The Oracle Cloud Infrastructure Monitoring service enables you to actively and passively monitor your cloud resources by using custom metrics and alarm features that are built into the service.
Currently, the Monitoring service doesn’t natively support collection of GPU-specific data from instances running those advanced chipsets. However, it’s possible to easily publish custom metrics to the Monitoring service.
This post walks through the high-level steps for publishing GPU temperature, GPU utilization, and GPU memory utilization metrics from GPU instances to the Monitoring service. Detailed step-by-step instructions are located in GitHub.
This solution uses the NVIDIA System Management Interface (NVIDIA-smi) command line utility to gather metrics from the GPUs, and then uses the Oracle Cloud Infrastructure command line interface (CLI) to publish these metrics to the Monitoring service.
NVIDIA-smi ships with NVIDIA GPU display drivers. GPU shapes with Oracle Linux 7 images come with the GPU drivers installed. GPU shapes with Ubuntu 16.04, Ubuntu 18.04, Windows Server 2012 R2, and Windows Server 2016 images are supported, but you must install the appropriate GPU drivers from NVIDIA. The solution works on Oracle Linux 7, Ubuntu 16.04, Ubuntu 18.04, Windows Server 2012 R2, and Windows Server 2016 images.
For Linux images, the solution is a shell script that is run by a cron job automatically. For Windows images, the solution is a PowerShell script that is run by a scheduled task automatically.
Here are the high-level steps:
- Query metrics from the GPU instance by using NVIDIA-smi.
- Convert the metrics gathered from NVIDIA-smi to valid JSON.
- Publish the JSON to the Monitoring service by using the CLI.
After the setup is completed, the metrics become visible in the Monitoring service. The following image shows the GPU temperature for a specific time frame.
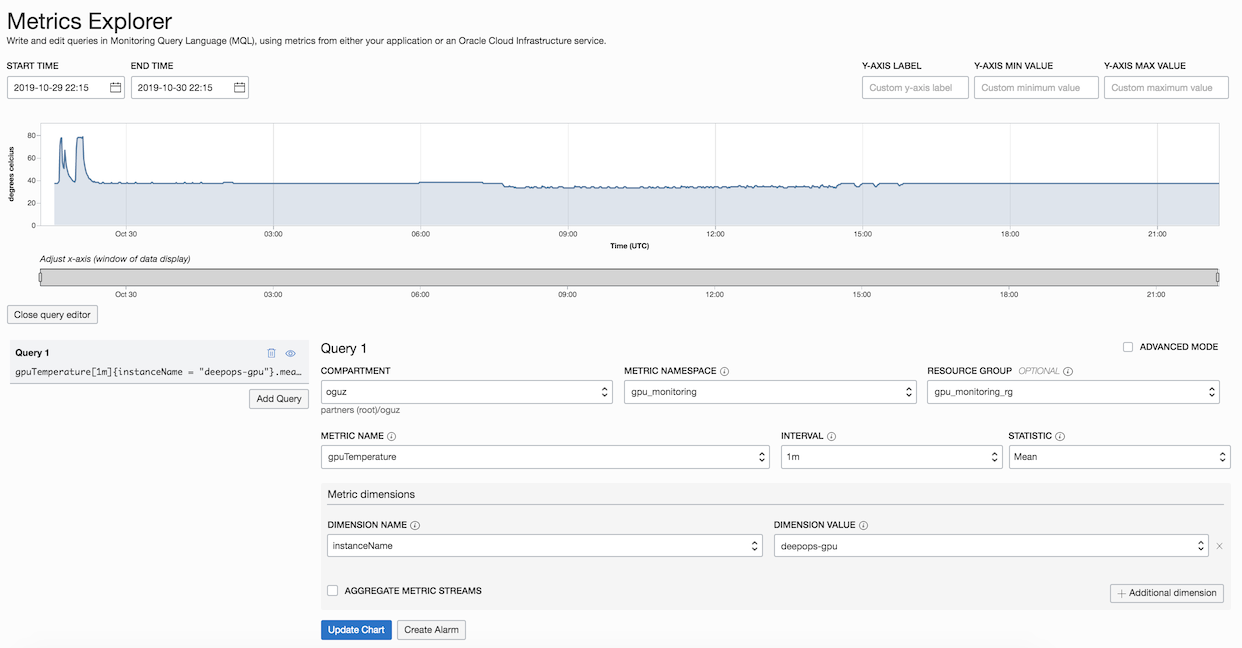
Because the metrics are fed into the Monitoring service, other services can act on them. For example, you can create an alarm that is triggered if the GPU temperature exceeds a certain threshold, and receive a notification email about it.
For detailed step-by-step instructions, see the GitHub repository.
