This guest blog was written in collaboration with Anne Holler, advisor at Elotl.
Deep learning models are being successfully applied in various fields, including image and natural language processing (NLP). Managing deep learning inferencing at scale for diverse models presents cost and operational complexity challenges. The resource requirements for serving a deep learning model depend on its architecture, and its prediction load can vary over time, leading to the need for flexible resource allocation to avoid provisioning for the maximum number of resources needed at peak load. Using the cloud to allocate resources flexibly can often add operational complexity to obtain minimum-cost resources matching model needs from the large and ever-evolving sets of instance types. Selecting minimum-cost cloud resources is particularly important given the high cost of x86 GPU compute instances, which are often used to serve deep learning models.
This blog post describes an approach to managing the cost and operational complexity of deep learning inferencing at scale using cloud resources, organized in a Kubernetes (K8s) cluster, combining the following processes:
-
Right-sizing the inference resources using Elotl Luna smart node provisioner, which adds right-sized compute to cloud K8s clusters when needed and removes it when not
-
Right-sizing the inference compute type, using Oracle Cloud (OCI) Ampere A1 Arm compute with the Ampere Optimized AI library, which can provide a price-performance advantage on deep learning inferencing relative to GPUs and to other CPUs
The benefits of this approach include significantly reduced costs and simplified operations when compared against non-right-sized resource allocation with the x86 GPU compute type for inference performed by autoscaled TorchServe deployments on an OCI OKE K8s cluster.
The spectrum of deep learning
Deep learning model architectures differ greatly in their serving resource requirements, particularly the system memory needed to store their weights. So, using cloud instance shapes that are right-sized for the models to be served can be economical. In production settings, a model’s prediction load can vary significantly according to time-of-day and other factors. So, the ability to automatically adjust serving resources to match the load is highly desirable.
While expensive GPUs are often used to serve deep learning models, some latency-sensitive server deep learning inference use cases involving a batch size of one can be better handled on thriftier CPUs. This alternative is worth evaluating in deployment preparation. Exploiting these efficiencies at scale with low operational complexity can be difficult, involving ongoing maintenance of the data required to obtain minimum-cost resources matching model needs from the large and ever-evolving sets of cloud instance types.
This post describes an approach to reducing the cost and operational complexity of deep learning inferencing at scale using cloud resources, organized in a K8s cluster for production-grade orchestration. The approach combines right-sizing the inference resources using Elotl Luna and right-sizing the inference compute type using OCI Ampere A1 Arm Compute instances. We first describe the components of the approach. Then we present results comparing the approach with two other approaches, each running on x86 GPU without optimized resource right-sizing. We then summarize and outline how the approach can fit into a multiple-cluster K8s environment, utilizing Elotl Nova cluster placement.
Right-sizing inference sources and compute type
The approach to right-sizing inference resources uses Elotl Luna, which provisions just-in-time right-sized cost-effective compute for cloud K8s when needed, removing it when not. Luna’s management of x86+GPU compute for deep learning training workloads, illustrated by validating Ludwig AutoML for tabular and text classification datasets running on Ray Tune, was previously reported.
Adapting Luna to managing right-sized compute for deep learning inference workloads was simple. We enabled its option to consider Arm instances and x86 instances, and we tuned its bin packing versus bin selection policy setting to use the highly granular Compute shapes available for OCI Ampere A1 compute. And support for running Luna itself on the Arm platform was added, to allow the use of Arm-only K8s OKE clusters when appropriate.
The approach to right-sizing the inference compute type utilizes OCI Ampere A1 Arm compute resources with the Ampere Optimized AI library. This combination is a CPU system tuned to perform deep learning inference without accuracy degradation. While the latest MLCommons datacenter inference benchmarks show GPU systems delivering the highest absolute performance for the tested scenarios, several cloud server scenarios can run more cost-efficiently on CPU-only systems, as discussed in CPU AI Inference in the Cloud.
For our use case, in which predeployment tests established that CPU-only deployment worked well, Luna chose Ampere A1 as more cost-competitive than x86. Note that Ampere A1 can also be more performant. This article shows the Ampere A1 shape outperforming x86 CPU shapes on the resnet_50_v15 model at fp32 resolution, delivering more than 1.5-times the performance over AMD’s best E4 OCI shape and more than twice the performance over Intel’s Standard3 OCI shape at the same cost.
Impact of right-sizing inference
We demonstrate the impact of right-sizing inference on a deep learning inference system with autoscaling, deployable on cloud-based K8s. We chose TorchServe, a high-performance full-featured tool for serving PyTorch models. TorchServe supports tuning resource-related settings for each model it is serving. You can deploy on cloud-based K8s clusters with autoscaling that responds to loads by changing the count of serving replicas backing its load-balancing endpoint.
We consider the workload of serving two standard deep learning models: vgg16 and squeezenet1_1. Model attributes are shown in Table 1. Note the large difference in weights between the two models.
| Model |
Task |
Weights |
| vgg16 |
Image classification |
138M |
| squeezenet1_1 |
Image classification |
1.2M |
Table 1: Models for inference resource management experiments
Each model is handled by a separate TorchServe deployment to allow each TorchServe worker replica size to be customized to the model size and each TorchServe worker replica count to scale for model load independently. Figure 1 depicts the experimental setup.
Figure 1: Set up for right-sizing experiment

We compare the following configurations:
-
Max-sized configuration: Static inference configuration with peak-count maximum-sized x86 GPU nodes, maintains sufficient x86 GPU resources to satisfy peak load for both models
-
Dynamic fixed-size configuration: Dynamic inference configuration with maximum-sized x86 GPU compute nodes, autoscales K8s x86+GPUs, which are less cost-efficient than A1 for my use
-
Right-sized configuration: Dynamic inference configuration with right-sized Ampere A1 compute nodes. Luna autoscales K8s CPUs, choosing right-sized cost-efficient A1 nodes.
For each model’s peak load, we use the hey load generator to run 10 minutes of 150 parallel threads requesting image classification on kitten_small.jpg. We configured TorchServe for low latency, setting worker and netty threads to 1. The TorchServe horizontal pod autoscaler is set to scale up to a specified maxReplicas based on CPU utilization greater than 50 percent, which triggers scaling for both CPU-only and GPU-enabled pods. I set maxReplicas based on maintaining 99 percentile end-to-end latency below 0.5 seconds at my maximum load.
The K8s cluster under test includes two statically allocated Ampere Arm CPU nodes to handle cluster management tasks, including hosting Luna. Each node uses a VM.Standard.A1.Flex shape with two OCPUs and 32 GB. Each model’s TorchServe deployment is set to create a minimum of one worker pod. Table 2 shows the computing resources for the three TorchServe configurations, including the worker pod size requested, the node instance type selected for the pod, and the maximum number of worker pods needed to handle the peak load. The worker pod memory needed for squeezenet1_1 was increased when running on a x86 GPU system.
| Config |
Vgg16 worker pod size |
Vgg16 node instance type |
Vgg16 max worker pod count |
Squeezenet1_1 worker pod size |
Squeezenet1_1 node instance type |
Squeezenet1_1 max worker pod count |
| Max-sized |
400 m, 4 GB, 1 GPU |
VM.GPU2.1 |
3 |
40 0m, 2 GB, 1 GPU |
VM.GPU2.1 |
3 |
| Dynamic fixed-size |
400 m, 4 GB, 1 GPU |
VM.GPU2.1 |
3 |
400 m, 2 GB, 1 GPU |
VM.GPU2.1 |
3 |
| Right-sized |
400 m, 4 GB |
VM.Standard.A1.Flex with 1 OCPU, 4 GB |
4 |
400 m, 1 GB |
VM.Standard.A1.Flex with 1 OCPU, 1GB |
4 |
Table 2: Computing resources for TorchServe configurations
Table 3 shows the 95 and 99 percentile end-to-end latency for the two models simultaneously handling peak load running on the right-sized and maximum x86 GPU configurations. Both configurations meet the desired end-to-end latency target for the presented workload.
| Model |
Right-sized 95% latency seconds |
Right-sized 99% latency seconds |
x86 GPU 95% latency seconds |
x86 GPU 99% latency seconds |
| vgg16 |
0.2243 |
0.2703 |
0.2453 |
0.4457 |
| squeezenet1_1 |
0.2176 |
0.2672 |
0.2975 |
0.4225 |
Table 3: 95 and 99 percentile latency seconds for right-sized and x86 GPU configurations
Table 4 presents the costs per hour for the three configurations at the following operating points:
-
Both models at idle load
-
Both models at peak load
-
Model vgg16 at idle load and model squeezenet1_1 at peak load
-
Model vgg16 at peak load and model squeezenet1_1 at idle load
Each statically allocated cluster management node costs $0.01×2 + $0.0015×32 = $0.0680/hr. For right-sized vgg16, each TorchServe pod was allocated to a node costing $0.01×1 + $0.0015×4 = $0.0160/hr. For right-sized squeezenet1_1, each TorchServe pod was allocated to a node costing $0.01×1 + $0.0015×1 = $0.0115/hr. For vgg16 and squeezenet1_1 on x86+GPU, each TorchServe pod was allocated to a node costing $1.2750/hr. Figure 2 shows the relative costs of dynamic fixed-size and right-sized costs to max-sized costs. When both models aren’t at peak, the Dynamic fixed-size configuration significantly reduces cost relative to the max-sized configuration. The right-sized configuration yields large savings for all four scenarios, reducing costs by nearly two orders of magnitude in all cases.
| Load |
Max-sized $/hr |
Dynamic fixed-size $/hr |
Right-sized $/hr |
| Both models idle |
7.7860 |
2.6860 |
0.1635 |
| Both models peak |
7.7860 |
7.7860 |
0.2460 |
| Vgg16 idle, Squeezenet peak |
7.7860 |
5.2360 |
0.1980 |
| Vgg16 peak, Squeezenet idle |
7.7860 |
5.2360 |
0.2115 |
Table 4: Cost results for inference resource management experiments
Figure 2: Relative costs of max-Sized, dynamic fixed-size, and right-sized shapes
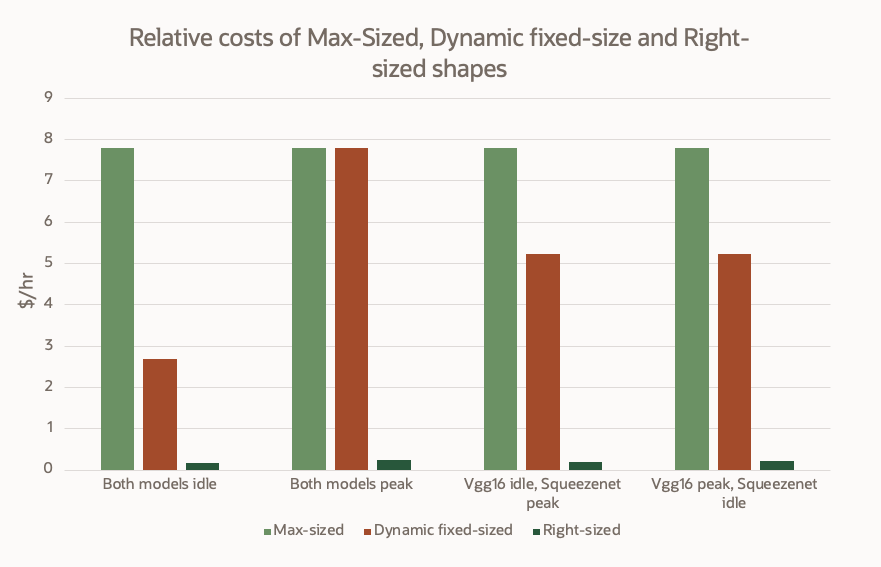
Table 5 compares the three configurations in terms of three areas of operational complexity. The right-sized configuration automatically adapts to changes in TorchServe maximum number of workers needed, in TorchServer worker size, and in cloud instance availability and offerings. The max-sized configuration requires manual update for changes in any of the three. The dynamic fixed-size configuration automatically adapts only to changes in maximum worker count. Kubernetes Cluster Autoscaler, with its manually-configured node groups, is an example of a dynamic fixed-sized configuration system.
| Configuration |
Automatically adapts to TorchServe max worker count needed changes |
Automatically adapts to TorchServe worker size changes |
Automatically handles cloud instance availability & offerings changes |
| Max-sized |
no |
no |
no |
| Dynamic fixed-size |
yes |
no |
no |
| Right-sized |
yes |
yes |
yes |
Table 5: Operational complexity comparison for inference resource management experiments
The need to track changes in cloud instance offerings is illustrated by the use in the max-sized and dynamic fixed-size configurations of VM.GPU2.1. OCI indicates VM.GPU2.1 (Nvidia P100 at $1.275/hr) is a previous generation GPU shape with limited availability and that the VM.GPU3.1 (Nvidia V100 at $2.950/hr) is a current generation shape. When VM.GPU2.1 becomes unobtainable, the max-sized and dynamic fixed-size configurations need manual update, whereas Luna automatically uses the least expensive shape that’s obtainable.
Conclusion
We have shown that the approach of right-sizing inference resources using Elotl Luna and right-sizing inference Compute shapes using OCI Ampere A1 Arm with the Ampere Optimized AI library reduced cloud resource costs by nearly two orders of magnitude in four measured scenarios versus two non-right-sized configurations, while also reducing the operational complexity of tracking model serving resource needs and cloud offerings and costs.
As a further consideration, the K8s cluster that hosts deep learning serving workloads might be one of a set of K8s clusters formed for different purposes. For example, you can have a separate K8s cluster comprising GPU nodes that hosts deep learning training workloads. You can use Elotl Nova, a K8s service that handles K8s cluster selection, to place K8s workloads into the appropriate cluster. You can also use Luna and Nova together to simplify K8s resource management.
The work in this blog utilizes several highly effective cloud and cloud native components. We want to thank the fantastic teams at Elotl and Ampere AI for creating and maintaining respectively Elotl Luna and Ampere A1 Arm with the Ampere Optimized AI library, which are critical technologies for performing efficient deep learning inference at scale.
We invite you to try right-sized resources using Elotl Luna on OCI OKE together with right-sized compute shapes using Oracle Cloud Infrastructure Ampere A1 Arm-based compute with the Ampere Optimized AI on your workloads.
To get started, see the following resources:
