With the launch of Oracle Dedicated Region Cloud@Customer customers get a fully managed and fully featured cloud region delivered on-premises. This region helps customers meet their most demanding latency and data residency requirements on industry-leading cloud infrastructure. As Lydia Leong of Gartner said, no one has previously delivered what she thinks customers really want:
- Location of the customer’s choice
- Single-tenant: No other customer shares the hardware or service and data guaranteed to stay within the environment.
- Isolated control plane and private self-service interfaces, such as portal and API endpoints, no tethering or dependence on the public cloud control plane, and no internet exposure of the self-service interfaces
- Delivered as a service with the same pricing model as the public cloud services. It’s not more expensive than public cloud as long as minimum commitment is met.
- All the provider’s services, including infrastructure and platform as services, are identical to the way that they’re exposed in the provider’s public regions.
Dedicated Region Cloud@Customer offers all cloud services current and future, the exact same SLAs for availability, performance and management, the same APIs, and the same resilience and operational capabilities that are available in our public cloud regions. Customers pay for what they use, and we manage capacity. As I engage with customers interested in Dedicated Region Cloud@Customer, they usually ask how this is possible? How can the broad feature set and services of our public cloud be delivered on-premises?
Today, I walk you through the first principles and unique approach to building public cloud regions that led to the launch of Dedicated Region Cloud@Customer.
Delivering what people want
When we architected Oracle Cloud Infrastructure (OCI), the tens of thousands of enterprise customers that Oracle serves across the globe made it clear that they wanted public cloud services for their most demanding enterprise workloads in their country or geo-area. Data residence requirements, country-specific compliance requirements, and network latency were some of the key driving forces. To thrill our customers, our strategy has been to launch right-sized regions closer to where our customers want them and scale them dynamically while preserving public cloud characteristics, such as elasticity, high reliability, and operational excellence. To serve the needs of our customers, we had to launch regions much faster than other cloud providers.
Today, we successfully operate and scale more than 28 regions across the globe, all in less than four years. We took radically different architectural approaches across a host of dimensions to achieve this goal, and with Dedicated Region Cloud@Customer, we extend the architecture refined for the last four years.
Let’s cover the architectural approaches to our region design, as it relates to availability, resiliency, and elasticity.
High availability
Typically, high availability in the public cloud is achieved through server and data center architecture that provides resiliency against equipment failure and through a failure isolation model that software services and apps use to implement failover and replication logic.
The data center has upstream and downstream components. Upstream components include utility substations, generators, switchgears, cooling units and UPSs that feed power distribution units (PDUs). Downstream components include the individual PDUs, breakers associated with them, the power whips coming out of the breakers and PDUs, and the rPDUs that the power whips feed. This logical view roughly holds true in most modern data center architectures.
The upstream components, including power substations, backup generators, UPS units, and cooling and fan units, have resilience and redundancy built into the architecture. Other major public cloud providers have a similar resiliency model.
