We’re excited to announce the launch of Oracle Cloud Infrastructure GM4 instance powered by the NVIDIA A100 80GB Tensor Core GPU. This new shape continues to fuel the explosive growth in large AI model training and inferencing by combining it with OCI’s high-throughput, ultra-low latency RDMA cluster networking which allows customers to create large scale clusters of NVIDIA A100 GPUs.
Upping the ante
Offered on bare metal, the OCI GM4 instance features the NVIDIA HGX A100 board with eight A100 Tensor Core GPUs and 80G of high bandwidth memory each, all interconnected by NVIDIA NVLink at 600 GB/s. The instance also features 128 physical cores of the AMD EPYC Milan processor with a 2.55Ghz base frequency and 3.5Ghz max boost frequency, 2 TB of system RAM and 27.2 TB of local NVMe storage to support model checkpointing and fast storage access.
With our simple, global pricing of $4.00 per GPU per hour, customers can expect to see better performance and price-performance compared to our previous A100 40GB based instances, especially for large models that don’t fit into the memory of a single GPU. This new instance offers the following advantages over the previous generation:
-
Up to three-times higher AI training performance for large language models (LLMs), deep learning recommendation models (DLRMs), and computer vision (CV) workloads
-
Up to 1.25-times higher AI inference performance for workloads, such as real-time conversational AI, manufacturing inspection, and autonomous driving
-
Up to 1.8-time higher performance on scientific HPC applications
The following table compares the technical specification and pricing of the A100 40GB and A100 80GB GPU instances.
| BM.GPU4.8 | BM.GPU.GM4.8 | |
|---|---|---|
| GPU memory | Eight GPUs, 40 GB each | Eight GPUs, 80 GB each |
| GPU memory bandwidth | Eight 1.6TB/s | Eight 2 TB/s |
| CPU | Two 32c AMD EPYC Rome | Two 64c AMD EPYC Milan |
| System memory | 2 TB DDR4 |
|
| Storage | Four 6.8 TB NVMe SSDs | |
| Cluster NIC | Eight 2 x 100 Gbps NICs | |
| Price (per GPU/hour) | $3.05 | $4.00 |
Scale out performance
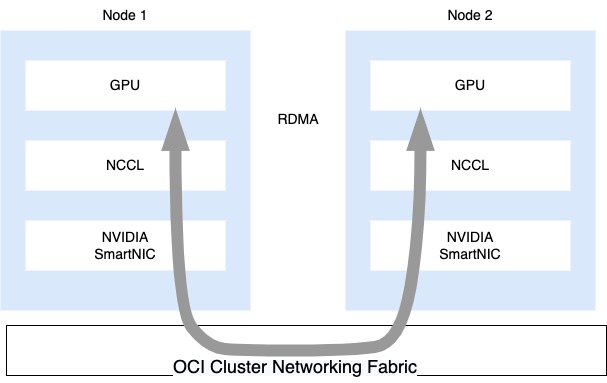
For customers seeking to train models with billions of parameters like GPT3 and Megatron 530-B, each BM.GPU.GM4.8 node is integrated into the high-throughput, ultra-low latency RDMA cluster network architecture that features eight 2 x 100 Gbps NVIDIA ConnectX SmartNICs connected through our high-performance non-blocking network, resulting in 1,600 Gbps of bandwidth between the GPU instances. This enables customers today to train the largest models by creating large clusters of NVIDIA A100 GPUs.
Starting in 2023 customers will be able to scale the NVIDIA A100 GPU on our RDMA cluster networking up to 32K GPUs to take on the next generation of foundation models.
Adept builds a powerful AI training model with OCI and NVIDIA
Machine learning research and product lab Adept is using OCI and NVIDIA technology to develop a universal AI teammate capable of performing a range of tasks people run on their computer or on the internet. Running on clusters of NVIDIA A100 80GB GPUs, and taking advantage of OCI’s high network bandwidth, Adept can train large-scale artificial intelligence (AI) and machine learning (ML) models faster and more economically than before. As a result, Adept has been able to rapidly advance its general intelligence roadmap and develop its first product: a rich language interface that enables the tools knowledge workers use every day to be productive and creative.

Getting started
The addition of the NVIDIA A100 80GB GPU complements the existing line up of available NVIDIA GPUs on OCI including the just announced A10 GPU, opening a new era of accelerated computing for startups, enterprises, and governments around world on OCI. Not all workloads are the same, and some may require customization to work optimally on the latest generation GPU hardware. OCI offers technical support to get your workload up and running, so talk to your sales contact for more information.
For more information about BM.GPU.GM4.8 instances including specifications, pricing, and availability, see our documentation. To learn more about Oracle Cloud Infrastructure’s capabilities, explore the following resources:
