![]() Provide a test environment at the touch of a button to let analysts and developers explore the necessary SQL queries, AI prompts and visualizations. With your own data and with a GIT connection to store and reuse versions of the knowledge gained. And the whole thing on-premises and cloud-portable? Kubernetes, containers and helm charts make it possible. Here using the example of the Oracle Graph Server with UI, linked Jupyter notebooks and sqlplus command line and test data.
Provide a test environment at the touch of a button to let analysts and developers explore the necessary SQL queries, AI prompts and visualizations. With your own data and with a GIT connection to store and reuse versions of the knowledge gained. And the whole thing on-premises and cloud-portable? Kubernetes, containers and helm charts make it possible. Here using the example of the Oracle Graph Server with UI, linked Jupyter notebooks and sqlplus command line and test data.
As part of the blog series “will it blend?” or “does it fit into the mixer?”, this time I wanted to try running the Oracle Graph Server for the visualization and analysis of property and RDF graphs under Kubernetes. However, the Graph Server alone makes little sense, as many examples and demos available on the Internet are based on Jupyter or Zeppelin Notebooks. The Graph Server UI also does not offer the option of storing or documenting queries and diagrams. It is therefore better to include a runtime for notebooks in the package. Naturally with a connection to an existing Oracle database and to a selectable GIT repository in order to download and maintain notebooks live. Of course, such packages are already available as a solution in the Oracle Cloud: each Autonomous Database Service comes with analysis tools and its own graph server. The Data Science Cloud Service also offers versionable analysis environments at the touch of a button. This blog therefore deals with an on-premises aspect, a Kubernetes software package with the necessary tools, with connectivity options and, on top of that, portability to other e.g. cloud-based Kubernetes environments.
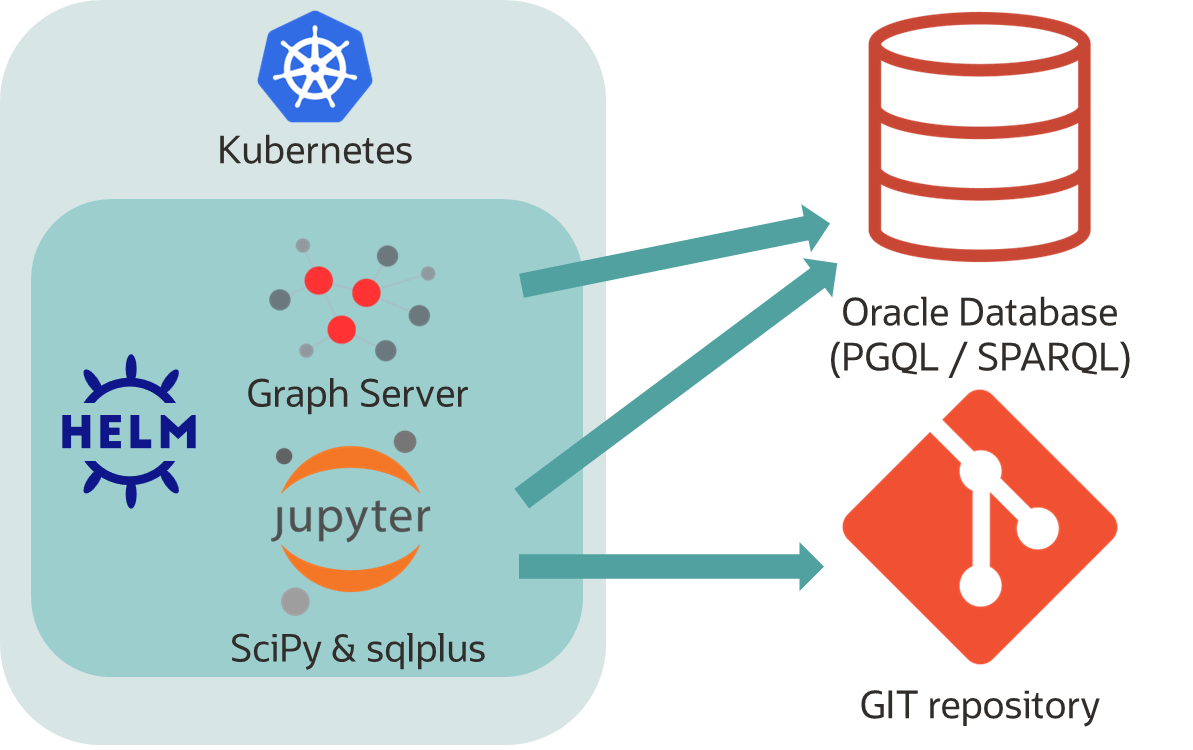
Let’s go straight into medias res! The following points are to be dealt with:
Creation of a container image for the Oracle Graph Server
Explanation of automated customization of the jupyter standard image “scipy”
Preconditions for the setup under Kubernetes
Setting up the helm chart via command line
Feature description and solution clickthrough
Creation of a container image for the Oracle Graph Server
Unlike many other Oracle components, the Oracle Graph Server is not available as a standard image on container-registry.oracle.com. This means we have to create an image ourselves. There is also no standard script for creating a Graph Server image on github.com/oracle/docker-images. However, there is a description in the form of a two-part blog from our Graph Product Management on how to create a container image:
https://medium.com/oracledevs/build-oracle-graph-on-docker-part-1-2-5fcacaca430e
https://medium.com/oracledevs/build-oracle-graph-on-docker-part-2-2-407827b0b93
The blog describes how to download the software from edelivery.oracle.com and use the docker build command to create an image that sets up the Graph Server with self-signed certificates. A docker file required for this is also provided there. An existing Oracle database is also prepared with test data and a database user with the necessary authorizations, e.g. the GRAPH_DEVELOPER role.
Unfortunately, the image described in the blog is started as the root user and requires the database connect to be entered manually in the configuration files. I have therefore optimized the Dockerfile a little and used an oracle user to start the Graph Server. The start command in the later Helm Chart inserts the database connection automatically.
Here is the customized Dockerfile for documentation purposes:
FROM oraclelinux:8
ARG VERSION_JDK
ARG VERSION_OPG
COPY ./jdk-${VERSION_JDK}_linux-x64_bin.rpm /tmp
COPY ./oracle-graph-${VERSION_OPG}.x86_64.rpm /tmp
RUN yum install -y unzip zip numactl gcc libgfortran python3.8 \
&& yum clean all \
&& rm -rf /var/cache/yum/* \
&& rpm -ivh /tmp/jdk-${VERSION_JDK}_linux-x64_bin.rpm \
&& rpm -ivh /tmp/oracle-graph-${VERSION_OPG}.x86_64.rpm \
&& rm -f /usr/bin/python3 /usr/bin/pip3 \
&& ln /usr/bin/python3.8 /usr/bin/python3 \
&& ln /usr/bin/pip3.8 /usr/bin/pip3 \
&& pip3 install oracle-graph-client==24.4.0 \
&& groupadd -g 54322 dba \
&& useradd -u 54321 -d /home/oracle -g dba -m -s /bin/bash oracle \
&& chown oracle:dba /home/oracle \
&& chown -R oracle:dba /var/log/oracle/graph \
&& chown -R oracle:dba /etc/oracle/graph \
&& chown -R oracle:dba /opt/oracle/graph
ENV JAVA_HOME=/usr/lib/jvm/jdk-17.0.13-oracle-x64
ENV PATH=$PATH:/opt/oracle/graph/bin
ENV SSL_CERT_FILE=/etc/oracle/graph/ca_certificate.pem
ENV PGX_SERVER_KEYSTORE_PASSWORD=changeit
RUN keytool -importkeystore \
-srckeystore /etc/oracle/graph/server_keystore.jks \
-destkeystore $JAVA_HOME/lib/security/cacerts \
-deststorepass changeit \
-srcstorepass changeit \
-noprompt
COPY server_ssl.conf /etc/oracle/graph
USER oracle
ENV JAVA_HOME=/usr/lib/jvm/jdk-17.0.13-oracle-x64
ENV PATH=$PATH:/opt/oracle/graph/bin
ENV SSL_CERT_FILE=/etc/oracle/graph/ca_certificate.pem
ENV PGX_SERVER_KEYSTORE_PASSWORD=changeit
EXPOSE 7007
WORKDIR /opt/oracle/graph/bin
CMD ["sh", "/opt/oracle/graph/pgx/bin/start-server"]
You can see that the Graph Server is set up and started with a supplied self-signed certificate without any further adjustments. The Helm Chart, which will be explained later, can influence this via suitable parameters by starting the Graph Server with certificates inserted from outside or optionally without any encryption at all, as this is usually carried out by a preceding gateway or an ingress that carries out SSL termination at a central point in the cluster.
Speaking of SSL, an additional configuration file is copied into the image for later optional use with information on certificates that are provided by Kubernetes means. The file is named server_ssl.conf and looks like this:
{
"port": 7007,
"enable_tls": true,
"server_private_key": "/cert/tls.key",
"server_cert": "/cert/tls.crt",
"enable_client_authentication": false,
"working_dir": "/opt/oracle/graph/pgx/tmp_data"
}
An example call to create a Docker image from this Dockerfile could look like this:
podman build . -f Dockerfile --tag graph-server:24.4.0 --build-arg VERSION_OPG=24.4.0 --build-arg VERSION_JDK=17.0.13 podman tag graph-server:24.4.0 fra.ocir.io/frul1g8cgfam/pub_graphserver:24.4.0 podman push fra.ocir.io/frul1g8cgfam/pub_graphserver:24.4.0
Instead of a docker command, I use podman here, and the versions of the Graph Server and JDK downloaded in advance from edelivery.oracle.com are 24.4.0 and 17.0.13 respectively. In this example, the image is uploaded to the Oracle Cloud after it has been created. These steps have already been completed for you: Please feel free to use a previously created image for testing purposes only, it does not require a password for the download. The above image URL is already entered in the Helm Chart, i.e. you do not need to make a note of anything here.
Explanation of automated customization of the Jupyter standard image “scipy”
Together with the Graph Server, a Jupyter container is set up for the execution and creation of notebooks, i.e. documented scripts and their execution results. Research protocols if you like, mostly with Python code and embedded SQL or REST service calls. The container used is one of numerous scipy standard containers for different environments, for example with and without GPU, with and without Java, JavaScript etc. support. The source code and various links to prepared containers can be found on github: https://github.com/jupyter/docker-stacks. In our example environment, a relatively up-to-date scipy image on quay.io is used: quay.io/jupyter/scipy-notebook:2024-05-27. It is already entered in the Helm Chart, so you do not need to make any notes here either.
 Jupyter containers have integrated git support by default, i.e. the git tool is available on the terminal interface, and the menus in the notebooks also offer git operations such as push, commit, etc. When the container is started, a shell script is executed which sets the selectable password for the Jupyter environment (default here: jupyter) and also loads some notebooks from a public git repository. The URL used for this can be freely selected when setting up the Helm chart if you prefer to use a personal git repostory.
Jupyter containers have integrated git support by default, i.e. the git tool is available on the terminal interface, and the menus in the notebooks also offer git operations such as push, commit, etc. When the container is started, a shell script is executed which sets the selectable password for the Jupyter environment (default here: jupyter) and also loads some notebooks from a public git repository. The URL used for this can be freely selected when setting up the Helm chart if you prefer to use a personal git repostory.
The shell script just mentioned is executed in a so-called initContainer. It configures the actual application container shortly before it is started so that no separate image needs to be created. The script is stored in a Kubernetes ConfigMap. You can change and adapt this ConfigMap at a later date. All you need to do after making changes is to restart the Kubernetes Pod, i.e. delete it – it will then be restarted by Kubernetes.
The Jupyter container receives the connection information to the Graph Server and the linked database via environment variables JDBC_URL and GRAPH_URL. The sample notebooks automatically loaded by the git clone command read these and connect to the database and Graph Server.
The Jupyter container also downloads the Oracle instant client and sqlplus at startup and sets up both so that notebooks and the shell terminal, which is also included, can connect to Oracle databases. The Oracle driver oracledb, which is written in Python, normally does not require an instant client installation. But not in every case, e.g. the shared libraries of the instant client are used for certain encryption mechanisms.
Depending on the Jupyter notebook used, the Oracle driver, a Graph Server Client, Java Runtime and visualization libraries (currently still vis.js or pyvis, not the Oracle Visualization Libraries for JavaScript) are installed. The automatically downloaded notebooks have been adapted, but are based on examples from Oracle Graph Product Management on github, e.g. the pgx samples.
Preconditions for the setup under Kubernetes
Most of the listed preconditions are rather optional but certainly useful:
Installation tool:
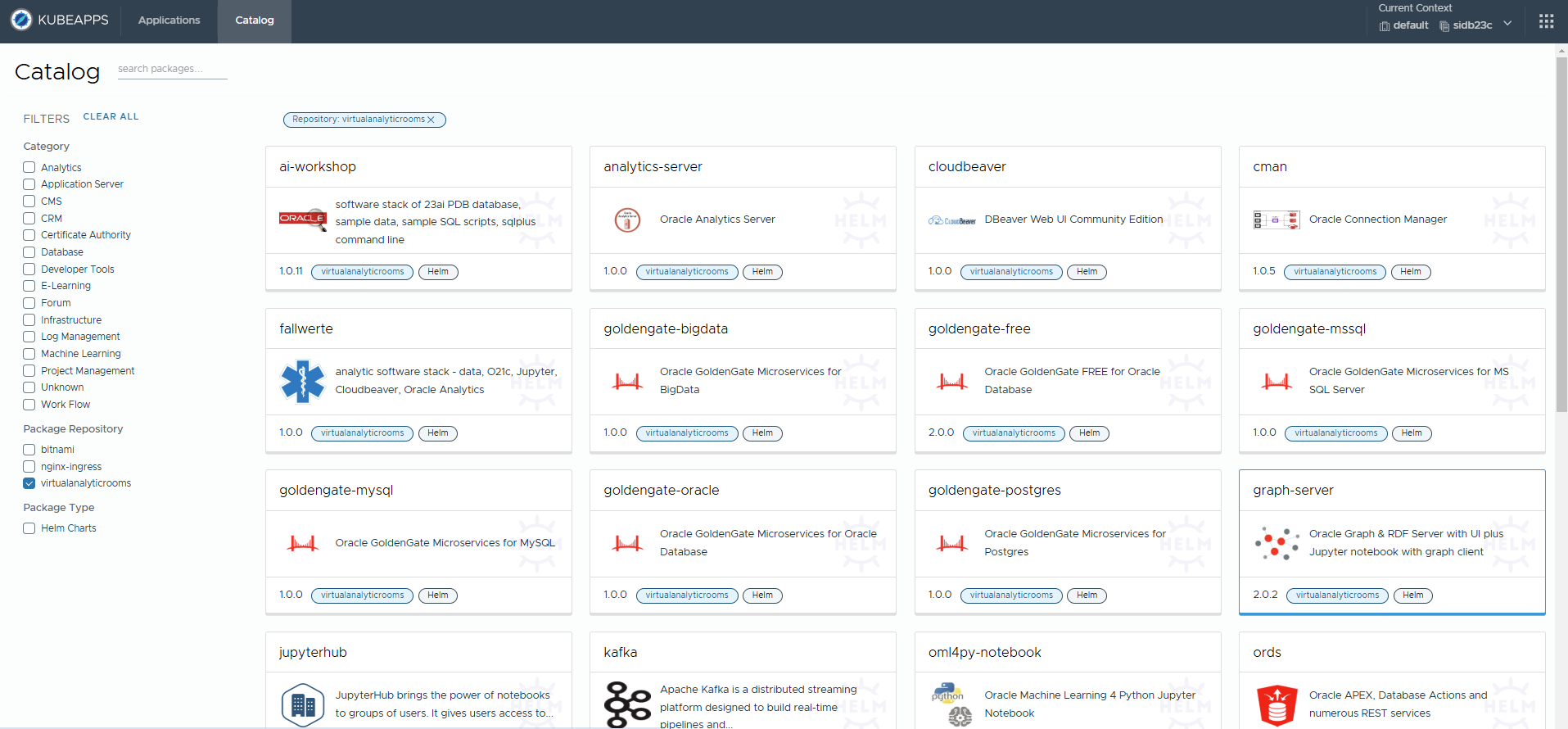
Instead of installing the Helm Chart via the command line, a graphical browser interface offers more convenience and enables developers and analysts to quickly set up their own environment via self-service and with just a few clicks. To do this, create Kubernetes user accounts in advance with authorizations, e.g. only for a specific designated namespace. A suitable tool for interactive deployments is kubeapps, for example. It can be installed very easily via helm from the bitnami chart repository and is also recommended by other Kubernetes distributions such as tanzu. In this blog, however, I will explain the installation via the command line using helm. To do this, the tool should be installed on a computer that already has access to your Kubernetes cluster, e.g. via kubectl, i.e. that has a valid kubeconfig file.
Internet access of the cluster:
During the installation and also through the Jupyter notebooks themselves, a few zip files and two container images are downloaded from the Internet. The installation routine, i.e. the helm chart, is also downloaded and executed. This means that your Kubernetes cluster should have Internet access, otherwise the installation will be a little more difficult. This is because you can freely specify the location of the container images during installation and copy them to your private repository before installation. Necessary Python libraries such as the Oracle Graph Client, Oracle database driver, JDK 17 and its installation routines, which are loaded into the notebooks, would have to be specified in the notebooks themselves and/or loaded into the Jupyter container via a browser. The Oracle instant client would also have to be obtained elsewhere in the provided ConfigMap or in the initialization script and entered there. The connected git repository for Jupyter Notebooks on github.com should be accessible – a URL other than the default can be specified during installation. The helm chart itself can also be downloaded in advance and can be used locally.
Browser access towards the cluster:
To be able to use the Graph Server and Jupyter Container user interfaces, Kubernetes services of type ClusterIP are first set up. You can choose whether you want to attach your own Kubernetes resources to address these services outside the Kubernetes cluster. For example, you could configure port-forwarding for test purposes to see whether the services are functional at all. Or you could change the type of services from ClusterIP to NodePort or LoadBalancer in order to talk to the containers directly from outside. However, under Kubernetes services are usually integrated via a central gateway, an Ingress or a VirtualService decides to which container a browser request is forwarded. The helm chart supports istio VirtualServices or optionally a kubernetes Ingress with selectable IngressClass (e.g. nginx, traefik or istio) for this purpose. An OpenShift Route would have to be defined manually; you are welcome to deactivate support for gateways, ingresses and VirtualServices during installation.
Storage and in-house network access of the cluster:
The containers set up do not use any persistent storage themselves, i.e. no volumes and no persistent volume claims. They obtain their structures and statuses from an external Oracle database with its data and graphs and from a git repository with notebooks. All components not present in the container image are loaded and installed at startup. However, Kubernetes ConfigMaps and Secrets also count as storage. ConfigMaps are created by the Helm Chart. Secrets (passwords, certificates, ssh-keys) must be created in advance and are integrated via the Helm Chart. Secrets are optional, i.e. they are not used by default. Please make sure that the Oracle database to be integrated is accessible from the Kubernetes cluster (firewall, routing, name resolution) as well as all other components that can be reached via the internal network instead of the Internet, such as git repository, container registry, download server of the Instant Client, Python libraries and JDK.
Setting up the helm chart via command line
Before installation, please create a namespace in Kubernetes into which you can install and test undisturbed. For example graph-server:
$ kubectl create namespace graph-server namespace graph-server created
Then include a helm chart repository with a creatively descriptive name, perhaps better than the myorarepo chosen here. The repository is provided via github (https://ilfur.github.io/VirtualAnalyticRooms/) and contains the graph-server chart. Then list all the charts available in it for testing purposes:
$ helm repo add myorarepo https://ilfur.github.io/VirtualAnalyticRooms/ "myorarepo" has been added to your repositories $ helm repo list artifact-hub https://artifacthub.github.io/helm-charts/ argo-cd https://argoproj.github.io/argo-helm bitnami https://charts.bitnami.com/bitnami myorarepo https://ilfur.github.io/VirtualAnalyticRooms/ $ helm search repo myorarepo NAME CHART VERSION APP VERSION DESCRIPTION myorarepo/graph-server 2.0.2 24.4.0.0.0 Oracle Graph & RDF Server with UI plus Jupyter ... myorarepo/ai-workshop 1.0.11 23.4.0 software stack of 23ai PDB database, sample dat... myorarepo/cloudbeaver 1.0.0 21.3.3 DBeaver Web UI Community Edition myorarepo/cman 1.0.5 23.5.0.0 Oracle Connection Manager myorarepo/goldengate-free 2.0.0 23.4.0.0.0 Oracle GoldenGate FREE for Oracle Database myorarepo/ords 2.0.0 latest Oracle APEX, Database Actions and numerous REST... myorarepo/radlaufstellen 1.0.0 21.3.0 analytic software stack of machine learning dat... myorarepo/sqlcl-liquibase 1.0.0 21.3.0.0.0 Oracle sqlcl with liquibase integration myorarepo/varraddauerzaehlstellen 1.0.3 21.3.0 analytic software stack - data, O21c, Jupyter, ... ... ...
In addition to the graph-server chart, the integrated repository myorarepo also contains other charts for Oracle components such as Goldengate, ORDS, Connection Manager, etc. All chart source codes are also available for customization at https://github.com/ilfur/VirtualAnalyticRooms. Most charts currently still use older container images and are not quite as flexible. They should therefore serve more as a source for your own ideas and customizations.
Now download the parameter file for the graph-server chart to have a look at it and customize it to your own needs. For the sake of simplicity, I recommend a setup without SSL encryption and without Ingress, just to check if the setup works. You can then undo the installation (uninstall) and try again with different parameters.
$ helm show values myorarepo/graph-server >myvalues.yaml $ cat myvalues.yaml image: pullPolicy: IfNotPresent graph: fra.ocir.io/frul1g8cgfam/pub_graphserver:24.4.0 jupyter: quay.io/jupyter/scipy-notebook:2024-05-27 services: ### a clusterIP type service will be created for graph and jupyter UIs. ### You can choose to create an istio virtualservice or an ingress in front of it ### with a virtual host name of <vhostName> external: ### set type to either ingress , virtualservice or none if You need something customized type: ingress ### typical ingressClasses are nginx and istio ingressClass: nginx ### ignored if type is not virtualservice vserviceGateway: istio-system/http-istio-gateway vhostName: 141.147.33.9.nip.io internal: graph: ### graph server can run with no ssl (ssl: "off") or with self-signed certificates (ssl: selfsigned) or with external certificates(ssl: secret). ssl: "off" ### should container tls.cert and tls.key entries, but is ignored when ssl is off or selfsigned. tlsSecretName: graph-tls jupyter: ### currently, only ssl: off and ssl: selfsigned are working, but will in the near future ssl: "off" ### should container tls.cert and tls.key entries, but is ignored when ssl is off or selfsigned. tlsSecretName: graph-tls database: ## The database user must have at least GRAPH_DEVELOPER role connection: "jdbc:oracle:thin:@db23c.sidb23c:1521/FREEPDB1" git: ## use this https repository for samples, better use ssh repositories for Your own purposes jupyterRepo: "https://github.com/ilfur/pgx_samples" type: public ## sshKey is ignored if repo type is public. no push possible then. sshKeySecretName: git-ssh jupyter: password: jupyter deployJupyter: true
Now adapt some parameters to your circumstances. The columns in which the parameters are entered are typical for YAML file formats. Therefore, please keep the text indentations!
At least the database connect (database.connection parameter) should refer to your database, not to my test database FREEPDB1. Incidentally, version 23ai is not absolutely necessary, but you are welcome to use an Oracle 23ai free container image for tests. You do not need to enter a database user here, as this will only be requested when you log in to the user interface. Your test database should offer a pre-created user who, in addition to typical CONNECT, CREATE and SELECT rights, also has a GRAPH_DEVELOPER role.
The parameter services.external.type should perhaps also be set to “off” as a test (with the quotation marks, please, so that the parameter is not accidentally interpreted as a boolean data type!) Because initially you are probably more interested in whether the containers can start and set themselves up.
If you are only interested in the Graph Server and not the combination with Jupyter, you can set the parameter jupyter.deployJupyter to false. This simplifies the setup quite a bit, the Jupyter container is then not set up at all.
Further rather optional parameters:
The two containers can either communicate internally without SSL, i.e. in plain HTTP, and the gateway secures access from outside via SSL. Or you can define selfsigned certificates for internal encryption in the service.internal.graph.type or service.internal.jupyter.type parameter, in which case the two containers generate their own certificates and listen in encrypted form with certificates that are actually invalid. Incidentally, these are rejected by the Oracle Graph Client in Jupyter, a connection to the Graph Server only works if the root certificate that is also generated is copied into the JDK of the Jupyter container. This is not yet done automatically. For the service.internal.graph.type secret, certificates must be stored in a Kubernetes secret. The keys to be used are tls.key and tls.crt, the standard names for certificate secrets that are assigned by the optional and convenient Kubernetes tool cert-manager. The Jupyter container is currently not yet able to handle the type secret, this has yet to be added.
The integrated public git repository for the demo notebooks is accessed anonymously via https, not via ssh. And without specifying a password, because it is a public repository. This means that no further git operations are possible in Jupyter, but the notebooks can still be downloaded when the container is started. If you have your own git repository, you are welcome to enter its ssh:… URL and store the files required for SSH access in a Kubernetes secret with the default name git-ssh. These files are copied into the .ssh directory of the container user and should have the names id_rsa, known_hosts and config. Please set the git.type parameter to any value other than public, e.g. protected. I can send you an example on request, but at the moment it may be too early.
Finally, as a parameter for the automatic configuration of the Jupyter container, a selectable unencrypted password for the user interface in the parameter jupyter.password. Perhaps a secret would be more suitable at this point, but there must still be room for improvement and further consultation.
Have you now adapted the parameter file to your requirements? Then let’s start the installation and see if the container setup worked.
The following helm command installs the chart with the parameter file “myvalues.yaml” into the previously created namespace graph-server. Once the installation is complete, an information text appears with URLs and further information on usage.
$ helm install graph-test myorarepo/graph-server --values myvalues.yaml -n graph-server NAME: graph-test LAST DEPLOYED: Fri Jan 10 08:58:29 2025 NAMESPACE: graph-server STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: Final NOTES: The graph server is pointing to this database: jdbc:oracle:thin:@db23c.sidb23c:1521/FREEPDB1 When entering a database user and password, please be aware that this database user must have the GRAPH_DEVELOPER role granted plus standard roles to connect and select data. You decided not to have an ingress or virtualservice configured. So currently, Your graph server and jupyter are reachable only from within the kubernetes cluster, using these names and ports: http://graph-test-graph-server-svc:7007 http://graph-test-graph-server-jup-svc:8080 The Jupyter container uses environment variables JDBC_URL and GRAPH_URL, pointing to the database and the graph server: JDBC_URL=jdbc:oracle:thin:@db23c.sidb23c:1521/FREEPDB1 GRAPH_URL= http://graph-test-graph-server-svc:7007 In jupyter, the Oracle instant client and sqlplus are preinstalled, so You can open a shell in the Jupyter UI and try to connect to Your database with sqlplus too: (Menu File-> New -> Terminal) Then, in the terminal, cd into the directory /home/jovyan/.jupyter/instantclient_23_6 and run ./sqlplus Have fun !
The information text shows generated URLs from the parameter file. For example, if you have switched off Ingress or VirtualService generation (services.external.type to off), as in my case, then the information appears that the containers are currently only accessible within the Kubernetes cluster. But let’s take a look at this together.
Have the containers been downloaded and started, have services been created and a ConfigMap with a start script in it?
$ kubectl get pod -n graph-server NAME READY STATUS RESTARTS AGE graph-test-graph-server-graph-57cc896d66-vq6d8 1/1 Running 0 4m24s graph-test-graph-server-jupyter-857c67b68d-smj4w 1/1 Running 0 4m24s $ kubectl get service -n graph-server NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE graph-test-graph-server-jup-svc ClusterIP 10.109.167.233 <none> 8080/TCP 4m58s graph-test-graph-server-svc ClusterIP 10.101.53.38 <none> 7007/TCP 4m58s $ kubectl get configmap -n graph-server NAME DATA AGE graph-test-graph-server-config 2 5m23s
In addition to a shared library “libaio.so.1” for the Oracle instant client, the ConfigMap contains a shell script that you can customize later to influence the start and configuration of the Jupyter container. You are welcome to remove the instant client installation completely. Here is an excerpt from the ConfigMap:
$ kubectl get configmap -n graph-server graph-test-graph-server-config -o yaml
...
data:
getfiles.sh: |-
echo "# my notebooks settings
c = get_config()
from jupyter_server.auth import passwd
password = passwd('jupyter')
c.NotebookApp.password = password
c.NotebookApp.base_url = '/jupyter/'
" >> /home/jovyan/.jupyter/jupyter_server_config.py
wget https://download.oracle.com/otn_software/linux/instantclient/2360000/instantclient-basic-linux.x64-23.6.0.24.10.zip
wget https://download.oracle.com/otn_software/linux/instantclient/2360000/instantclient-sqlplus-linux.x64-23.6.0.24.10.zip
unzip instantclient-basic-linux.x64-23.6.0.24.10.zip -d /home/jovyan/.jupyter
unzip instantclient-sqlplus-linux.x64-23.6.0.24.10.zip -d /home/jovyan/.jupyter
cp /scripts/libaio.so.1 /home/jovyan/.jupyter/instantclient_23_6
cd /home/jovyan/work
git clone https://github.com/ilfur/pgx_samples
kind: ConfigMap
...
Then we take a look at the logs of the two containers. Is the graph server starting properly?
$ kubectl logs graph-test-graph-server-graph-57cc896d66-vq6d8 -n graph-server starting Jan 10, 2025 9:20:06 AM org.apache.coyote.AbstractProtocol init INFO: Initializing ProtocolHandler ["http-nio-7007"] Jan 10, 2025 9:20:06 AM org.apache.catalina.core.StandardService startInternal INFO: Starting service [Tomcat] Jan 10, 2025 9:20:06 AM org.apache.catalina.core.StandardEngine startInternal INFO: Starting Servlet engine: [Apache Tomcat/9.0.90] Jan 10, 2025 9:20:11 AM org.apache.catalina.startup.ContextConfig getDefaultWebXmlFragment INFO: No global web.xml found Jan 10, 2025 9:20:12 AM org.apache.jasper.servlet.TldScanner scanJars INFO: At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time. TeeFilter will be ACTIVE on this host [graph-test-graph-server-graph-57cc896d66-vq6d8] Jan 10, 2025 9:20:22 AM org.glassfish.jersey.server.wadl.WadlFeature configure WARNING: JAXBContext implementation could not be found. WADL feature is disabled. Jan 10, 2025 9:20:24 AM org.apache.coyote.AbstractProtocol start INFO: Starting ProtocolHandler ["http-nio-7007"]
As described above, the Jupyter Pod consists of two containers, an init container called get-config and an application container called app. Both generate logs, which we can view as follows – only excerpts, because the file download generates many lines of log:
$ kubectl logs graph-test-graph-server-jupyter-857c67b68d-smj4w -n graph-server get-config
--2025-01-10 09:20:06-- https://download.oracle.com/otn_software/linux/instantclient/2360000/instantclient-basic-linux.x64-23.6.0.24.10.z
ip
Resolving download.oracle.com (download.oracle.com)... 23.32.100.101
Connecting to download.oracle.com (download.oracle.com)|23.32.100.101|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127839197 (122M) [application/zip]
Saving to: ‘instantclient-basic-linux.x64-23.6.0.24.10.zip’
0K .......... .......... .......... .......... .......... 0% 32.0M 4s
50K .......... .......... .......... .......... .......... 0% 7.24M 10s
100K .......... .......... .......... .......... .......... 0% 29.0M 8s
...
$ kubectl logs graph-test-graph-server-jupyter-857c67b68d-smj4w -n graph-server app
Entered start.sh with args: start-notebook.py
Running hooks in: /usr/local/bin/start-notebook.d as uid: 1000 gid: 100
Done running hooks in: /usr/local/bin/start-notebook.d
Running hooks in: /usr/local/bin/before-notebook.d as uid: 1000 gid: 100
Sourcing shell script: /usr/local/bin/before-notebook.d/10activate-conda-env.sh
Done running hooks in: /usr/local/bin/before-notebook.d
Executing the command: start-notebook.py
[I 2025-01-10 09:20:41.881 ServerApp] Extension package jupyterlab_git took 0.1680s to import
[W 2025-01-10 09:20:41.946 ServerApp] A `_jupyter_server_extension_points` function was not found in nbclassic. Instead, a `_jupyter_server_extension_paths` function was found and will be used for now. This function name will be deprecated in future releases of Jupyter Server.
[I 2025-01-10 09:20:41.958 ServerApp] jupyter_lsp | extension was successfully linked.
[I 2025-01-10 09:20:42.141 ServerApp] jupyter_server_mathjax | extension was successfully linked.
[I 2025-01-10 09:20:42.178 ServerApp] jupyter_server_terminals | extension was successfully linked.
[W 2025-01-10 09:20:42.587 LabApp] 'password' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[W 2025-01-10 09:20:42.587 LabApp] 'base_url' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[W 2025-01-10 09:20:42.598 ServerApp] ServerApp.password config is deprecated in 2.0. Use PasswordIdentityProvider.hashed_password.
[I 2025-01-10 09:20:42.598 ServerApp] jupyterlab | extension was successfully linked.
[I 2025-01-10 09:20:42.599 ServerApp] jupyterlab_git | extension was successfully linked.
[I 2025-01-10 09:20:42.612 ServerApp] nbclassic | extension was successfully linked.
[I 2025-01-10 09:20:42.612 ServerApp] nbdime | extension was successfully linked.
[I 2025-01-10 09:20:42.625 ServerApp] notebook | extension was successfully linked.
[I 2025-01-10 09:20:42.627 ServerApp] Writing Jupyter server cookie secret to /home/jovyan/.local/share/jupyter/runtime/jupyter_cookie_secret
[I 2025-01-10 09:20:45.384 ServerApp] notebook_shim | extension was successfully linked.
[I 2025-01-10 09:20:45.445 ServerApp] notebook_shim | extension was successfully loaded.
[I 2025-01-10 09:20:45.448 ServerApp] jupyter_lsp | extension was successfully loaded.
[I 2025-01-10 09:20:45.449 ServerApp] jupyter_server_mathjax | extension was successfully loaded.
[I 2025-01-10 09:20:45.450 ServerApp] jupyter_server_terminals | extension was successfully loaded.
[I 2025-01-10 09:20:45.453 LabApp] JupyterLab extension loaded from /opt/conda/lib/python3.11/site-packages/jupyterlab
[I 2025-01-10 09:20:45.453 LabApp] JupyterLab application directory is /opt/conda/share/jupyter/lab
[I 2025-01-10 09:20:45.454 LabApp] Extension Manager is 'pypi'.
[I 2025-01-10 09:20:45.475 ServerApp] jupyterlab | extension was successfully loaded.
[I 2025-01-10 09:20:45.482 ServerApp] jupyterlab_git | extension was successfully loaded.
[I 2025-01-10 09:20:45.486 ServerApp] nbclassic | extension was successfully loaded.
[I 2025-01-10 09:20:45.591 ServerApp] nbdime | extension was successfully loaded.
[I 2025-01-10 09:20:45.615 ServerApp] notebook | extension was successfully loaded.
[I 2025-01-10 09:20:45.615 ServerApp] Serving notebooks from local directory: /home/jovyan
[I 2025-01-10 09:20:45.615 ServerApp] Jupyter Server 2.14.0 is running at:
[I 2025-01-10 09:20:45.615 ServerApp] http://graph-test-graph-server-jupyter-857c67b68d-smj4w:8888/jupyter/tree
[I 2025-01-10 09:20:45.615 ServerApp] http://127.0.0.1:8888/jupyter/tree
[I 2025-01-10 09:20:45.615 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[I 2025-01-10 09:20:49.018 ServerApp] Skipped non-installed server(s): bash-language-server, dockerfile-language-server-nodejs, javascript-typescript-langserver, jedi-language-server, julia-language-server, pyright, python-language-server, python-lsp-server, r-languageserver, sql-language-server, texlab, typescript-language-server, unified-language-server, vscode-css-languageserver-bin, vscode-html-languageserver-bin, vscode-json-languageserver-bin, yaml-language-server
Then there is still a small test to see whether the containers can be reached via the network. Either you change the type of services created from ClusterIP to NodePort or LoadBalancer and use the external IP addresses generated as a result, or we tunnel the ports of the two containers to the computer from which the installation was carried out for a simple test. The latter works as follows:
$ kubectl port-forward graph-test-graph-server-graph-57cc896d66-vq6d8 -n graph-server 7007:7007 & Forwarding from 127.0.0.1:7007 -> 7007 Forwarding from [::1]:7007 -> 7007 $ curl http://127.0.0.1:7007/dash/ -v * Trying 127.0.0.1... * TCP_NODELAY set * Connected to 127.0.0.1 (127.0.0.1) port 7007 (#0) Handling connection for 7007 > GET /dash/ HTTP/1.1 > Host: 127.0.0.1:7007 > User-Agent: curl/7.61.1 > Accept: */* > < HTTP/1.1 200 < X-Content-Type-Options: nosniff < X-Frame-Options: SAMEORIGIN < X-XSS-Protection: 1 < Content-Type: text/html < Content-Length: 1266 < Date: Fri, 10 Jan 2025 09:56:49 GMT < <!doctype html><html lang="en-us"><head><title>Graph Dashboard</title><meta charset="UTF-8"/><meta name="viewport" content="viewport-fit=cover,width=device-width,initial-scale=1"/><meta name="description" content="Graph Dashboard"/><link rel="icon" href="styles/images/JET-Favicon-Red-32x32.png" type="image/x-icon"/><link rel="stylesheet" href="https://static.oracle.com/cdn/apex/21.2.4/libraries/font-apex/2.2.1/css/font-apex.min.css?v=21.2.5"><link rel="stylesheet" type="text/css" href="styles/redwood/16.1.6/web/redwood.min.css"> <link rel="stylesheet" type="text/css" href="styles/theme-redwood/16.1.6/web/theme.css"> ......
This means that the internal port 7007 of the container has been forwarded to port 7007 of the local computer. If you have a graphical user interface available here, you can now also access the Graph Server via a browser. The situation is very similar with the Jupyter container, which you can simultaneously switch to a port other than 7007. How about 8888, the same port as the one within the Jupyter container?
$ kubectl port-forward graph-test-graph-server-jupyter-857c67b68d-smj4w -n graph-server 8888:8888 Forwarding from 127.0.0.1:8888 -> 8888 Forwarding from [::1]:8888 -> 8888 $ curl http://127.0.0.1:8888/jupyter -v * Trying 127.0.0.1... * TCP_NODELAY set * Connected to 127.0.0.1 (127.0.0.1) port 8888 (#0) > GET /jupyter HTTP/1.1 > Host: 127.0.0.1:8888 > User-Agent: curl/7.61.1 > Accept: */* > Handling connection for 8888 < HTTP/1.1 302 Found < Server: TornadoServer/6.4 < Content-Type: text/html; charset=UTF-8 < Date: Fri, 10 Jan 2025 10:04:55 GMT < Location: /jupyter/tree? < Content-Length: 0 < * Connection #0 to host 127.0.0.1 left intact
This should suffice as an initial test and the environment should actually work! I am happy to answer any questions you may have about Ingresses and SSL encryption, but I think they are beyond the scope of this blog at the moment. I would much rather show and explain the interfaces and the notebooks provided below.
Feature description and solution clickthrough
The user interface of the Oracle Graph Server should now be accessible in different ways via the browser. I have selected a configuration services.external.type virtualservice and as services.external.vhostName the entry graph.test.141.147.33.9.nip.io, i.e. the name of an externally accessible gateway in my Kubernetes cluster. The gateway uses SSL encryption, the Graph Server and Jupyter do not. In this configuration, the Graph Server UI and its REST services can be reached at the address https://graph.test.141.147.33.9.nip.io/dash, the Jupyter interface connects seamlessly via the URI /jupyter, or completely https://graph.test.141.147.33.9.nip.io/jupyter. Both UIs show up with an initial login:
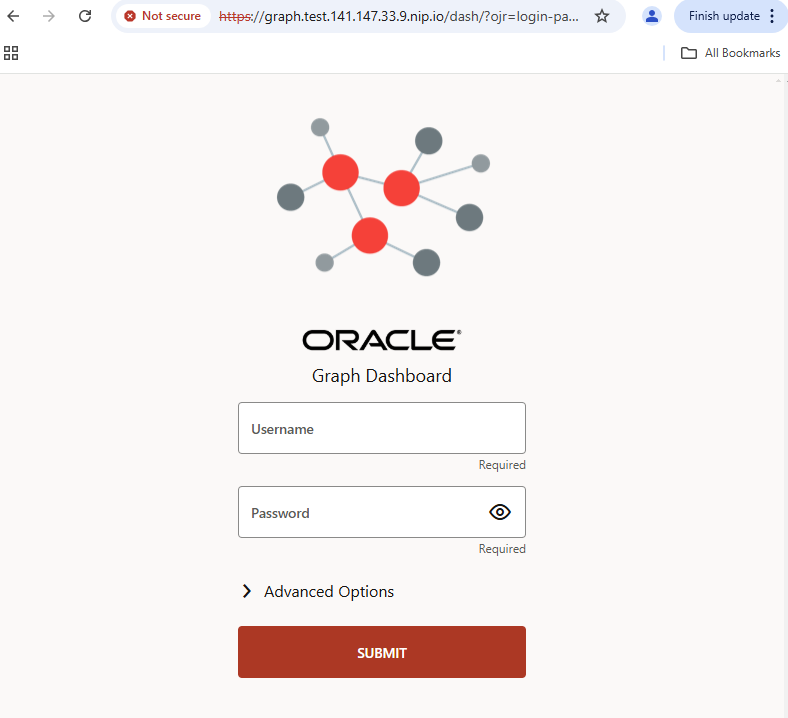
The Graph Server and the connected Oracle database have probably not yet loaded or configured any graphs. Perhaps there is also no database user in your environment with the GRAPH_DEVELOPER role to log on to the Oracle database via the Graph Server. Therefore, we first look at the Jupyter environment, because one of the loaded notebooks offers installable demo data and graph structures, the “banking graph” with bank transactions in it. Please log in to Jupyter with the password you assigned during installation. It is probably jupyter . Then start a terminal window and call sqlplus to connect to your database as an authorized user (e.g. system) and create a bankgraph user.
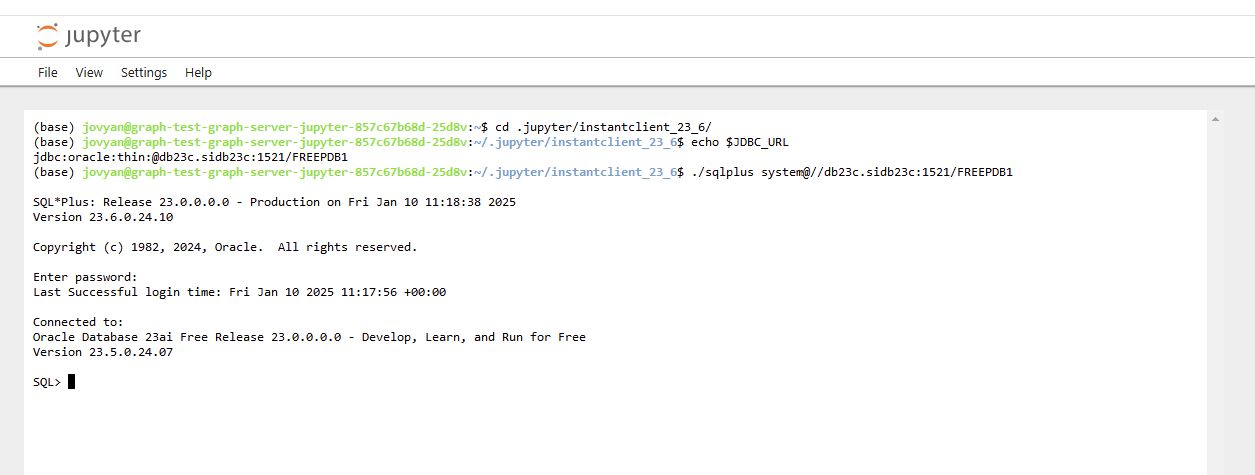
The directory of the instant client installation is ~/.jupyter/instantclient_23_6 , the environment variable JDBC_URL contains the name of the database still to be set up. You can access your database using ./sqlplus (the PATH variable is not set here!). Create the bankgraph user that is still required with the following SQL commands:
CREATE USER bankgraph IDENTIFIED BY Welcome1 DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp QUOTA UNLIMITED ON users; GRANT alter session , create procedure , create sequence , create session , create table , create trigger , create type , create view , graph_developer -- This role is required for using Graph Server TO bankgraph;
There is no obligation to use sqlplus. Having a command line in the browser is a feature of this environment that I think is worth showing. And even with sqlplus in it.
So let’s turn our attention to the notebooks. Some notebooks have already been downloaded in the background using the git command. The first notebook to be viewed is located in the directory work/pgx-samples/banking-graph-init.ipynb :
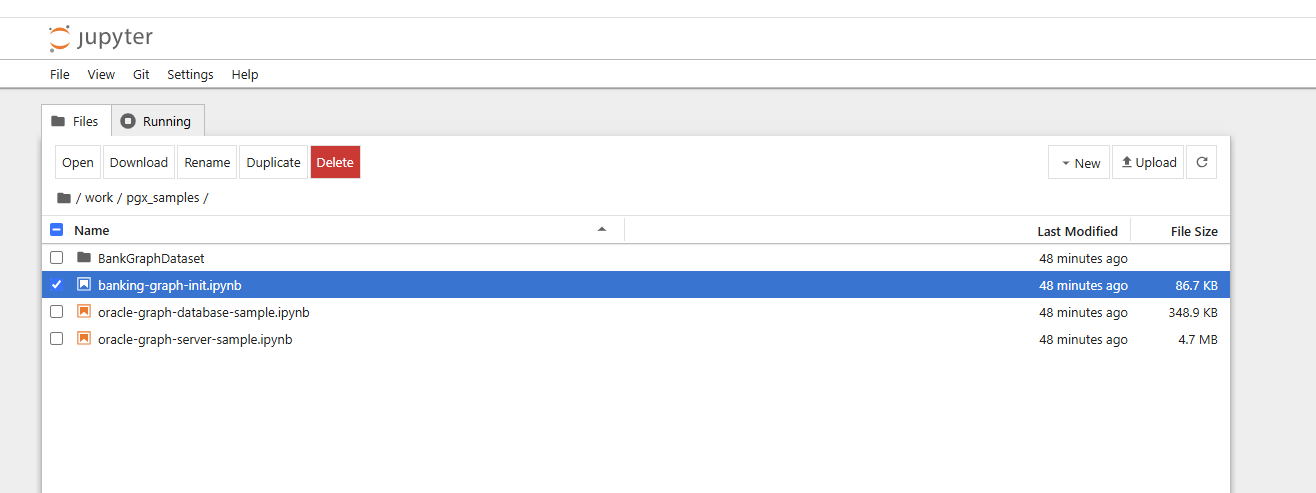
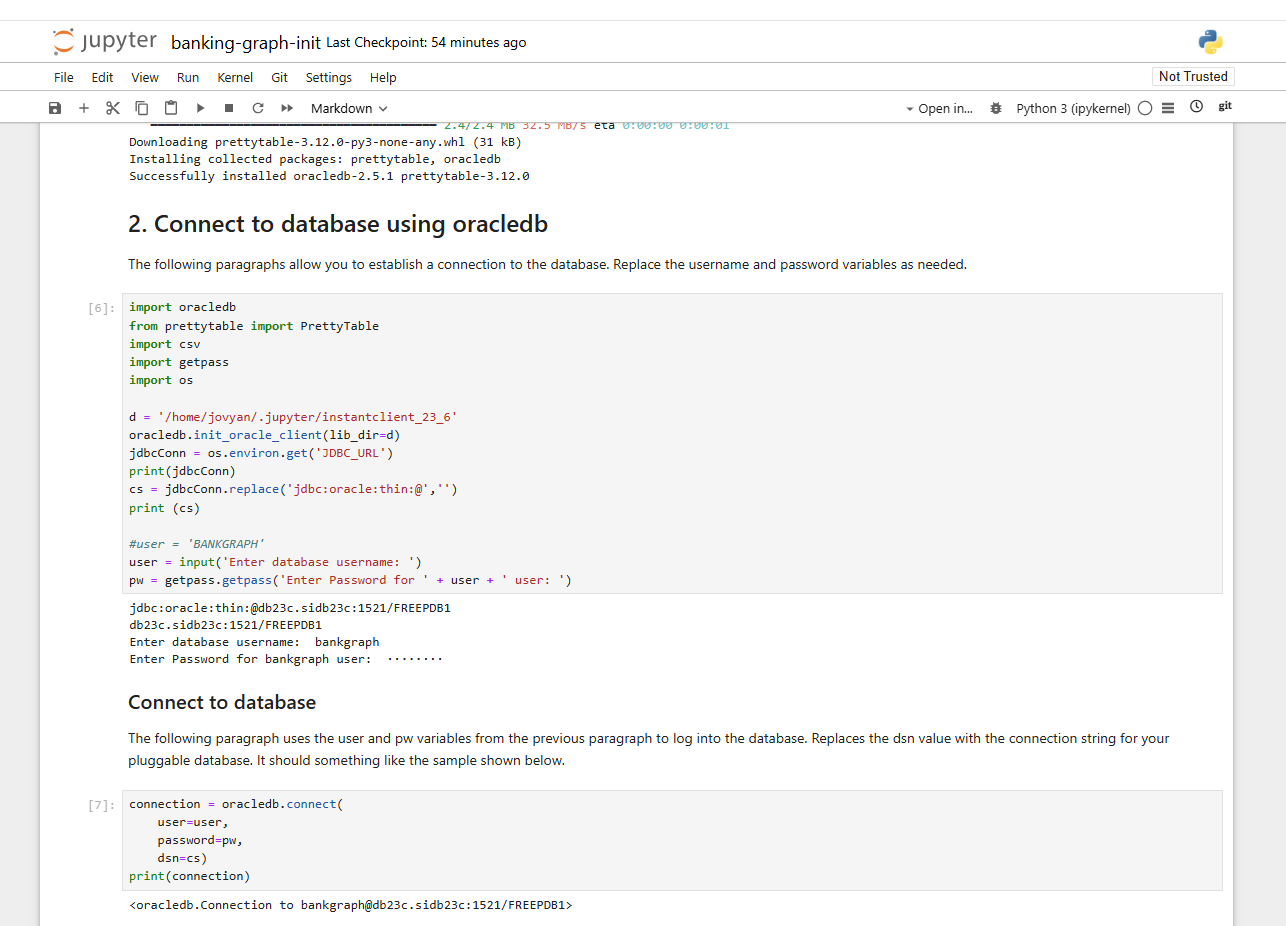
The notebook generates database tables and creates a property graph, which you can also read and visualize with the Graph Server UI. Other notebooks visualize and query either the Graph Server or the Oracle Database with SQL/PGQ. You can see from the notebook shown that the installed Oracle instant client is used from Python and the database connect is read from the JDBC_URL environment variable. You can now run step by step in the notebook and experiment with the graph for financial transactions.
The second Jupyter Notebook oracle-graph-server-sample.ipynb connects to the Graph Server via the environment variable GRAPH_URL. The notebook also installs the Oracle Graph Client for Python and the necessary JDK 17.
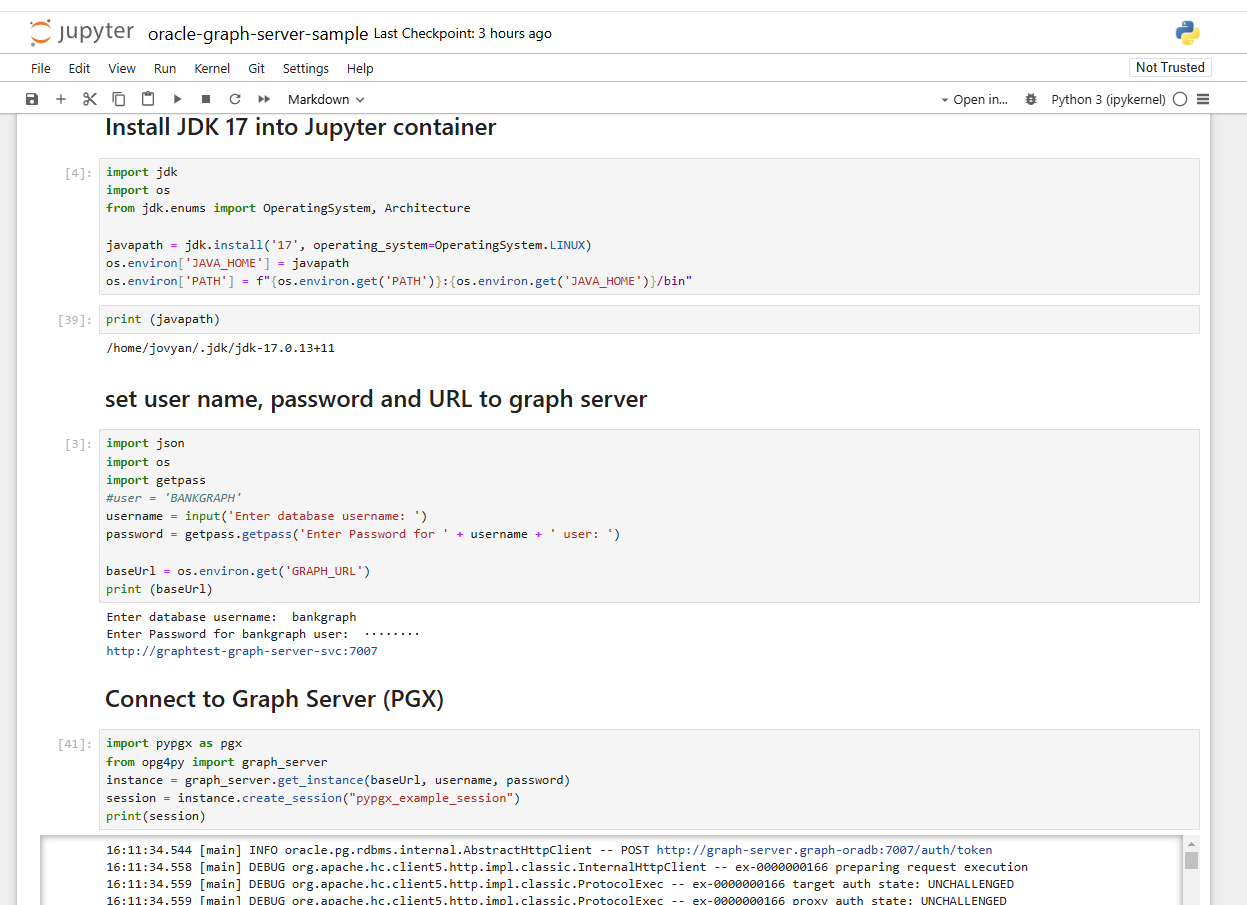
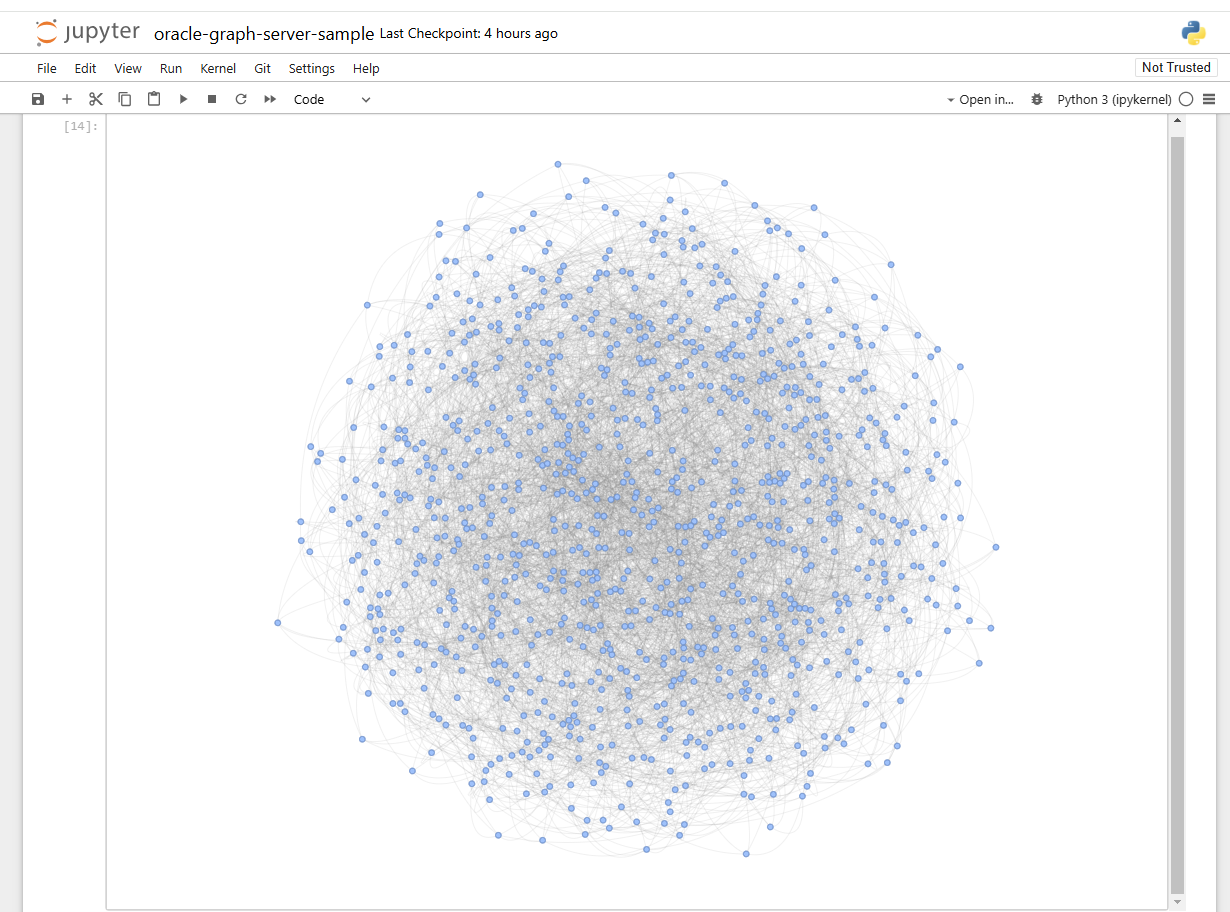
At a later point in the same notebook, the previously loaded graph BANK_GRAPH is transferred from the database to the graph server. The visualization library vis.js loads the approximately 5000 nodes of the graph and displays them quite nicely after a waiting time of several minutes. You are welcome to experiment with filters and optimized return quantities in order to shorten the waiting time in the future. The much faster Oracle Visualization Library for JavaScript does not yet have support for Python or a Jupyter plugin, but according to product management this is on the roadmap.
Now return to the Graph Server UI and log in as the bankgraph user who owns the loaded data and graphs from the Jupyter notebooks.

Switch from the standard view to the “Database (SQL Property Graphs)” tab.
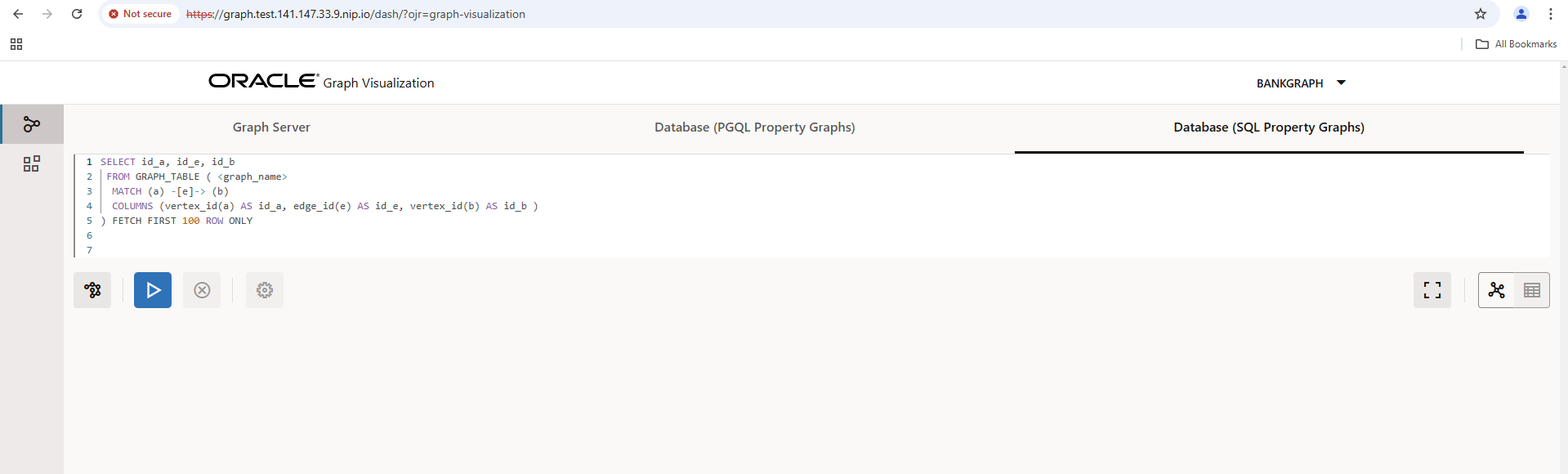
Then click on the network icon on the left to select graphs in your database and check whether the BANK_GRAPH is in the list.
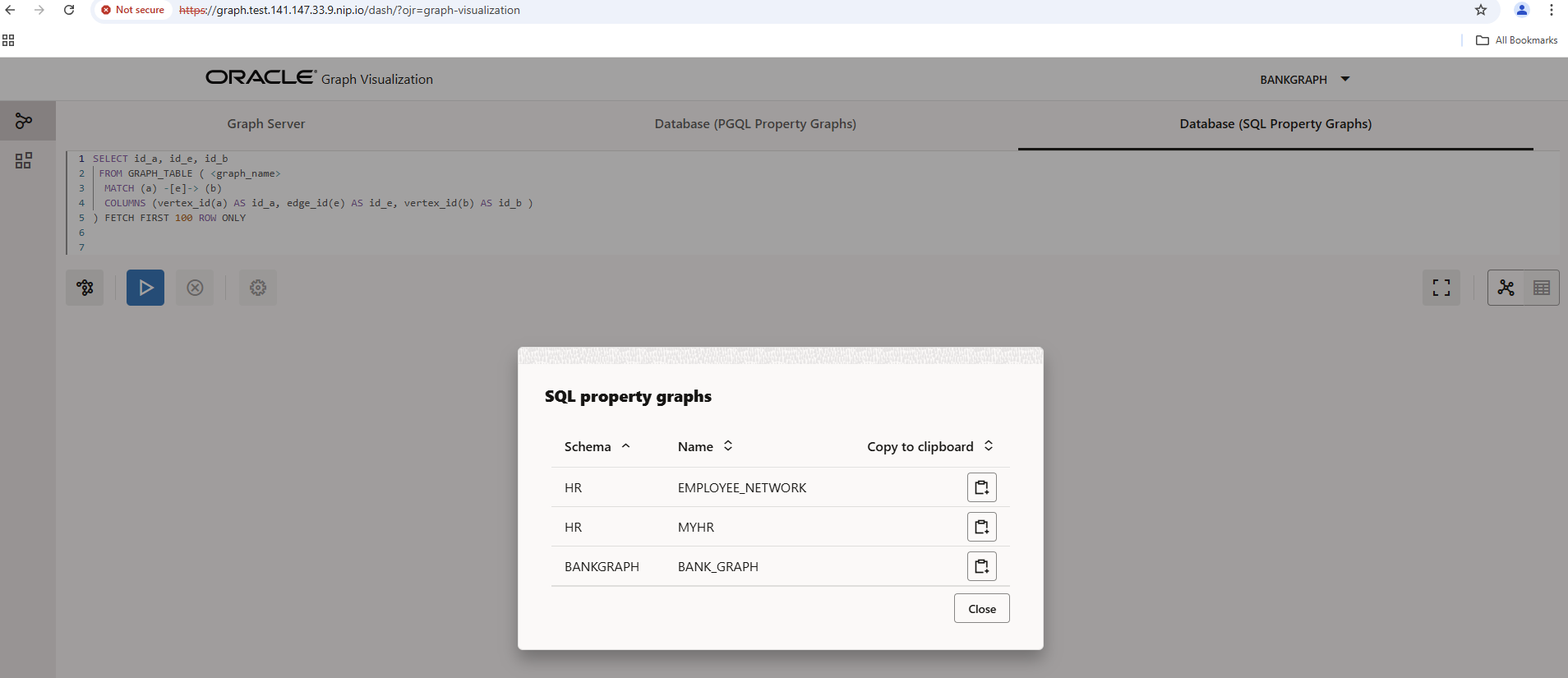
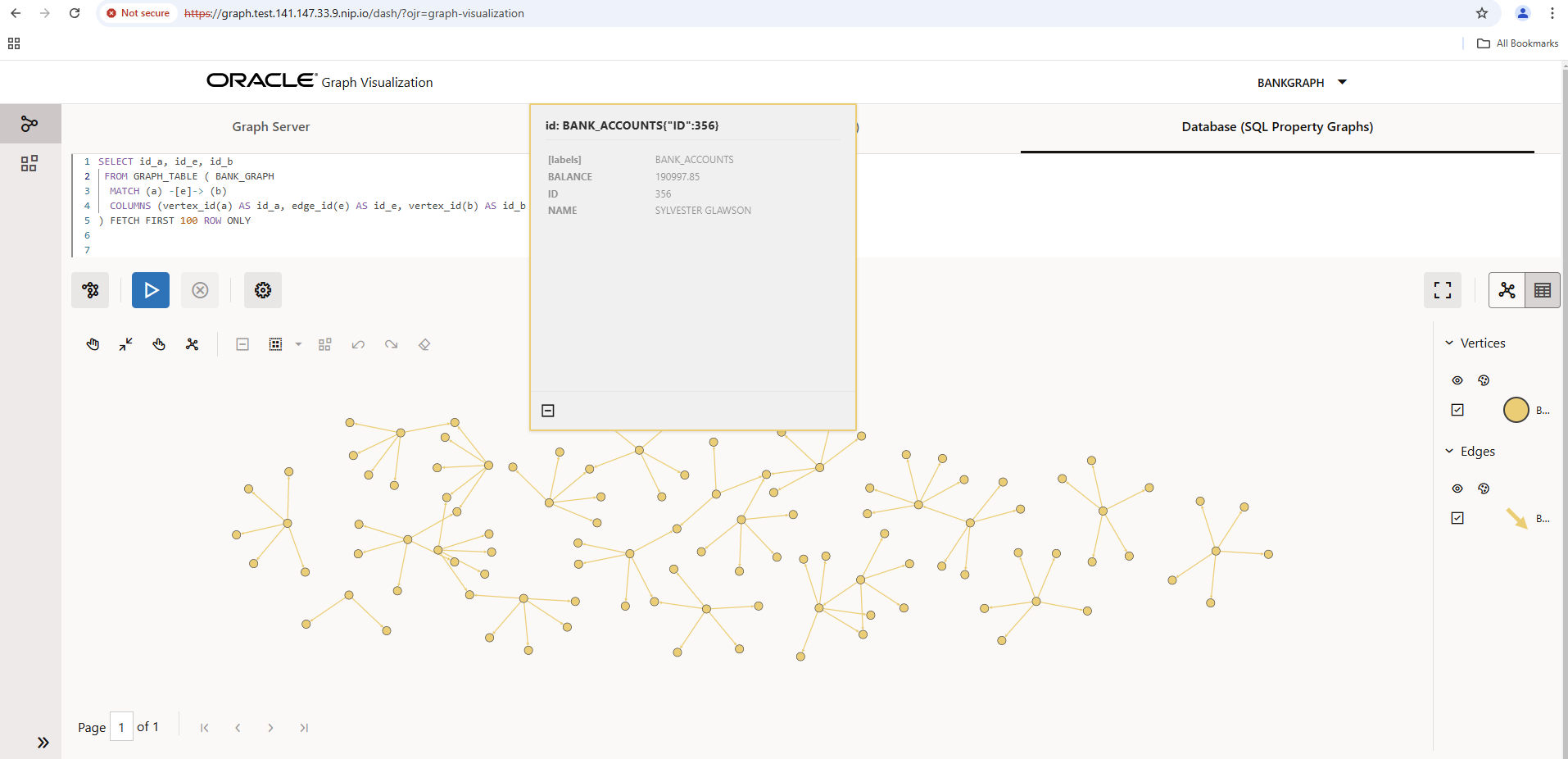
Enter the BANK_GRAPH at the top of the SQL/PGQ query and execute the query. You can customize the resulting diagram with a maximum of 100 nodes, view the data behind the nodes, etc.
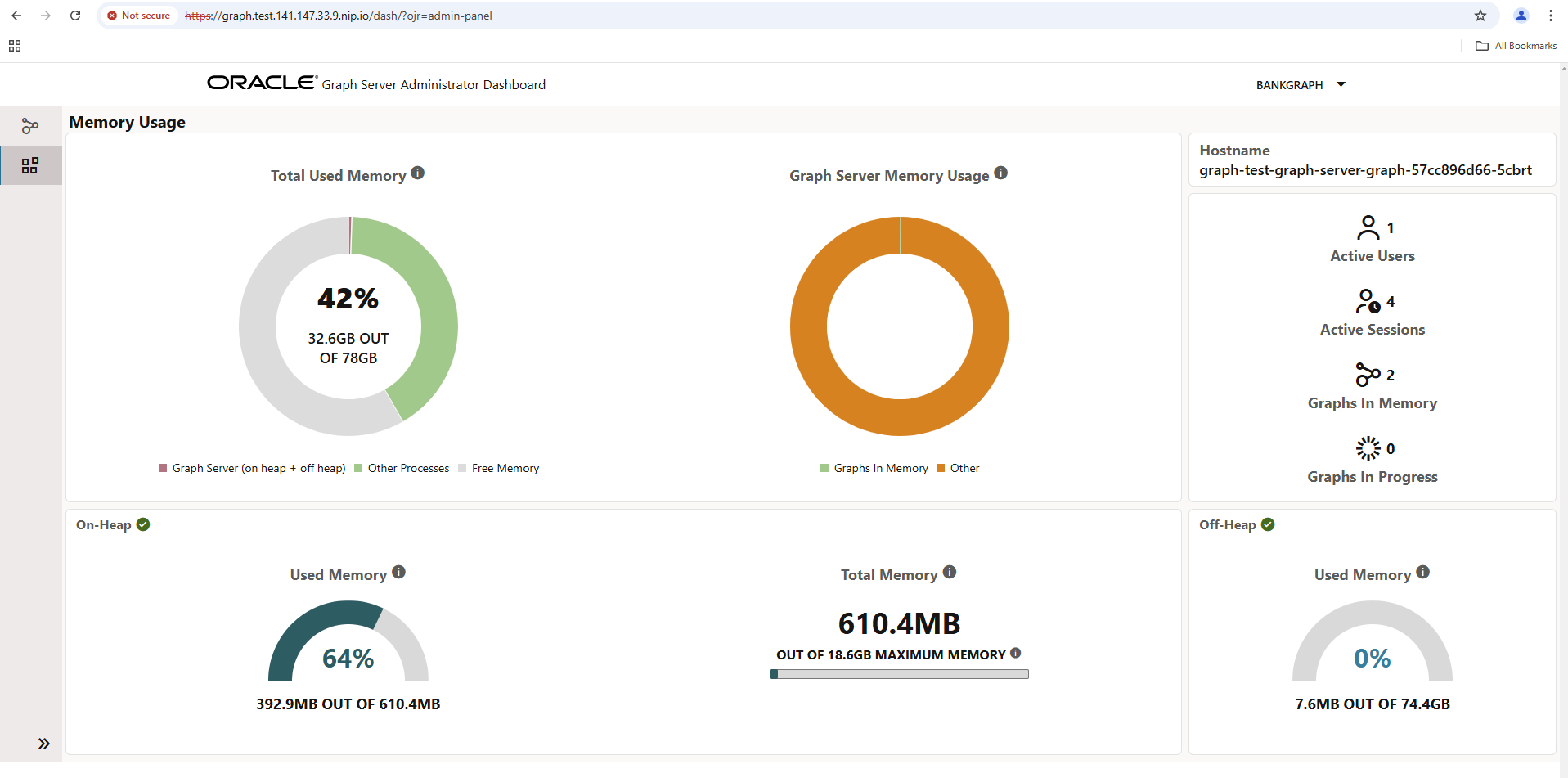
The server statistics of the Graph Server are probably also interesting. Click on the icon for the “Administrator Dashboard” on the far left-hand side of the page:
That concludes this article on using the Graph Server with Kubernetes for the time being. There are certainly still many things to discover, queries to formulate and try out, perhaps even with your own data. But this is precisely the purpose for which such small and fine analysis environments exist. They are easy to set up, ideally via a self-service user interface, and can be reused at any time.
There are many further blogs on property graphs and the graph server itself, some of which I have used for reference in this blog. Perhaps the same information will help you on your way, so I have listed all the links used below. Additionally, the links to the source code for this and other Helm Charts so you can embed them into your environment and feel free to customize.
And now as always: have fun testing !
Used links in this blog:
Instrcutions on Graph Server on docker part 1
Instructions on graph server on docker part 2
Diverse prepared Jupyter containers (“scipy”) on quay.io
Demo notebooks and data about graph server from Oracle product management (“pgx-samples”) on github
Browser based installation tool for helm charts named “kubeapps”
Source code of the used helm chart and other charts of Oracle components on github
Used helm chart repository URL on github.io
Related links to Oracle Graph:
The Oracle Graph learning path
Up-to-date issue: Retrieval Augmented Generation (RAG) with graph queries, not only fulltext or relational
Running graph algorithms in Jupyter: usage of Graph Server
Using Oracle Graph Python client with Autonomous Database