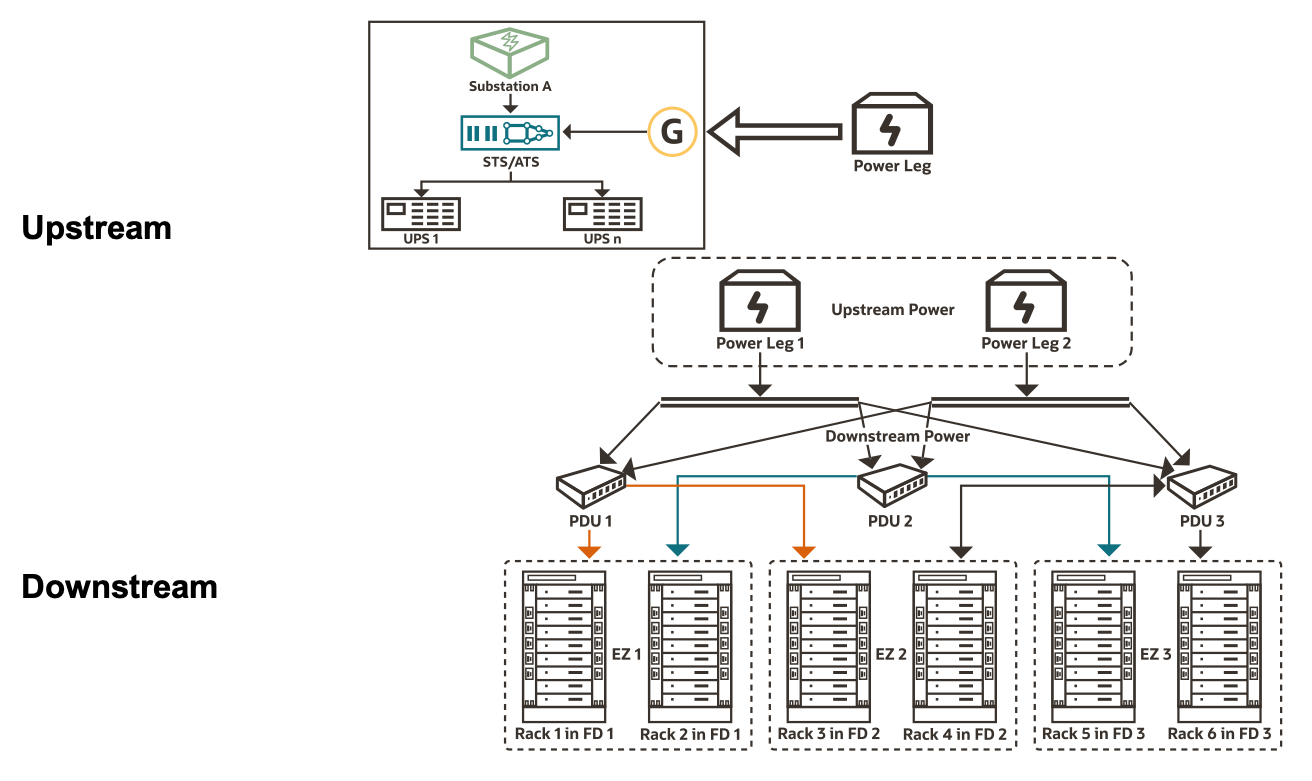
However, the downstream architecture is fundamentally different, where we took a radically different approach compared to other cloud providers. Many cloud providers generally assume that every customer workload is spread across large number of server racks, justifying not having redundancy for downstream components. The blast radius of downstream component failure is relatively small when the regions are large. However, the effect of the downstream component failure becomes more noticeable for smaller regions. With our goal to right-size regions and scale them linearly, we had to think differently about downstream failures.
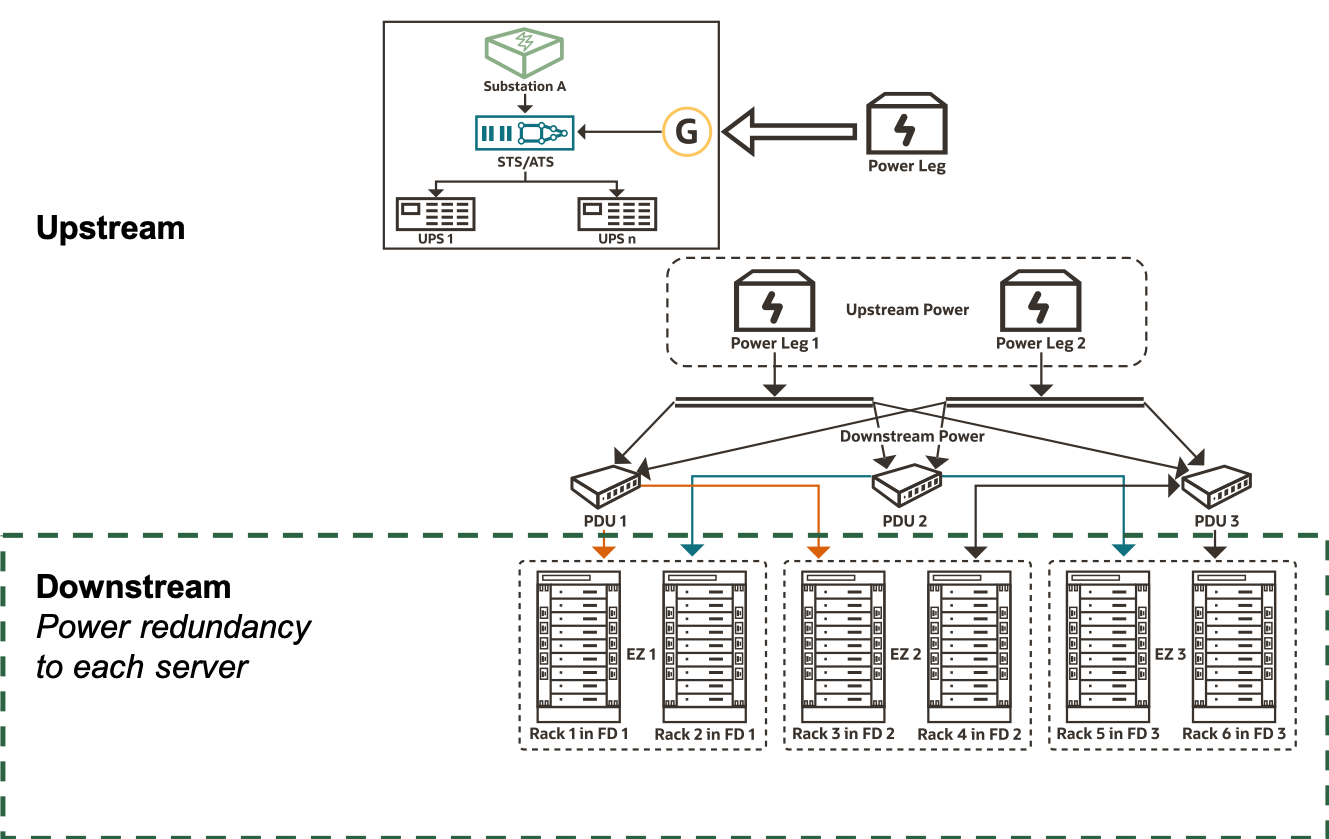
When we architected OCI, we made a conscious choice of having redundancy for downstream components, down to individual servers. Single point of failures associated with PDUs, power whips, and rack PDUs are eliminated when every server gets redundant power supply lines from different PDUs. Failure data over the years tell us that non-redundant downstream components can result in roughly 1% annual server failure rate. With redundancy for downstream components, we all but eliminate this failure mode.
This architectural and business choice fundamentally makes OCI data center architecture suitable for smaller regions including Dedicated Region Cloud@Customer. For sake of consistency and better customer experience, we use the same architecture in all regions independent of the size.
Failure isolation model
With Dedicated Region Cloud@Customer and other smaller regions, it’s important for customers to achieve high availability and resilience within an availability domain or single data center facility and across multiple availability domains. Fault domains were designed for this purpose.
A fault domain is a grouping of hardware and infrastructure that provides anti-affinity and failure isolation within a single availability domain. Applications can use fault domains to achieve resilience by using resources, such as Compute instances, in multiple fault domains with failover and replication across them.
We had the following architectural goals with fault domain architecture to substantially lower the probability of correlated failures across fault domains:
- Failure of any single downstream power component can’t impact any fault domain.
- Failure of multiple components belonging to a single group of downstream power components can’t affect more than one fault domain.
- The blast radius of server or rack level changes, including data center operations, must be isolated to no more than one fault domain at a time.
The first goal is fairly straight forward because we have redundancy for all downstream power components.
To achieve the second goal, we architected a power component level isolation domain called an electrical zone. No two electrical zones share all the power components even if they share some of the power components. For example, two electrical zones can share one PDU but can never share two PDUs. As a result, an outage that impacts two PDUs can take down one electrical zone. Next, we ensured that every electrical zone is mapped to exactly one customer-facing fault domain. So, failure of two downstream components can only take down one fault domain, reducing the probability of correlated failures across fault domains.
To achieve the third goal, we implemented a rigorous change management structure that ensures software changes, such as intrusive switch firmware updates, and data center operations like rPDU operational changes don’t impact more than one fault domain at a time.
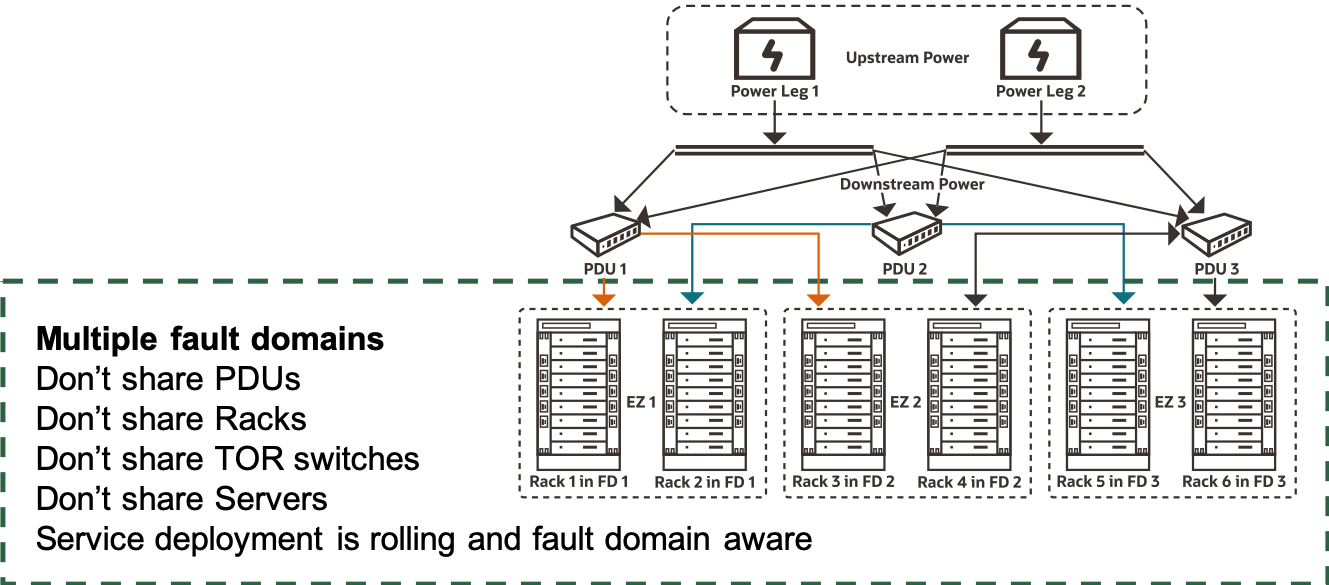
OCI’s server and data center architecture creates inherent resilience for workloads deployed to relatively smaller regions. The fault domain architecture creates a powerful fault isolation model that a customer’s app can use for replication and failover even in smaller regions. Dedicated Region Cloud@Customer inherits the same architecture and the same advantages.
Scaling region count
Launching ultra-high scale region is an infrequent activity, but launching many smaller regions happens frequently. This timing creates both an opportunity and the necessity to take a different approach from other public cloud providers and excel at launching operating regions efficiently. Automation was the key, and we aimed to standardize region level services, service configurations, static resolution of dependencies across them to automate the region bootstrap process.
We architected the bootstrap automation like the evolution of Linux OS installation process. Back in the day, DVD- or CD-based desktop Linux installation presented users with a series of menus that showed OS package choices. Dependency checking and resolution happened during the installation process after user selection. These days, image-based OS provisioning is the standard, where you can turn up virtual machines and containers on a whim and tear them down quickly. Image-based provisioning of OS standardizes the package selection that allows for static resolution of dependencies across the preselected OS packages, enabling faster touchless OS installation.
Similarly, all OCI regions including Dedicated Region Cloud@Customer launch with all OCI services, with the exact same features and capabilities. This availability helps standardize the services and microservices that are part of our region bootstrap process. The services and microservices that go into each region are preselected, and most of the intraservice dependencies are statically resolved well before the region bootstrap time, increasing parallelism and reducing error rates during the bootstrap process. Therefore, the time to bring up a region reduced down significantly.
Elasticity
Elasticity refers to ability to scale resource usage up and down dynamically and pay for only the resources you use. For example, Oracle Cloud Object Storage service offers elastic performance for the PUT and GET operations, where customers get the performance that they need on-demand, without having to reserve how much bandwidth they need ahead of time.
Elasticity in public cloud is an illusion created using the following unique attributes of the public cloud:
- Uncorrelated workloads: In public cloud, different workloads from different customers are often unrelated. Their cycles of resource consumptions don’t correlate to each other. for example, retail workloads might peak during holiday season and financial workloads might peak during quarterly reporting seasons. As a result, the aggregate usage across all customers tends to be more stable when compared to individual customer’s usage.
- Fungible resource pools: Fungibility means that customers can migrate workloads seamlessly across the resource pool, based on utilization. In response to customer’s resource usage changes, fungibility of resource pools allows us to respond quickly and balance the load across the fleet.
The combination of uncorrelated workloads and fungible resource pools allows cloud providers to buy capacity for the aggregate usage across all customers while serving peak usage of each customer seamlessly.
Extending the previous example, Object Storage has a frontend web-server fleet. This fungible fleet of frontend servers can serve an object PUT or GET from any customer. If a frontend server is too hot, we have software architecture that routes future requests to other servers to balance the load. An individual customer’s load tends to vary over time with low correlation across them. As a result, the frontend fleet scales as a function of aggregate load on the system while serving the individual customer’s load with large variances.
Elasticity has breaking points. Large correlated workloads perturb the attributes that elasticity relies on. So, some degree of capacity planning and resource allocation is needed. This adaptability applies to all public cloud providers and all regions, independent of size.
The difference with smaller regions is the thresholds for breaking points. In OCI, we took a different approach with architecture and capacity management strategy to provide elasticity in smaller regions, including the following features:
- Fungibility through common server types: Cost optimization drives the need for specialized server types. However, during early phases of a data center growth, we took the opposite approach, where smaller number of server types are used behind the scenes to increase fungibility. The increased fungibility allows for better elasticity even when the region is scaled. This approach isn’t cost effective for all scenarios. So, we increased specialization of underlying hardware dynamically as the region grows. We want to keep customer experience similar, independent of the region size, and as a result, we only pursue dynamic server specialization approach where the details can be abstracted away from customers.
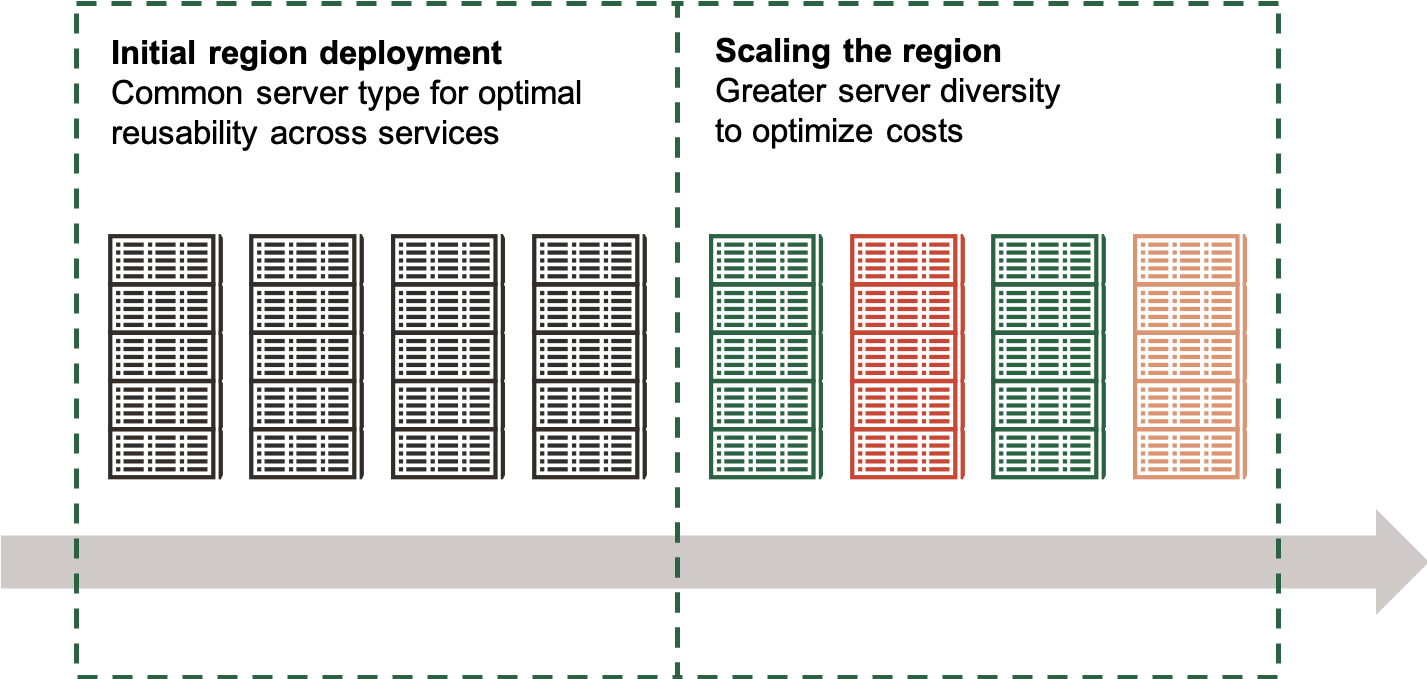
- Dynamic capacity management: Even with small regions, sum of capacity demands across many small regions is large. As a result, if we can manage capacity not at a region level but really at the granularity of ‘group of regions’, we derive the same benefits of having larger region. At OCI, we have a geo-area centric supply chain process with ‘just in time’ capacity acquisition at region level. This way, when a customer has a sudden demand, capacity can be made available in a matter of days instead of weeks.
- Workload analysis: With Dedicated Region Cloud@Customer, we need to manage space and power in the facility in close coordination with customers. As a result, planning and automation that helps us understand the scale and patterns of the workloads becomes critical. This planning is no different from how we manage our largest customers in the public cloud today. We work closely with customers to scale capacity to ensure elasticity, while balancing space and power usage in the on-premise environment.
Elasticity always has breaking points, and the thresholds are different with small regions. Increased server capacity fungibility with common server types during early phases of a region’s life and dynamic capacity management strategy allows us to offer elastic products effectively even with small regions.
Conclusion
The choices we made to develop Oracle Cloud Infrastructure are markedly different. The most demanding workloads and enterprise customers have pushed us to think differently about designing our cloud platform. Dedicated Region Cloud@Customer is our continued commitment to enterprise customers who want all the advantages of the public cloud but can’t get there for various reasons. We bring the full experience of a public cloud region to them on-premises.
We have more of these engineering deep dives as part of this first principles series, hosted by myself and other experienced engineers at Oracle.
Click to view more First Principles posts.
