Oracle Cloud Infrastructure (OCI) Data Flow is a fully managed Big Data service that runs Apache Spark applications at any scale with almost no administration. Spark has become the leading Big Data processing framework, and OCI Data Flow is the easiest way to run Spark in Oracle Cloud because there’s nothing for Spark developers to install or manage.
The problem
Big Data applications crunch large amounts of data, such as logs or sensor data, and summarize this data for downstream consumers, such as dashboards or user-facing applications. Because downstream consumers need this data fresh, Big Data applications need to complete within a certain time window, referred to as a service-level agreement (SLA).
Consider a manufacturing sensor application that crunches hundreds of gigabytes of data per minute and summarizes it in a dashboard. The business needs data in the dashboard to be no more than five minutes old to avoid manufacturing problems. That five-minute threshold becomes the SLA, and the operations team needs to be alerted immediately if the SLA is not met.
Because these applications run on a schedule, no one is watching them, and Operations needs to be alerted if things are running too slow or failing. Until now, Data Flow users had to solve this problem themselves, building custom management scripts or using OCI’s Apache Airflow plugin for Data Flow. Data Flow application metrics give the power to solve these problems directly within the OCI Console.
Announcing Data Flow application metrics
Available now, Data Flow applications include metrics to track SLAs and stay on top of Spark application health. Look deeper into a Data Flow application, and the following SLA statistics are available:
-
Startup times for each run of the Data Flow application
-
Execution times for each run of the Data Flow application
-
Total run time = startup time + process time
These metrics show how consistently the application hits its SLAs. These metrics also integrate with the OCI Monitoring service, allowing alerts through PagerDuty, Slack, or email if things go wrong. Let’s look at an example.
Example: Alert when a spark application runs too long
Let’s say we have an application that needs to complete in less than 10 minutes. We start by navigating to the specific application in the OCI Console.
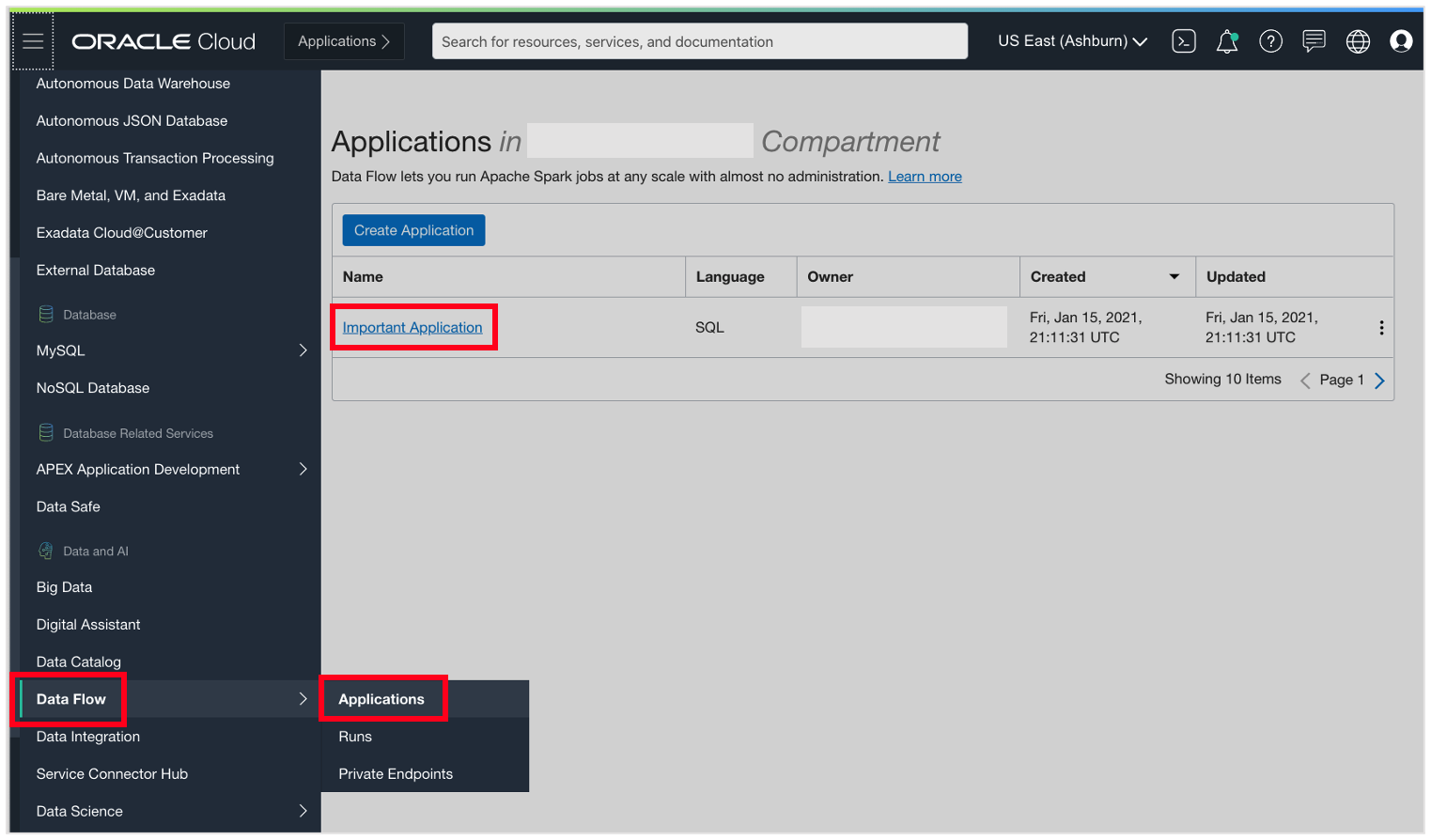
When we select the application in the Console, we see a panel called Total Run Time. Selecting Options inside this panel lets us create an alarm on this query.
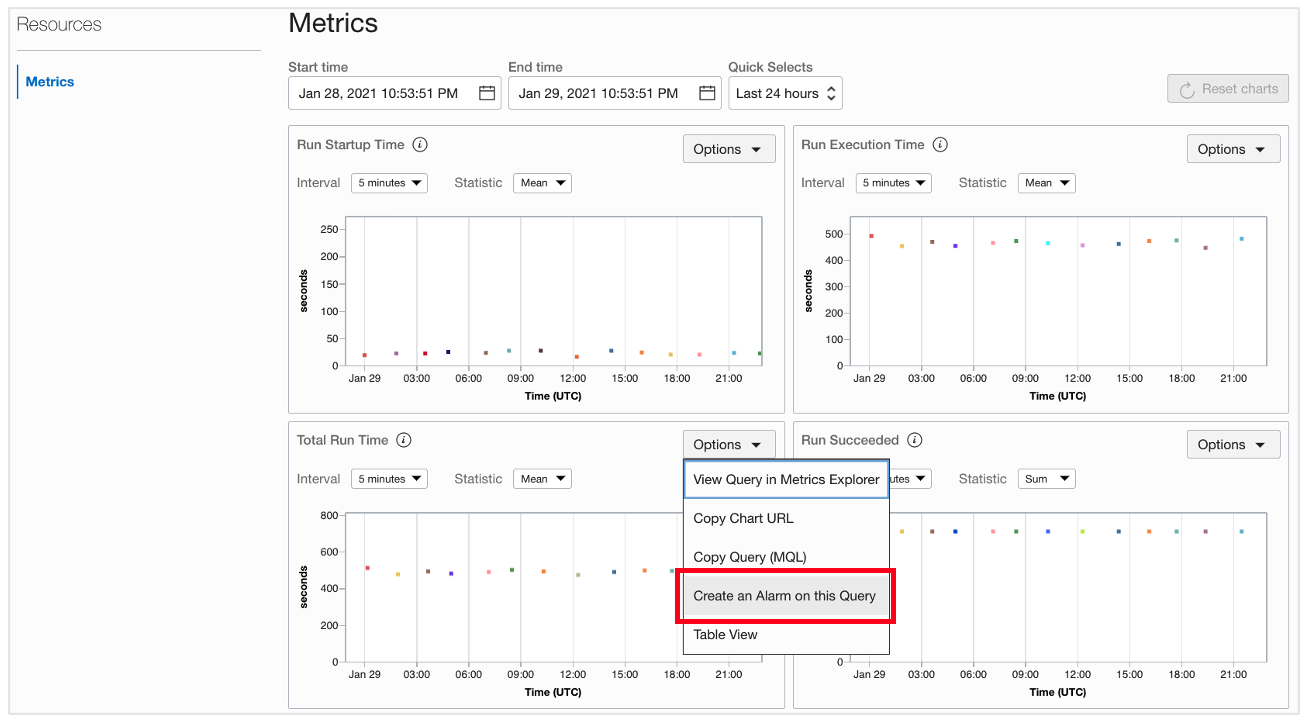
Clicking this option takes us to an alarm definition interface with many fields prepopulated.
This blog doesn’t cover basic setup details for alarms like required IAM policies. For an overview, refer to the Alarms section of the OCI Monitoring service. To create our alarm, we need to do the following tasks:
-
Configure our metric name and dimensions
-
Set the SLA threshold in the Trigger rule section
-
Link the alarm to a notification topic
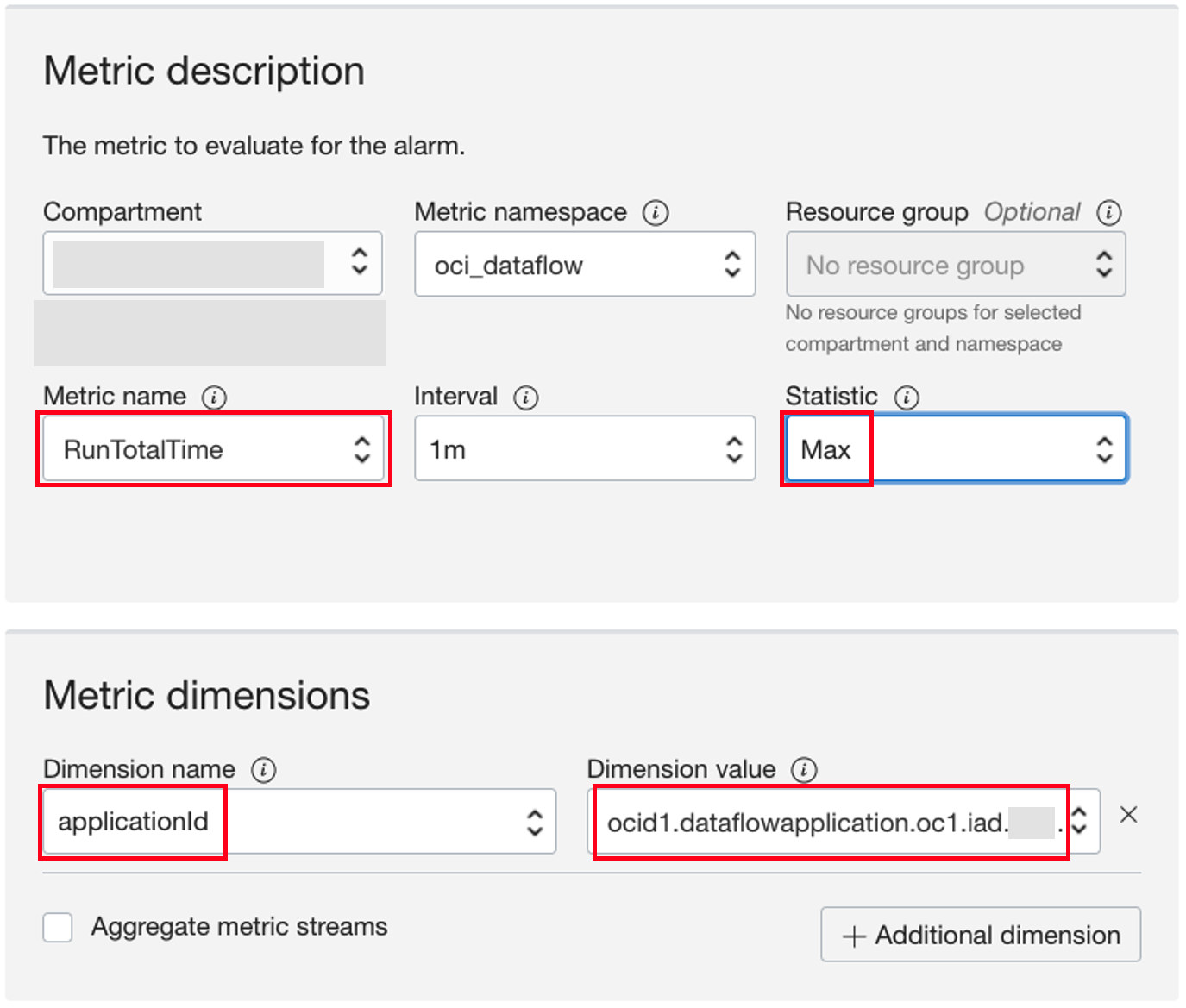
First, the metric name and dimension. Since we’re tracking the total run time, we use the RunTotalTime metric and the Max statistic. For the dimension, we select the specific Data Flow application that we’re monitoring.
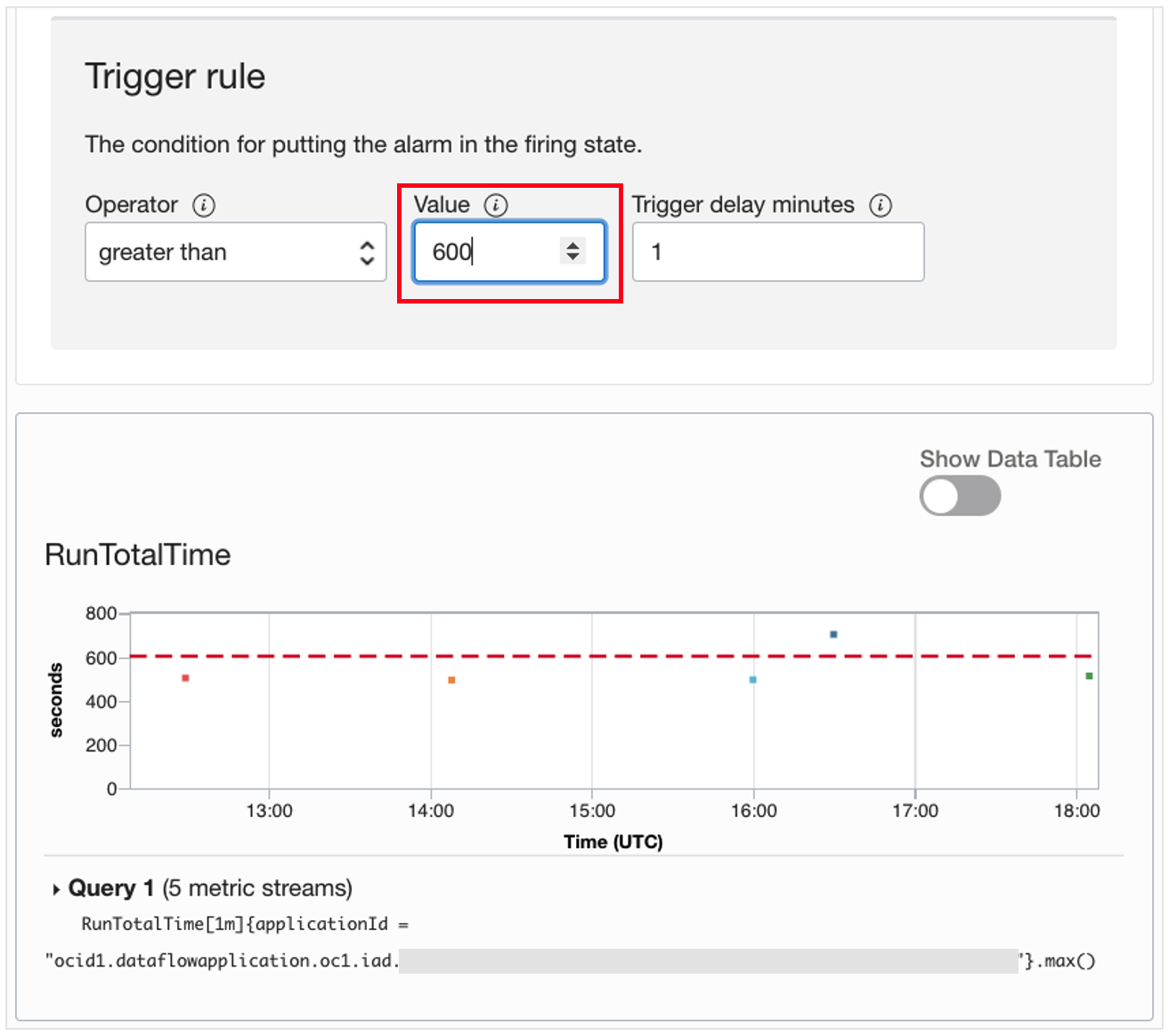
Set the trigger rule value to the SLA in seconds. Because we’re targeting 10 minutes, we set this to 600 seconds.
Finally, link the alarm to a notification topic. The topic controls how alerts are delivered and to whom. For more detail on how, see the Notifications service documentation.
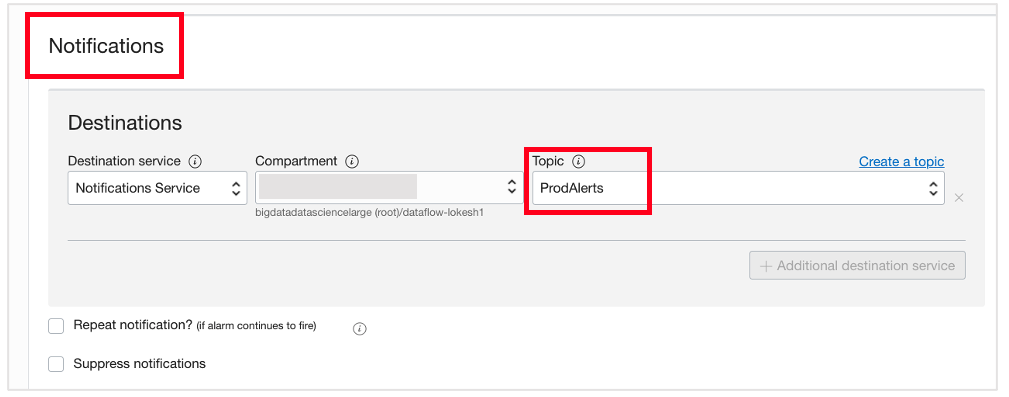
With this alarm, any run of the Data Flow application lasting longer than 600 seconds causes the alarm to go off.
Other use cases
Application metrics address the following common monitoring tasks:
-
Alerting if jobs fail, or they fail repeatedly.
-
Alerting if too many jobs are running concurrently.
-
Alerting if a job takes a long time to start.
See for yourself
Data Flow application metrics are available now in all commercial regions. With Data Flow, you only pay for the resources that your Spark jobs use while Spark applications are running, so there’s no extra charge for these metrics. To learn more about Data Flow application metrics, see the Data Flow documentation.
To get started today, sign up for the Oracle Cloud Free Trial or sign in to your account to try OCI Data Flow. Try Data Flow’s 15-minute no-installation-required tutorial to see how easy Spark processing can be with Oracle Cloud Infrastructure.
