We’re thrilled to announce a new release of Oracle Cloud Infrastructure (OCI) Data Integration. This release expands connectivity with the addition of REST as a source, which opens the door to many popular web and cloud companies that use REST APIs for their applications, and support for reading Excel files.
This release also adds new operators, such as the flattening operator and decision operator to help facilitate increased developer productivity. Users that need to process nested JSON or hierarchical data to prepare data for analytics can now use the flattening operator for hierarchical data processing in Data Integration.
Cloud native, serverless Data Integration
As a refresher, OCI Data Integration is a cloud native, fully managed server-less extract, transform, and load (ETL) service on OCI. Organizations building lakehouses for analytics and data science, artificial intelligence and machine learning on OCI with Object Storage, and Autonomous Data warehouses can quickly deliver insights by simplifying, automating, and accelerating the consolidation of data from multiple data silos.
Data Integration provides a graphical, no-code design interface, with interactive data preparation and profiling. It also helps data engineers to design data pipelines using patterns and rules to handle schema evolution. It supports both Spark ETL and ELT push-down processing to the database. If you’re not familiar with this new service, check out the blog, What is Oracle Cloud Infrastructure Data Integration?
Data Integration is available in all OCI commercial regions.
Expanded connectivity
REST as a source
We continue to expand the Data Integration connectivity suite to include a greater variety of data sources. Data Integration users can now extract data using the generic REST data asset type. Using the generic REST data asset, users can ingest data from REST service endpoints with basic authentication. For example, you can now enrich Fusion Application Supply Chain data by extracting weather data from a REST endpoint to create effective models for predictions.
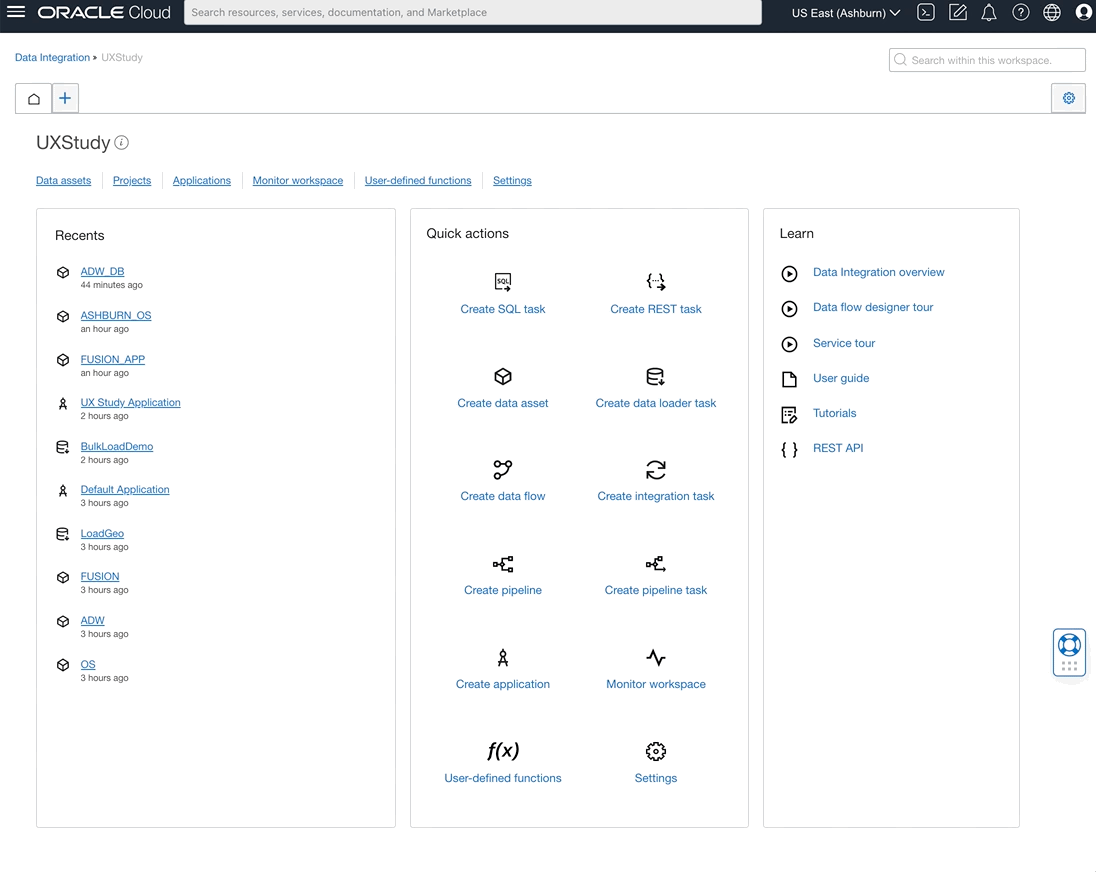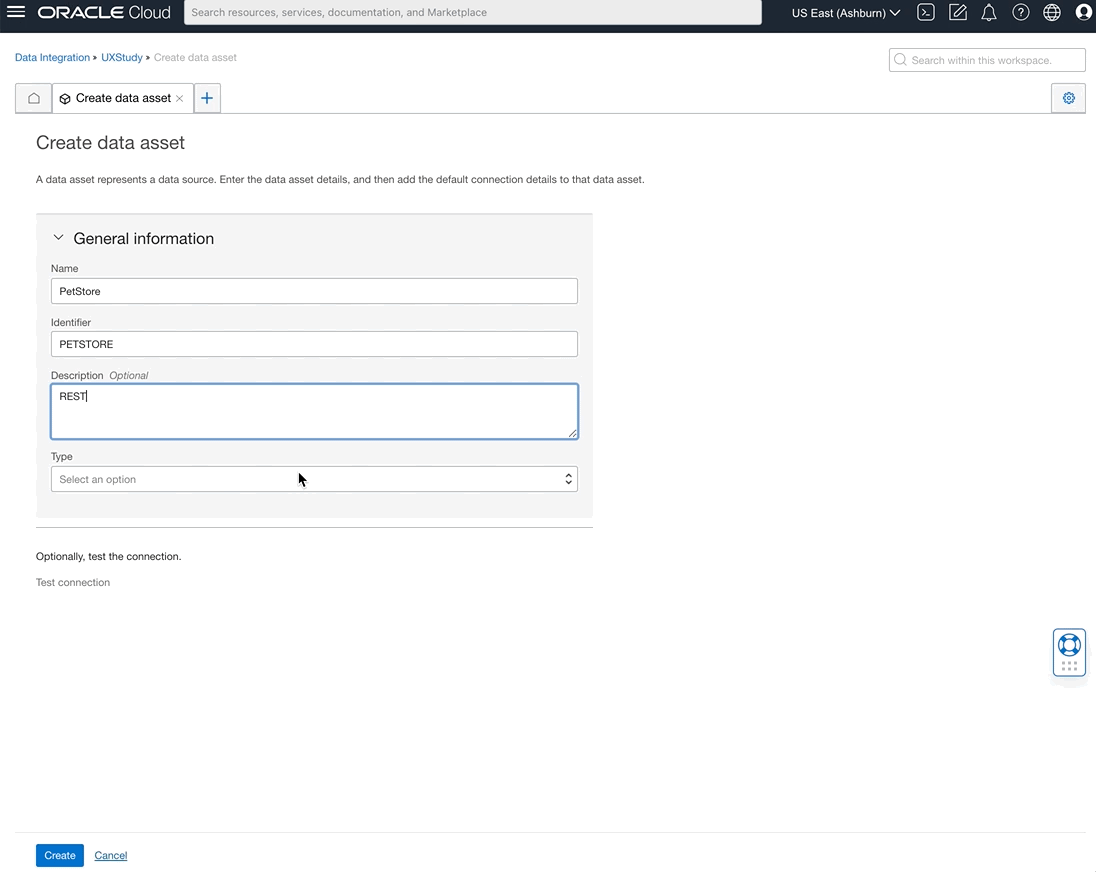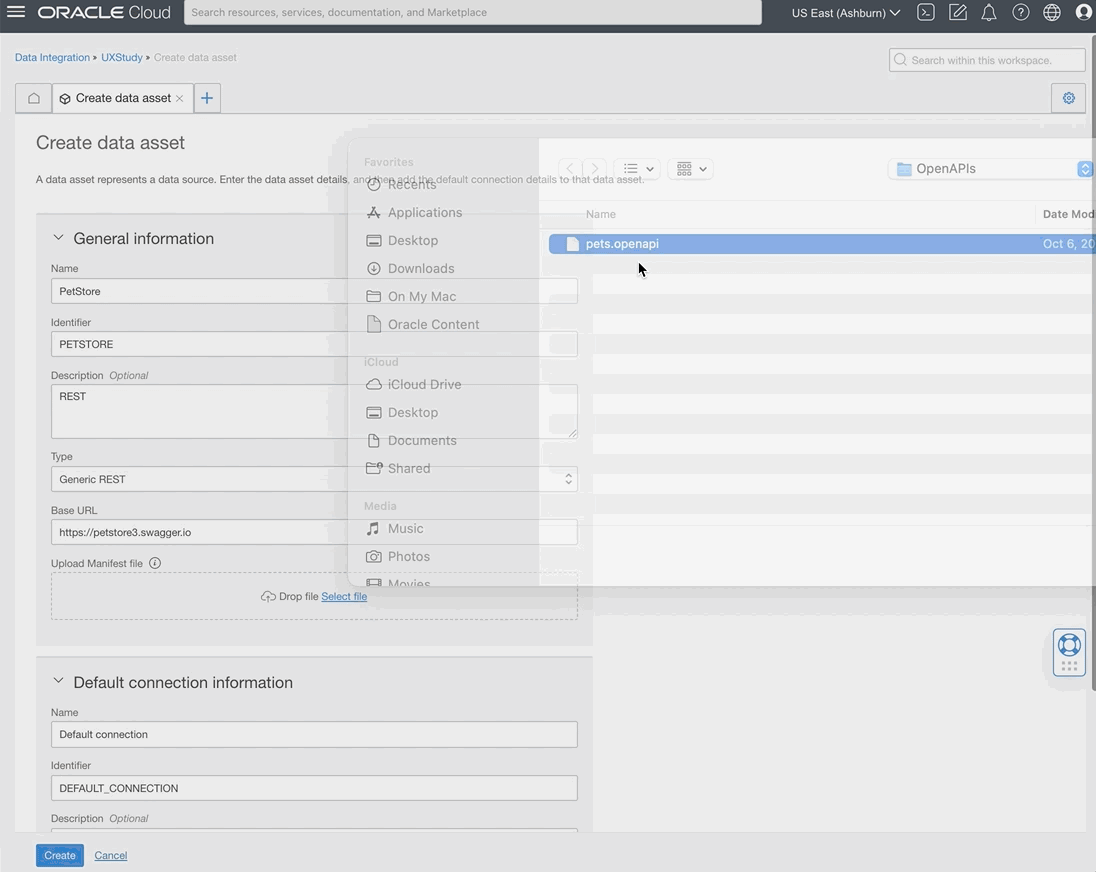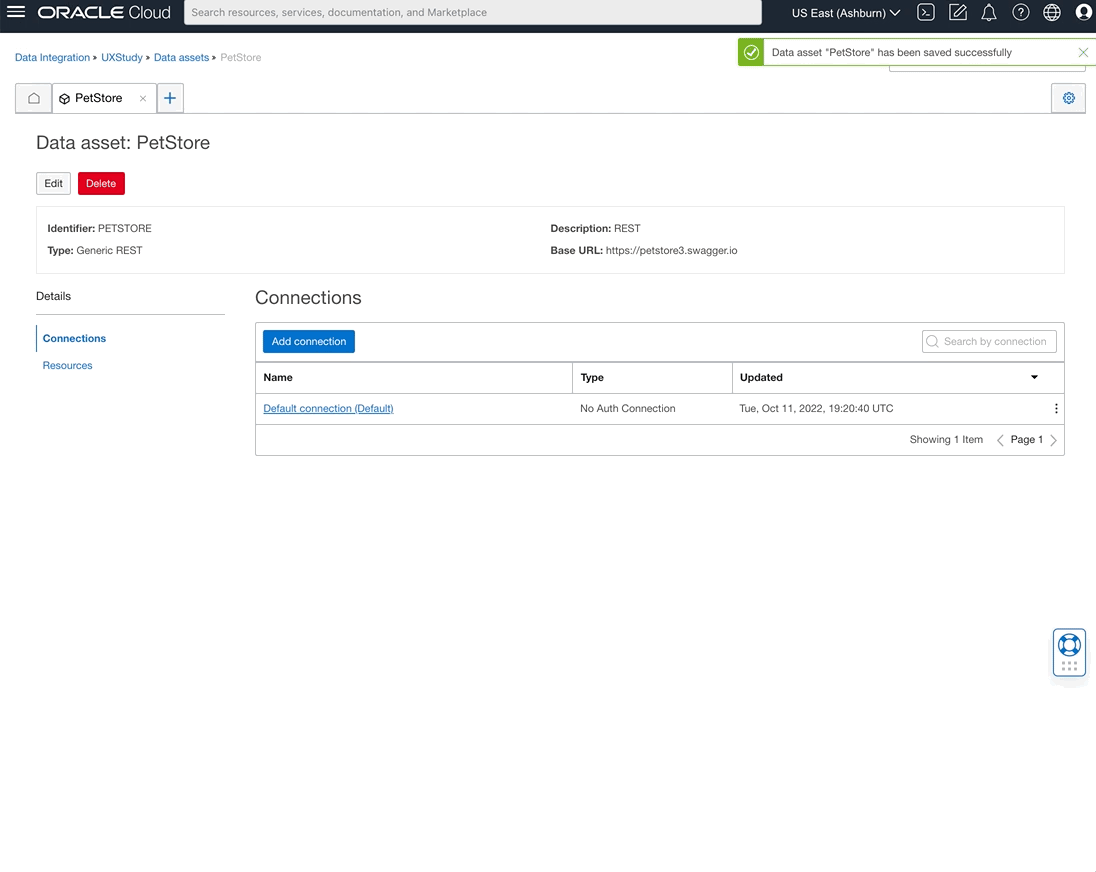
Figure 1: REST as a source
Excel support
We have also added support for xlsx file format (Excel) stored on Oracle Object Storage, Amazon S3, or HDFS. See the complete list of supported data assets.
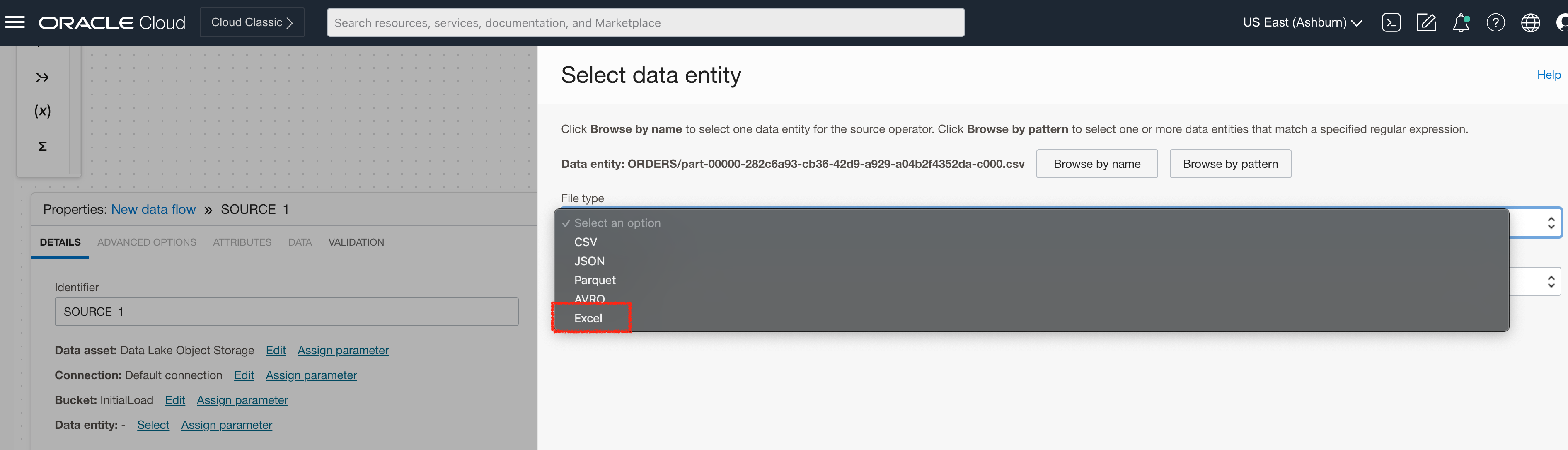
Figure 2: Excel support on OCI Object Storage
Fusion (BICC) enhancement
When ingesting Oracle Fusion Applications using BICC connector, you now have more advanced option while ingesting data. You can now choose to extract only default columns, default and primary columns, or just the primary keys. This functionality help optimize your data flows and data loader tasks when you have many columns in a PVO.
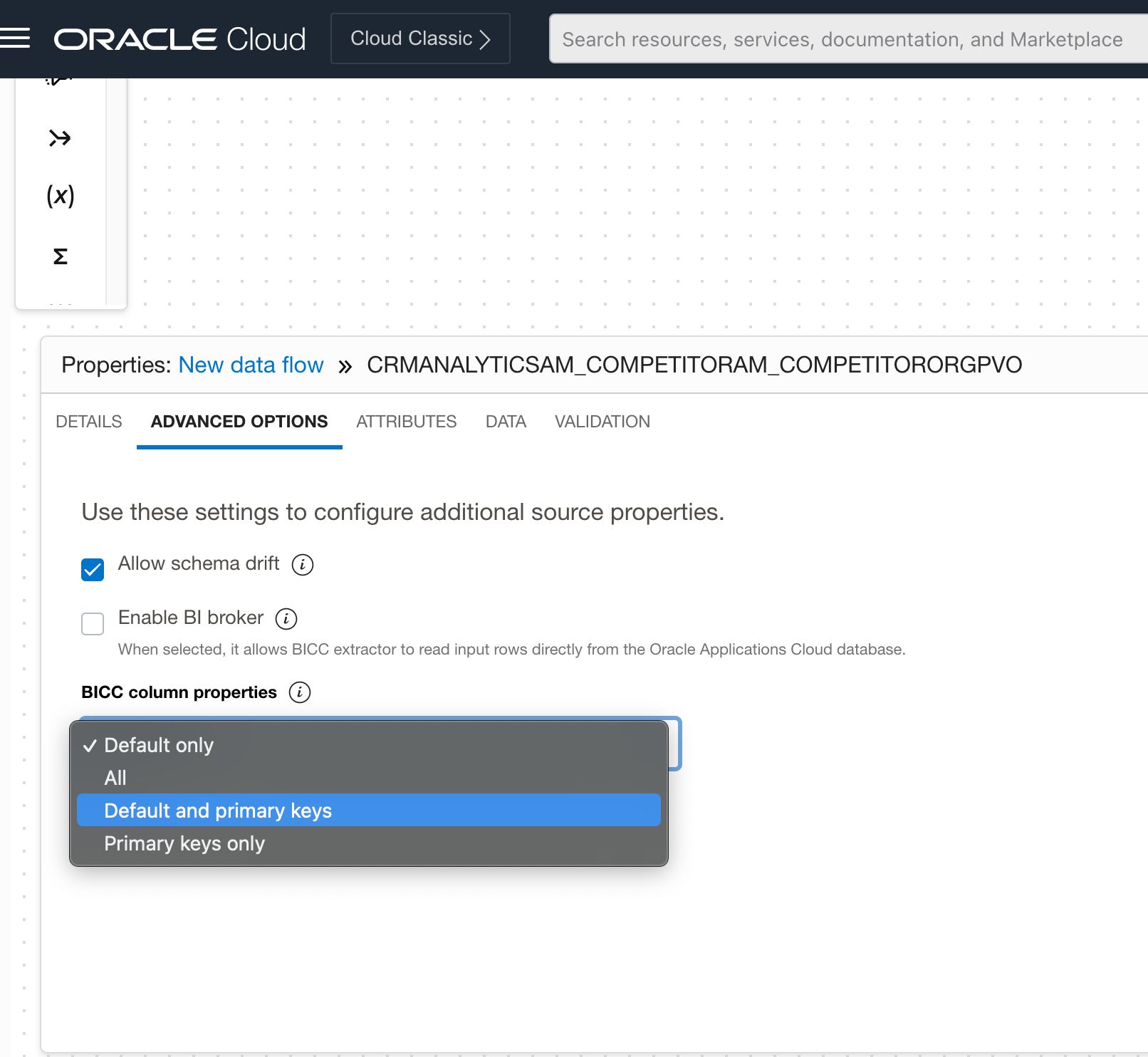
Figure 3: BICC column selector
SSL support
OCI Data Integration now has SSL support for the following sources:
-
Microsoft SQL Server Database
-
Microsoft Azure SQL Database
-
Kafka
-
Apache Hive
-
IBM DB2
More operators for increased developer productivity
Flattening operator in Data Flow
With this release, OCI Data Integration now supports the flattening operator in the data flow, where users can flatten the hierarchical structure like arrays in JSON into a relational format. When the complex data is flattened, you can perform transformations, aggregations, joins, and load into the target.
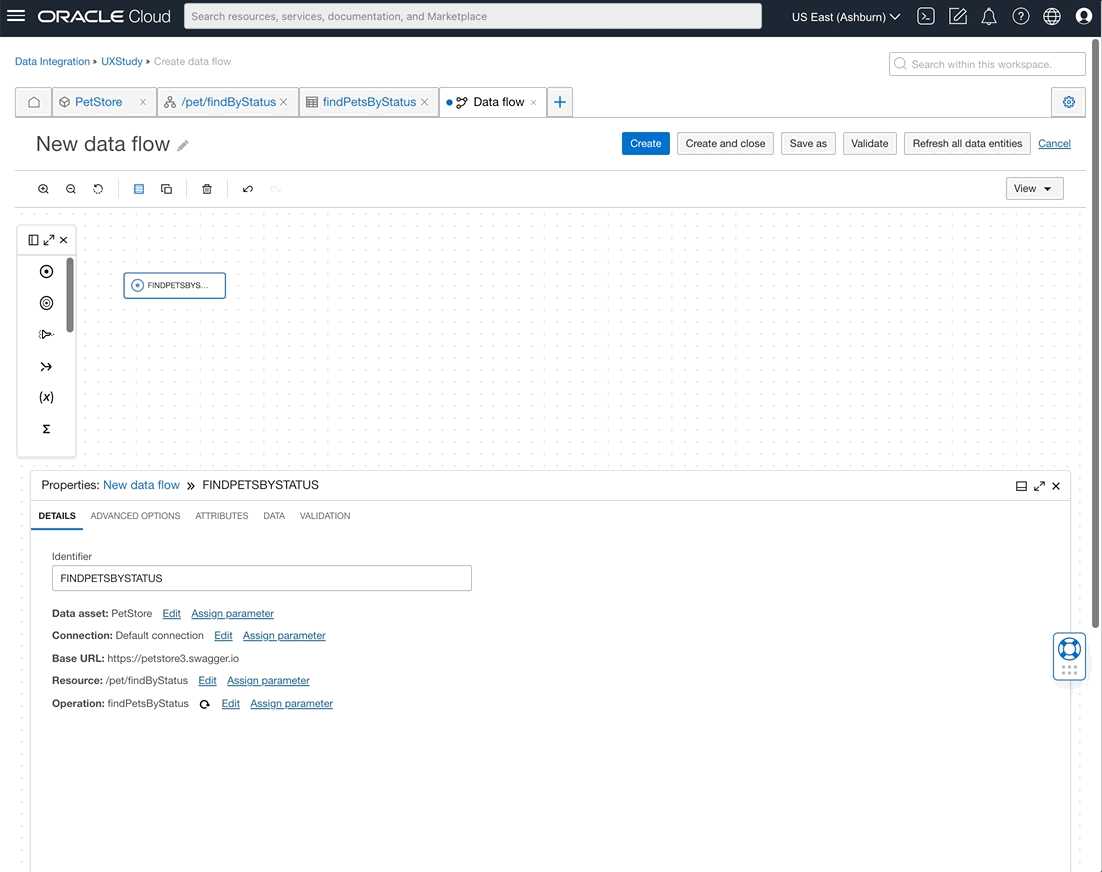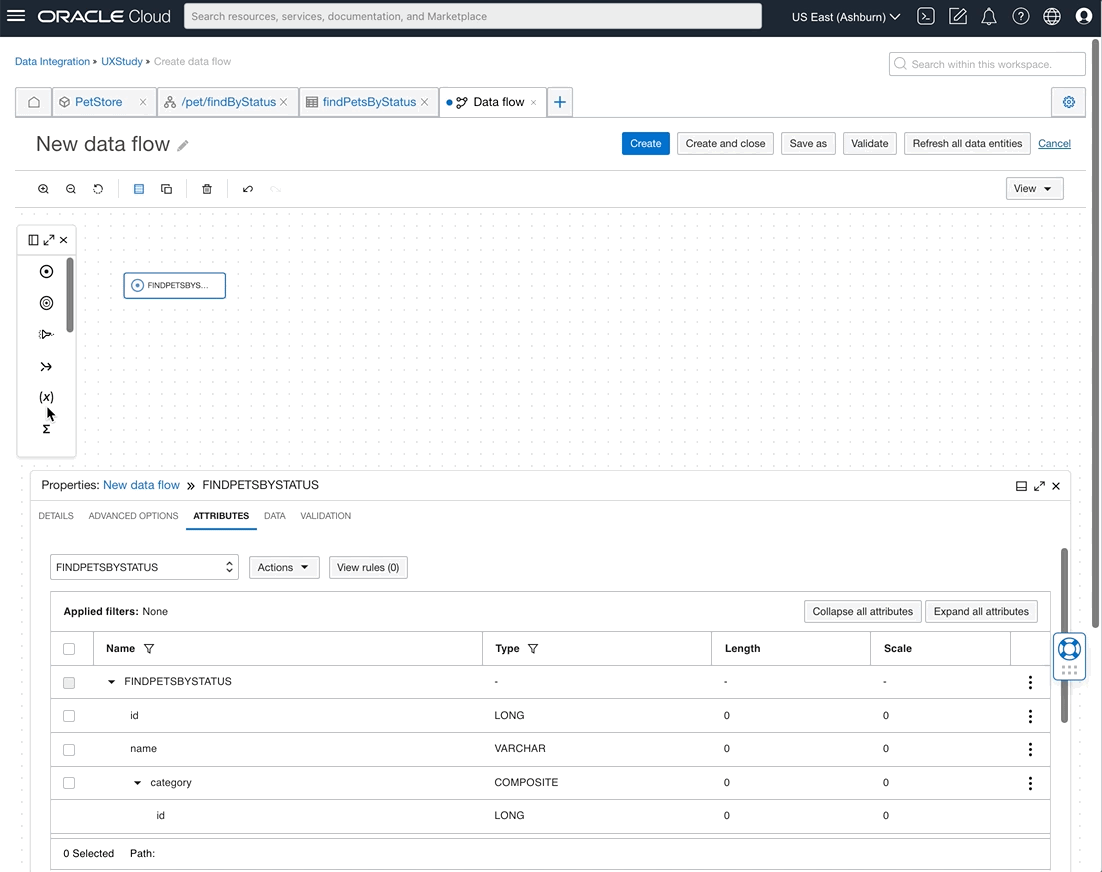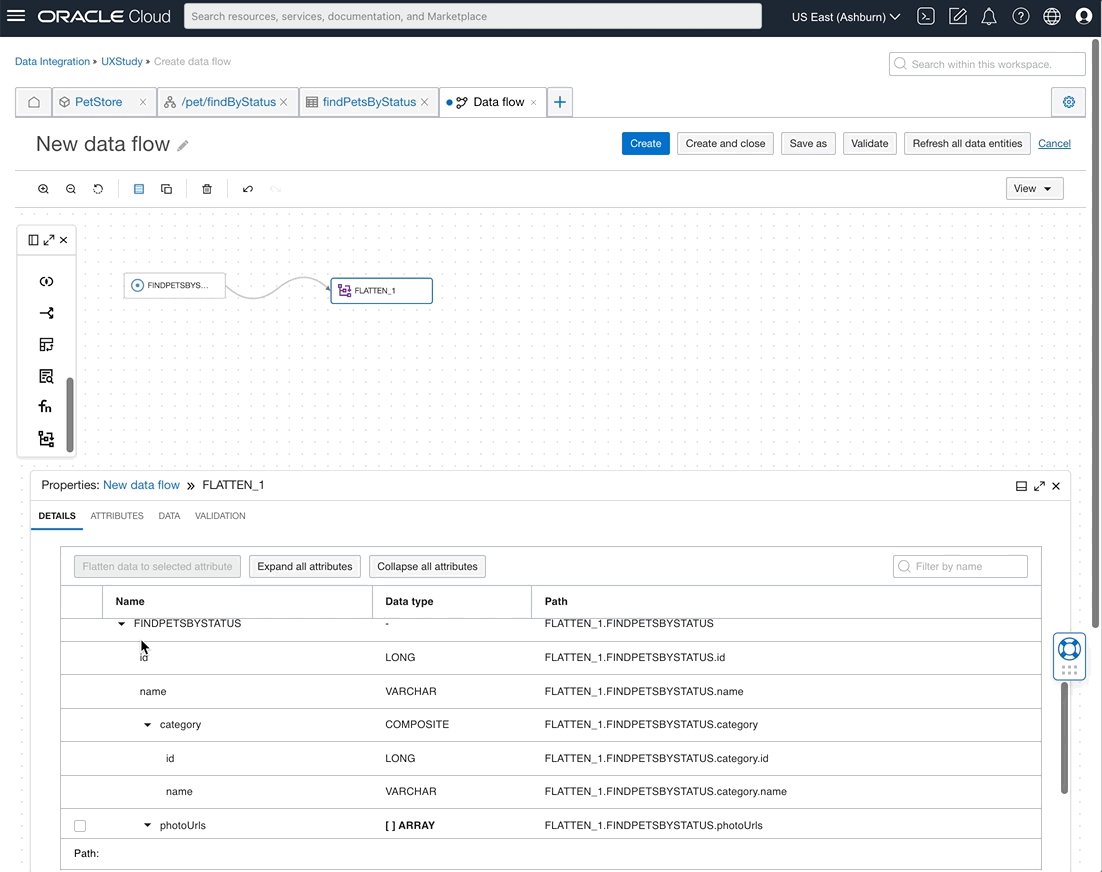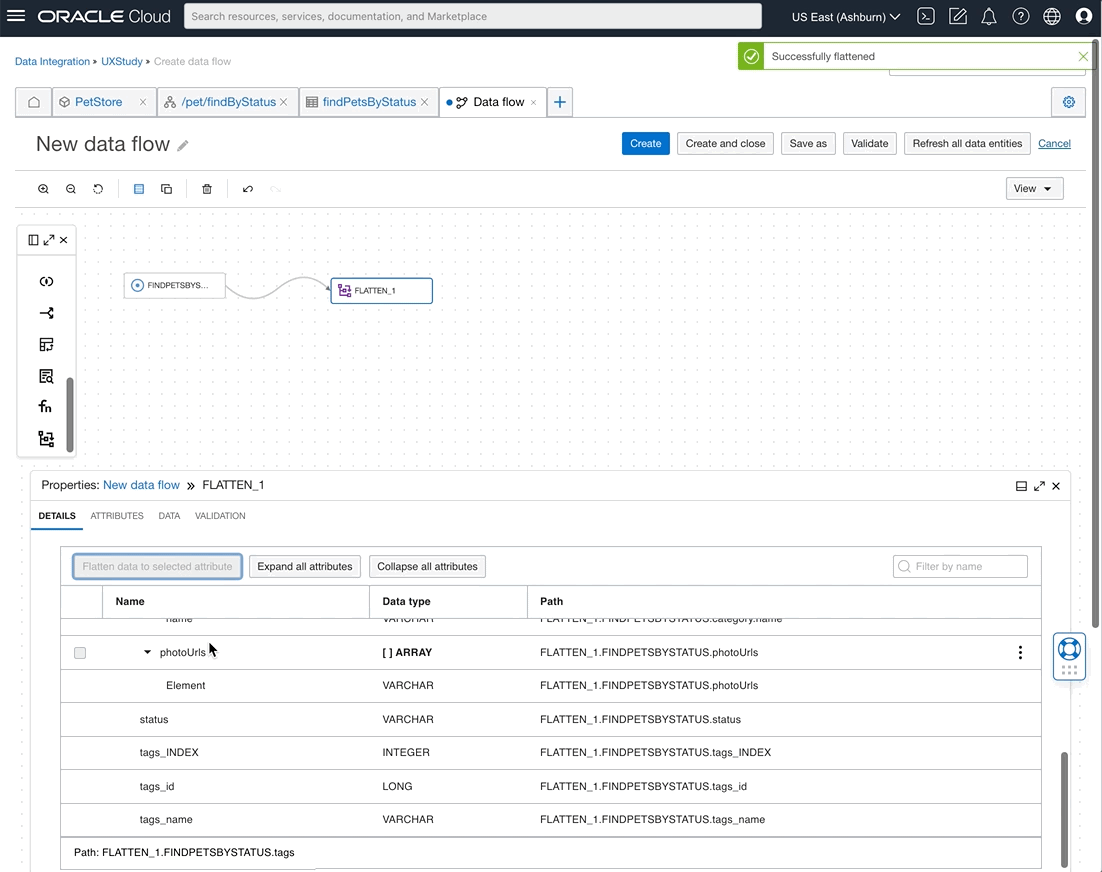
Figure 4: Flattening REST source results
Decision operator in pipeline
The OCI Data Integration pipeline has added a new operator: Decision operator. You can use the decision operator to write a boolean condition that determines the branching flow in the pipeline. This functionality allows you to solve use cases where they want to take decisions based on some condition in the pipeline and determine the execution path of the pipeline. You can write these conditions using preceding task output parameters or system parameters.
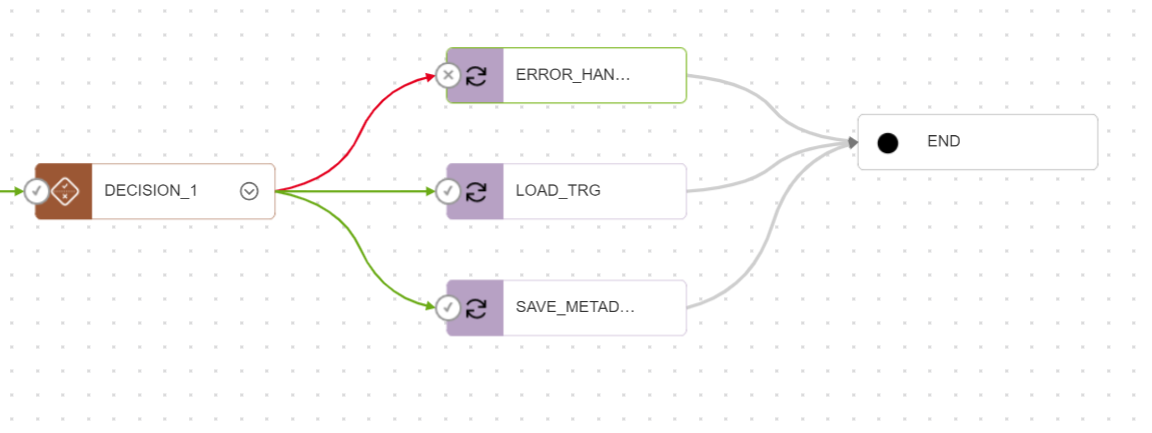
Figure 5: Decision Operator in a data flow
OCI Logging integration
OCI Data Integration now lets you use OCI Logging to enable logging and retrieve service logs in the Console or from the command line interface (CLI). Data Integration service logs are enabled at the workspace resource level using the Data Integration Workspace Logs log category. This functionality helps you debug your pipelines and tasks and enhance your user experience.
Data Loader enhancements
You can now extract data from Oracle Fusion applications using BICC connector in multiple entity load mode. With this capability, you can write data loader task to extract data from multiple Oracle Fusion application PVOs. This feature helps improve the productivity of teams who want to do full data extract from Oracle Fusion Applications for multiple entities.
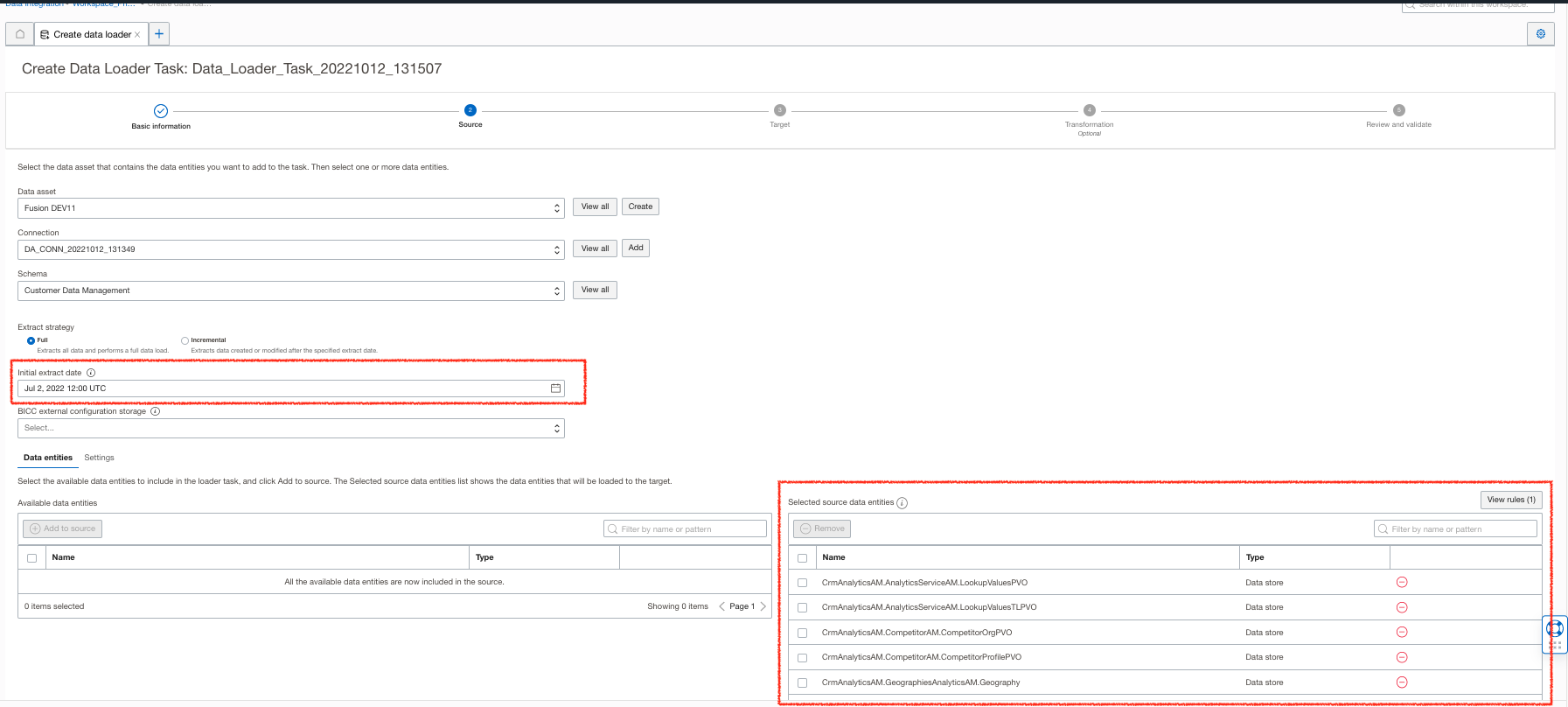
Figure 6: Data loader multiple Fusion entities initial load
You can now also select data entities from OCI File Storage source type by writing rules using either REGEX patterns or logical entity qualifier.
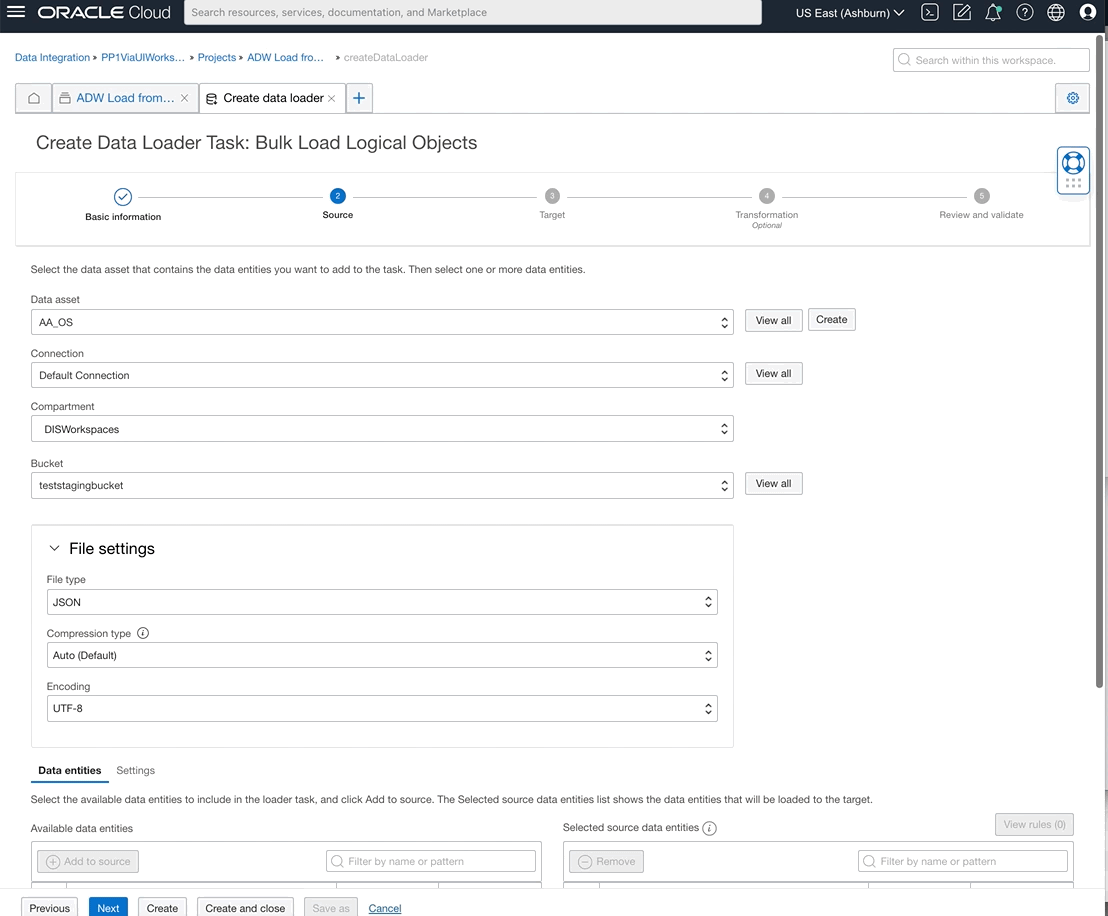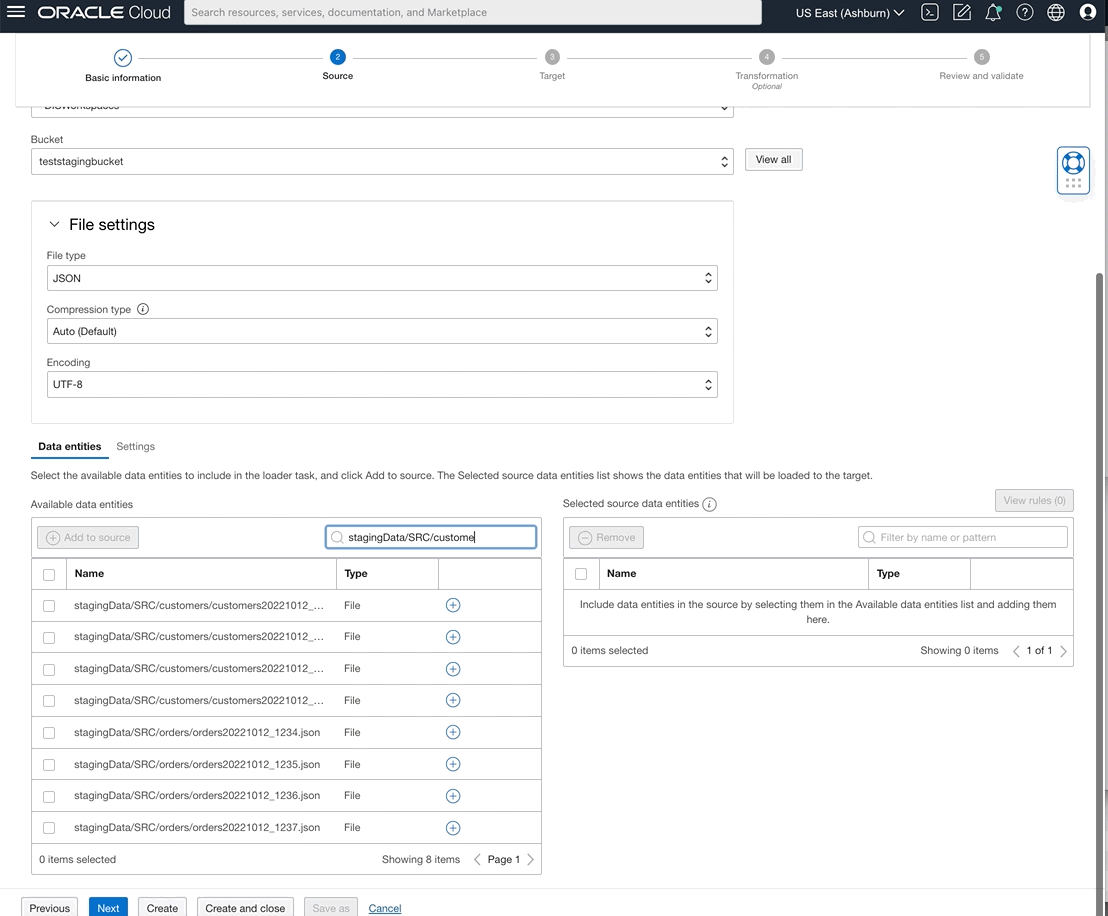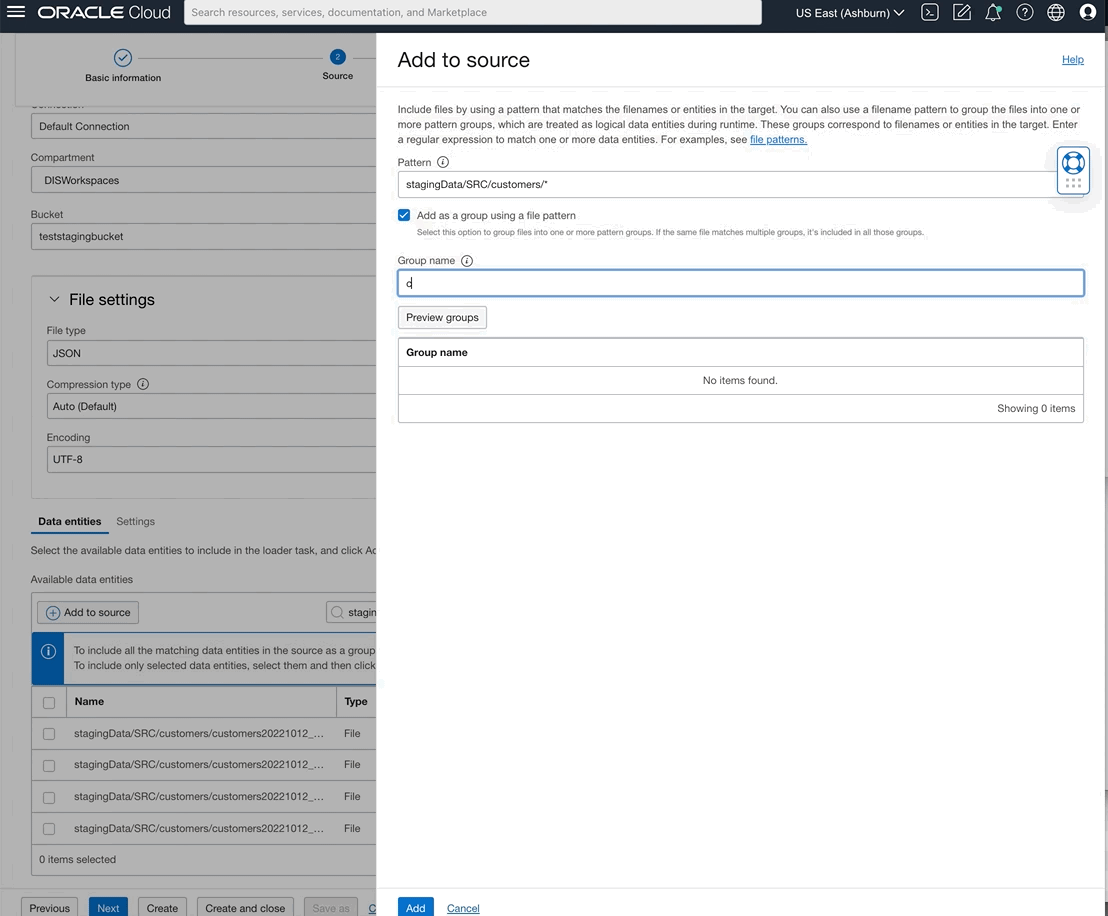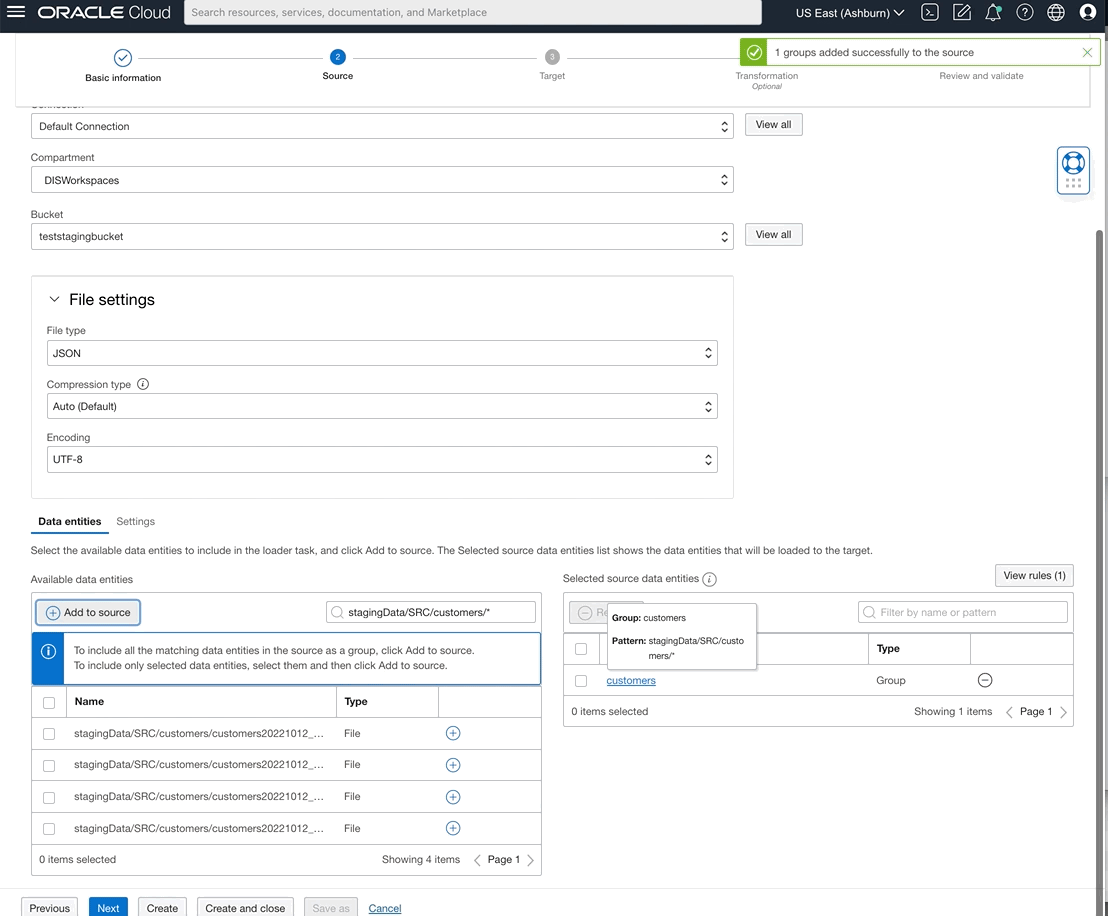
Figure 7: Defining ‘customers’ from many files that represent customers and naming group as ‘customers’
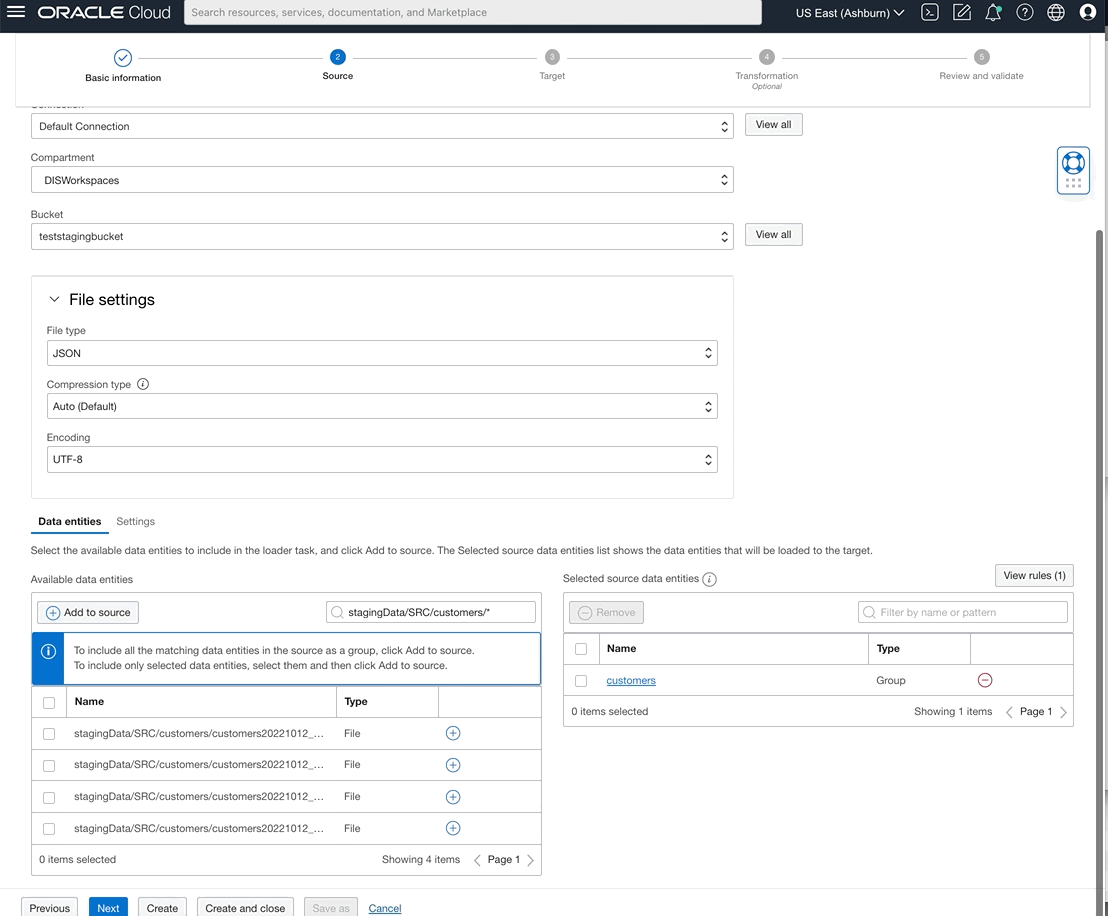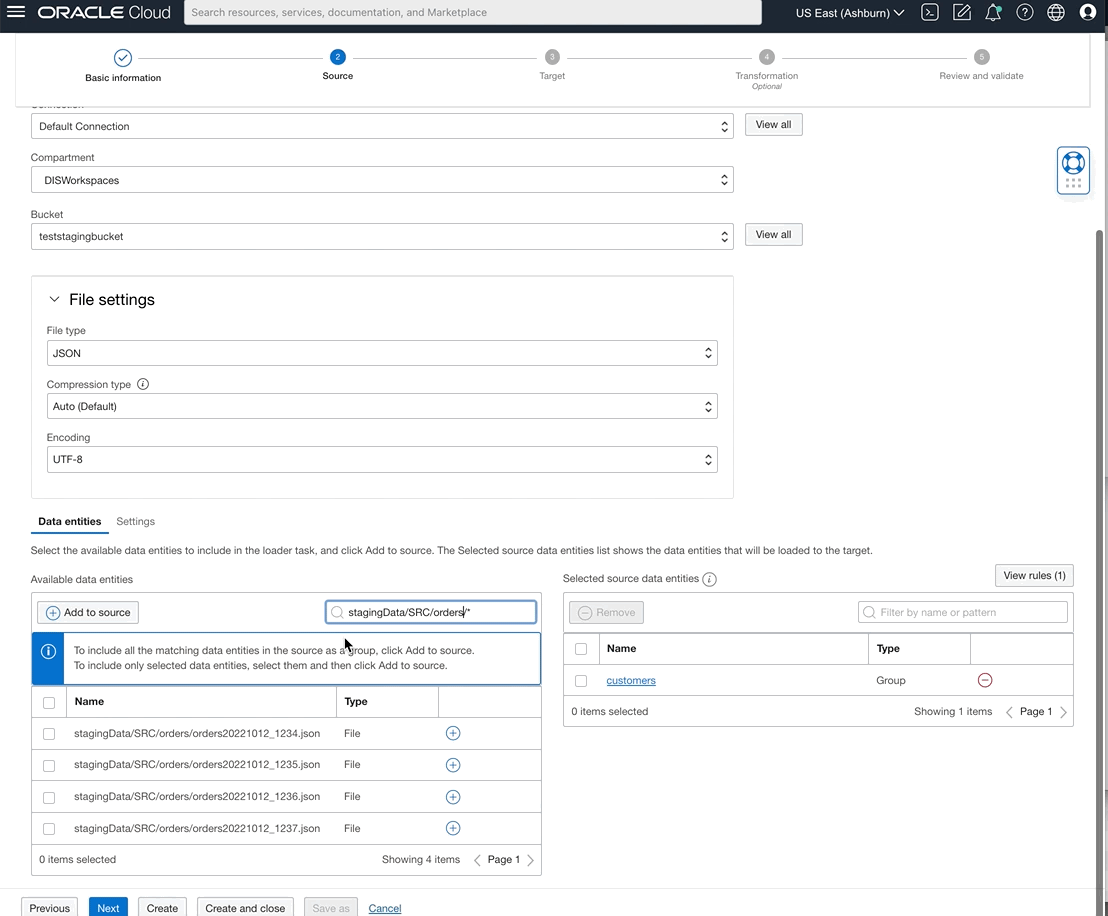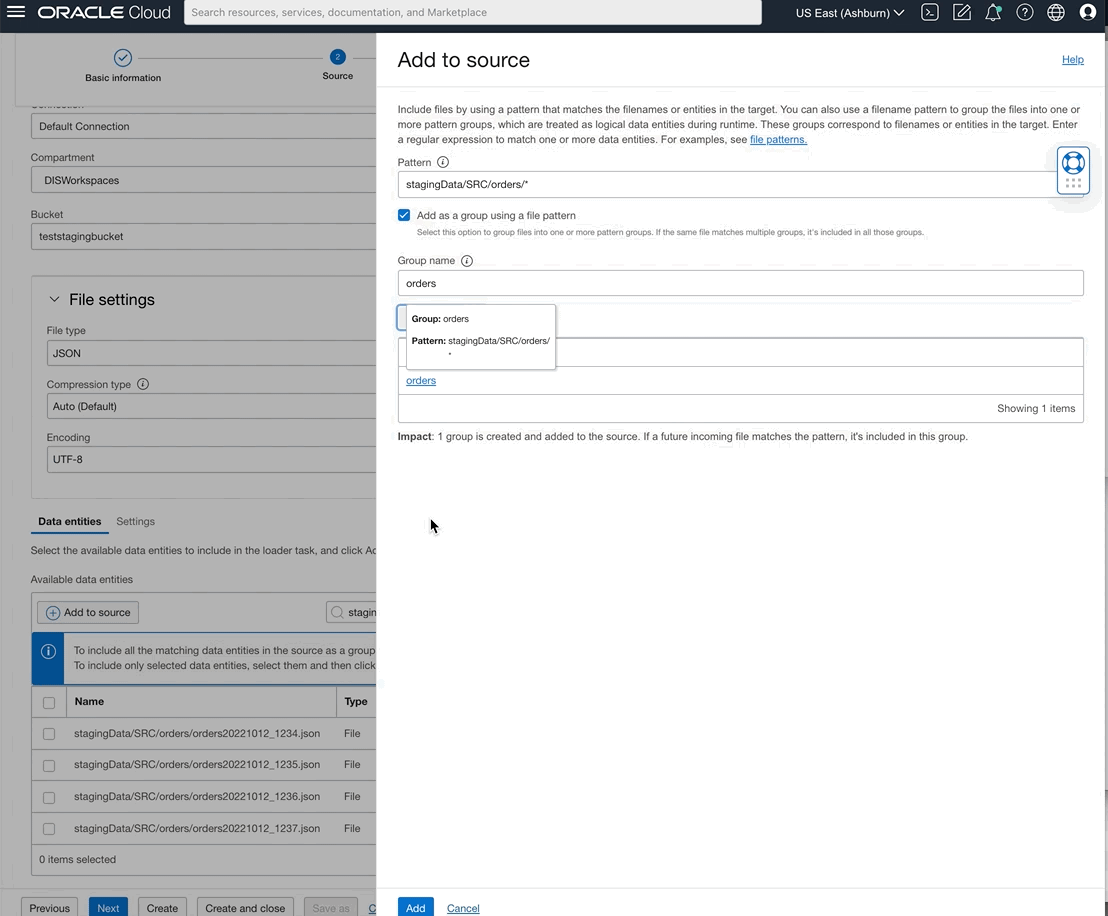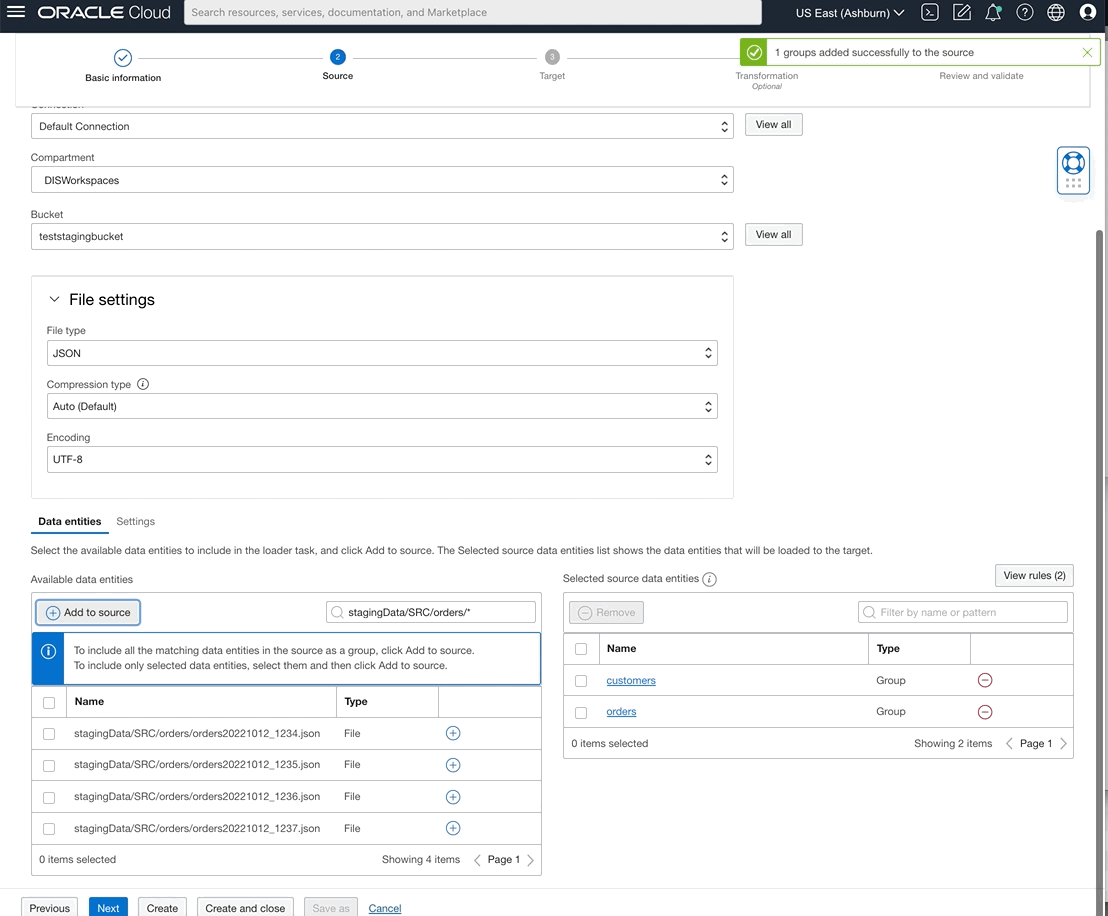
Figure 8: Defining “orders” group
Want to know more?
Organizations are embarking on their next-generation analytics journey with data lakehouses and advanced analytics with artificial intelligence and machine learning in the cloud. For this journey to succeed, they need to ingest, prepare, transform, and load their data with Oracle Cloud Infrastructure Data Integration quickly and easily. Try it out today!
For more information, review the Oracle Cloud Infrastructure Data Integration documentation, associated tutorials, and the Oracle Cloud Infrastructure Data Integration blogs.
