Scalability is a desirable attribute of a system or process. Poor scalability can result in poor system performance. Scaling an Oracle Container Engine for Kubernetes (OKE) cluster can be challenging, and if it’s not done, you can have difficulty scaling up the application when the cluster is running at capacity. During this time, your app can easily be overwhelmed with connections because it can’t scale further.
Kubernetes autoscaling automatically adjusts the number of nodes in a cluster according to current resource usage to ensure that the workload completes and resources are used efficiently. However, during periods of high utilization, the rate at which nodes are provisioned might not be sufficient to keep up with demand, resulting in an overwhelmed application and dropped connections.
Combining cluster overprovisioning with node autoscaling in a Kubernetes cluster can ensure that, during high utilization, sufficient node resources are available to support the application, without wasting resources and incurring unnecessary costs.
This blog walks you through the process of effectively overprovisioning an Oracle Container Engine for Kubernetes (OKE) cluster for scaling and failover.
When you need cluster overprovisioning
Let’s consider an OKE cluster running at capacity with no resources left for more pods. The cluster autoscaler reacts by adding a node only when new pods are in a pending state. It can take few minutes for the control plane to add new worker nodes to the cluster and be ready to provision the new pods. This delay can result in dropped connections and unavailability for your application. Critical applications need new pods to be deployed immediately.
Cluster autoscaler
The cluster autoscaler is a GitHub project that you can deploy on OKE. To enable autoscaler in OKE clusters, you deploy it to your cluster like a regular application and configure it so that it finds and manages your node pool. Instances are grouped as a node pool in Oracle Cloud Infrastructure (OCI).
The cluster autoscaler performs the following tasks:
-
Add more nodes to the node group if pods are in pending state (You need resources to schedule a pod)
-
Remove nodes that are underutilized for a certain period: Separate and drain node, then remove it from the node group
Pod priority to achieve node scaling
The problem of node scaling has no default solution, but we can consider the following workarounds:
-
Use pod priority and preemption: Reserve the fixed CPU and memory needed for critical services
-
Always have fixed extra worker nodes to accept the new pod, but this method isn’t cost-efficient
Because the second method isn’t cost-efficient, let’s use pod priority and preemption. As a prerequisite, deploy and configure your OKE cluster with cluster autoscaler.
Pod priority and preemption are Kubernetes features that allow you to assign priorities to pods. When the cluster is low on resources, it can remove lower-priority pods to make space for higher-priority pods waiting to be scheduled.
With pod priority, we can run some dummy pods for reserving extra space in the cluster, which are freed when “real” pods need to run. The pods used for the reservation are ideally not using any resources but just sitting and doing nothing. You can use pause containers for dummy pods that are already used in Kubernetes for a different purpose. Create dummy pods with a pod priority of “-1.” By default, a pod is created with a priority of “0.”
Now, consider an OKE cluster with two worker nodes with 6 CPUs each. Let’s overprovision and create a dummy pod with 4 CPUs to see what happens when we create another pod.
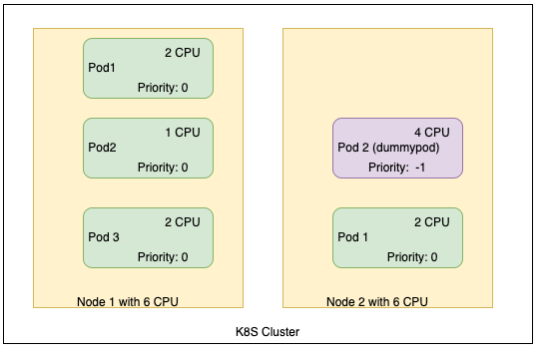
When a pod is created with 3 CPUs, the scheduler looks for the resource availability. When the resources aren’t available, the scheduler removes the low-priority pod from node 2 and schedules the new pod on node 2. The new pod, “dummypod,” moves to a pending state. Now, the cluster autoscaler reacts to the pod pending state by adding a node to the cluster.

The following code block provides a sample pod yaml for creating a dummy pod with lower priority:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: dummypod
spec:
replicas: 1
selector:
matchLabels:
run: dummypod
template:
metadata:
labels:
run: dummypod
spec:
priorityClassName: overprovisioning
containers:
- name: reserve-resources
image: iad.ocir.io/myimages/oke-public-pause
resources:
requests:
cpu: 1
memory: 4Gi
Conclusion
We can run a few paused pods in our cluster to reserve space for the cluster autoscaler to add more nodes. These dummy pods have a lower priority than regular pods, which have a priority of “0.” The dummy pods are removed from the cluster when resources are unavailable. The dummy pods then go into a pending state, which triggers the cluster autoscaler to add capacity.
For product details and testimonials, access the OKE resource center. To learn more about other concepts in this blog, see Cluster Node Autoscaling with OCI Container Engine for Kubernetes and Pod Priority and Preemption.