JAX is a rapidly growing Python library for high-performance numerical computing and machine learning (ML) research. With applications in drug discovery, physics ML, reinforcement learning and neural graphics, JAX has seen incredible adoption in the past few years. JAX offers numerous benefits for developers and researchers, including an easy-to-use NumPy API and direct integration with Autograd for easy differentiation and optimization. JAX also includes support for distributed processing across multinode and multi-GPU systems in a few lines of code, with accelerated performance through XLA-optimized kernels on NVIDIA GPUs.
To help more customers to take advantage of the power of JAX, Oracle and NVIDIA are working together to enable easy setup and use of JAX on multinode clusters in OCI. With the combination of Oracle Cloud Computing platform, NVIDIA GPUs and RDMA networking, you can take advantage of the scalability and performance benefits of JAX in a cloud environment.
In this guide, we walk through how to set up a multinode high-performance comuting (HPC) cluster powered by NVIDIA A100 Tensor Core GPUs on OCI with built-in support for CUDA and SLURM. We also go over how to install JAX into that environment and get started with multinode JAX code.
Import a GPU + OFED image into OCI
First, we import a machine image into your compartment that includes support for both GPU computation with CUDA and RDMA over ethernet using OFED.
-
In the Oracle Cloud Console, go to the menu and, in the Compute section, select Instances.
-
In the side panel, select “Custom Images” and then “Import image.”
-
Select “Import from object storage URL” and “OCI.”
-
Use the following URL to import the image: https://objectstorage.ap-osaka-1.oraclecloud.com/p/-O5UHXYmvBSvGcNBhMDH6e263KXVRPit-_wRY6D9275faFJiS2_IiovreESkWtPI/n/hpc_limited_availability/b/Obj_archive/o/OracleLinux-7-UEK-OFED-5.4-3.1.0.0-GPU-510-2022.05.07-0
The image is accessible on request with current OCI subscriptions.
Create a multinode cluster with NVIDIA A100 GPUs in OCI
-
Log in to the Oracle Cloud Console.
-
In the Marketplace section of the menu, select “All applications.”
-
Search for and select “HPC cluster.”
-
Choose the latest version and your OCI compartment. Then click Launch stack.
-
Optionally, configure your cluster name, description, and tags. Then, click Next.
-
For your cluster configuration, use the following settings:
-
Upload your SSH public key. If you don’t have SSH keys, you can generate a public or private key pair using ssh-keygen and following the prompts. For more information, such as generating keys or Windows, see Generate SSH Keys.
-
For the head node, select an availability domain, and leave the shape as default. Increase the disk size to 500 GB.
-
For the Compute nodes, select an AD availability, choose the “BM.GPU4.8” shape (8x NVIDIA A100 40GB Tensor Core GPUs), uncheck hyperthreading, increase the boot disk to 500 GB, select 4 as “Initial cluster size” for four nodes, uncheck “use marketplace image,” and select the image you imported previously.
-

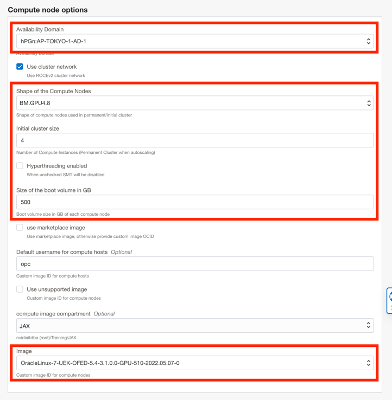
Leave the other options at their default and click Next. On the review page, check “Run apply” and then click Create.
-
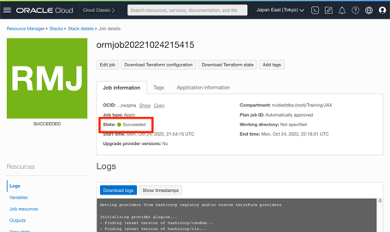
In the menu, go to “Resource Manager” and then “Stacks.”
-
Select the “Stack detail” and then “Job details.”
-
Wait for the apply job to finish and succeed. This process can take 15–45 minutes.
SSH into the head node and install Python and JAX
-
In the menu, go to Compute and then Instance.
-
Locate the public IP address of the head node.
-
Use the IP address to SSH into the head node with the following command:
ssh opc@[IP_ADDRESS] -
Install Miniconda and Python by running the following command:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh && bash ~/miniconda.sh -b -p ${HOME}/miniconda && ~/miniconda/bin/conda init bash -
Log out and log back in. Then install Jax with the following command:
pip3 install --upgrade "jax[cuda]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
Run your first JAX code with SLURM
OCI HPC clusters come preinstalled with SLURM, which simplifies running multiprocess jobs across multiple nodes. To run JAX with SLURM, create a file ~/run.py with the following content:
import jax
import jax.numpy as jnp
jax.distributed.initialize()
print(f"Total devices: {jax.device_count()}, "
f"Devices per task: {jax.local_device_count()}")
x = jnp.ones(jax.local_device_count())
# Computes a reduction (sum) across all devices of x
# and broadcast the result, in y, to all devices.
# If x=[1] on all devices and we have 32 devices,
# the result is y=[32] on all devices.
y = jax.pmap(lambda x: jax.lax.psum(x, "i"), axis_name="i")(x)
print(y)From the login node, run the following command:
(base) [opc@helpful-python-bastion ~]$ srun -N 4 -n 32 --tasks-per-node=8 --gpus-per-node=8 bash -c "~/miniconda/bin/python3 ~/run.py"You get receive the following output:
Total devices: 32, Devices per task: 1
[32.]
⋮
Total devices: 32, Devices per task: 1
[32.]Congratulations! You have successfully run a JAX job on four nodes with 32 NVIDIA A100 GPUs and 32 processes in total. With this guide, you’re well-equipped to get started on your multinode JAX journey. For more information on how JAX multihost processing works, visit the JAX documentation. For more information and the latest updates for JAX GPU workloads, sign up for NVIDIA’s JAX Early Access program, where you can get an early look at how JAX can run faster and at larger scales on GPUs.
Getting started
The addition of the NVIDIA A100 80GB GPU complements the existing line up of available NVIDIA GPUs on OCI including the just announced A10 GPU, opening a new era of accelerated computing for startups, enterprises, and governments around world on OCI. Not all workloads are the same, and some might require customization to work optimally on the latest generation GPU hardware. OCI offers technical support to get your workload up and running, so talk to your sales contact for more information.
For more information about BM.GPU.GM4.8 instances including specifications, pricing, and availability, see our documentation. To learn more about Oracle Cloud Infrastructure’s capabilities, explore the following resources:
Acknowledgments
Leopold Cambier, software engineer
Leopold Cambier received his Ph.D. in Computational and Mathematical Engineering from Stanford University in 2021. During his Ph.D., he focused on fast solvers for very large sparse linear systems, from both a theoretical and parallel-computing perspective. He also interned at NVIDIA in 2016 and 2017 when he worked on cuDNN. Since he joined full-time in January 2021, Leopold has been working on cuFFT and cuFFTMp in the CUDA Math Libraries team, and more recently on JAX.
Neal Vaidya, technical marketing engineer
Neal Vaidya is a technical marketing engineer for deep learning software at NVIDIA. He is responsible for developing and presenting developer-focused content on deep learning frameworks and inference solutions. He holds a bachelor’s degree in statistics from Duke University.
