MySQL HeatWave is a fully managed database service that provides an online transaction processing (OLTP) database, a real-time in-memory data warehouse, in-database automated machine learning, lakehouse, and Generative AI (in private preview) capabilities in a single cloud database service—without the complexity, latency, and cost of ETL duplication. It provides the best performance and price performance in the industry for analytics processing in both data warehouse and lakehouse environments.
With MySQL HeatWave, users can query up to hundreds of terabytes of data from object storage and optionally combine it with transactional data from MySQL databases in a single SQL query. Data in the object store remains in the object store and is not copied to the MySQL database, allowing customers to take advantage of HeatWave for non-MySQL workloads in addition to MySQL-compatible workloads. Querying the data in object storage is as fast as querying the databases—an industry first.

We are happy to share the new and enhanced capabilities that we have recently added to MySQL HeatWave.
Generative AI and vector store
With support for Generative AI, users can interact with MySQL HeatWave in natural language. Both the user queries and the response from the system are generated in natural language using a Large Language Model (LLM). LLMs are trained on public data, and for organizations looking to leverage LLM capabilities for enterprise data, the results can be incorrect due to the hallucination problem of LLMs, and lack of enterprise knowledge. In order to mitigate this problem, we are introducing vector store in MySQL HeatWave.

The vector store uses a language encoder to create vector embeddings from documents in HeatWave Lakehouse which could be stored in variety of formats—.ppt, pdf, text, etc. It also takes the question asked by the user to create vector embeddings and does a similarity search in an n-dimensional space. The output of the vector store is context, included along with the users’ question in the prompt, which is the input to the LLM. The LLM uses this information to generate a response which now includes proprietary information from the documents in MySQL HeatWave. This functionality is currently available in private preview.
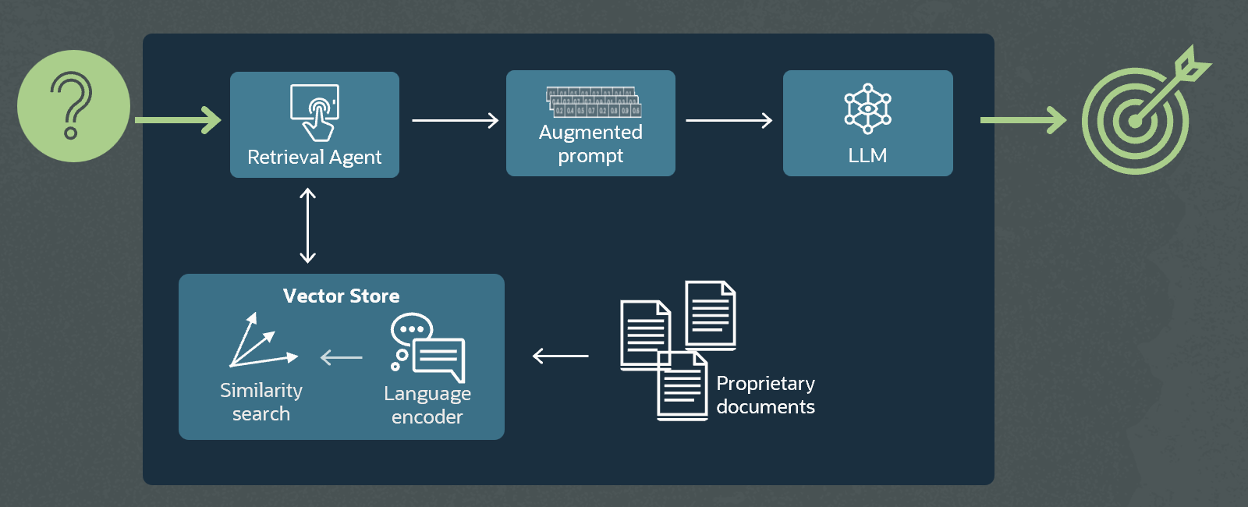
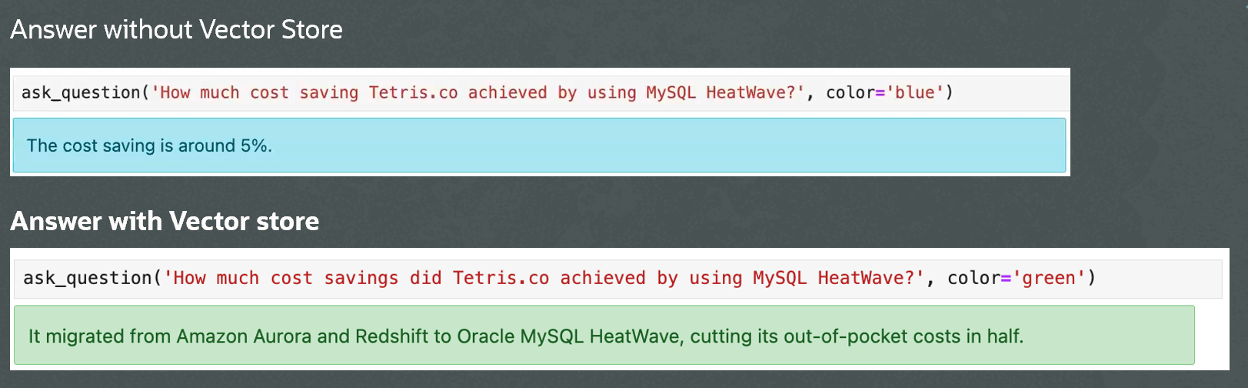
Following are some examples of reponses with Generative AI, both with and without Vector store. In this example, there is a corpus of white papers in .pdf formats stored in MySQL HeatWave that have been ingested by the vector store.

HeatWave Lakehouse is now available on AWS
MySQL HeatWave Lakehouse allows users to load up to half a petabyte of data from object storage into HeatWave and query it along with transactional data from MySQL, in the same query, using standard SQL syntax. With in-database machine learning, data analysts can also train, predict, and explain machine learning models for classification, regression, recommendations, anomaly detection, forecasting, and more using data stored both inside MySQL and in the object store.
The MySQL HeatWave Lakehouse capability is now available natively to AWS customers (limited availability), enabling them to query data in Amazon S3 object storage using HeatWave Lakehouse. Since the service runs entirely within AWS, customers do not incur data egress charges when the data is loaded into HeatWave Lakehouse (provided the customer’s data in S3 and the HeatWave instance are in the same AWS Availability Zone).
HeatWave’s scale-out architecture enables it to scale to hundreds of nodes and query hundreds of terabytes of data. Several file formats, such as CSV, Parquet, and Avro are supported. Customers can also ingest data exported from databases such as Aurora, Redshift, and even MySQL into HeatWave —without requiring users to import the data into the MySQL database.
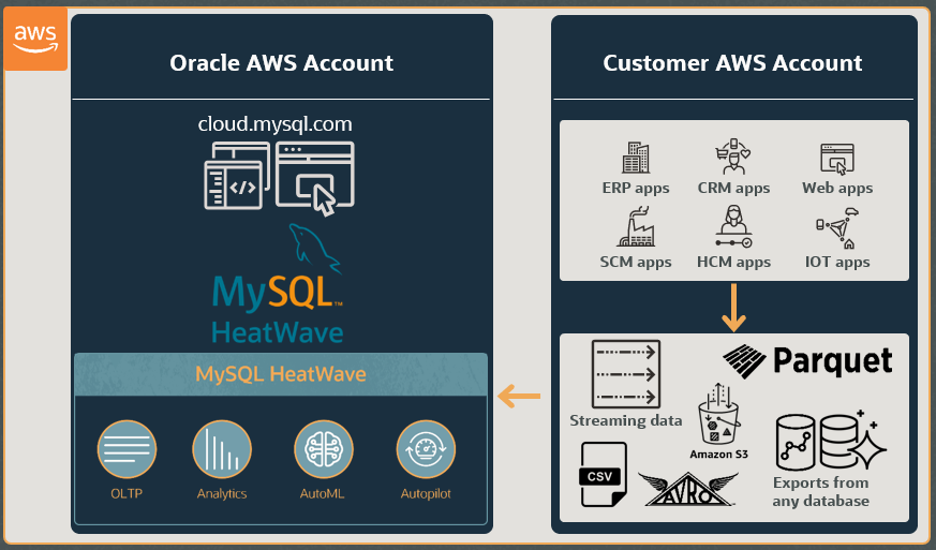
With HeatWave Lakehouse, customers use familiar SQL syntax to query data loaded from S3 and optionally combine it with transactional data stored in the MySQL database.
To address the challenges of loading massive amounts of data efficiently and rapidly, HeatWave Lakehouse uses adaptive, MySQL Autopilot ML-driven techniques. MySQL Autopilot optimizes the network movement of data when loading it from S3, auto-infers the data schema—even for CSV files without metadata, estimates the capacity and time needed to load the data, and more. (See additional enhancements to MySQL Autopilot below.)
Customers that have their data in S3 can now benefit from the same ease-of-use, performance, and price-performance that HeatWave Lakehouse provides in OCI, without moving data out of S3 and incurring potential steep data egress charges.
Loading data from S3 into HeatWave is achieved in four simple steps via an intuitive visual console:
- Provisioning a HeatWave instance.
- Granting HeatWave the appropriate IAM permissions to read data in the S3 bucket.
- Using MySQL Autopilot to map data in S3 object storage to the HeatWave Lakehouse schema.
- Loading data from S3 to HeatWave.
Machine Learning on HeatWave Lakehouse
Customers can now also use HeatWave AutoML to perform machine learning operations on data loaded from object storage on OCI and AWS. They can run predictions and explanations on machine learning models to perform regressions, classifications, predictions, and anomaly detection tasks, generate personalized recommendations, and produce time-series forecasting.
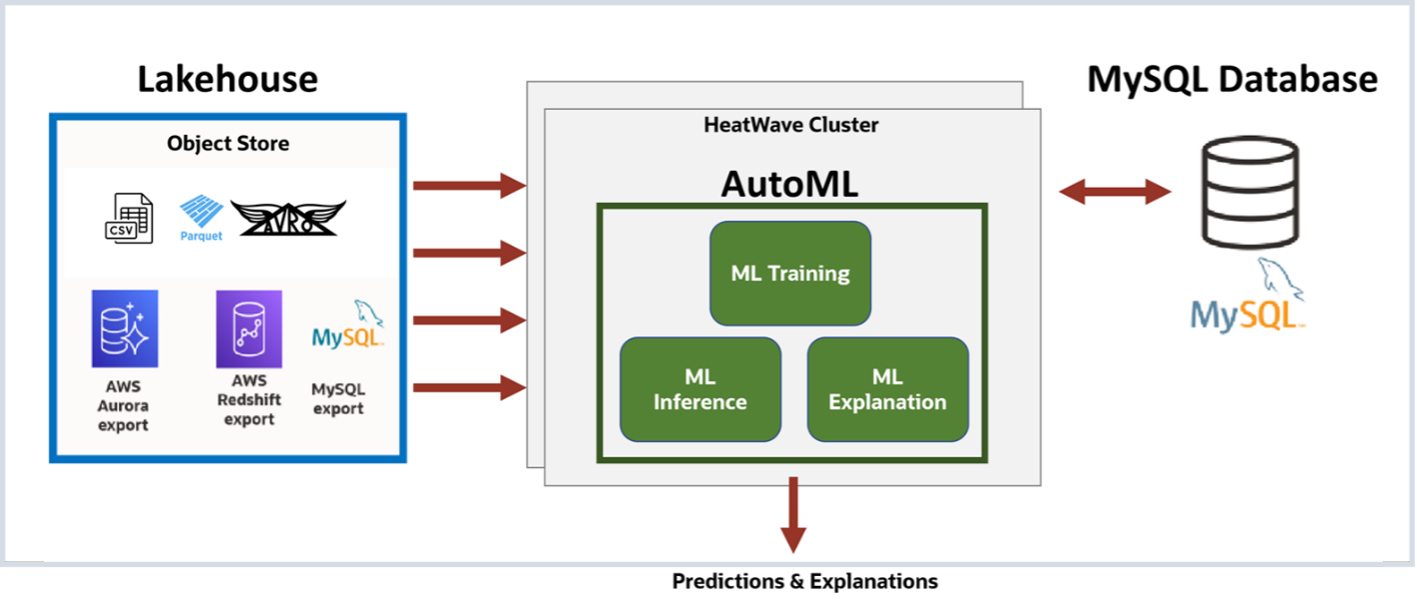
Using HeatWave AutoML, customers don’t need to move data to a separate machine learning service. They can easily and securely apply machine learning training, inference, and explanation to data stored both inside MySQL and in the object store. This provides several advantages:
- Fully Automated: HeatWave AutoML fully automates the creation of tuned models, generating inferences and explanations, thus eliminating the need for the user to be an expert data scientist.
- SQL interface: Provides the familiar MySQL interface for invoking machine learning capabilities.
- Performance and Scalability: The performance of training models with HeatWave AutoML is much higher than other services such as Redshift ML. By training models faster, users can update their models more frequently with changing data.
- Easy Upgrades: HeatWave AutoML leverages state-of-the-art open-source Python ML packages that enable continual and swift uptake of newer (and improved) versions.
- Cost Efficiency: The advanced features of MySQL HeatWave AutoML come at no additional cost for HeatWave customers. In contrast, for AWS customers, Redshift ML and SageMaker (plus S3 storage) are separately charged services.
HeatWave AutoML replaces the laborious and time-consuming tasks that a data scientist typically needs to perform, including:
- Preprocess the data.
- Select an algorithm from a set of candidates to create a model.
- Select only the relevant features to speed up the pipeline and reduce overfitting.
- Select an optimized representative sample of data.
- Tune the hyperparameters of the algorithm selected in step 2.
- Ensure the model performs well on unseen data (also called generalization).

Machine learning pipeline automated by HeatWave AutoML
JavaScript support in MySQL HeatWave
JavaScript is one of the most popular programming languages. Apart from use in website and server-side programming, it is also used as a language for procedural programming in databases. This enables developers to leverage third-party tools and libraries as well as increase the portability of their code.
MySQL HeatWave now supports JavaScript stored programs/procedures (limited availability). This means that queries that call stored procedures written in JavaScript can be accelerated by HeatWave—simplifying the execution of complex operations.
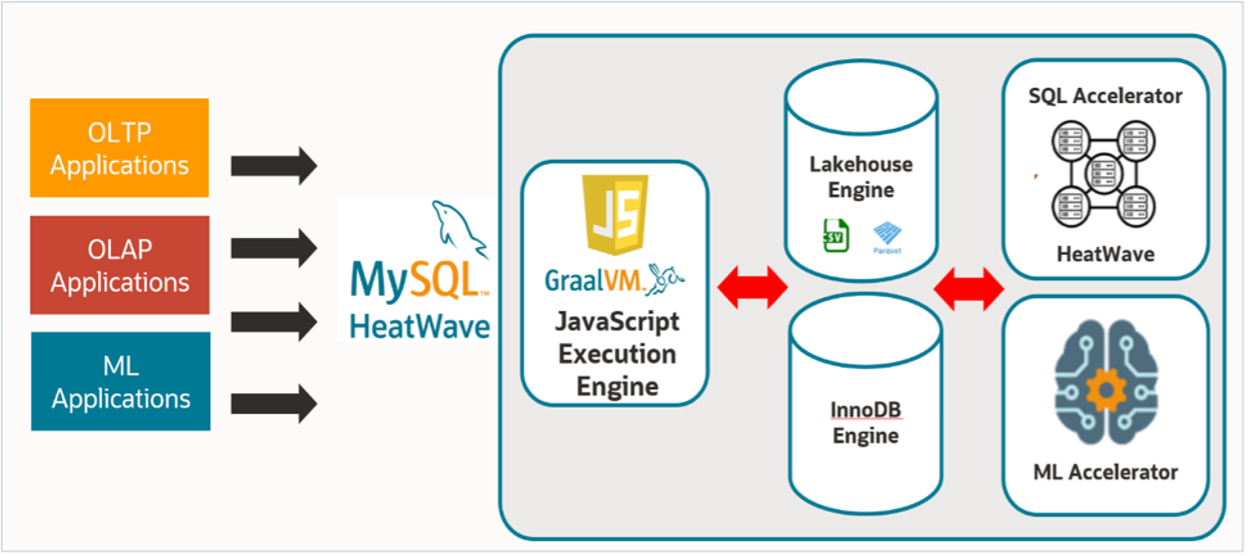
A JavaScript function can be called from SQL statements—in SELECT expressions, WHERE and ORDER BY clauses, DMLs, DDLs, views etc. The new feature also provides an interface to issue SQL queries inside JavaScript, which is particularly useful for JavaScript stored procedures that cannot be invoked inside SELECT, DMLs, and DDL statements.
Both simple SQL statements and prepared statements are supported with full parameter binding support.
The JavaScript runtime is integrated via GraalVM, where the user can use GraalVM’s Enterprise Edition (EE) features, such as compiler optimizations, performance, and security features at no additional cost.
The following features are supported with HeatWave:
- JavaScript language based on ECMAScript 2023.
- MySQL datatypes such as all variations of integers, floating point, temporal and VARCHAR, CHAR types with full utf8mb4 support.
- Data access API based on MySQL Shell JavaScript XDevAPI.
This is an example of a JavaScript stored procedure created in MySQL: 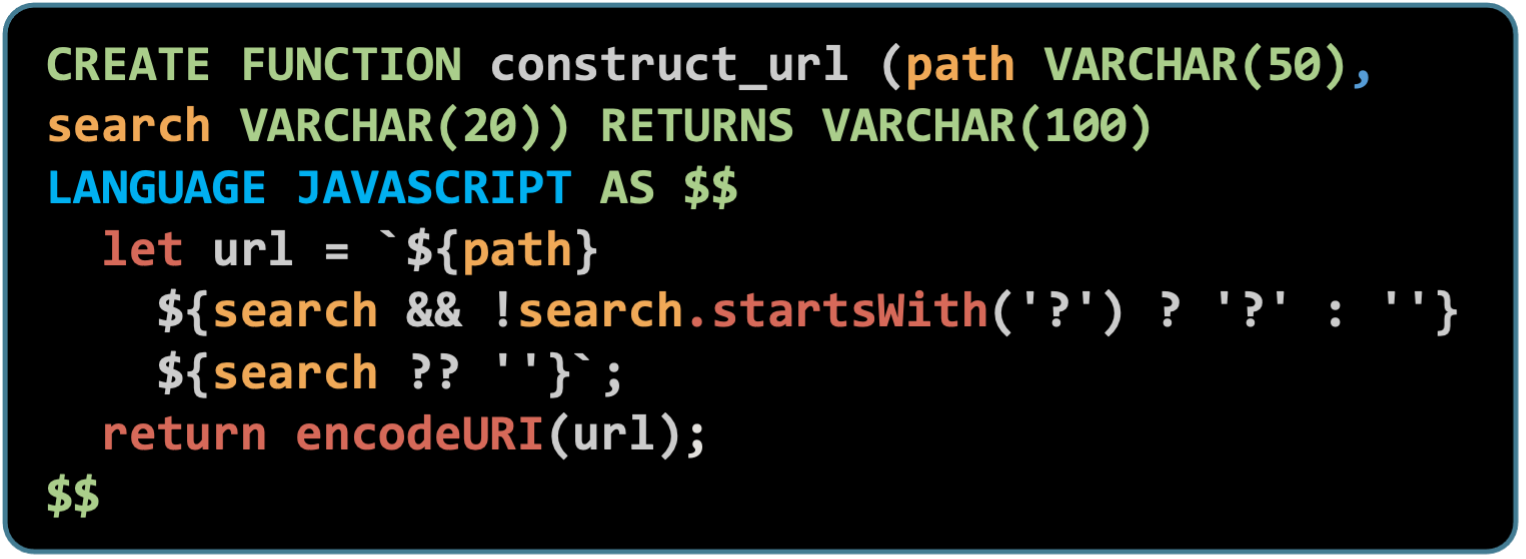
Note that the LANGUAGE clause is used to specify the language of the stored function.
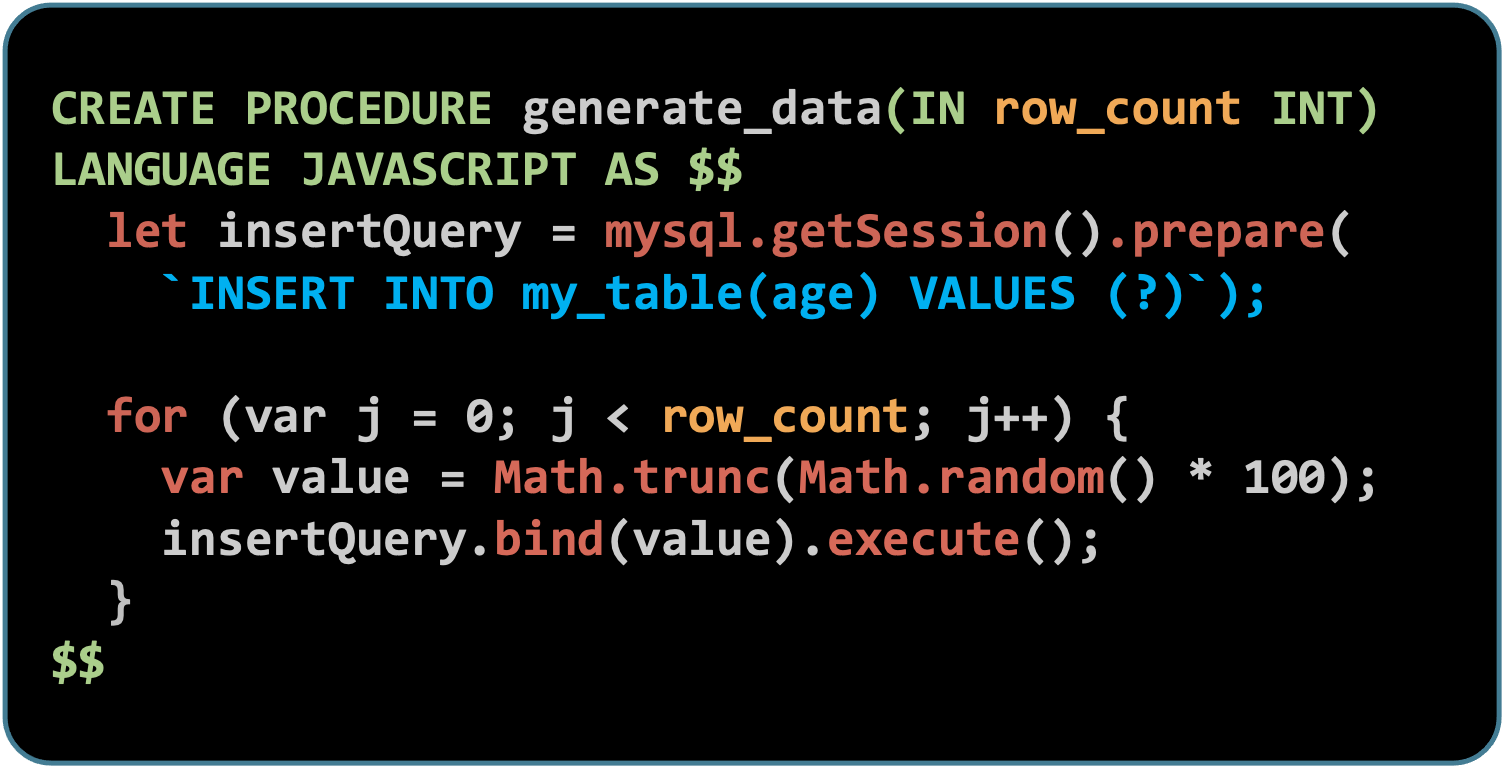
In the example below, a prepared statement generates age data and inserts it into a table, while the second example uses a simple statement to iterate over the rows and sum the age.
MySQL Autopilot Indexing
MySQL Autopilot provides workload-aware, machine learning-powered automation. It automates most of the important and often challenging aspects of achieving high query performance at scale, including provisioning the right cluster size, loading data, querying data, and failure handling. MySQL Autopilot improves performance and scalability without requiring database tuning expertise, increases the productivity of developers and DBAs, and helps eliminate human errors.
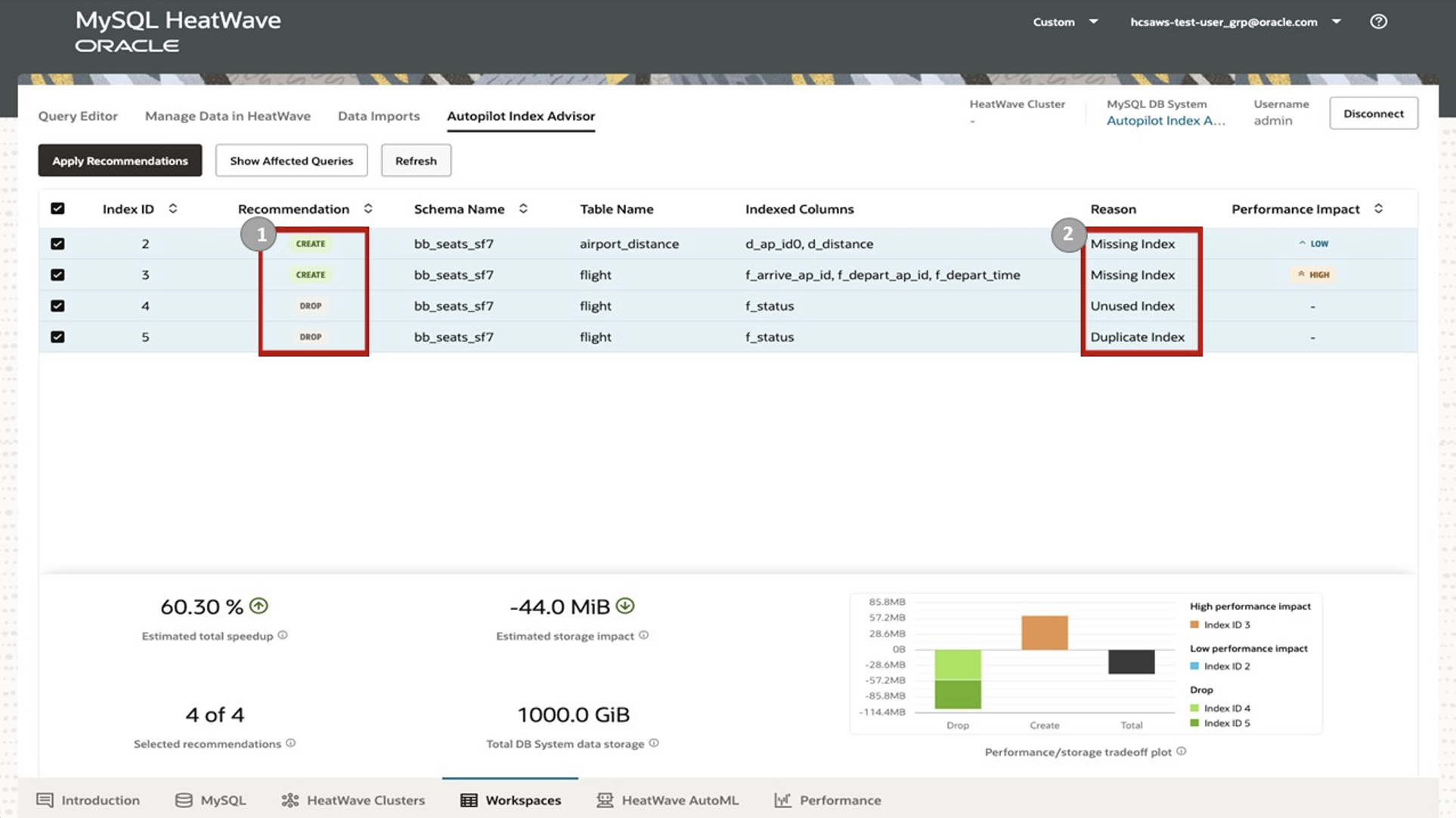
Autopilot Indexing is a new capability we added to MySQL Autopilot, currently in limited availability. It is machine learning-based and further optimizes the database for better performance and reduced cost by making recommendations to create and drop indexes. It helps customers eliminate the time-consuming tasks of creating optimal indexes for their OLTP workloads and maintaining those over time as workloads evolve.
If too few indexes are created, query performance remains low. On the other hand, creating too many indexes causes excessive index maintenance overhead, and can also adversely affect system performance. DBAs need to understand how indexes affect storage, system, and query performance, and know how indexes impact various query constructs like WHERE predicates, JOINs, ORDER BY etc. As query and data workloads change, DBAs need to revisit these index choices.
Autopilot Indexing makes recommendations on secondary indexes to create—since tables in InnoDB storage already have indexes on primary keys. Autopilot Indexing automatically generates secondary index recommendations based on the current workload. It considers both the query performance and the cost of maintaining these indexes. It provides performance and storage estimates as well as explanations for the recommendations it generates. Users can view and analyze the performance and storage impact of index recommendations via an interactive console interface. This makes it easy to see the impact of changes to your database systems before applying the suggestions.
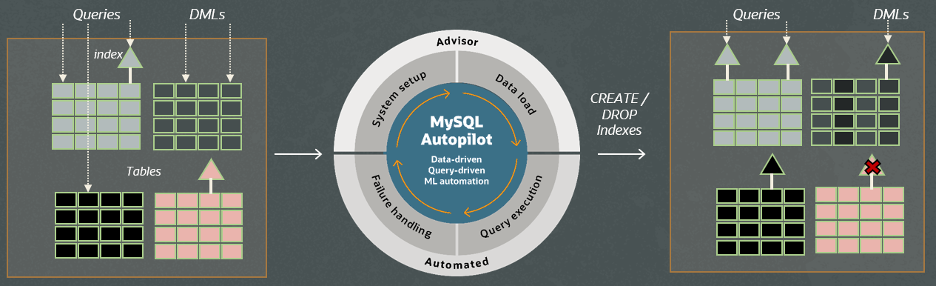
High-level diagram showing a sample user workload and indexes before and after using MySQL Autopilot Indexing.
Autopilot Indexing has a comprehensive set of features that allow the user to tune the performance of database systems, including:
- Considers both query and DML performance (index maintenance cost).
- Recommends CREATE and DROP indexes.
- Generates DDLs for index creation/drop.
- Provides performance prediction (per query and total workload).
- Provides storage prediction for the recommended indexes.
- Provides explanation for the recommendations.
- Console integration to improve user experience.
Invoking Autopilot Indexing
Once a minimum number of queries have been run, Autopilot Indexing can make recommendations on the indexes to be created. Autopilot Indexing evaluates these queries, determines if their execution is sub-optimal, and if they can benefit from an index. Index recommendations are provided along with the estimated storage and performance impact, as well as explanations for the recommendations. If the workload dataset is very small, or if the current set of indexes are sufficient, Autopilot Indexing may not recommend any additional indexes. Autopilot Indexing can be invoked either via the interactive console on AWS or via command line on OCI.
Autopilot Indexing User Interface
In the Autopilot Indexing Advisor console available on AWS (image below), you can see four recommendations: two for creating indexes and two for dropping indexes, along with the reasons for each recommendation. The last column, labeled ‘Performance Impact’, provides an assessment of each of the actions—creating or dropping indexes. Users can now take action based on the recommendations shown on the console.
JSON acceleration with MySQL HeatWave
JSON (JavaScript Object Notation) is a standard text-based format for representing structured data based on JavaScript object syntax. It’s one of the most popular standards for data interchange.
MySQL HeatWave now supports the acceleration of queries that reference JSON data types, accelerating performance by several orders of magnitude. No changes to applications are required, nor is there a need to create any indexes for speeding up queries.
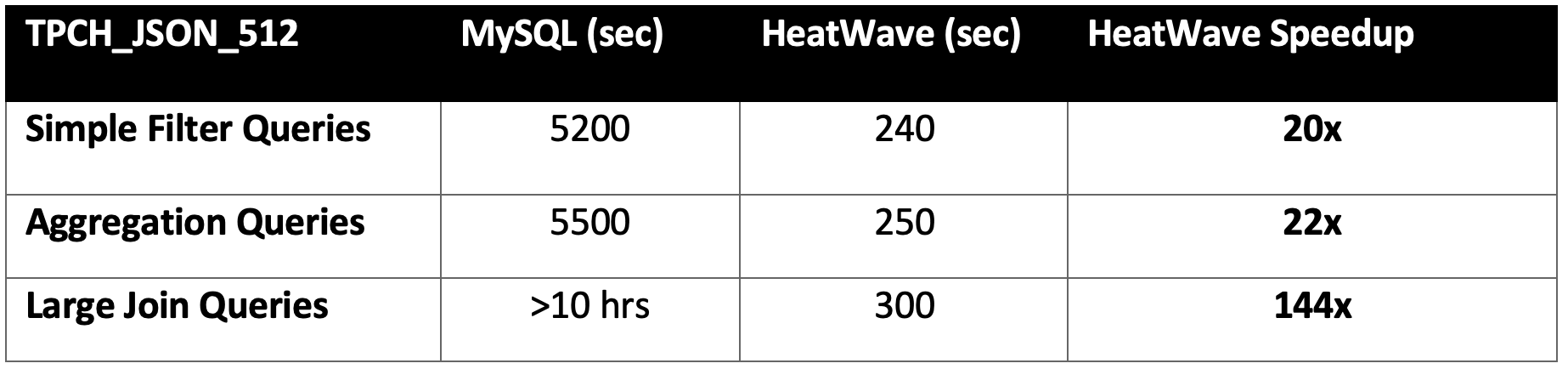
With JSON acceleration in HeatWave, queries with simple filters as well as queries with aggregations run 20X faster, while queries with large joins run 144X faster.
Native JSON Support in HeatWave
To efficiently store and process JSON data, HeatWave introduces its own native JSON data type format. It is a binary and compressed representation of JSON. This JSON column is managed like any standard column and is stored in a hybrid-columnar representation in HeatWave memory. Similarly, any updates in the JSON data stored in MySQL will automatically be propagated to HeatWave without user intervention. During query processing, JSON operators are executed directly on compressed binary representation of the JSON data structures.
The following JSON functions are currently supported in HeatWave:
- JSON_EXTRACT()
- ->> which is equivalent to JSON_UNQUOTE(JSON_EXTRACT())
- -> which is equivalent to JSON_EXTRACT()
- JSON_OBJECT()
- JSON_UNQOUTE()
- JSON_ARRAY()
- JSON_LENGTH()
- JSON_DEPT()
With these enhancements, Oracle continues the innovation stream for MySQL HeatWave to address customer challenges.

Additional Resources:
