Kubernetes has become the standard platform for automating deployment, scaling, and management of modern containerized applications. Data scientists and machine learning (ML) engineers have also gravitated to Kubernetes since its infrastructure abstraction capabilities enable them to better focus on their workloads. An increasing number of data science platforms are today built on top of containers and plugged into Kubernetes.
GPU-based compute infrastructure that data science and ML workloads run on tend to be quite expensive, so there’s strong motivation to maximize their utilization. The ideal scenario is one where available GPU resources are pooled together and managed by a scheduling system that provides multiple queues with different priorities, through which jobs are submitted. Users are assigned quotas to ensure that everyone gets a fair share. Also, when resources are idle, jobs are allowed to use resources above their quota limits. When a user’s job or higher priority request comes along, the scheduler preempts jobs as needed in accordance with a configurable policy. Gang scheduling is supported to ensure that all parts and pieces of a job get started together. When choosing GPU nodes to run a job, the scheduler considers the topology of interconnections between them to maximize performance. Detailed resource utilization easily provides accounting information for appropriate cost sharing.
Implementing such an environment is relatively straightforward using schedulers, such as Slurm and LSF, which are predominantly used in traditional CPU-based high-performance computing (HPC) setups. But while Kubernetes provides first class support for orchestrating containerized workloads, its scheduling mechanism lacks the functionality to implement such an environment to maximize GPU utilization.
The Run:ai solution
Run:ai is a cloud native AI orchestration platform that simplifies and accelerates AI and ML through dynamic resource allocation, comprehensive AI lifecycle support, and strategic resource management. Pooling GPU resources from both public and private cloud infrastructure and utilizing Run:ai significantly enhances GPU efficiency and workload capacity. Its policy engine, open architecture, and deep visibility into AI workloads foster strategic alignment with business objectives, enabling seamless integration with external tools and systems. This combination results in significant increases in GPU availability, workloads, and GPU utilization, all with zero manual resource intervention, accelerating innovation and providing a scalable, agile, and cost-effective solution for enterprises. Run:ai supports most popular versions of Kubernetes.
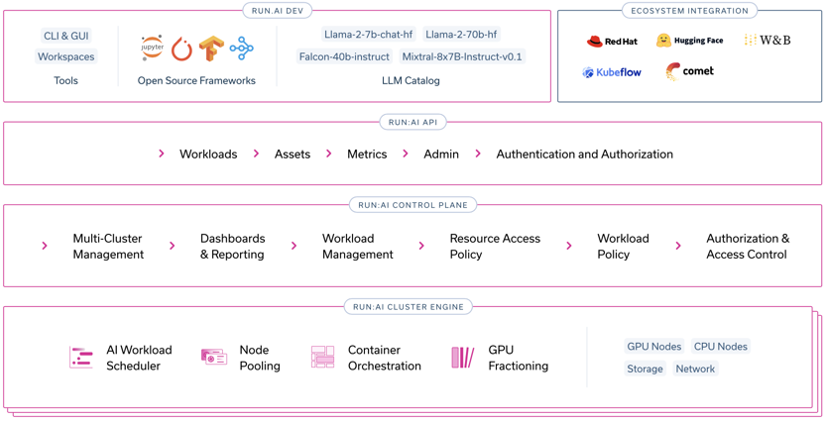
In a joint exercise, Oracle and Run:ai engineers set up and tested the Run:ai solution in the Oracle Cloud Infrastructure (OCI) environment. This article highlights some of the key features tested during this activity.
Projects
Run:ai uses projects to streamline resource allocation and prioritize work. An administrator creates a project in the user-interface and assigns researchers to it. They also specify the number of GPUs, CPUs, CPU memory allowed for use. Policies regarding allowing “over quota” usage and scheduling rules are also configured in a project.
Internally, Run:ai projects are implemented as Kubernetes namespaces. A researcher submitting a job must associate a project name to the request for the Run:ai scheduler to determine eligibility and allocate resources.
Workspaces
A workspace is a simplified tool for researchers to conveniently conduct experiments, build AI models, access standard MLOps tools and collaborate with their peers. A workspace consists of all the setup and configuration needed for research in a single space, including container images, data sets, resource requests, and all required tools for the research. With facilitating research, workspaces ensure control and efficiency while supporting various needs. An active workspace is a Run:ai interactive workload.
The following figures show connecting to an active workspace to invoke a Jupyter session.
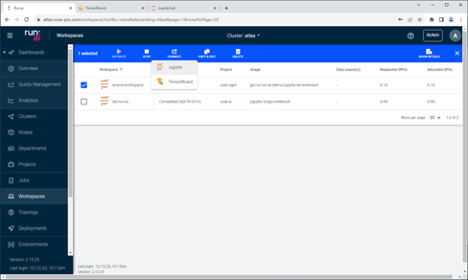
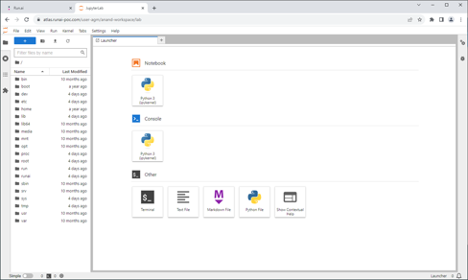
Launching workloads
The engineers submitted various kinds of workloads through the CLI and tested them successfully, including unattended training, interactive build (including exposing internal ports to user), hyperparameter optimization (HPO) and inference workloads. They also tested overquota allocation, bin packing, and preemption behaviors.
GPU fractions
Run:ai provides the capability to allocate a container with a specific amount of GPU RAM specified at the time of submitting the job. Attempting to reach beyond the allotted RAM results in an out-of-memory exception. This configuration enables multiple containers to simultaneously run on a single GPU, each utilizing its own specified fraction of the total GPU memory. All workloads running on a single GPU share the compute capabilities in parallel and on average get an even share of the compute. Specifically, the GPU fractions feature does not require a GPU that supports NVIDIA multi instance GPU (MIG) technology.
In the following tests, two jobs are run simultaneously on a single GPU each taking 50% and 20% of available GPU memory.



Dynamic MIG
Run:ai also provides a way to dynamically create a MIG partition NVIDIA GPUs that support the technology, such as NVIDIA A100. This process happens spontaneously, without needing to drain workloads or involve an IT administrator. The partitions are automatically deallocated when the workload finishes. The partition isn’t removed until the scheduler determines that it’s needed elsewhere.
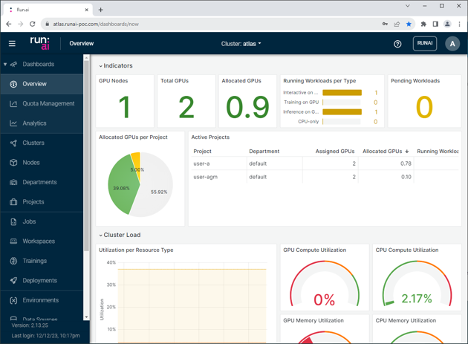
Conclusion
The Run:ai solution offers more than just an improvement in GPU utilization. It’s a transformative asset for enterprises aiming to lead in the competitive landscape of AI-driven industries. By optimizing resource allocation, Run:ai not only enhances the operational efficiency of Kubernetes environments, but also significantly accelerates the pace of AI innovation. This solution can directly translate into faster time-to-market for new AI solutions and improvements in cost efficiency. For organizations looking to scale their AI capabilities without corresponding increases in operational complexity or costs, Run:ai offers a compelling solution. We invite you to explore how Run:ai can tailor its capabilities to your specific business needs.
By integrating Run:ai’s cloud native approach, enterprises can ensure that their AI and ML workloads are not just running, but running smarter, faster, and more cost-effectively.
Discover firsthand how Run:ai can revolutionize your AI projects by scheduling a personalized demo. For detailed tech briefs, case studies, and webinars that delve into the capabilities and successes of Run:ai solution and services, visit our resources page. If you’re ready to discuss your organization’s needs, visit our site today to get started on transforming your AI infrastructure.
For more information, see the following resources:

