We’re excited to announce a new release of Oracle Cloud Infrastructure (OCI) Data Catalog. In this release, we have added many productivity improvements to help data professionals harvest, curate, and search metadata for assets across their Object Storage data lake, Autonomous Data Warehouse, and Oracle and non-Oracle databases for analytics.
One feature that we’re particularly proud of is for data experts and data stewards. We’re employing advanced fuzzy matching and artificial intelligence (AI) and machine learning (ML) techniques to recommend which business glossary terms and categories can be linked to technical objects. This feature not only improves productivity but also invites you to add enrichment. Such enrichment means better information and a holistic view for data consumers.
Support data discovery and improve governance with OCI Data Catalog
As a quick refresher, OCI Data Catalog is a recently launched service that makes it easier to find valuable trusted data. It helps find data in OCI and beyond and collects details to understand what data exists where, its business context, and how it can be useful for analytics. At its core, it is a metadata management solution that supports data lakes, data warehouses, analytics, and data science solutions by enabling self-service data discovery and improving data governance.
If you’re not familiar with this new service, see the blog What is OCI Data Catalog? for an overview. Data Catalog is available in all 22 OCI commercial regions.
New features of Data Catalog
This release of Data Catalog has enhancements to the following areas:
-
Harvesting
-
Business glossary
-
Integration with other services
-
Functional improvements
Harvesting
Harvesting is how you extract data structure information from your data sources or assets into your data catalog repository. A data asset is any physical data store or stream of data, such as a database, cloud storage container, or message stream. These data assets are at the foundation of Data Catalog, providing it the inventory of information to organize in a way that makes it more discoverable.
To better understand the relationship between tables and help identify other dependent tables that you might want to harvest, more details are made available at the table level. Most importantly, RDBMS level constraints are now included in the harvesting, including primary, foreign, and unique keys.
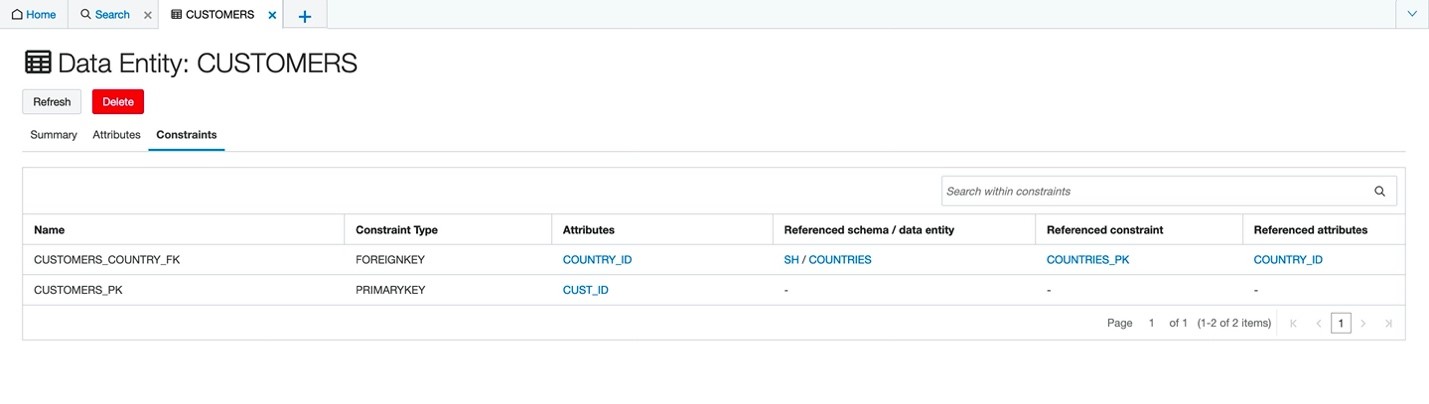
Figure 1: Data entity Customers, showing related tables.
During file harvesting, Data Catalog parses the file content. Sometimes you want to correct file parsing behavior, such as file delimiter or header rows, to get appropriate file schemas. With this release, you can edit parsing properties for CSV files and logical entities, and you can reharvest a file or logical entities based on the updated properties.
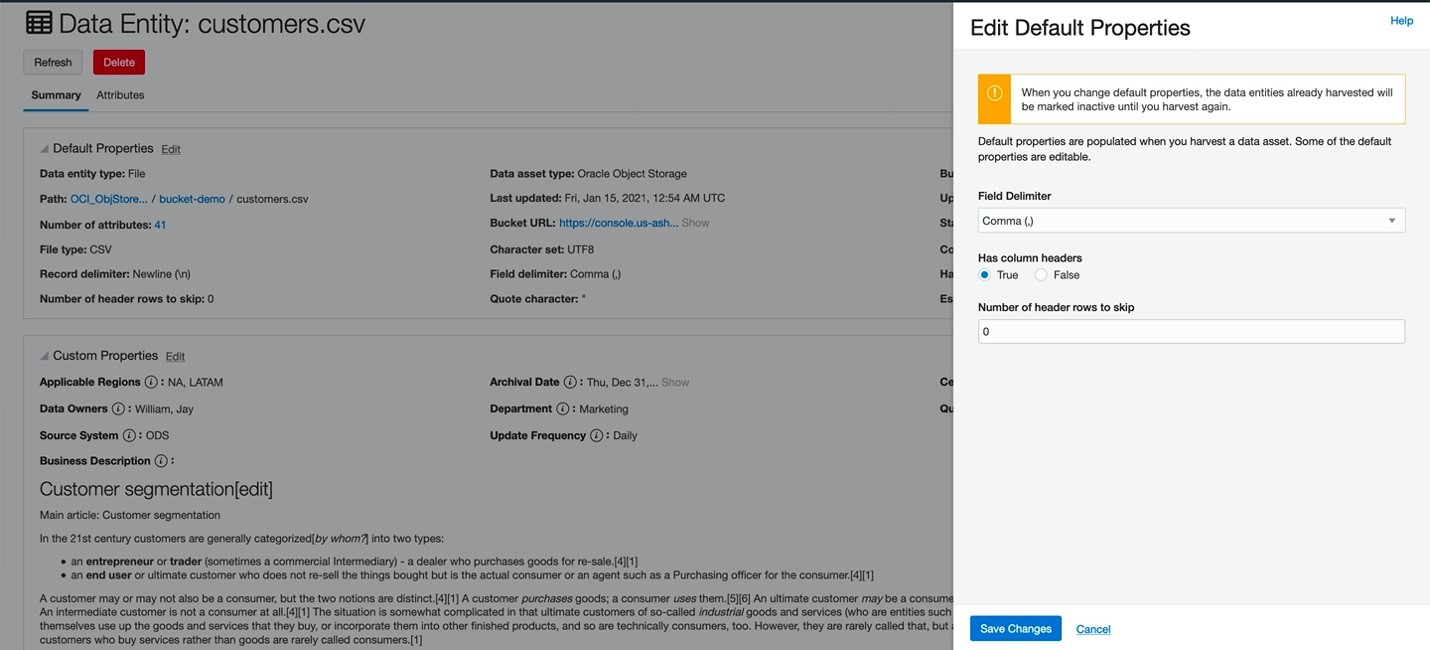
Figure 2: Editing of parsing behavior.
Business glossary
A business glossary defines your concepts across your business domain. Creating a business glossary brings common understanding of the vocabulary used throughout your organization. In Data Catalog, you create categories and terms in a glossary to manage and organize your business concepts. This release brings in machine learning enhancements for more automation.
Linking business glossary categories and terms to data entities and attributes enriches your data catalog objects and makes them easily searchable and discoverable in Data Catalog. Manually linking these data entities and attributes can be time-consuming and isn’t scalable. In this latest release, using various fuzzy matching algorithms and AI and ML techniques, Data Catalog identifies and recommends business glossary categories and terms for your data entities and attributes. Using these recommendations, linking is easier, faster, scalable, and more productive than the manual linking process. Glossary terms and technical metadata are easily connected for better usability.
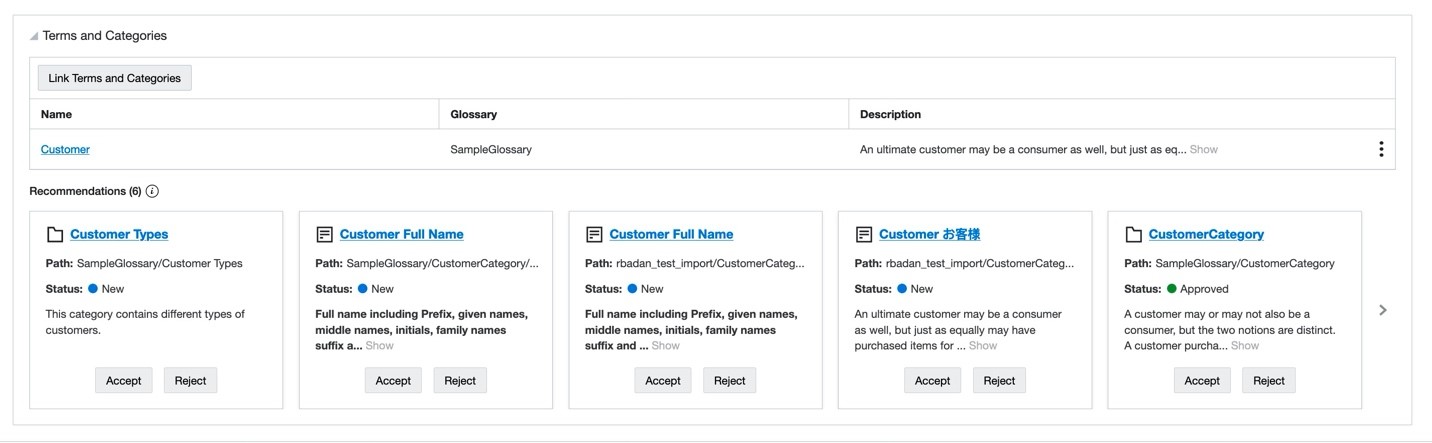
Figure 3: Example of where to link terms and categories in OCI Data Catalog
Import and export of the glossary using the familiar Microsoft Excel format is now possible for the following supported elements: categories and terms, relationships, and custom properties. Rich text descriptions are retained in this process, providing a more familiar format for easier readability and editing. There’s even a sample import template available.
Integration
In expanding on the integration across OCI services, Data Catalog is now integrated with the Oracle Cloud Events service, where consumers can create rules that listen to events and create topics or subscriptions to get notifications by Slack or email. Data Catalog publishes harvest-related events such as started, succeeded, failed, and so on, allowing consuming services to react as appropriate.
Functional enhancements
This release also includes the following functional and UX improvements:
-
File name patterns to derive logical entities in object store data lakes have been enhanced, making it easier to group files with slightly disparate names together for better organization.
-
Exadata Cloud service is now supported using private IP. SCAN IP is not yet supported.
-
Search improvements make ranking and filtering easier.
-
Incremental harvesting support now extends to most of the data asset types.
-
Navigation URL to reach harvested Object Storage buckets from Data Catalog file details page.
-
Delete data entities in bulk from schemas and folders.
-
Path properties in search results to help clarify objects with the same name.
With these capabilities, you can harvest, access, and start to discover the data that you’ve never known was available!
Want to know more?
Organizations are embarking on their next-generation analytics journey with data lakes, autonomous databases, advanced analytics, artificial intelligence, and machine learning in the cloud. Data Catalog helps support discovery, insights, and governance of data assets. The current capabilities of Oracle Cloud Infrastructure Data Catalog are available to Oracle Cloud customers at no extra cost, providing customers with great value-added capabilities! Try it out today!
For more information, review the Oracle Cloud Infrastructure Data Catalog documentation and associated tutorials.
