld</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.helidon.integrations.cdi</groupId>
<artifactId>helidon-integrations-cdi-jpa</artifactId>
<scope>runtime</scope>
</dependency>
The UCP could alternatively be loaded, instantiated and configured via Java code in a self-written Java class and then registered e.g. via JNDI API, so that the instance could be fetched from anywhere in the same Java process. A simple example code is part of the Oracle JDBC documentation. Some application servers like IBM WebSphere allow the registration of datasource classes by configuration.
There is a ServletFilter class included in the Oracle JDBC driver for WildFly or for the JBoss application server, which loads and configures the UCP when loading servlets, e.g. REST services. It is named oracle.ucp.jdbc.UCPServletContextListener ; its usage with an example is described in a PDF What’s in Oracle Database 21c for Java Developers?
The same document also explains an integration possibility of the UCP in SpringBoot applications. After including the Oracle JDBC driver, the name, Java class and necessary parameters of the UCP must be included directly in the typical application.properties file. The UCP is then loaded at startup, configured and given a searchable name. This is due to the SpringBoot DataSource class “oracle.ucp.jdbc.UCPDataSource“, which is included in the JDBC driver and is loaded by Spring Framework at startup as soon as it is in the classpath. A working code example for using the UCP, with and without TAC, but without using the JPA (only spring-jdbc) is on github.com in the Oracle-Samples section for JDBC. The application.properties file there looks like this:
# For connecting to Autonomous Database (ATP) refer https://www.oracle.com/database/technologies/getting-started-using-jdbc.html # Provide the database URL, database username and database password spring.datasource.url=jdbc:oracle:thin:@dbname_alias?TNS_ADMIN=/Users/test/wallet/wallet_dbname_alias spring.datasource.username=<your-db-user> spring.datasource.password=<your-db-password> # Properties for using Universal Connection Pool (UCP) # Note: These properties require Spring Boot version greater than 2.4.0 spring.datasource.driver-class-name=oracle.jdbc.OracleDriver spring.datasource.type=oracle.ucp.jdbc.PoolDataSource # If you are using Replay datasource (=TAC) spring.datasource.oracleucp.connection-factory-class-name=oracle.jdbc.replay.OracleDataSourceImpl # Use this if you are not using Replay datasource # spring.datasource.oracleucp.connection-factory-class-name=oracle.jdbc.pool.OracleDataSource spring.datasource.oracleucp.sql-for-validate-connection=select * from dual spring.datasource.oracleucp.connection-pool-name=connectionPoolName1 spring.datasource.oracleucp.initial-pool-size=15 spring.datasource.oracleucp.min-pool-size=10 spring.datasource.oracleucp.max-pool-size=30 spring.datasource.oracleucp.fast-connection-fail-over-enabled=true
No matter if SpringBoot, Helidon or JBoss:
The difference between the use or omission of TAC lies in the used Connection Factory class (or interface) oracle.jdbc.pool.OracleDataSource or oracle.jdbc.replay.OracleDataSourceImpl. The latter class is also called the “replay driver” and is able to replay open transactions on a surviving database node. If local or “simple” user defined transactions are driven this is the right class. If it concerns distributed transactions, steered by the Java Transaction API and with XA protocol to be considered (e.g. with several involved resources at a transaction), then the class oracle.jdbc.replay.OracleXADataSourceImpl should be used. Mostly in projects the use of JTA is limited to local transactions, so that the driver can perform the “database replay” as described. But if the used database connection is actually part of a real distributed transaction and the XA protocol has to be used this will be detected and the database replay will not take place in favor of the transaction sync of the XA protocol. This avoids duplicate operations: the XA protocol (unfortunately very slow in testing) has priority over the replay driver. The remaining TAC features like the transparent connection failover and the database session replay still take place.
Similar to SpringBoot, the same applies to Java Microprofile and our Helidon example. After including the JDBC driver and the CDI plugin for the UCP, the configuration file microprofile-config.properties, which is typical for Java Microprofile, can be provided with class names, parameters and a searchable (JNDI) name. When the application is started, the UCP is loaded and configured here as well. In our example, the microprofile-config.properties file looks like this:
oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.URL=jdbc:oracle:thin:@(DESCRIPTION = (CONNECT_TIMEOUT= 3)(RETRY_COUNT=4)(RETRY_DELAY=2)(TRANSPORT_CONNECT_TIMEOUT=3) (ADDRESS_LIST = (LOAD_BALANCE=on) (ADDRESS = (PROTOCOL = TCP)(HOST=hpcexa-scan.de.oracle.com)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME = tacservice.de.oracle.com))) oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.connectionFactoryClassName=oracle.jdbc.replay.OracleDataSourceImpl oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.password=tiger oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.user=scott oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.fastConnectionFailoverEnabled=true # Checks if a connection is still valid before handing it out. Relatively slow on short-lived operations # oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.validateConnectionOnBorrow=true # Checks is a connection is still valid after an idle timeout - bit more unsafe but dow not slow down as much # oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.secondsToTrustIdleConnection=20 # If You need a custom ONS configuration, normally not required since part of TNS communication # oracle.ucp.jdbc.PoolDataSource.DeptEmpDataSource.onsConfiguration=true
Preparation of the Java project for TAC: linking the JPA Persistence Unit with the UCP
At the Java Persistence API level, all underlying frameworks such as SpringBoot, Helidon and JBoss/WildFly come together again. After the UCP has just been integrated, the JPA configuration file “persistence.xml” must now be connected to the UCP so that a JPA EntityManager can retrieve the correct classes and connections. This moment is also well suited to consider whether distributed transactions with multiple participants (“transaction_type=JTA”) are really needed, or whether it is not sufficient to use simple database transactions with exactly one database connection (“transaction_type=RESOURCE_LOCAL”). Accordingly, the replay driver configured so far would have to be replaced by the one that also handles XA transactions.
The configuration file persistence.xml (to be created by default in the same subdirectory as miroprofile-config.properties, namely “META-INF”) in our Helidon example looks as follows if distributed or JTA/XA transactions are to be used:
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence
https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="DeptEmpUnit" transaction-type="JTA">
<description>The TAC Dept/Emp database.</description>
<!-- EclipseLink as default provider in Helidon, could have been Hibernate -->
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<!-- JNDI name of Connection Pool / Data Source to use -->
<jta-data-source>DeptEmpDataSource</jta-data-source>
<class>com.oracle.tac.pushData.Department</class>
<class>com.oracle.tac.pushData.Employee</class>
<properties>
<!-- EclipseLink Properties -->
<property name="eclipselink.weaving" value="false" />
<property name="eclipselink.deploy-on-startup" value="true"/>
<property name="eclipselink.jdbc.native-sql" value="true"/>
<property name="eclipselink.logging.logger" value="JavaLogger"/>
<property name="eclipselink.logging.parameters" value="true"/>
<property name="eclipselink.target-database" value="org.eclipse.persistence.platform.database.OraclePlatform"/>
<property name="eclipselink.target-server" value="io.helidon.integrations.cdi.eclipselink.CDISEPlatform"/>
<!-- Tuning parameters for JDBC Batching -->
<property name="eclipselink.jdbc.batch-writing" value="JDBC"/>
<property name="eclipselink.jdbc.batch-writing.size" value="100"/>
</properties>
</persistence-unit>
</persistence>
The most important differences to the non-XA or non-JTA configuration are:
- transaction-type = “JTA” in the persistence-unit “DeptEmpUnit” instead of transaction-type = “RESOURCE_LOCAL”.
- jta-data-source with JNDI name of the UCP in it instead of a non-jta-data-source
The Java code for local and distributed transactions
The entire executable Helidon sample project with configuration files and complete Java code is available for download or via “git clone” at github.com/ilfur/tac_helidon_jpa. We would like to excerpt a few lines here to show the difference between local and distributed transactions. The Java code shown should not differ much between WildFly, SpringBoot and Helidon either. Only the Java imports would have to be different, so Helidon uses already completely the jakarta libraries, while SpringBoot and WildFly use in some places still Java EE libraries with class imports from the “javax” namespace.
In the example, a Java class “DbConnect.java” provides a REST service that reads, inserts and deletes data from a database table “EMP”. Insertion and deletion are each done in a separate transaction.
In the case of a (distributed) transaction, in our example a container managed transaction (the framework manages transactions, not its own code) with the XA-Replay driver and a jta-datasource, the class with the example REST service must first load a PersistenceContext and reference the PersistenceUnit defined in the persistence.xml file in the previous section:
@PersistenceContext(unitName="DeptEmpUnit") private EntityManager em;
An example method for inserting new employees does not have to open and close a transaction manually, but only marks via an annotation @Transactional that it would be part of a new or existing transaction. A simple “em.persist(…)” is enough, the framework then decides when actually the record gets to the database and when the transaction is closed:
@GET
@Path("/addEmps")
@Produces(MediaType.APPLICATION_JSON)
@Transactional
public Response addEmps() {
try {
Employee e = null;
LOGGER.info("Adding Employees....");
for (int i=10000 ; i<11000; i++) {
e = new Employee();
e.setDepartmentNo ( Long.valueOf(30) );
e.setEName ( "BOERMANN" );
e.setEmpNo (Long.valueOf(i));
e.setJob ("ENGINEER");
em.persist(e);
}
} catch (RuntimeException e) {
LOGGER.error(e.getMessage());
return Response.status(500).build();
}
return Response.ok(Json.createObjectBuilder().add("action","ok").build(), MediaType.APPLICATION_JSON).build();
}
For a local transaction with “RESOURCE_LOCAL” configuration in persistence.xml, the Java code should use a database transaction instead of a JTA transaction, which can be retrieved from the included entity manager. But first this Java class must also find an entity manager. This is not possible with a PersistenceContext annotation which directly returns an EntityManager. First a PersistenceUnit must be specified, which returns an EntityManagerFactory. From that point, EntityManager and database transaction can be fetched if necessary.
@PersistenceUnit(unitName="DeptEmpUnit") private EntityManagerFactory emf;
The same method as in the JTA/XA case now retrieves an EntityManager from the EntityManagerFactory, starts a database transaction (just not a JTA/XA transaction) and completes it by itself:
@GET
@Path("/addEmps")
@Produces(MediaType.APPLICATION_JSON)
public Response addEmps() {
try {
EntityManager em = emf.createEntityManager();
EntityTransaction entityTransaction = em.getTransaction();
entityTransaction.begin();
Employee e = null;
LOGGER.info("Adding Employees....");
for (int i=10000 ; i<11000; i++) {
e = new Employee();
e.setDepartmentNo ( Long.valueOf(30) );
e.setEName ( "BOERMANN" );
e.setEmpNo (Long.valueOf(i));
e.setJob ("ENGINEER");
em.persist(e);
}
entityTransaction.commit();
em.close();
} catch (RuntimeException e) {
LOGGER.error(e.getMessage());
e.printStackTrace();
return Response.status(500).build();
}
return Response.ok(Json.createObjectBuilder().add("action","ok").build(), MediaType.APPLICATION_JSON).build();
}
Why is a PersistenceContext loaded in one case and a PersistenceUnit in the other ? The difference is that when the PersistenceContext is loaded, not only the PersistenceUnit is loaded, but a transaction manager is also attached to the PersistenceContext in the background. You could tell an EntityManager afterwards that it is part of a global transaction, but this might lengthen and complicate the code and didn’t really work for us… maybe you will have more success with this than we did, and we would be very happy to get feedback from you !
The failure tests and the test findings
Thanks to batching operations, inserting new employee objects was too fast for failover tests. So we built a cumbersome way to delete employee objects again: Each object is first searched and read by its employee ID, then deleted. This operation took between 20 and 40 seconds with 1000 employees and a DSL VPN line with high latency (25ms). Enough time to simulate a crash during this time and see how the frameworks react.
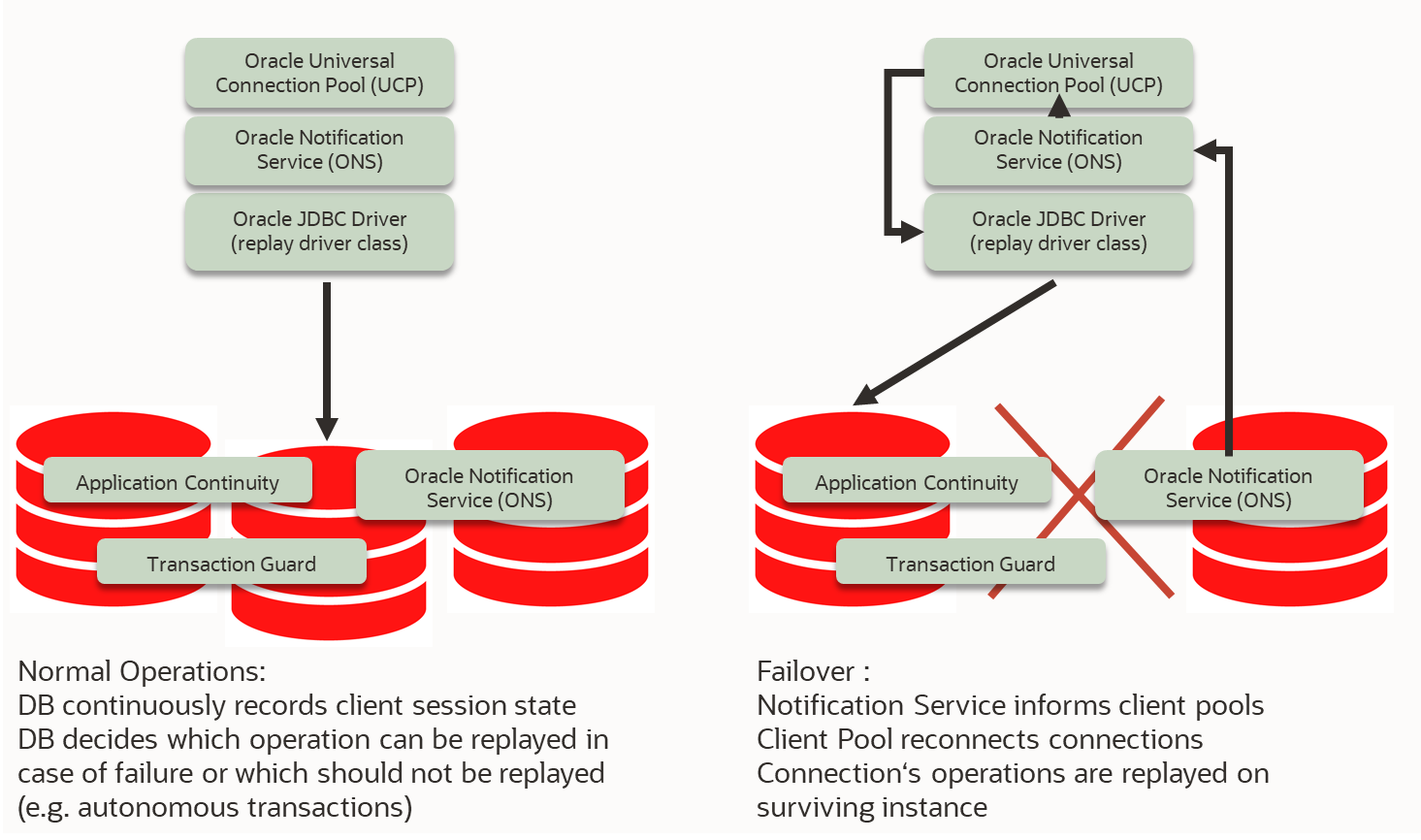
The database stores session states of the clients, i.e. remembers replayable SQL operations.
If a node fails, ONS informs the client connection pools. These establish new connections.
Transactions that are still open are retraced in the database.
Planned outage: Service move to new node
Unplanned failure: Service termination or listener shutdown
To simulate a planned outage, e.g. to patch a database node and enable rolling updates, the database service that the Java program had connected to is moved. The command for the service move in our sample environment was as follows:
srvctl relocate service -db cdb19a -service tacservice -oldinst cdb19a1 -newinst cdb19a2 -force -stopoption IMMEDIATE
The Java program with local transactions without using JTA and XA ran cleanly without error messages and took only about one second longer than a run without database interruption. The Employee objects had also been deleted from the database. This means that the notification of the connection pool by the ONS was timely, the open transaction on the already booted node was followed up and completed. There was no error message in the log of the Java application, only a new database connection was retrieved when the service was down.
The Java program with JTA/XA configuration initially encountered error messages from the transaction manager after more than a minute, which aborted the operation and returned an HTTP error 500 (“internal server error”) to the caller of the REST service. The records had not been deleted from the database either. After increasing the Java program’s JTA/XA transaction timeout to 3 minutes, the failover was again able to go through cleanly and without error message, deleting all records. The operation took more than 1:15 minutes to get to the end. This is where the XA protocol struck: instead of re-executing all the commands flagged by the database in a “replay” operation, all the commands were synced between the transaction server and the database, operation by operation, and then continued with a new database connection but in the same distributed transaction. These sync operations lengthened the execution very much, especially for high latency connections like ours (DSL VPN with 25ms latency). But even here, all records were ultimately processed cleanly, i.e. deleted.
Small hint: the Helidon framework as well as other Jakarta EE 9.1 compliant frameworks certainly use “Arjuna” as transaction manager. To configure the transaction timeout there, a small system property at the start of the Java program like this is sufficient:
-Dcom.arjuna.ats.arjuna.coordinator.defaultTimeout=180
The unplanned shutdown abort tests the behavior of the Notification Service and its cooperation with the Java clients: if the database is suddenly missing, all clients with their running operations must notice this. A standard TCP timeout for a running network operation (fetch data, send SQL to database,…) is often 3 minutes. The ONS should reduce this timeout to a minimum by passing the very short wait times within the RAC to the clients and their UCPs. These tests also worked as expected, running operations like deleting employees now took (thanks to tight timeouts in the RAC) about 3 seconds longer in simulated failure compared to a normal run without database interruption. Again, this applies to non-XA and XA transactions, although the already long runtime of an XA recovery was hardly measurably extended, 3 seconds was within tolerable measurement inaccuracy.
Conclusion:
From our point of view, the JDBC Replay driver in combination with the Universal Connection Pool enables smooth operation without interceptable error messages and hardly measurable waiting times when a RAC database node fails. Modern Java frameworks like SpringBoot, Helidon, Micronaut, WildFly are either directly supported or should still be easily linkable to the Oracle UCP to support a node failure smoothly and transparently. In any case, it is worth considering whether previously used JTA transactions accidentally mutate into XA transactions or whether one should not completely dispense with JTA transactions on a case-by-case basis. Regardless of which mode one chooses, there will still be no interruption. The only question that remains is that of latency and thus performance.
Links:
Explanation and Set-Up of Transparent Application Continuity
Presentation “Application Continuity explained”
Source Code of example program with Helidon, UCP, JPA, TAC
Oracle JDBC Documentation on UCP
Example program with UCP, SpringBoot and spring-jdbc
Example program with UCP, Spring Boot, GraphQL, JPA
White paper “Whats in database 21c for Developers” ?