If you have Spark applications feeding into the analytics systems, you can now view their lineage in Oracle Cloud Infrastructure (OCI) Data Catalog. We’re excited to announce the data lineage feature in OCI Data Catalog now extends to cover Spark applications running on OCI Data Flow and on your own systems. With the added lineage capability, you get a more holistic view of lineage of data in your organization.
What’s new in OCI Data Catalog’s data lineage?
The ever-growing volume of data demands a data processing framework that can cater to not only the traditional batch processing systems but also streaming machine learning (ML)-related and data science workloads. Spark caters to these use cases and forms a critical part of data pipelines today. As a result we are expanding our data lineage feature to cover data processed in Spark services, whether it’s in OCI Data Flow or a Spark framework of your choice.
So far, in OCI Data Catalog, you can see data lineage of data processed in the OCI Data Integration pipelines. Now, the lineage graphical representation also includes Spark applications in your data pipelines. Both table and column level lineages are supported for Spark applications.
Lineage with OCI Data Flow
Data lineage in OCI Data Catalog provides a graphical representation of the end-to-end journey of data from the data source through the processing systems to the final target. It provides a single place to view the lineage of your data pipeline. With the latest release, Data Catalog automatically receives lineage metadata from Spark application running either on OCI Data Flow in your tenancy or a different tenancy.
For Spark applications running on OCI Data Flow in the same tenancy, follow these steps:
-
Set the following IAM policies:
allow any-user to manage data-catalog-data-assets in tenancy where all {request.principal.type = 'dataflowrun'} - Configure your application in OCI Data Flow to push lineage-related metadata to the specific catalog instance where you want to view the lineage. You can select an existing catalog or enter the details manually for cross-tenancy use cases.
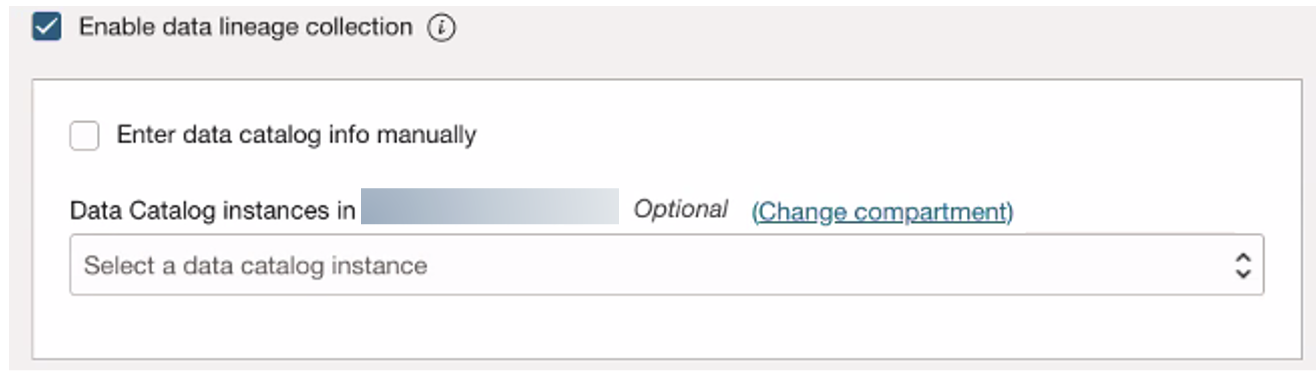
Figure 1: Enable data lineage in a Data Flow application - In the catalog, a data asset for OCI Data Flow is automatically created the first time any lineage-related metadata is pushed to it.
- Run the Spark applications.
- The Spark applications show up in the lineage graphs for related data entities.
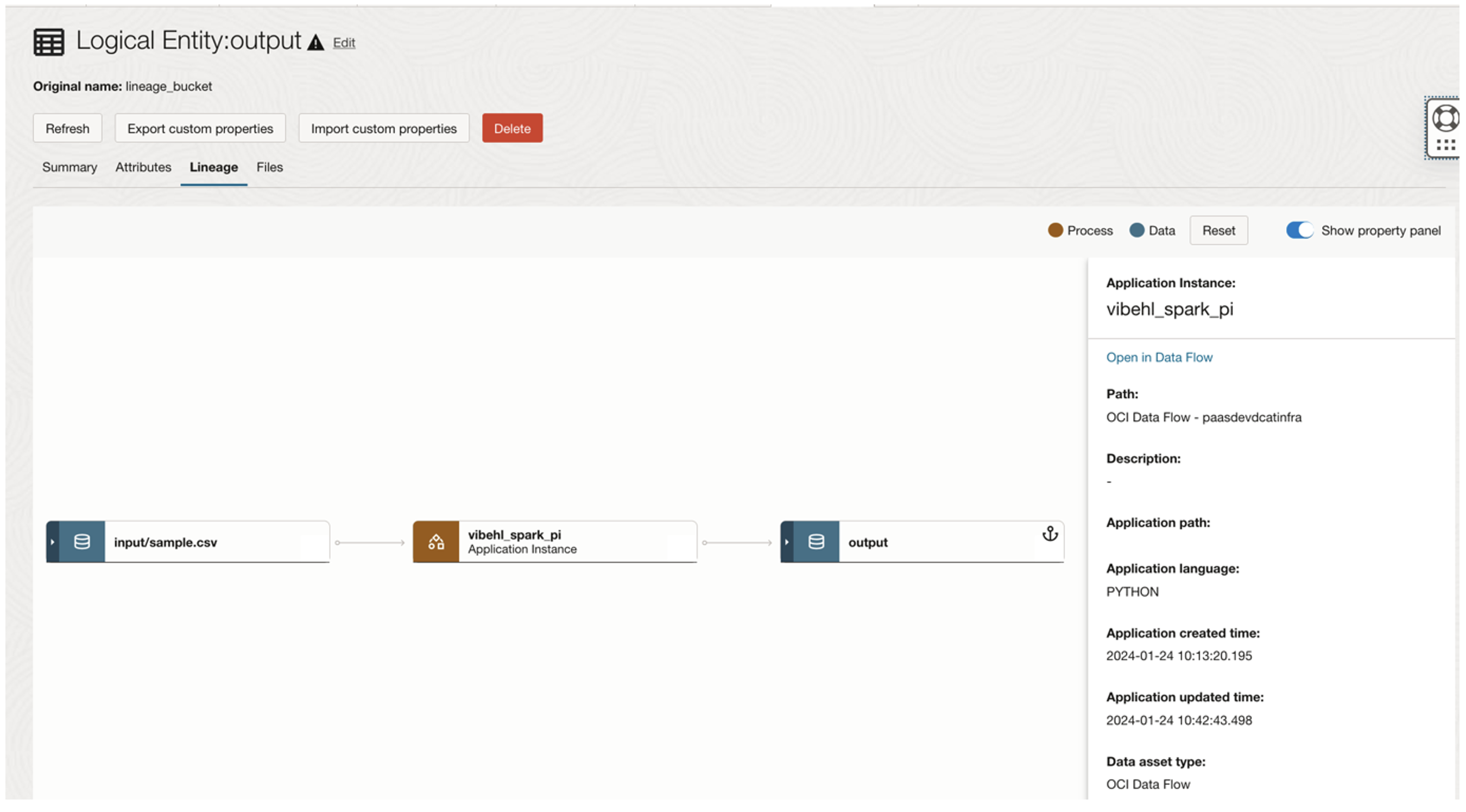
Figure 2: View data lineage graph in Data Catalog
For Spark applications running on OCI Data Flow service in a different tenancy, follow these steps
-
Set the following Identity and Access Management (IAM) policies:
admit any-user of tenancy <Data Flow Tenancy> to manage data-catalog-data-assets in tenancy where all {request.principal.type = 'dataflowrun'} endorse any-user to manage data-catalog-data-assets in tenancy <Data Catalog Tenancy> where all {request.principal.type = 'dataflowrun'} - In the remote tenancy, configure your application in OCI Data Flow to push lineage-related metadata to the specified catalog instance where you want to view the lineage.
- In the tenancy containing the catalog, create a data asset for the OCI Data Flow service.
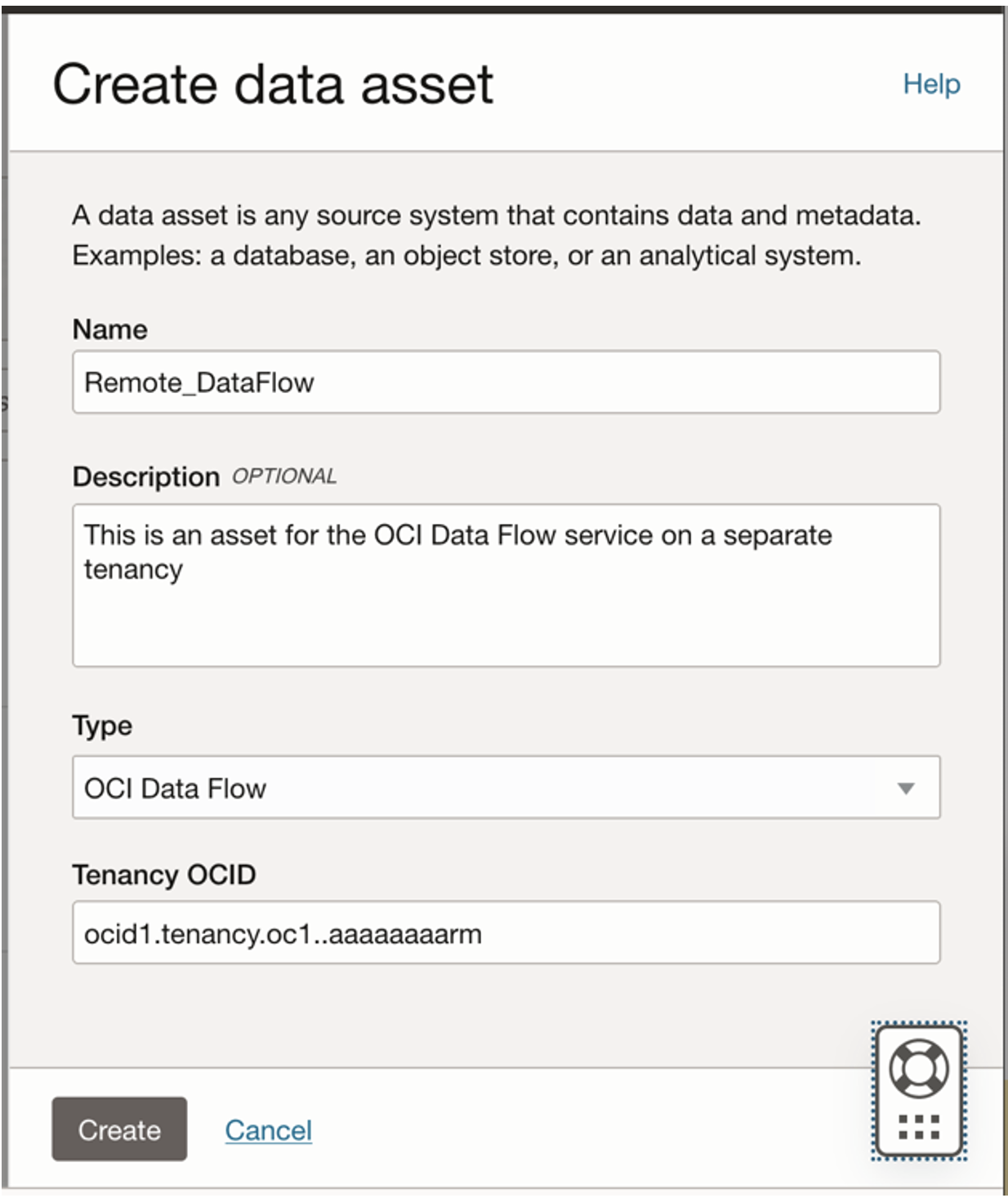
Figure 3: Create a Data Flow data asset - Run the Spark applications.
- See the Spark applications show up in the lineage graphs for related data entities.
Push custom lineage to the catalog
If your data is processed in custom applications or systems that aren’t natively supported for lineage metadata harvesting by Data Catalog, you can still include those systems in the lineage graph. A new Data Catalog API, importLineage(), allows you to push lineage-related metadata from such systems. The API accepts an openLineage compliant payload, allowing you to use available openLineage plugins as a starting point. This metadata is combined with any harvested lineage metadata for the data entities, so you can get a complete lineage graph including your custom applications.
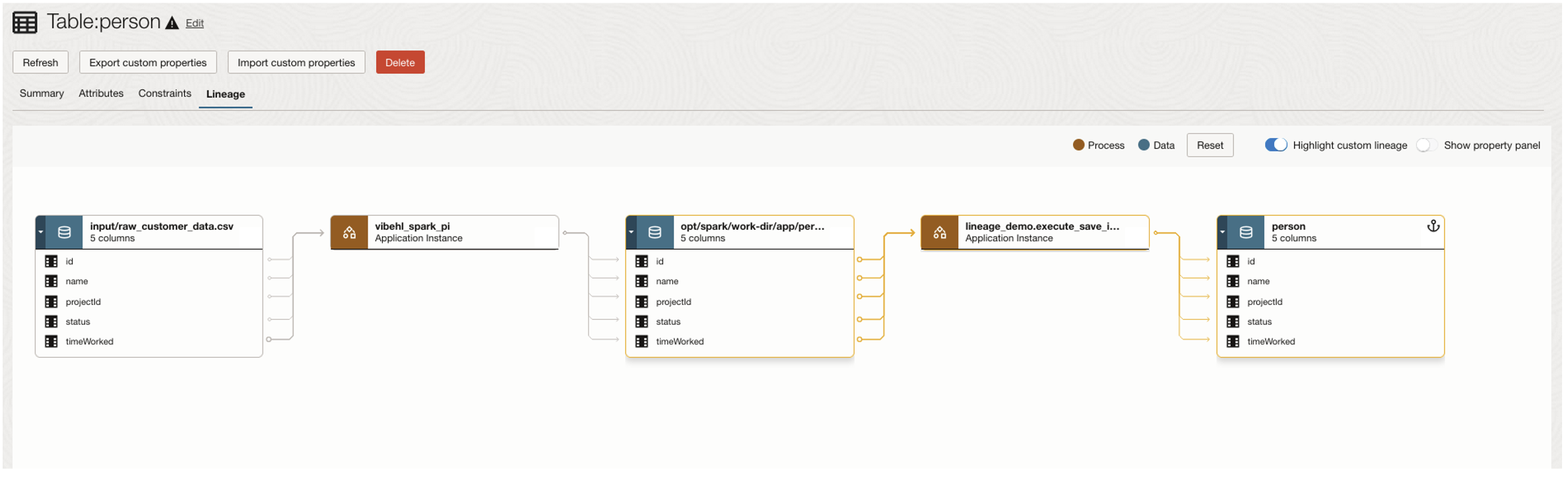
Conclusion
OCI Data Catalog provides you a single place to view lineage of data processed is all your data processing systems. You get a complete picture of the lineage, which improves trust and confidence in the data used for critical business decisions.
Try out the new capabilities in your own Oracle Cloud Infrastructure Data Catalog instance now!
For more information, review the Oracle Cloud Infrastructure Data Catalog documentation and associated tutorials.
