In our previous blog posts, we discussed the performance of Oracle Cloud Infrastructure (OCI) Compute with AMD Instinct MI300X for serving Meta’s Llama large language model (LLM). We also discussed performance numbers and maturity of AMD’s ROCm software stack for LLM serving. Building on our previous testing, in this blog, we focus on the fine-tuning scenario with the Llama LLM, specifically Llama 3 70B, on a single OCI Compute bare metal instance with AMD MI300X. The details from this experiment help readers glean into the performance characteristics of AMD MI300X GPUs on OCI Compute bare metal instances.
The BM.GPU.MI300X.8 instance comes with eight MI300X GPU accelerators, each with 192 GB of HBM3 memory for a total of 1.53 TB of GPU memory. Memory bandwidth is 5.2 TB/s to quicken tensor computations with fine-tuning. Bare metal hardware, unique to OCI, eliminates the overhead of a virtualization layer between the workload and the underlying hardware. It’s a powerful hardware well suited for LLM inference as well as LLM fine-tuning and training experiments. Don’t take our word for it—use the Try-Before-You-Buy-Program to get access to BM.GPU.MI300X.8 today.
Fine-tuning and LoRA
Fine-tuning takes a pretrained foundation LLM model and trains it further on a specific task or dataset to improve its performance on specific tasks and domains. It’s an efficient way to bring your business data context into an LLM model that reduces the computational power, time, and training data needed than starting from scratch. Models usually reach optimal performance quicker with finetuning as they get a warm start from the existing trained model.
Low-rank adaptation (LoRA) has emerged as a powerful technique for efficiently fine-tuning LLMs. We explore an implementation of LoRA fine-tuning for LLAMA 3 70B on the tau/scrolls (govt_record) dataset. For more information on LoRa, see What is low-rank adaptation (LoRA).
LoRA Configuration
The following steps outline how we set up LoRA:
peft_config = LoraConfig(
lora_alpha=32,
lora_dropout=0.05,
r=8,
bias="none",
target_modules="all-linear",
task_type="CAUSAL_LM",
)
This configuration sets up LoRA with a rank of 8 (r=8) and applies that to all linear layers in the target module. We applied it to all linear layers with (target_modules= “all-linear”). The lora_alpha parameter scales the LoRA update, and lora_dropout add regularization. By choosing a rank value of 8, we reduce the number of trainable parameters, reducing the memory footprint. The all-linear method is the best for comprehensive fine-tuning for diverse downstream tasks or broader experimentation with neural networks whose most impactful layers are not clear. For efficiency focused fine-tuning, we target specific modules like “self_attn.q_proj,” “self_attn.v_proj,” or “mlp.”
Flash attention and gradient checkpoint optimizations further enhance training efficiency. Flash attention reduces memory usage and increases computational efficiency for the attention mechanism. Gradient checkpointing recomputes activations during backpropagation, trading-off more memory usage for increased computation. We implement them with the following command:
model = AutoModelForCausalLM.from_pretrained(
script_args.model_id,
attn_implementation="flash_attention_2",
torch_dtype=quant_storage_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
Performance Results
The BM.GPU.MI300X.8 instance has large memory capacity. Training speed and loss metrics help evaluate how efficiently the model uses the machines’ memory, as shown in the following table.
• training_runtime: total training time
• training_samples_per_second: number of samples processed per second
• train_steps_per_second: number of training steps completed per second
• train_loss: how well the model is converging
Results obtained with one epoch show total training time of 29,236.4 seconds and training loss of 1.583.
| Name | Value |
| epoch | 1 |
| eval_loss | 1.506 |
| eval_runtime | 879.2 |
| eval_samples_per_second | 5.375 |
| eval_steps_per_second | 0.672 |
| grad_norm | 0.353 |
| learning_rate | 1.000e-5 |
| loss | 1.53 |
| total_flos | 9,224,442,995,539,968,000 |
| train_loss | 1.583 |
| train_runtime | 29,236.4 |
| train_samples_per_second | 2.996 |
| train_steps_per_second | 0.187 |
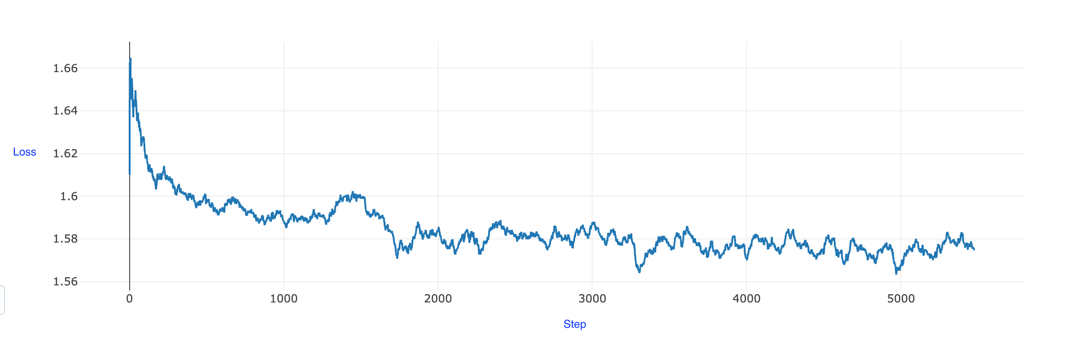
The graph shows training loss that starts at approximately 1.66 gradually decreases over 5,000 steps, stabilizing at around 1.58. The loss values show minor fluctuations, while maintaining a general downward trend, suggesting steady but incremental improvements in the model’s performance. Consider the following metrics of importance:
Training speed versus steps per second
- train_samples_per_second (A) = 2.996
- train_steps_per_second (B) = 0.187
- samples per step = A/B = 16.021
Compute efficiency: Total TFLOPs = 9.22 x 10^6
Data processing rate:
- Total samples processed = 2.996 x 29,236.4 = 87,592 samples
- Total steps = 0.187 x 29,236.6 = 5,467 steps
Conclusion
For enterprises looking to utilize LLMs for various tasks, these findings suggest that BM.GPU.MI300X.8 can efficiently handle customization of pretrained models for domain-specific tasks. The results show that the instance has potential for scaling to larger models, larger datasets, larger batch sizes and more epochs.
The fine-tuning performance metrics show the efficiency and capability of this instance to handle complex machine learning tasks with train_samples_per_second of 2.996 and eval_samples_per_second of 5.375, which add up to approximately 19 TB of data processed per minute running through one full training cycle (epoch).
The total TFLOPS of 9.22 x 10^6 highlight the instance’s capacity to handle tensor operations efficiently. These results demonstrate that the bare metal compute from OCI and high-memory AMD MI300X GPUs can provide a balance in processing speed, memory management, and price for fine-tuning LLMs. The success of this experiment also underscores the capability of AMD’s ROCm Software Stack for ML training workloads. Full details of this experiment is available in the public repository on GitHub.
In the next post, we explore the capabilities of BM.GPU.MI300X.8 for a multinode fine-tuning ML experiment. To evaluate AMD MI300X on Oracle Cloud Infrastructure, sign up through the Try-Before-You-Buy-Program.

