The authors want to thank Larry Wong and Richard Sachs for their contributions to this blog.
Credit card purchase and payment has become part of our daily lives. Unfortunately, fraudulent credit card transactions have also increased from 127 million in 2021 to an estimated 150 million in 2023 in the United States, amounting to about 1 fraud per thousand of transactions, or 5 fraud cases every second. Retailers are expected to lose $130 billion this year on card-not-present transactions, as reported by Dataprot.
Credit card fraud happens when a scammer uses a stolen or copied credit card to make a purchase. The Financial Services industry has combated this crime for decades, assisted by the latest IT technology and computational algorithms. The real-time online transaction pre-authorization process is one of the common techniques used to battle credit card fraud. The process requires a consumer to submit purchasing and credit card information at the point-of-sales (POS) through an online device to the card-issuing bank for screening. When an approval code is returned, usually within a couple of seconds, the purchase can move forward. Otherwise, the credit card is denied, warning the merchant not to accept it for the purchase. This instantaneous approval/denial process increases protection for both consumers and merchants.
In a recent technical collaboration, OCI and NVIDIA engineering teams constructed a proof-of-concept (POC) implementation to apply machine learning enhancements against a real-time online pre-authorization process. These enhancements can add a new layer of protection for both consumers and merchants while maintaining the same real-time online processing speed. In this blog post, we will walk through the key concepts and procedures involved in the implementation.
Machine learning enhancement for fraud detection
Comprehensive machine learning models can be developed and trained by using extensive anti-fraud data and experiences accumulated by the financial services industry. Such models analyze raw transactional features such as consumer name, time, amount, and place of the transaction, in addition to information provided by consumer credit-reporting companies. Armed with feature engineering strategies, machine learning models, for example, can further group together and analyze transaction patterns made during the last given number of hours by merchant type, dollar amount of purchase, speed of spending, and geographical location, etc. As a result, machine learning-based evaluation rules are developed and added as an enhancement step to a currently deployed real-time online pre-authorization process, resulting in an additional layer of protection for both consumers and merchants.
A machine learning-enhanced transaction pre-authorization solution is illustrated in Figure 1 below.
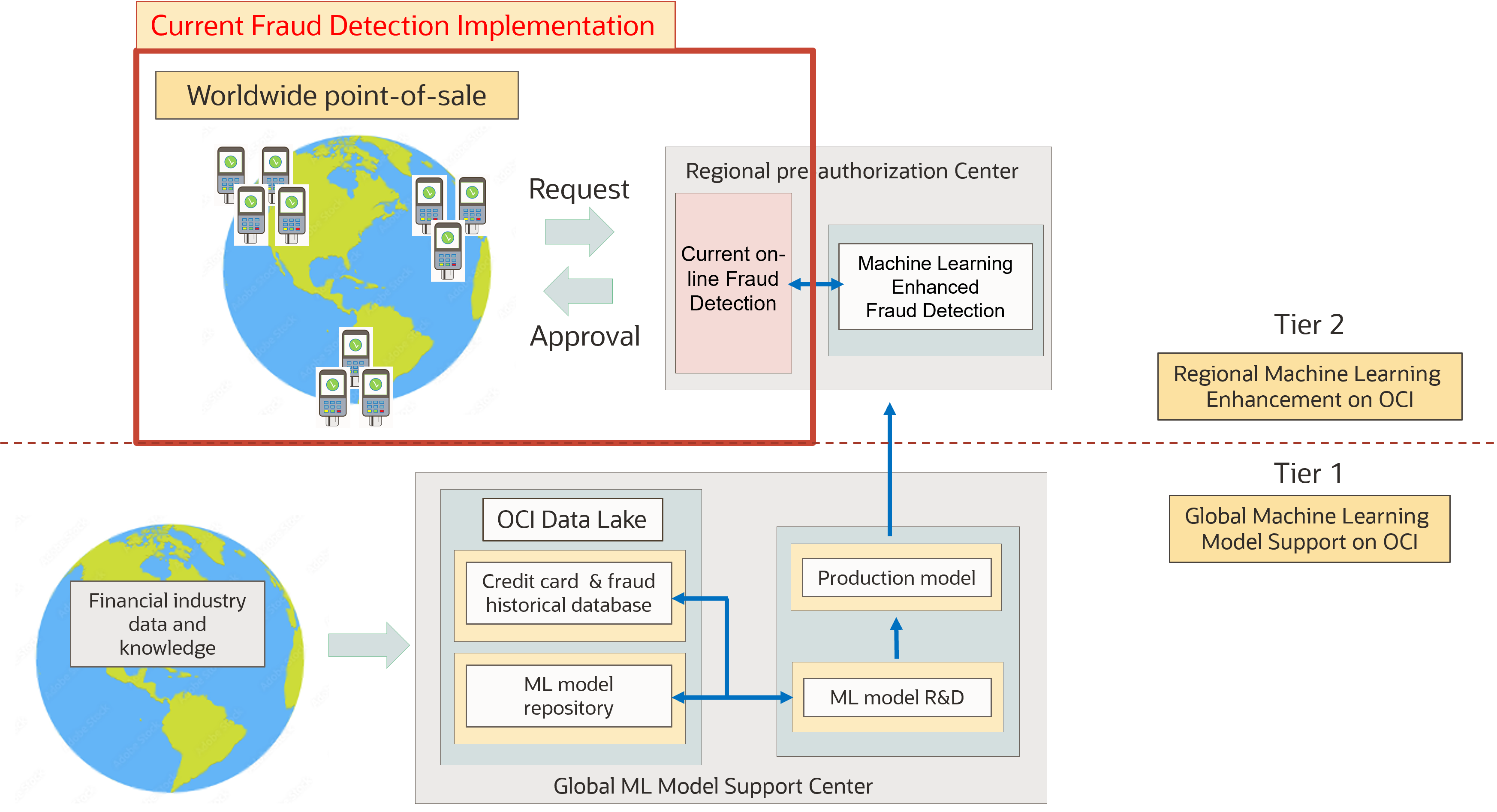
The currently deployed fraud detection implementation is highlighted in the red box in Figure 1. The machine learning enhancement can be created in two tiers as indicated in Figure 1:
- Global machine learning model support center: This is where the machine learning model is developed, trained, validated, packaged, and finally shipped for production release. A data lake system is established in this tier to manage the extensive credit card and fraud detection history data collected from the worldwide financial services industry. Also under management are machine learning algorithms, models, and other related knowledge and research information.
- Regional machine learning enhancement center: Here, the current online fraud detection process is closely integrated with the new machine learning enhancement, generating a new layer of protection and/or a “second opinion” that goes into the final decision of pre-authorization.
For brevity, Figure 1 includes only one global machine learning model support center and one regional pre-authorization center. Multiple global and regional centers are preferable for a large financial institution, enabling it to provide national or international geographical coverage so that local data and knowledge can be gathered more efficiently, and fast responses can be delivered to POS systems with minimal delay. This also enables the high-availability (HA) redundancy required by the financial services industry.
The machine learning solution described in Figure 1 can be implemented following the architectural diagram in Figure 2. There are three workflows illustrated in the figure, as follows:
- Blue arrows: Machine learning (ML) model development and deployment workflow
- Golden arrows: Online preauthorization process workflow
- Brown arrows: Machine learning model update and correction workflow
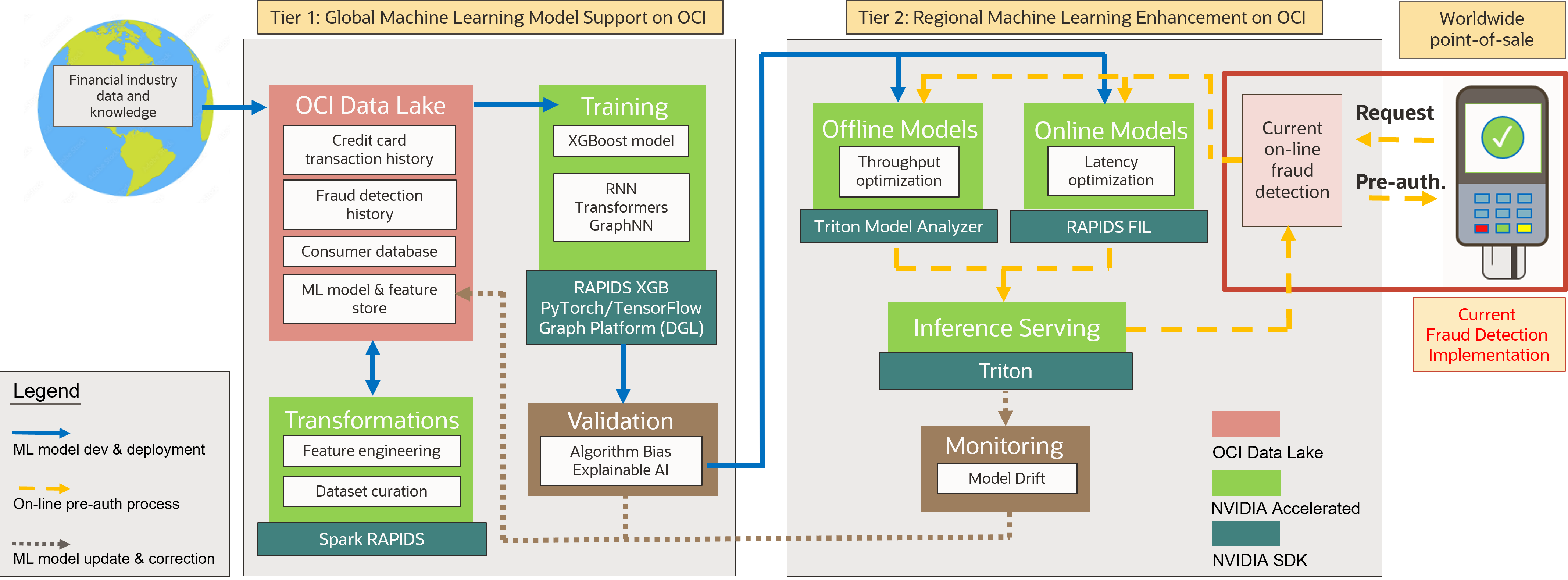
We can see that Figure 2 expands each functional unit and workflow outlined in Figure 1, providing additional details about both the machine learning enhancement solution and the pre-authorization process implementation. While these functional units and workflows are mostly self-explanatory, we want to highlight the NVIDIA RAPIDS Accelerator for Apache Spark and NVIDIA Triton Inference Server – both a part of the NVIDIA AI Enterprise software platform for the development and deployment of production-grade AI applications – which are key pieces of technology to help enable machine learning application development.
An offline batch process model is also included in Figure 2 which is designed to integrate latest transaction data into feature engineering functionalities and make them immediately usable for the next round of pre-authorization processing.
Building a machine learning model
When a credit card pre-authorization request is processed, information about the card, its holder, and purchase-related information are validated by the card-issuing institution item by item, with a pass or fail decision given to each validation. This process is schematically represented as a decision tree, which is a type of flowchart used to visually demonstrate a decision-making process. A pre-authorization code is generated at the end of the process only when the transaction is completely validated.
To create a machine learning model for fraud detection, we selected the NVIDIA GPU-accelerated XGBoost (Extreme Gradient Boosting) to build decision trees to represent the request validation process. XGBoost is one of the most popular machine learning libraries for regression, classification, and problem-ranking and is used widely in the financial services industry to build and train models for fraud detection. Because XGBoost can involve thousands of decision trees, it runs significantly faster with NVIDIA GPUs. XGBoost includes seamless drop-in GPU acceleration, which speeds up model training and improves accuracy for better predictions.
Next, we used NVIDIA Triton Inference Server to deploy our XGBoost model for production inference processing. NVIDIA Triton Inference Server is AI model-serving software that streamlines and accelerates the deployment of AI inference workloads in production, helping enterprises reduce the complexity of model-serving infrastructure, shorten the time needed to deploy new AI models, and increase AI inferencing and prediction capacity. It is also available as part of the NVIDIA AI Enterprise, now available on Oracle Cloud Marketplace, with enterprise-grade support.
Implementing a fraud detection solution on OCI
Our POC solution implementation was deployed on an OCI VM.GPU.A10.2 shape, which was configured with two NVIDIA A10 Tensor Core GPUs, 30 Intel Xeon Platinum 8358 (Ice Lake) processor cores, and 480 GB of system memory. In addition, the A10 GPUs also have 24 GB of GPU memory in each processor.
The VM was powered by an NVIDIA GPU Cloud Machine Image, an Ubuntu server 20.04.6-based, GPU-accelerated platform optimized for deep learning, data science, and high performance computing (HPC) workloads. It was further enhanced with these enabling software packages:
- NVIDIA driver: 530.30.02
- Docker CE: 23.0.4-1
- NVIDIA Container Toolkit v1.13.1-1
- RAPIDS cudf 21.12.02
- Mellanox OFED 5.9-0.5.6.0
- Jupyter-lab v3.6.3
- oci-cli v3.25.4
- ngc-cli v3.20.0
POC experiment and observations
A typical pre-authorization processing center is linked with hundreds of millions of POS devices in its designated geographical areas for a credit card-issuing institution. It must respond in a window of milliseconds with a yes/no decision to online pre-authorization requests so that the decision can be quickly transferred back to POS devices. To effectively process the requests that are continuously arriving, our POC experiment sets up a time interval Δt and group processes the requests received during the time interval.
Let’s use N to represent the total number of requests collected during Δt (assume Δt=2 milliseconds).Triton Inference Server can parallel process P batches of concurrent workload, so we divided N into P batches, with each batch containing R requests. This gave us the relationship N = P * R. Because the value of N fluctuates constantly, moving higher during business hours and dropping lower after midnight, we needed to scan through a range of N values to measure the time needed to process these pre-authorization requests.
We selected the Kaggle IEEE-CIS Fraud Detection competition data set for our POC, and we trained two XGBClassifier models on GPUs for model comparison purpose:
- The small model included 500 trees with a maximum depth of 3.
- The large model included 5000 trees with a maximum depth of 12.
The POC experiment was recorded in a Jupyter notebook available for readers to download. Documentation is included in the notebook to guide readers through each step of the experiments. To better manage the pre-authorization requests, which arrive anytime of the day, we grouped the requests that arrived within Δt millisecond for batch processing.
Table 1 below summarizes the results of our study using the large model, where:
- N: number of pre-authorization requests arrived during the time interval Δt. (Assume Δt=2 milliseconds, further adjustable based on workload)
- P: number of batches parallel processed by Triton Inference Server
- R: number of requests in each batch
- T(p99): time needed to process 99% of N requests
- Throughput: number of requests processed per second (K=1000)
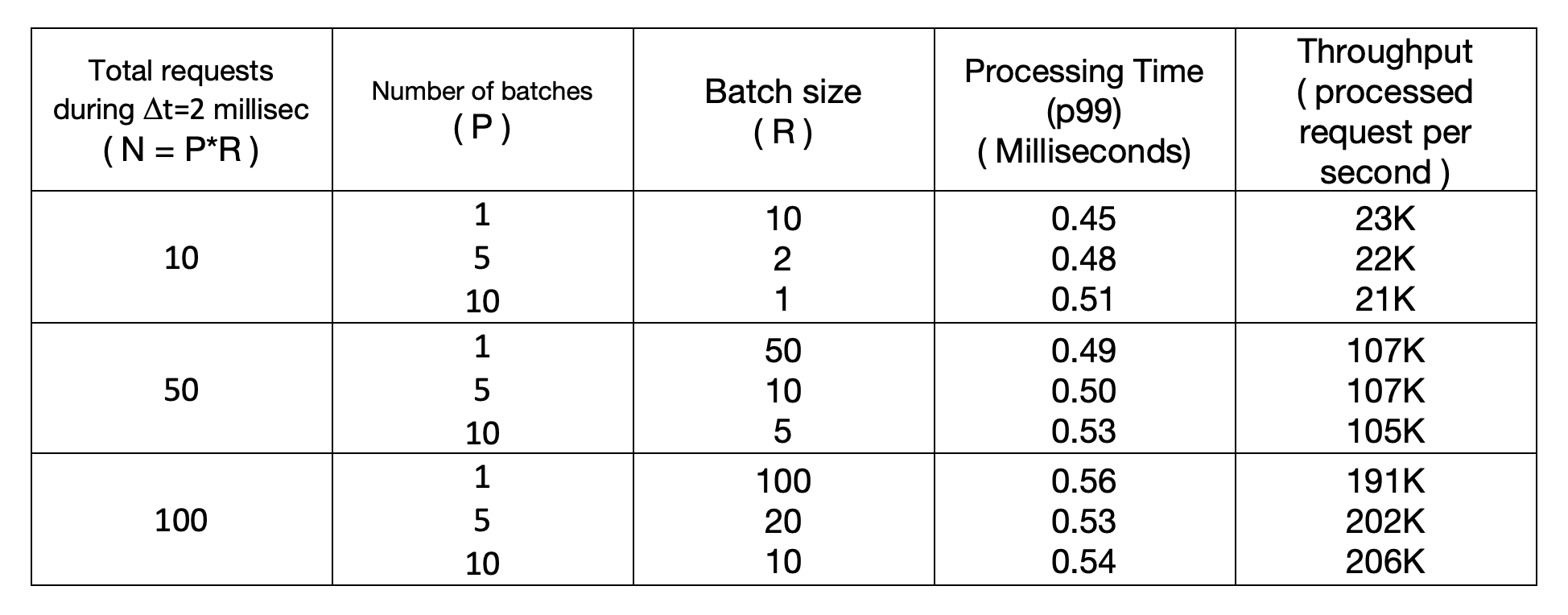
Table 1 showed that Triton inference server was able to process up to 100 requests in 0.6 milliseconds. As these requests were collected in Δt=2 milliseconds, the total processing time for these requests were 2.6 milliseconds. As it typically takes 2-3 seconds for the existing pre-authorization process to complete, incorporating less than 3 milliseconds into the process will further enhance consumer and merchant protection while POS devices will not notice any difference in response time.
In a practical implementation, an automated algorithm can be set up to adjust value Δt , N, P and R to ensure prompt processing of incoming requests. As the Triton Inference Server can run parallel on multiple GPUs, the performance can be further enhanced by deploying the code on servers with higher number of GPUs.
This processing capability is more than adequate to support the highest demand of online pre-authorization workloads. According to Statista.com, Visa credit cards were used in roughly 22 billion transactions in Q1 of 2023, or approximately 1.4 transactions per millisecond. Because these transactions are further distributed to thousands of credit card-issuing institutions for pre-authorization, the number of transactions per institution per Δt=2 milliseconds is not likely to be higher than 100, which was the maximum requests number that we used in the POC.
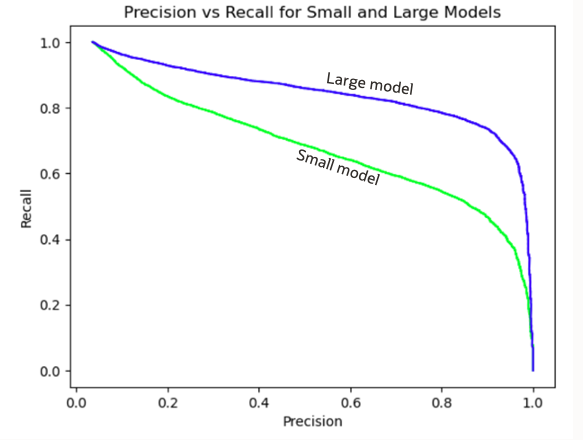
A precision-recall curve is commonly used to evaluate and visualize decision tree model performance. In Figure 3, we plotted the precision-recall curves for both the small and large models used in this study. The large model showed higher scores than the small model for both precision (higher accuracy) and recall (more positive results), as expected.
Summary
In this blog, we demonstrated a real-time credit card pre-authorization process that can add a new layer of protection for both consumers and merchants. We found that the process delivered the same real-time response speed and was easy to implement and integrate into the current process.
What makes Oracle best suited for the machine learning applications in the financial services industry?
Oracle offers a modern data platform and low-cost, high-performance cloud infrastructure to meet enterprise customer requirements. For machine learning applications such as online credit card fraud detection, NVIDIA GPU-based instances on OCI deliver outstanding performance, as demonstrated in a recent industry-standard MLCommons Inference benchmark. Additional factors, such as unrivaled data security and embedded ML services, demonstrate that Oracle’s ML offering is truly built for enterprises. Oracle enterprise-grade software solutions accelerate the data science pipeline and streamline the development and deployment of production machine learning solutions and artificial intelligence, including generative AI, computer vision, and speech AI natural language processing. For more information, see the latest about Artificial Intelligence (AI) at Oracle and NVIDIA AI Enterprise.
Join us at NeurIPS in New Orleans! Talk to Oracle experts who can help solve your challenges and experience a sample of Oracle’s comprehensive portfolio of AI capabilities at the Oracle Pavilion. Through OCI, Oracle applications, and Oracle’s partner ecosystem, you will find solutions and services that can help with your AI journey, regardless of your starting point and what your objectives are.
Reference:



