The following benchmarks were run by Alberto Araldo and Giovanna Vatteroni from Azimut-Benetti SPA
Siemens Simcenter STAR-CCM+ is a multiphysics computational fluid dynamics (CFD) software for the simulation of products and designs. Customers can deploy it on Oracle Cloud infrastructure (OCI) using the reference architecture, following the LiveLab, and running the terraform scripts. In some cases, particularly for customers with predetermined budgets and minimal resource needs, running a high-performance computing (HPC) workload on a dense node with high number of CPU cores can be more feasible rather than running it on a multinode HPC cluster as a distributed workload.
This post illustrates comparison results of running customer-specific STAR-CCM+ models from Azimut Benetti on an HPC cluster based on BM Optimized3 Shape (Intel) up to four nodes and a single Standard BM E5 shape (AMD) and a standalone BM Optimized3 Shape (Intel). For more details regarding the E5 shape, see Available now: E5 instances on AMD EPYC processors for up to 2x better performance.
Azimut Benetti is the first global leading private group in the yachting sector. Thanks to continuous innovation and experimentation, it has been the world’s leading manufacturer of megayachts and the shipyard with the widest range of models on the market for 24 years.
Infrastructure
The architecture used to run this benchmark is based on the one described in the reference architecture site and is shown in Figure 1. An alternative architecture with Standard E5 shape is also illustrated in Figure 2.
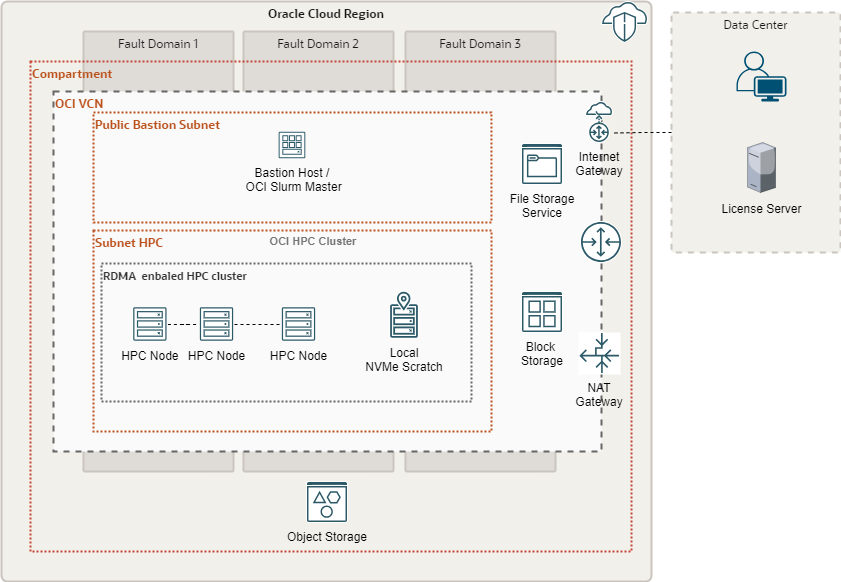
Figure 1: OCI HPC RDMA cluster with Bare Metal Optimized3 cluster nodes

Figure 2: A generic architecture with a single BareMetal E5 standard node
The benchmark runs use two different architectures, based on the following components:
Setup 1:
- Bastion host: A virtual machine (VM) with a Standard.E4.Flex shape used as a jump host and a Slurm master
- HPC nodes: Bare metal instance using a BM.Optimized3.36 shape with 36 Intel Xeon 6354 cores, 3.84-TB locally attached NVMe SSD, and 100-Gbps RDMA network.
- Other OCI services, including Block Volume, Object Storage, and Identity and Access Management (IAM), are used to prepare and run the environment.
Setup 2:
- Bastion host: A VM with a Standard.E4.Flex shape used as a jump host and a Slurm master
- HPC nodes: Bare metal instance using a BM Standard E5 shape with 192 AMD EPYC 9J14 cores and a Block Storage attachment.
- Other OCI services, including Block Volume, Object Storage, and IAM, are used to prepare and run the environment.
Star-CCM+ CFD simulations benchmark
To evaluate a total cost to time-to-solution metric, we carried out CFD simulations with the following models:
- Virtual towing tank test (VTTT Two Phase VOF – 2DOF)
- Virtual towing tank with exhaust gas (GAS Two Phase VOF – 2DOF)
- Aerodynamic simulation (AIR 1Phase – 0DOF)
Azimut owns these models, VTTT, GAS, and Aerodynamic, and the geometry and simulation settings are Azimut’s specific test use case.
To perform these simulation benchmarks, we designed two variations of architectural infrastructures. In the first variation, we deployed a HPC cluster with Intel CPU-based BM.Optimised3.36 bare metal nodes on four nodes to reach a total number of 144 cores. In the other variation, we chose a single AMD E5-based BM.Standard.E5.192 node to perform the same benchmarks.
Simulation model description
The following table summarizes the technical details of the simulation models:
| VTTT |
GAS |
AIR |
| N. Cells: 1.30 mil. Solver Setup: U-RANS N. Time-steps: 200 N. Iterations: 1000 |
N. Cells: 2.75 mil. Solver Setup: U-RANS N. Time-steps: 200 N. Iterations: 1000 |
N. Cells: 12.0 mil. Solver Setup: S-RANS N. Time-steps: – N. Iterations: 200 |
Price-to-performance analysis
The following figures compare the CPU time and cost analysis for the different use cases.
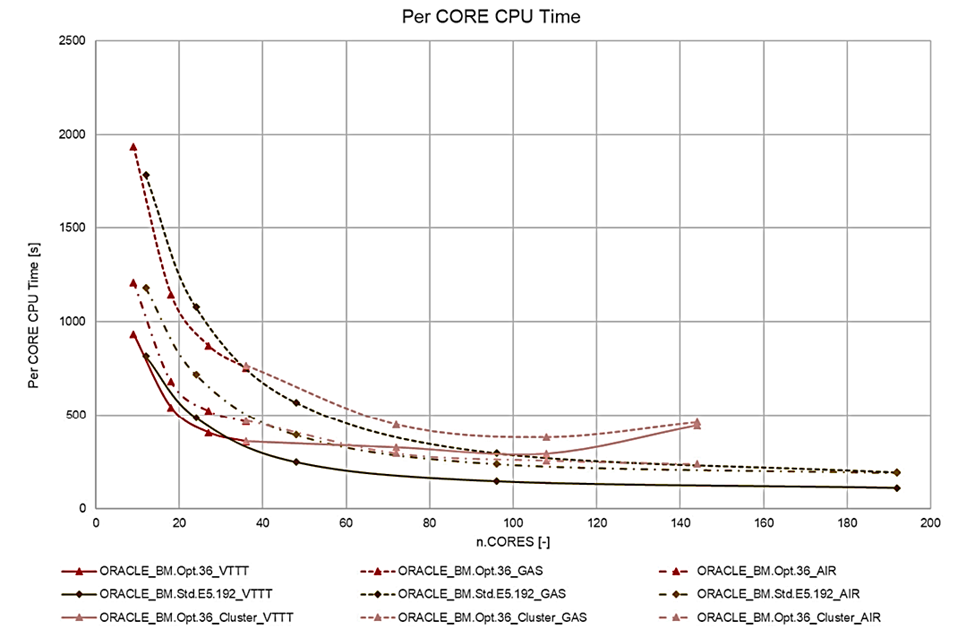
Figure 3. CPU time per core for different simulation runs.
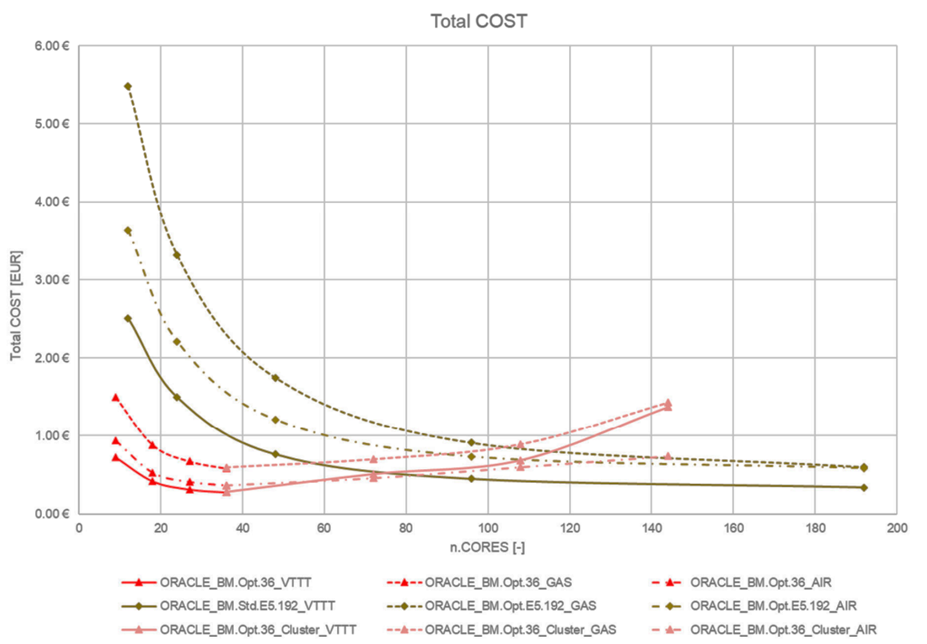
Figure 4: Total cost per simulation runs for different setups
These three different simulations use cases show that the time to solution and total cost per simulation minimizes when using the standard E5 shapes compared to the HPC optimized X9 (BM.Optimized3.36) shape around 120 CPU cores. The addition of multinode distribution and RDMA network for the BM.Optimized3.36 nodes compared to the intranode runs for the BM.Standard.E5.192 contributes to this outcome.
However, while only concentrating on the price-to-performance for these use cases, the standard bare metal E5 shows a good lead. Distributed parallel runs on a RDMA cluster have their own strengths and performance scaling, but these use cases didn’t show speed-up while running on RDMA cluster. There can be many reasons, such as parallel efficiency of the model and load distribution or memory footprint, but an investigation for the cause is out of scope.
The following images illustrate the visual models of the streamlines, free surface, and mesh structures:

Figure 5: Hull geometry (orange), sea surface (light blue), and velocity magnitude on aerodynamic streamlines in aerodynamic simulation.
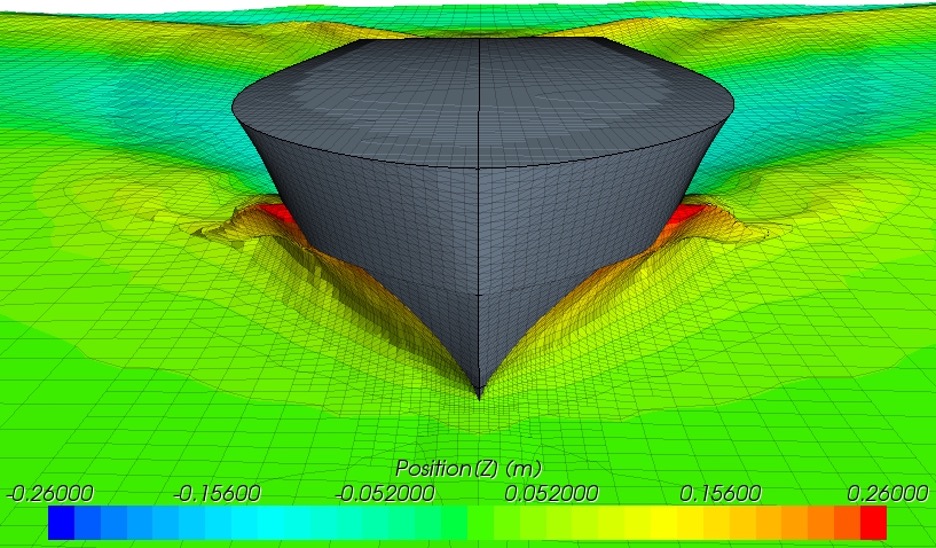
Figure 6: Hull geoemtry (in grey) and wave formation in a Virtual Towing Tank Test simulation.

Figure 7: Hull geometry (orange), wave formation (light blue), and velocity magnitude on exhaust gas streamlines in a virtual towing tank test simulation with exhaust gases.
Conclusion
The benchmark results show that, for these CFD workloads, running them on a single node with standard bare metal hardware configuration without RDMA capabilities could become more feasible and productive for price-to-performance than running the same workloads on a specially optimized HPC cluster nodes with powerful CPUs, locally attached high throughput IO drives, and fast low-latency network. This setup is mostly applicable for parallel workloads that can ideally fit into the CPU count and memory of a single node.
For more information, see the following resources:
- Azimut Benetti
- Simcenter STAR-CCM+ CFD software
- High Performance Computing: STAR-CCM+ on Oracle Cloud Infrastructure (reference architecture)
- Siemens Simcenter STAR-CCM+ in Oracle Cloud (LiveLab workshop)
- Siemens Simcenter STAR-CCM+ runbook (Terraform scripts)
- E5 instances on AMD EPYC processors for up to 2x better performance (blog post)

