Organizations are handling progressively larger volumes of data, encompassing both structured and unstructured formats. In addition to their conventional databases and data warehouses, they frequently establish data lakes. These data lakes use object storage to ensure reliability, versatility, and cost-effectiveness in storing data. However, the use of object storage comes with inherent limitations, particularly concerning security and governance. Misconfigurations can occur easily, and even if object storage is properly secured, you can only implement this security at a bucket level, instead of at the level of individual objects or object types.
So, we’re excited to announce our new Oracle Cloud Infrastructure (OCI) Data Lake service, which provides the best of both worlds: versatility and low cost of object storage with security and governance at object level.
You can set fine-grained access control rules on all resources in a data lake by role. You can set the access rights on any object in object storage by bucket, object, or field, using standard SQL data definition language.
Simplify data sharing
OCI Data Lake makes it easy to store and govern your data with unified access control. You can query the data from OCI Big Data, Data Flow, Autonomous Data Warehouse, Data Integration service, and Data Science services with a central permissions model.
When you have set the access policies for assets in OCI Data Lake, they’re enforced for all tools and services with access. Instead of managing access for each of the tools and services individually, this unified solution saves time and reduces errors.
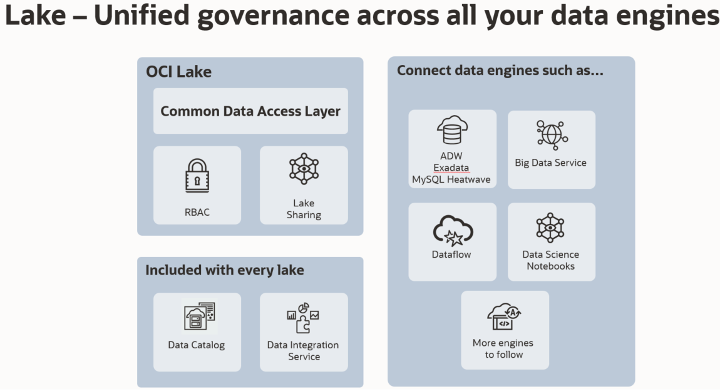
Figure 1: OCI Data Lake as part of your analytical solution
Most users of a database must also work with unstructured and semistructured data. OCI Data Lake makes it easy to connect the lake as a resource to an Autonomous Database instance.
Unify access control
Using OCI Data Lake has two parts: creating roles and assigning permissions to those roles. You can use role creation to mimic your enterprise, creating for instance, a datascienceuser role, a dataanalyst role, and a financial planner role. You can assign Identity and Access Management (IAM) users as members of these roles. In Figure 3, the data_scientist role members inherit the permissions assigned to data_scientist role.
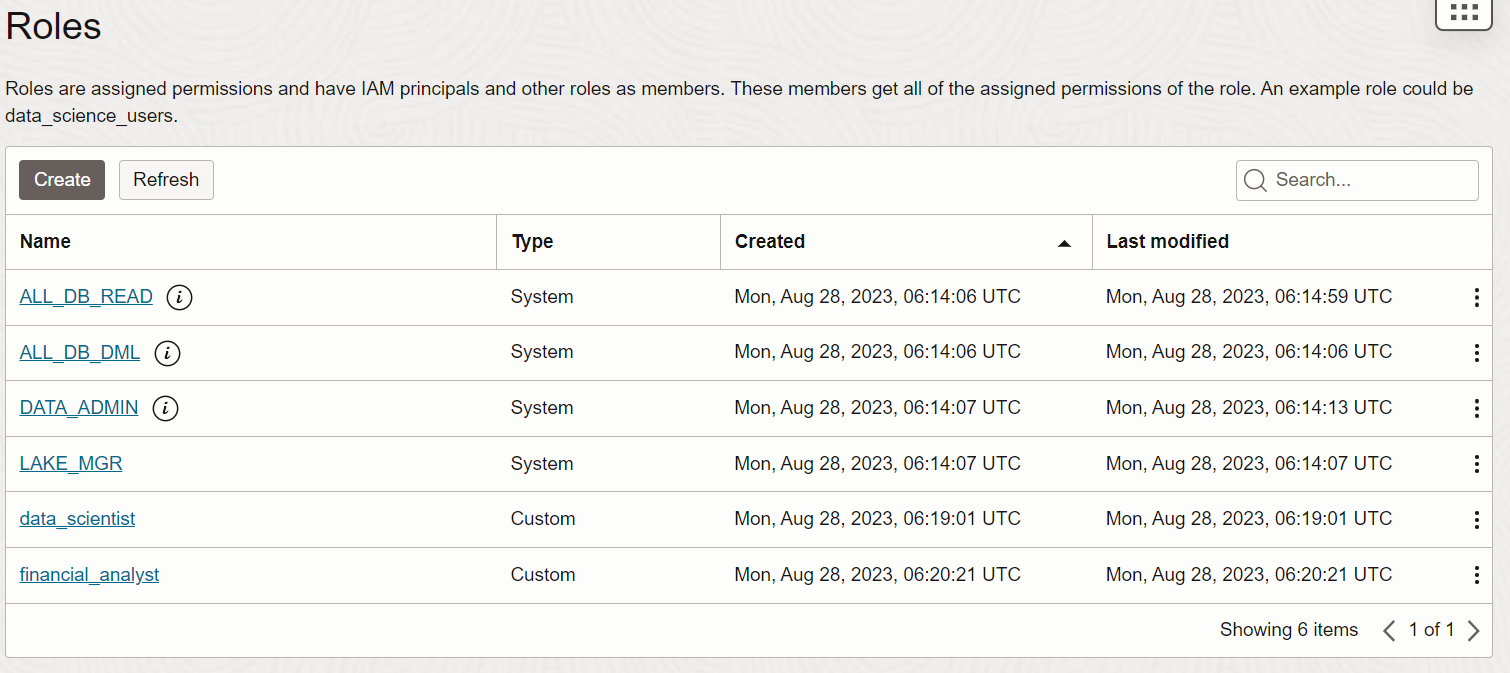
Figure 2: List of roles
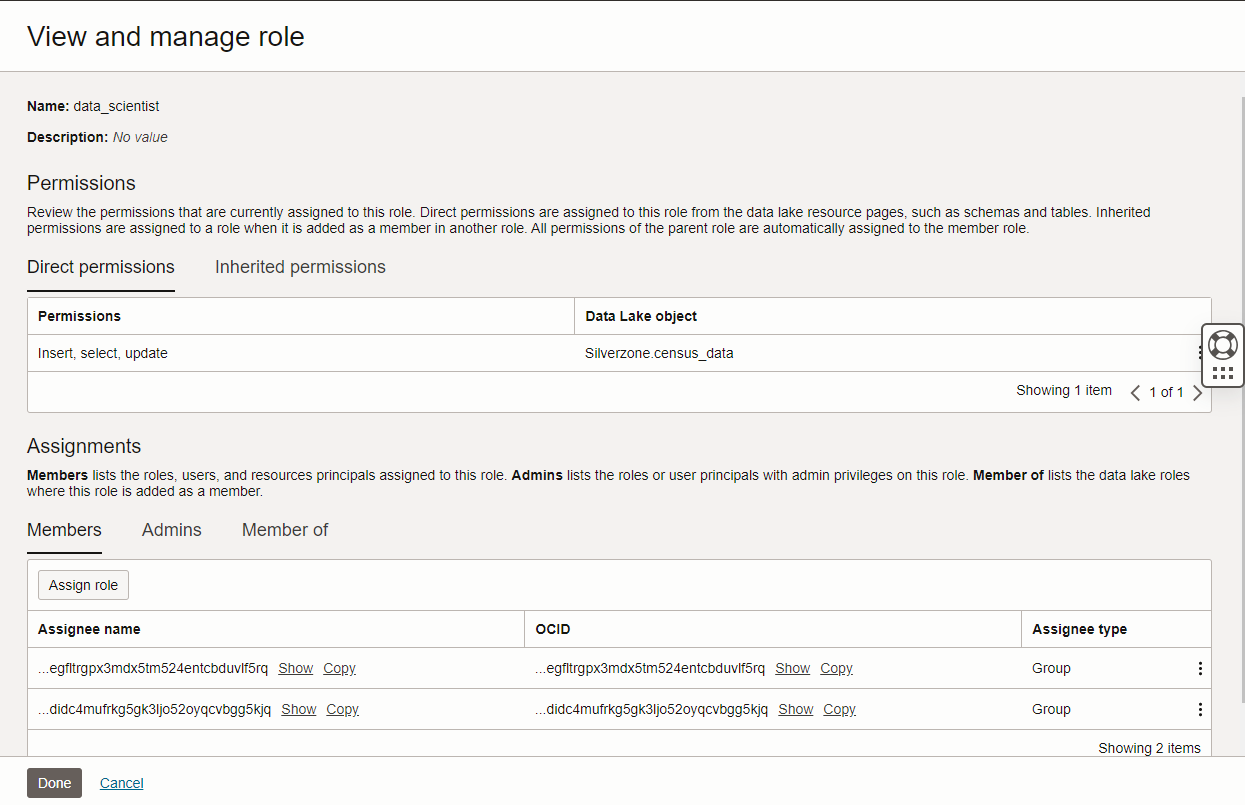
Figure 3: Details of datascience user role
Permissions are just as easy to assign. Permissions use a SQL-like syntax, enabling admins to control a user’s ability to query or edit tables, databases, views, mounts, or files.
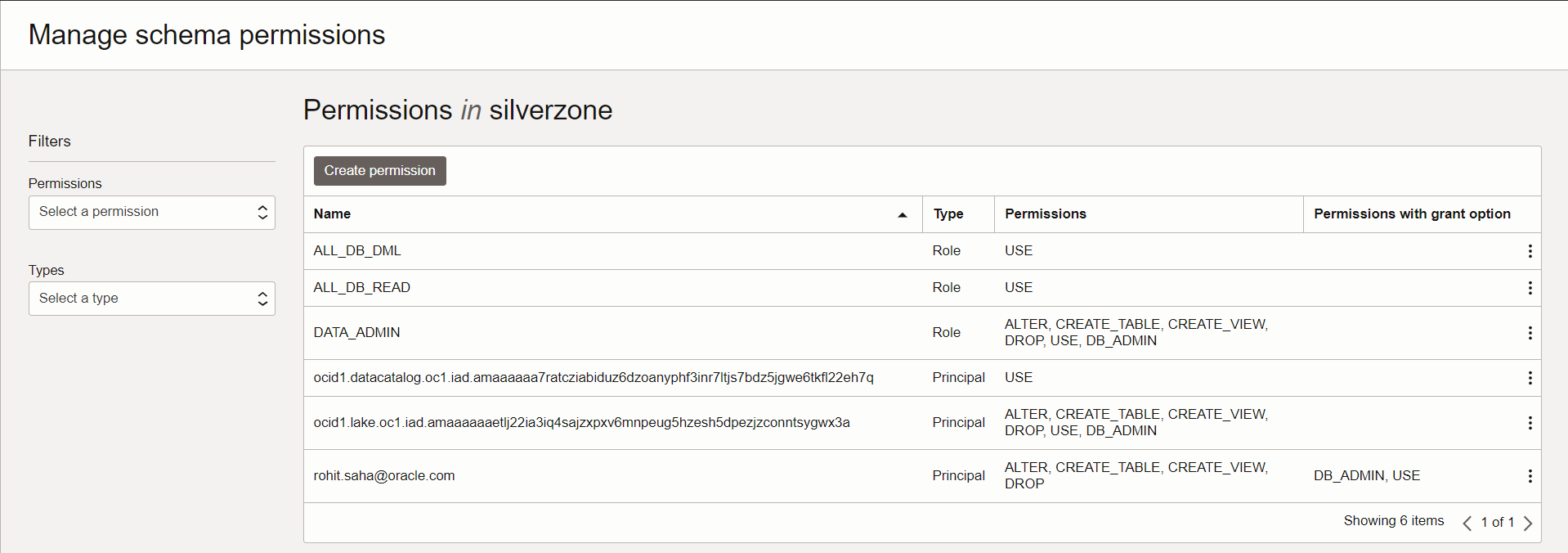
Figure 4: Adding permissions to a table
Fine-grained access control
OCI Data Lake enables you to define fine-grained access control rules, such as who can access a particular column in a table. You can define column-level access control rules like which user has access to a subset of columns. Alternatively, you can also write an access policy using an except list, so that the user has access to all columns except a subset of columns.
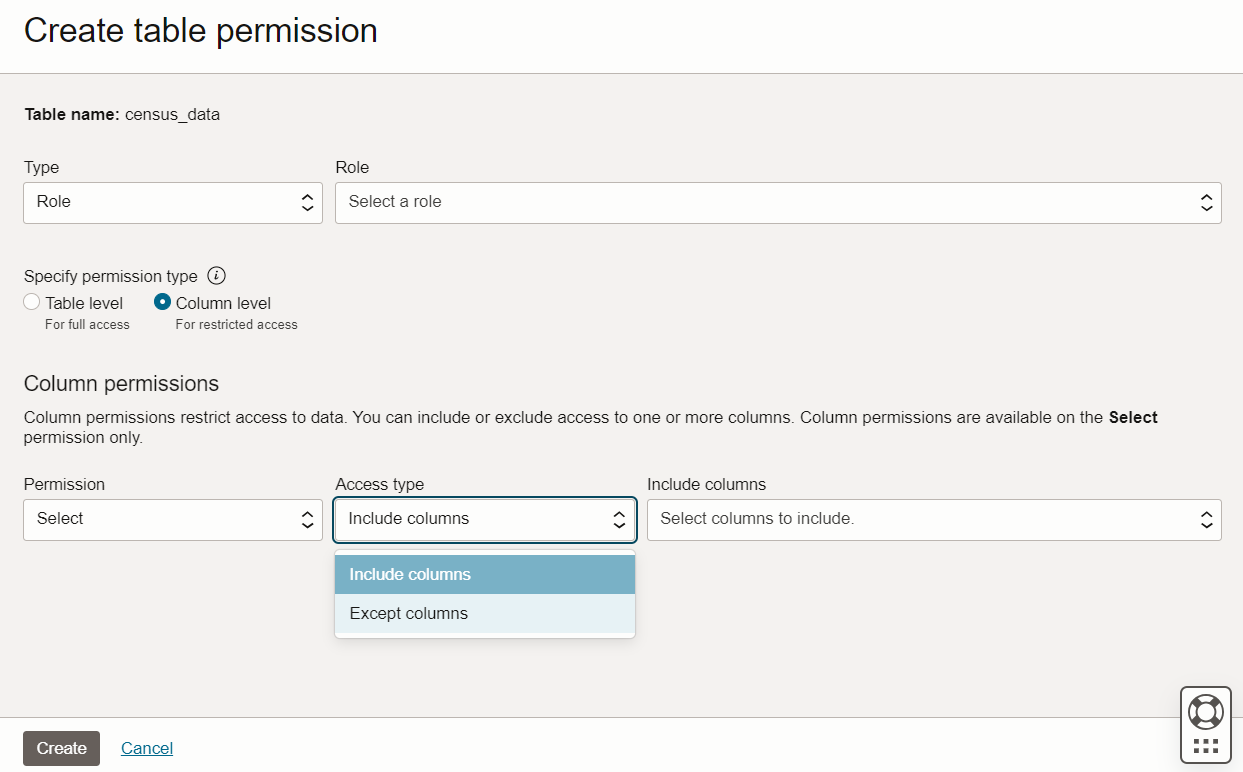
Figure 5: Column level access control
The row level security feature is on the service roadmap.
Integrate with OCI open source managed data services
OCI Data Lake enables you to decouple storage and compute. You can analyze the data stored and governed by OCI Data Lake using the following engines:
-
Ingest data into the lake using a no-code service like OCI Data Integration or using Data Lake APIs or software developer kits (SDKs) in a Spark application.
-
Process and analyze the data using fully managed Spark applications in OCI Data Flow or using Hadoop ecosystem capabilities in a managed Hadoop service with OCI Big Data Service.
-
Use Data Science notebooks to explore the data and build artificial intelligence (AI) and machine learning (ML) models.
-
Interactively query the data using OCI Data Flow SQL Endpoint.
All these engines honor the access control rules defined in the lake.
Store unstructured and semistructured data
With OCI Data Lake, you can store data in both a file and table structure. File structure storage works like any OCI Object Storage bucket. You can create a mount to connect to a bucket or a folder and assign permissions to that mount. With table structure storage, you create virtual databases that can contain many tables and views in OCI Data Lake. These tables and views are built on information stored in the lake in Parquet, Avro, Delta, ORC, csv, and JSON file formats. Creating a table over a file allows users to secure with fine-grained access policies. For example, data scientists can now build models with patient records with the patient names removed.
Support ACID transaction
OCI Data Lake users can create tables using Delta format, bringing support for atomicity, consistency, isolation, and durability (ACID) transactions and time travel capabilities.
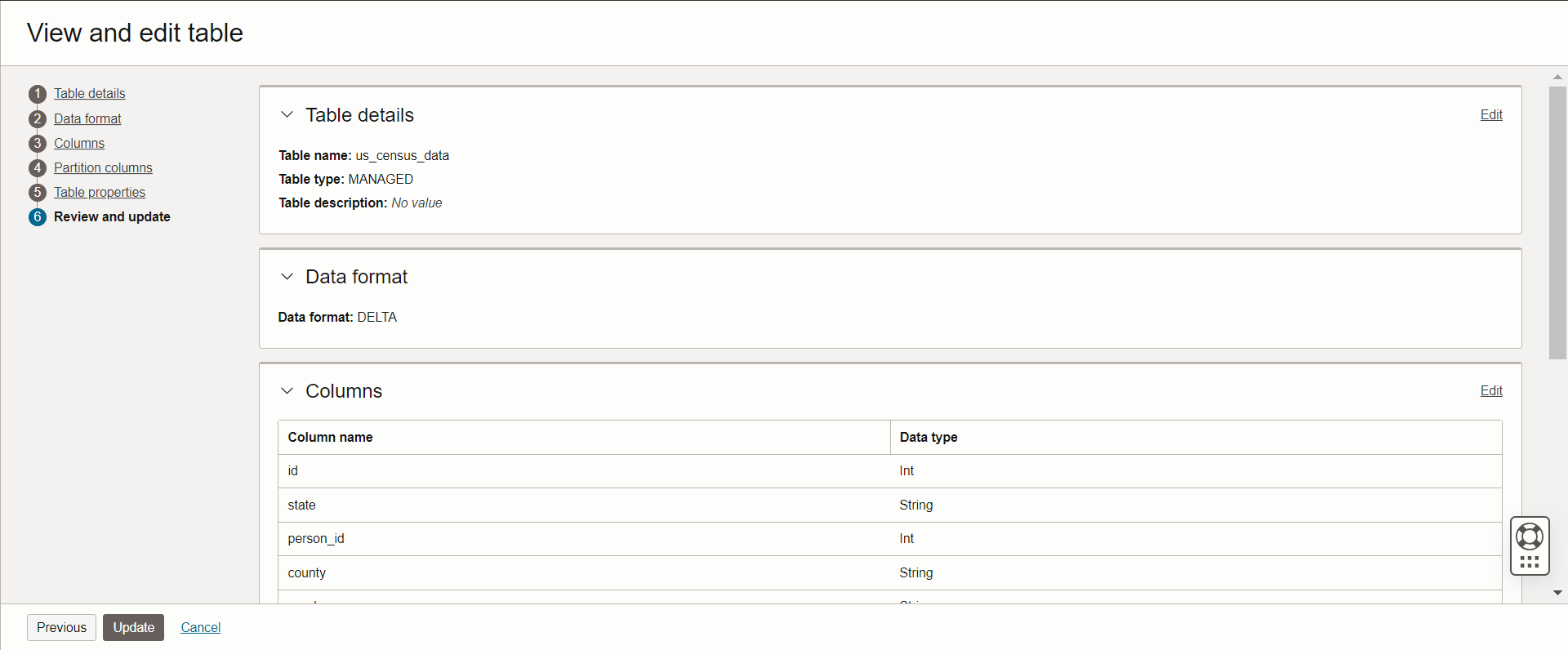
Figure 6: OCI Data Lake supports DELTA format
Early access
Early access is available now with an upcoming global release in 2023. Using and evaluating OCI Data Lake during early access incurs no cost. If you have any questions about Oracle Cloud Infrastructure Data Lake or want to validate your use case, contact us. We look forward to hearing from you.
