With the rapid growth of ChatGPT—over 100 million active users in just two months—people hear “large language model” (LLM) over and over. However, while the “language” in the name LLM refers to their original development for language processing tasks, the “large” is far more informative. All LLMs have many nodes—the neurons in a neural network—and an even larger number of values that describe the weights of the connections among those nodes. While they were first developed to process language, they can potentially be used for various tasks, including extensive use in protein research.
The recent breakthroughs of LLMs in the context of natural language processing (NLP), and the relationships between human natural language and the language of proteins, invite the application and adaptation of LLMs to protein modelling and design. Protein language models have been already trained to accurately predict protein properties and generate novel functionally characterized proteins, achieving state-of-the-art results. In this blog post, we show how an Oracle Cloud Infrastructure (OCI) customer takes advantage of the benefits of OCI NVIDIA GPU infrastructure’s compute scalability and performance for antibody discovery.
Protein LLM training
To test their system, the researchers tried a range of LLM sizes, varying the number of parameters that describe the strength of the connections among their nodes from 8 million up to 15 billion. A clear pattern emerged with the varying sizes. For proteins that were rare or unusual in some way, performance started out low in the base LLM and improved as the size went through XL to XXL. Nothing indicated that this improvement had saturated, even with the 15 billion-parameter, XXL system.
So, we’re still at the point that throwing more computational resources at the problem improves overall performance, even though it’s already as good as it’s likely to get for many individual proteins. We provisioned a single OCI NVIDIA GPU node to train the protein LLMs with eight A100 NVIDIA GPUs.
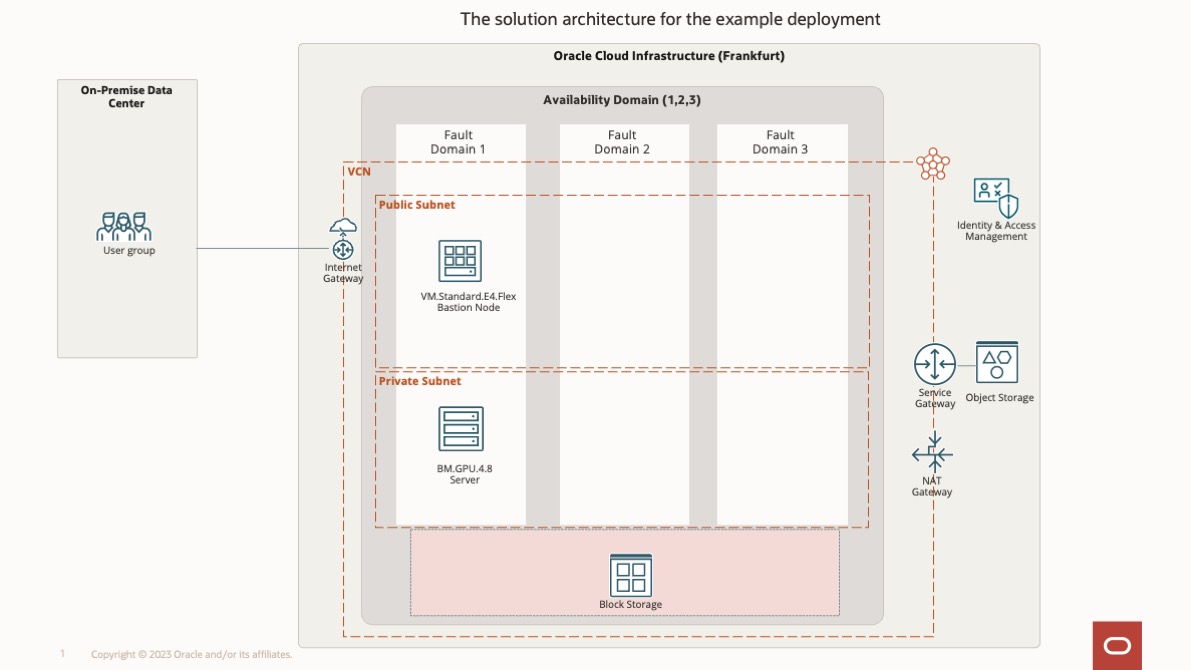
Solution Architecture
A solution architecture is an architectural description of a specific solution based on best practices. The following diagram shows the OCI architecture that the customer used in detail. It uses a bastion node in the public network for log in purposes. The server node is in a private network and uses the BM.GPU4.8 shape with eight A100 NVIDIA GPUs with 500 GB of boot volume. A 27.2-TB NVMe SSD is locally available with the server node for AI modal training.
Challenges
The customer faced the challenge of the default Oracle Linux NVIDIA GPU image Logical Volume Manager (LVM) root partition not being sufficient. We created a boot volume of 500 GB but needed to resize to get all available storage in the root partition. We followed the solution available in Resize Boot Volume in Linux 7 and 8 Instances in OCI to resize the LVM root partition to 500 GB on the NVIDIA GPU instance, which worked perfectly.
Testing and Results
We trained models in OCI GPU Infrastructure environment for a customer’s internal wet lab validation project. A wet lab is one where drugs, chemicals, and other types of biological matter can be analyzed and tested by using various liquids. They needed to redesign important regions of an approved breast cancer drug, trastuzumab.
We trained six novel protein LLMs (about 1 billion parameters each) for generation of antibody binding regions and 15 novel protein LLMs (about 0.5 billion parameters each) for selection of better candidates among the generated ones. The customer utilized all eight A100 NVIDIA GPUs for this LLM training, and the computational resources of that scale were crucial for this project.
Using those models, the customer generated 40 variants of trastuzumab with redesigned regions and sent them to their wet lab partner for the wet lab validation. These results show that OCI reduces the time needed to train large protein language models with a simple ethernet network architecture. OCI Compute bare metal instances powered by NVIDIA GPUs offer ultra-low latency and bare line-rate network performance.
Conclusion
With OCI as the foundation for their solutions, customers can use our GPU Compute service, high-performance network, and storage to help run LLM workloads at scale. While this customer used OCI to train protein LLMs within the necessary time frame, the modelling productivity continues to increase and can be applied to a wide variety of uses.
OCI offers support from cloud engineers for training LLMs and deploying NVIDIA GPUs at scale. To learn more about Oracle Cloud Infrastructure’s capabilities and supercluster architecture, see the following resources:
- OCI Compute: GPU Instances
- OCI Compute: High-performance computing
- First principles: superclusters with RDMA—ultra-high performance at massive scale
- First principles: building a high-performance network in the public cloud
