This blog reviews various architectural approaches and tradeoffs for multicloud logging integration based on a real-world customer engagement. It offers solutions that a customer implemented in their production environment. You can expect to walk away with a better understanding of various approaches to multicloud integration from an Oracle Cloud Infrastructure (OCI) perspective, the architectural tradeoffs involved, and prescriptive guidance on implementing a working solution in your environments.
Background
In today’s multicloud environment, we’re increasingly seeing customers build hybrid solutions that follow several common patterns. The first involves spanning a single application across multiple clouds and applying best-of-breed services in each, while the second involves a software-as-a-service (SaaS) vendor offering their platform hosted in multiple clouds to stay close to their diverse customer bases. In both cases, logs from all cloud environments must be collected in a central point for unified analysis.
We recently worked with a large SaaS vendor following the second pattern, who used the Amazon ElasticSearch service as a collection point for analysis. Although OCI has excellent options for collecting and analyzing log data, such as OCI Search with OpenSearch and OCI Logging Analytics, this customer had already built their analysis infrastructure and needed to transport OCI logging data into ElasticSearch.
This blog describes several options prototyped with the customer, the pros and cons of the various approaches, and links to implementation steps that you can follow in your environment.
The first approach: Synchronous push
The following image illustrates the initial approach discussed for moving logging data from OCI to ElasticSearch:
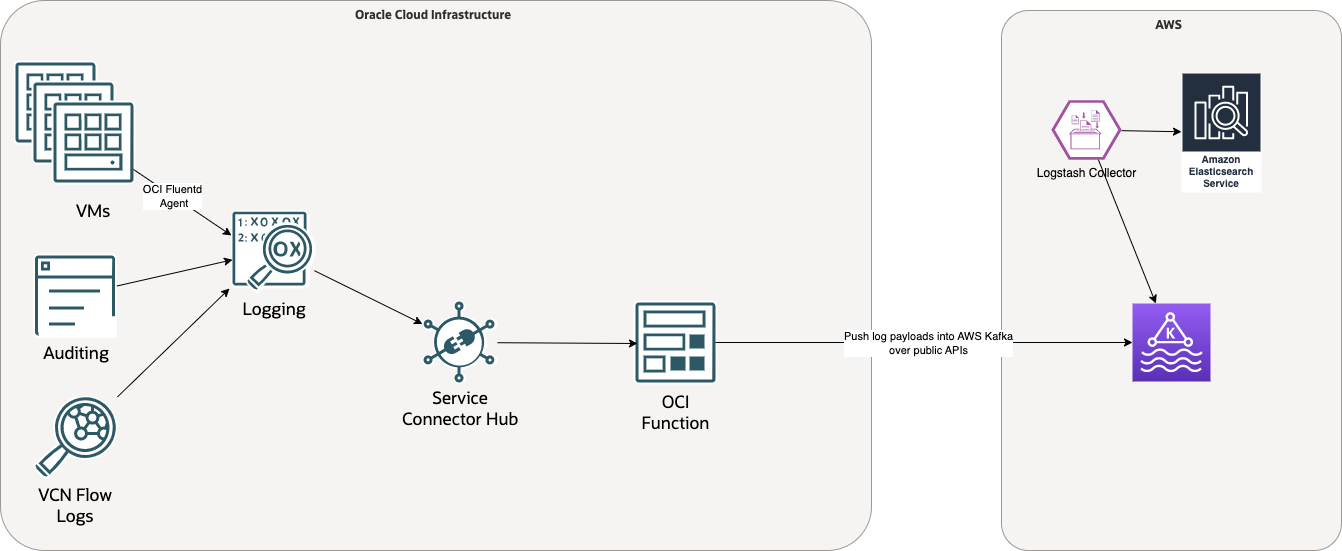
OCI generates logging data from sources like audit logs, service logs, virtual machine (VM) host logs, and network flow logs. You can configure these logs to flow into the OCI Logging service as a central aggregation point in OCI. From there, you can configure the Service Connector Hub to distribute each log message through a custom OCI function, which embeds a Kafka client to make calls over the public internet to a Kafka cluster running in Amazon Web Services (AWS). That cluster maintains a transient log message stream consumed by a Logstash ingestor that moves each message into ElasticSearch.
This solution has the following benefits:
-
Simple from a control flow perspective
-
Asynchronous and scalable with each part of the OCI architecture able to scale to demand without the need to code any scaling logic
-
Based primarily on configuration instead of custom code. The only custom code required is the Kafka client.
-
Economical: All OCI components are serverless and consume cost only when data is flowing through them, with no overhead for preprovisioned resources.
One particularity of this approach is that the customer’s Kafka cluster required mutual transport layer security authentication (mTLS) for enhanced security, so the solution we developed supported this extra level of authentication.
You can review a full, step-by-step tutorial of how you can implement this log streaming solution to a remote Kafka cluster while using mTLS in this Oracle Help Center tutorial, which we authored after this engagement.
The second approach: Loosely coupled push
While the first approach functioned well and proved the overall concept, this architecture has several deficiencies when considered for a business-critical, production purpose.
The primary concern is that the action of the OCI function is a synchronous, push-based approach. After the Service Connector Hub passes a log message to the function, that flow is complete, and the Service Connector Hub has no way of knowing whether the function successfully delivered the message to its target. If the function can’t make a connection to the remote Kafka cluster, because the cluster is down or the network connection is severed from problems with the source cloud, target cloud, or intermediate network segments, it is responsible for implementing retries in custom code. However, OCI functions can only run for a maximum of 300 seconds, so if an outage persists for longer than five minutes, the data might not reaching the target system.
To remedy this architectural deficiency, we considered modifying the approach to be loosely coupled, as depicted in the following figure:
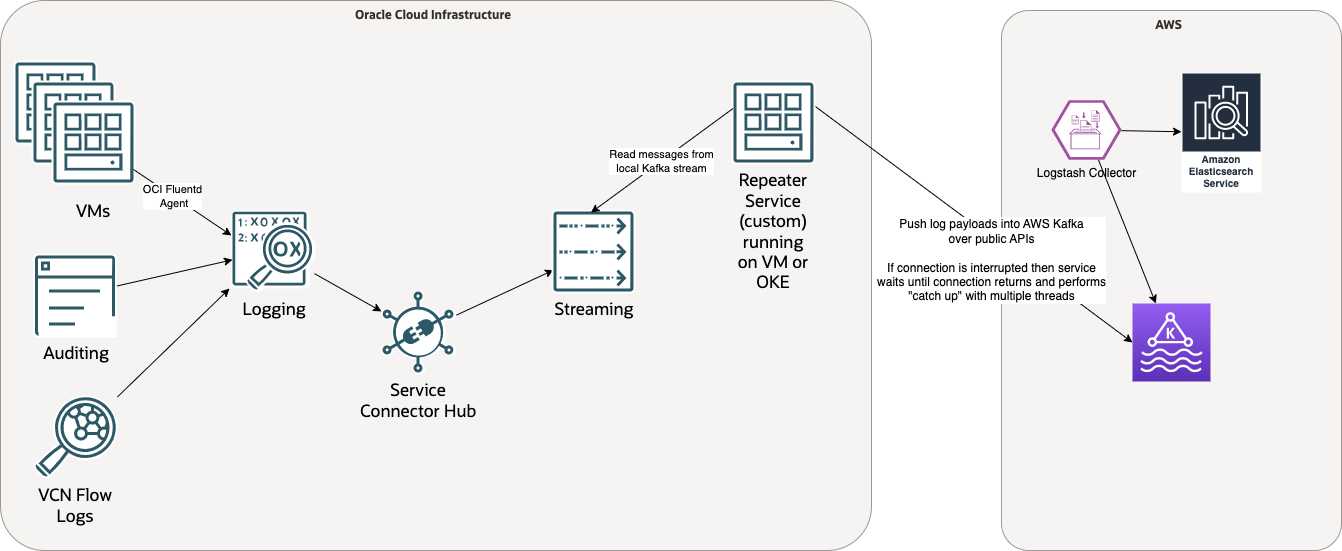
Instead of synchronously calling a function, the Service Connector Hub targets the OCI Streaming service to act as a local, transient store of message data. OCI Streaming is a fully managed, scalable, and durable solution for ingesting and consuming high volume data streams in real time.
A service with a server replaces the serverless function and runs on a VM or as a pod in Oracle Container Engine for Kubernetes (OKE), which acts as a software repeater. On the local side, the repeater reads from the local stream and writes to the stream on the remote side. Any service interruption is recoverable because the repeater code doesn’t advance past a message in the local stream until it receives confirmation that the remote write had succeeded. Even a long outage can be recovered from since the repeater is implemented as a long-running service, and you can adjust the number of concurrent running threads to increase the velocity of message delivery.
The third approach: Loosely coupled pull
While the second approach solved the challenge of defending against loss of connectivity between two clouds, it introduced several layers of cost and complexity that were not present in the first approach, including the following examples:
-
Maintaining two streams (One in OCI and one in AWS) increases cost and administrative overhead.
-
Using a serverful service, instead of a serverless function, introduces the need to care for a VM or Kubernetes cluster. Instead of relying on purely managed services like Logging, Service Connector, and Functions, the customer needs to worry about network configuration, VM patching, and so on.
-
A serverful component introduces constant costs and must be sized appropriately for peak demand. We can also use autoscaling, but implementing it further increases the complexity of the solution.
-
The custom code necessary to write the repeater increases in complexity and requires authoring, versioning, deployment, and maintenance.
To solve these challenges, we redesigned the integration by reversing the flow of control and modeling the system as pull-oriented instead of push-oriented. The following graphic depicts the resulting architecture:
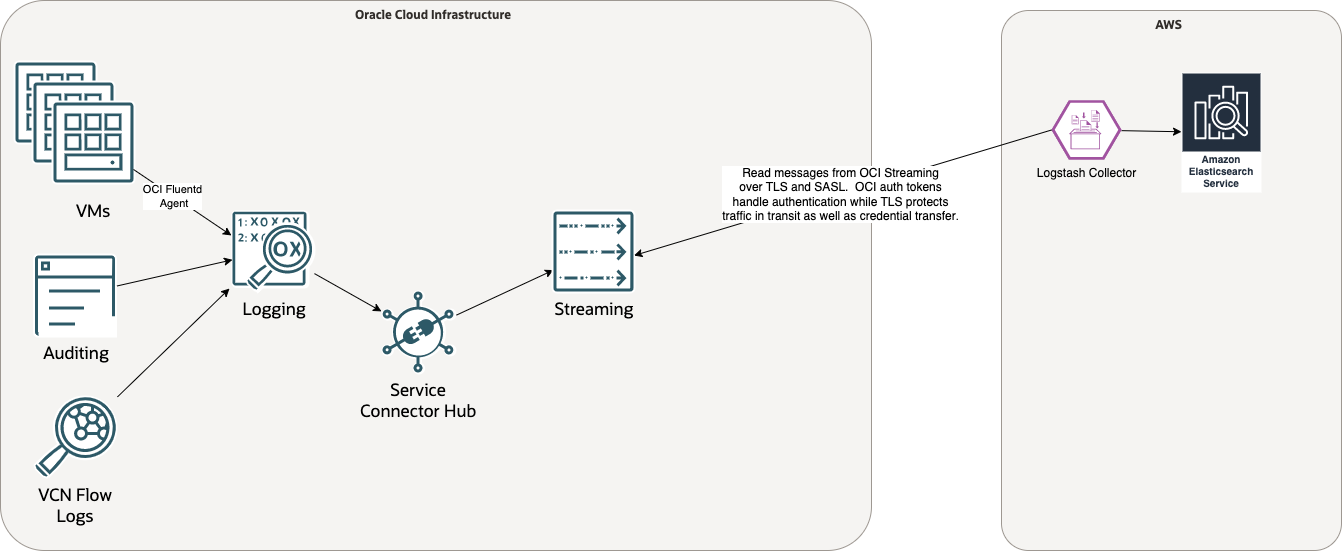
This approach eliminates any custom code and serverful components on the OCI side. OCI Streaming becomes the single source of truth for log streaming data. We can configure the Logstash ingestor to pull data directly from OCI Streaming using Kafka-compatible APIs without writing any custom clients. OCI Streaming supports securing the Kafka stream using the Simple Authentication and Security Layer (SASL) framework operating within a transport layer security (TLS) wrapper. You can achieve this goal by enabling Kafka Connect compatibility mode in OCI Streaming. If the Internet connection between the clouds is down, messages persist in OCI Streaming and Logstash transparently picks up where it left off after service is restored.
This final approach met all the requirements for a resilient, durable, and cost-effective implementation of cross-cloud log integration. We implemented this approach and documented it in this Oracle Help Center tutorial.
Conclusion
You can achieve the same goal in multicloud integrations using many methods, but different architectures can exhibit different characteristics that can impact their appropriateness for various use cases. What works well for a quick proof-of-concept or system where some data loss can be tolerated might not suffice when you need a high level of durability.
For cross-cloud log integration, this blog helps you understand a real-world journey that we undertook with a customer, the various approaches we considered, their trade-offs, and how to implement them using our tutorial content.
For more information using Oracle Cloud Infrastructure services for your use case, see the following resources:


