Telecommunications (telco) companies deal with massive amounts of data, including social media monitoring, customer information, network traffic, and operational data. With the growing demand to increase customer satisfaction, enhance customer loyalty, and provide a personalized customer experience, telcos need efficient solutions for intelligent contact centers, proactive social media, brand reputation protection, and sound decision-making at every point in the customer lifecycle.
Telcos face several specific challenges when using call center interactive voice response (IVR) systems and social media interactions for customer support and marketing: First, speech recognition and natural language processing (NLP) technologies might not always accurately interpret customer speech, accents, or dialects, leading to miscommunication and frustration. Over social media, interactions require real-time monitoring and response capabilities to address customer inquiries, complaints, and feedback effectively. For broader marketing, developing compelling and visually appealing content requires creativity and expertise in multi-modal formats, including text, images, videos, and interactive elements.
To address these and other challenges, telcos can use GPUs on Oracle Cloud Infrastructure (OCI) to power machine learning (ML) and generative AI for various applications, such as network optimization, fraud detection, customer experience, and personalized marketing. GPUs on OCI excel in training and deploying deep learning models because of their parallel processing architecture, making them suitable for handling complex ML tasks in telecommunications. Generative AI can assist in generating content for social media posts, marketing materials, and generate scripts for Agents in Call centers to improve customer service responses
In this blog post, we explore how OCI instances powered by GPUs can benefit telco customers with accelerated performance, reduced time to insights, increased efficiency and employee productivity for manually-intensive tasks by simulating the following use case of IVR personalization: Enhancing IVR systems’ natural language understanding capabilities by interpreting and responding to customer queries more accurately and conversationally.
How Many Instances of AI Model?
This use case uses distinct AI models, consuming resources independently from one another. Moreover, this use case can apply different AI models, such as JAIS for Arabic, and different ML libraries, such as PyTorch, HuggingFace and so forth.
However, the throughput of incoming queries varies for each AI model. We evaluated the projected throughput independently in order to appropriately design the resources for each AI model. A logical chain for IVR personalization that maps the AI model onto the necessary number of instances of this AI model is demonstrated in the example below.
IVR Personalization:
- 10M customer “dialogues” per month.
- 10M/30/24/60 = 231 concurrent dialogues start every minute.
- Assuming three minutes for a typical dialogue, 231*3 = 693 dialogues happening concurrently.
- Let’s assume it takes 3 seconds for the customer to ask every question, and 6 seconds to listen to the answer. If the speech synthesis is started within 1 second from the end of the customer utterance, these dialogues send requests to LLM once in 10 seconds each = 0.1 requests/second. So, for all the dialogues 693*0.1 = 70 requests/second will be submitted.
- Assuming that an instance of an AI model can serve 3 requests/second within the interactive latency budget 70/3 = 24 instances of the IVR personalization model to process expected throughput of requests, so that customers enjoy quick response without random delays.
The logical chain includes the following nuances:
- It assumes that a dialogue of a customer and AI consists of a sparse series of customer requests, followed by responses from AI. In between these requests, nothing is happening from the AI’s point of view. Effectively, AI remains idle waiting for the next requests from a human.
- The reasoning heavily depends on the AI model and underlying ML library. In this example, we took three requests at a time to sustainably stand at the lowest latency based on our experience in PyTorch. However, this estimation may vary.
- In all cases, we round numbers up for the sake of reliable estimation.
After completing the investigation, we mapped 24 instances of a single AI model for IVR personalization to handle the volume of consumer demands.
How many GPU devices?
Now that we know we’ll have to run up to 24 instances of AI model for IVR Personalization at a time, we can calculate how many GPU devices these will consume.
Assuming that we’ll use LLAMA2 70B with GPU RAM footprint of 320GB, we’ll consume up to 320GB * 24 = 7680GB GPU RAM.
How many compute instances?
Provided that we use eight devices per compute instance BM.GPU.H100.8, 640GB GPU RAM each, we must deploy 7680/(80GB*8) = 12 compute instances. This configuration goes on a production tier for processing up to 10M inference requests in IVR personalization use case.
Total amount of resources?
As we have estimated twelve compute instances for 10M requests in production, we have an opportunity for optimization of the total amount of resources here. In the following table, there is storage real-time mirroring between the primary and DR sites:
| Tier | Primary Site | DR Site |
| PROD | 12x OCI BM.GPU.H100.8 | 1x OCI BM.GPU.A10.4 12x OCI BM.GPU.H100.8 |
| PREPROD | 9x of DR prod utilized | |
| QA | 2x of DR prod utilized | |
| DEV | 1x of DR prod utilized 1x OCI BM.GPU.A10.4 |
We’re aiming to have the production, pre-production, quality assurance (QA), and development tiers spread across master and disaster recovery facilities. This layout requires a full duplication of the production tier on the disaster recovery site to be able to quickly switch over.
Because the duplicated production tier is expected to stay idle 99% of time, we can reuse its resources for the rest of the master tiers, pre-production, QA, and development. The only differentiation of production is the maximum (production) throughput of requests, while the hardware and software configuration remains the same.
So, we can reuse the disaster recovery production tier and saturate the following resources:
- 50% of the master development: The other 50% remains on the master site to make 50% of development available constantly, regardless of a failure.
- 100% of QA, provided that QA is identical to development and business processes allow it to be unavailable in case of a disaster.
- 100% of preprod, if QA mimics prod at 75% (9 of 12) of prod throughput
Solution Architecture:
The following diagram shows the solution architecture for this use case. The head nodes 1 and 2 are used for login purposes and with the master failover configuration. The server node is in a private network with compute options (BM.GPU.A10.4, BM.GPU.4.8, and BM.GPU.H100.8) locally available with the server node for AI modal training.
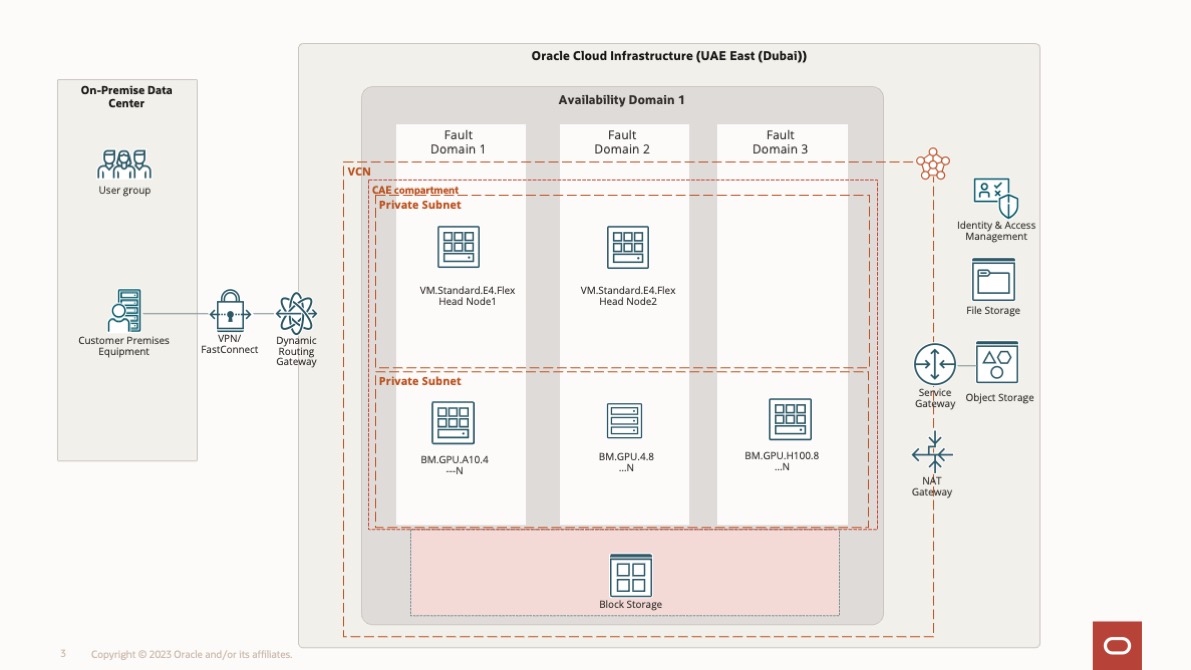
We are deploying two BM.GPU.A10.4 compute instances for fine-tuning and are distributing these across primary and DR as well.
This layout applies the following assumptions:
- Recovery from a disaster is only a few kilometers away. If the arrangement is expanded to a longer range in an asynchronous mode with a switchover latency measured in tens of seconds or less, this can also be accomplished.
- Preproduction mimics 75% of prod capacity.
- QA can become unavailable during a disaster.
Even though not practical for many customers, these assumptions still allow customer-tuning, such as extension of QA to make it constantly available across sites, at the cost of pre-production mimicking a smaller share of the production throughput. Eventually, such a layout allows for 32% cost-cutting (25 BM.GPU.H100.8 compute instances instead of 37), at the same time provides continuous development, a few seconds for switchover, and zero loss of data.
Conclusion
GPUs on Oracle Cloud Infrastructure can offer telcos significant performance improvements, scalability, and cost-efficiency across various tasks ranging from data processing and analysis to AI, video streaming, virtualization, and cybersecurity. Integrating GPU technology into telco infrastructure can help drive innovation, improve service quality, and meet the growing demands of modern telecommunications networks and services.
To learn more, see the following resources:


