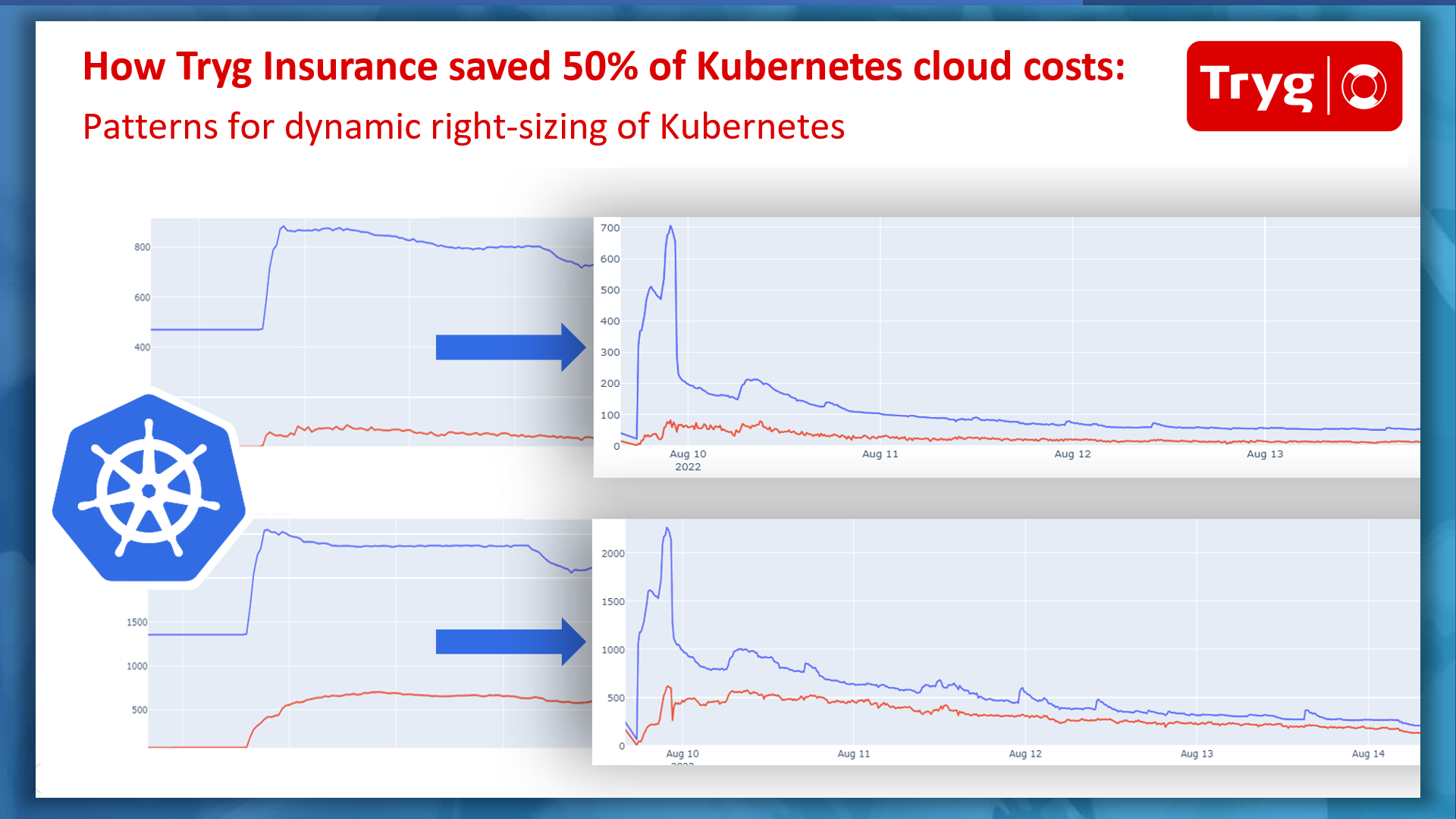
As Kubernetes use cases and adoption continue to expand across industries, we see Kubernetes infrastructure footprints growing significantly. This increase has led enterprises to look for ways to rein in cloud costs, particularly for large-scale environments. Your Kubernetes costs aren’t only the result of the infrastructure costs of the underlying cloud you’re using. Your application architecture and your Kubernetes configuration—from node configuration, autoscaling rules, pod resource requests, scheduler, and more—have a huge impact on your resource consumption and utilization. Consequently, these factors impact your bottom line and your Kubernetes cloud bill.
Recently, I had the pleasure of hosting OCI customer Tryg Insurance, the largest provider of general insurance services in the Nordic countries, at a Cloud Native Computing Foundation (CNCF) technical webinar. Varsha Naik from Tryg shared how they reduced their Kubernetes cloud costs by 50% by implementing dynamic right-sizing for their large-scale environments.
Read on to learn about the patterns Tryg uses to accurately measure their app usage, configure their Kubernetes environment, and automate resizing to optimize resource utilization. These changes resulted in significant Kubernetes costs savings without compromising on performance.
Tryg’s Kubernetes scale
Listed on Nasdaq OMX Copenhagen under symbol TRYG, Denmark-based Tryg is a Scandinavian insurance company present in Denmark, Norway, Sweden, and Finland. TRYG is the largest non-life insurance company in the Nordics, serving more than 5.3 million customers with a broad variety of insurance offerings across the private, commercial, and corporate sectors. These offerings range from car insurance, home, health, worker liability, commercial property insurance, group life insurance, and more
Tryg’s Kubernetes-based application is responsible for processing all their insurance claims across all product lines, handling huge amounts of real-time structured and unstructured data from various sources. Their stack involves many different technologies, such as Strimzi Kafka, Postgres DB, Kafka Connect, and various monitoring and alerting technologies using Prometheus, Elastic Search, Grafana, Kibnana.
Tryg operates a large-scale Kubernetes environment with five clusters running on Oracle Container Engine for Kubernetes (OKE), each with 5,000 vCPUs, 12.7-TB memory, 307-TB storage, and the capacity to run 2,150 pods per cluster.
Challenges with right-sizing Kubernetes
Balancing performance, cost, and meeting service level agreements (SLAs) in a Kubernetes setting can be a difficult task for organizations. Cluster size, Compute shape, scaling, and resource requests are among the many factors impacting service experience and associated costs. However, accurately estimatinh the needs of your application or dynamically adjusting to achieve a cost-performance sweet spot is often challenging. The complexity of your architecture and app portfolio, lack of visibility, automation, the dynamic nature of the workloads, and dependencies on other running applications all compound the problem.
In Tryg’s case, the multiple components that make up their claim processing application had varying requirements, some demanding more CPU, others more memory for data processing, and some requiring increased I/O throughput. This complexity made it difficult to fine-tune the Kubernetes environment to meet the needs of each microservice. The cluster also had a fixed number of worker nodes, leading to the same cost regardless of peak or idle usage.
Solution: Optimizing Kubernetes resources and automating dynamic resizing for cost savings
Tryg has optimized the following key factors that impact the cloud resources consumed by Kubernetes:
Node resource optimization
Tryg began addressing the challenge of fine-tuning their Kubernetes environment using Oracle Cloud Infrastructure (OCI) flex shapes for their Kubernetes worker nodes’ shapes. Flex shapes allow granular CPU and memory allocation for your chosen compute. Standard VMs require you to scale both CPU and memory together in predefined intervals by “jumping” to a larger instance size. By contrast, flex shapes enable you to granularly increase or decrease CPU or RAM for your specific application needs, even for demanding workloads, to optimize performance, resource utilization, and avoiding over provisioning to reduce cost.
Tryg configured their OKE worker nodes with the just-right number of OCPUs (equals to two VCPUs) and memory. They also established separate node pools for each application component to better address their unique requirements. The size of the nodes was discovered to be a critical factor, and they found that allocating large nodes with high CPU and memory resources led to reaching the limit of persistent volumes on a node before the compute and memory resources are fully utilized. On the other hand, if they allocated too many smaller nodes, they risked running into IP address exhaustion if the worker node subnets weren’t appropriately sized.
Node shape optimization
To meet the diverse needs of their applications, Tryg used the following flex shapes hardware options from OCI:
- AMD64 worker nodes for some of their Java services and for running Strimzi (An Apache Kafka solution)
- ARM64 nodes for performance-critical components. These nodes were cheaper than the AMD64 shapes, while being highly performant and reliable.
- For low latency and optimal performance, Tryg runs their Postgres DB in the Kubernetes cluster. The DenseIO VMs provide local disk storage that helps reduce latency significantly.
Tryg then utilized the Kubernetes node affinity, node selectors, taints, and tolerations to allocate specific workloads to their preferred worker nodes.
Horizontal pod autoscaling: Dynamically adjusting pod replicas based on demand
To reduce costs during idle times in their Kubernetes cluster for their stateful application, Tryg implemented horizontal pod autoscaling (HPA). HPA adjusts the number of pod replicas based on demand, increasing or decreasing replicas as needed. You can use HPA by setting thresholds on CPU and memory utilization and creating or deleting replicas as usage exceeds or falls below the thresholds. You can also use custom metrics which is how Tryg implemented their HPA.
Tryg exposed certain application-specific metrics to their Prometheus server. Thresholds for the custom metric were set and sent to the HPA through the Kubernetes API by the Prometheus server.
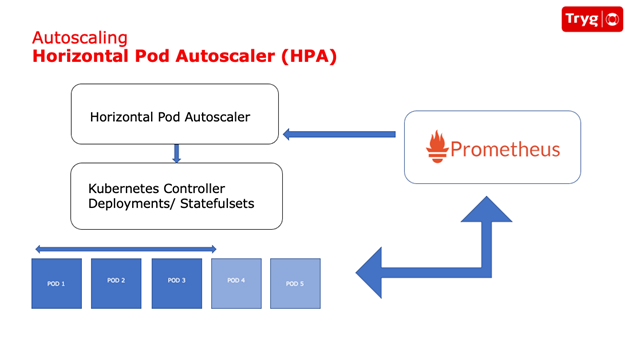
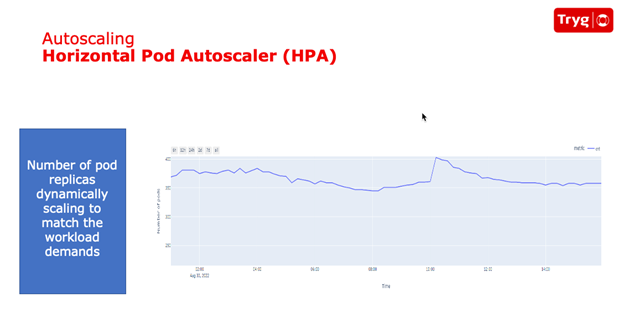
Although HPA dynamically allocated the right number of pods for peak and idle periods, Tryg’s Kubernetes clusters were still statically configured, resulting in the same number of worker nodes being allocated during peak and idle periods. Because the number of worker nodes impacts costs, HPA alone didn’t result in any cost savings.
Cluster autoscaler: Dynamically adjusting worker nodes based on demand.
To address the fixed number of worker nodes, Tryg implemented the Kubernetes cluster autoscaler. it automatically scales the number of worker nodes based on pod demand, scaling up and down as needed. The cluster autoscaler also offers features such as the ability to scale specific node pools and the speed at which nodes are scaled.
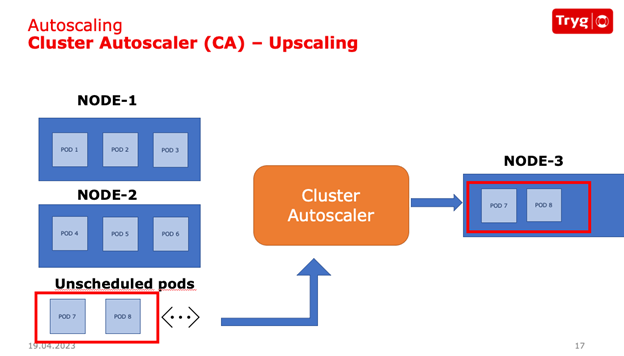
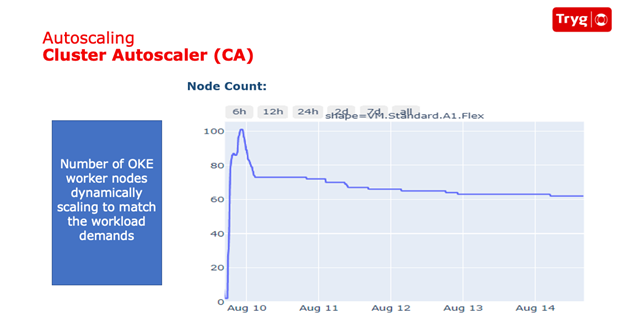
Using HPA in combination with the Kubernetes cluster autoscaler adjusted the number of worker nodes according to the peak and idle periods. With this combination, Tryg was able to save significant costs. However, more work can be done.
Vertical pod autoscaling: Eliminating idle default capacity
When specifying the CPU and memory resources request for pods, developers usually estimate based on expected utilization during peak periods and often add buffers to their calculations. This adjustment can lead to overprovisioning the requests for CPU and memory in the pod. With over 2,000 pods per cluster, these unused resources can accumulate quickly, resulting in higher costs.
The following graph illustrates the allocated CPU and memory resources compared to the actual usage at the pod level within a Kubernetes cluster at Tryg.
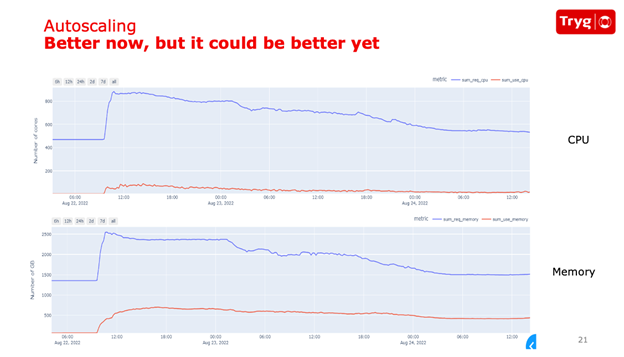
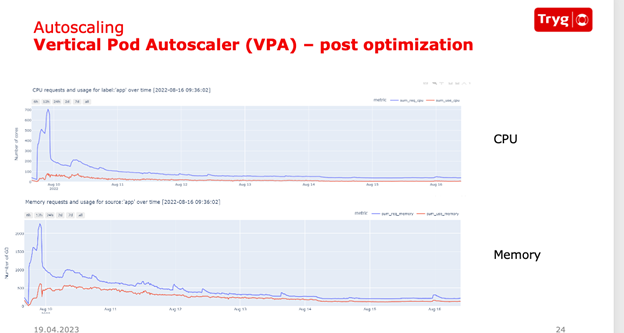
To get concrete numbers for the utilization at the pod level, Tryg introduced vertical pod autoscaling (VPA). VPA is a Kubernetes add-on that addresses the gap between requested resources per pod and actual utilization.
VPA is designed to improve resource utilization by automatically modifying the allocation of resources for pods based on the CPU and memory usage of an application. However, VPA can’t work with HPA if HPA is configured to use CPU and memory utilization as thresholds. Tryg was able to utilize VPA with HPA by adopting custom metrics for their HPA implementation, resulting in a comprehensive solution for managing the scaling of their pods. While VPA adjusts the allocation of resources for pods, HPA modifies the number of pod replicas.
Conclusion
Finding the right balance between performance and cost is essential for organizations to meet their SLAs and support the growing scale of their Kubernetes environments in a cost-effective way. Kubernetes provides several levers to control resource consumption and cluster performance. By implementing these optimizations and combining HPA with VPA for dynamic resizing, Tryg was able to optimize their environment and reduce Kubernetes costs by 50%. At scale with a smaller footprint. these savings have a significant impact on your bottom line.
To learn more, watch the replay of Tryg’s CNCF webinar:
For more information, see the following resources:
