Oracle Cloud Infrastructure (OCI) Data Flow is a fully managed Apache Spark service capable of processing petabyte scale datasets. While the DNA of the OCI Data Flow is serverless, where we typically provision the underlying infrastructure on-demand and in parallel by default, our customers have been increasingly asking for more control over the Spark infrastructure for various use cases. Some customers want better startup times for their service level agreement (SLA)-bound production jobs. Some want to schedule their daily jobs in a warmed up Spark infrastucture ahead of time to eliminate any capacity related uncertainties during peak usage, while some simply want to submit back-to-back jobs in the same Spark infrastructure instead of deploying and setting up separate resources on demand. To enable all those controls for our customers, we’re pleased to announce the general availability of Data Flow pools.
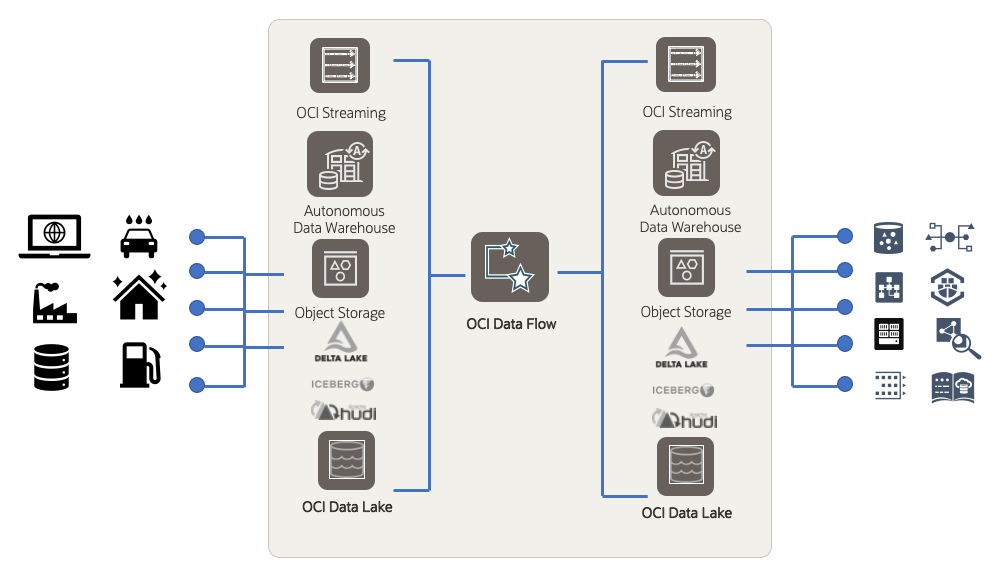
What Data Flow pools can do
A Data Flow pool is a group of preallocated compute resources that you can use to run Data Flow-based Spark workloads with faster startup times. We’ve designed Data Flow pools for all Data Flow user personas: analysts, developers, and data scientists. Data Flow users expect their clusters and notebooks to start quickly, process the runs efficiently, and in many cases terminate automatically when the runs are finished and their cluster is idle for a certain amount of time.
Pools takes care of all these factors: They help improve the startup times of Data Flow runs and notebooks, enable easier governance and separation of development, test, and production environments by directing Spark jobs to specific Data Flow pools, provide more control over cost, and usage separation, and improves cost efficiency by terminating idle resources. You can still run Data Flow applications without pools, but the resources required for those runs are only provisioned on demand or after the run is submitted, typically leading to slower start up times.
Data Flow pools allow you to configure one or multiple pools with support for both homogenous and heterogeneous shapes in the same pool. You can run them on a schedule and have them terminate based on idle times. You can submit one or multiple Data Flow runs on the same pool at the same time. Data Flow runs are queued if all the shapes are in use. Pools serve various use cases, including the following examples:
-
Time-sensitive large production workloads with many executors, which need faster startup times
-
Separation of production and development workloads. Critical production workloads aren’t competing with development workloads for dynamic allocation resources because you can now configure them to run on different pools.
-
Cost and usage separation between development and production workloads with Identity and Access Management (IAM) policies that lets you submit specific Data Flow runs to specific pools.
-
Process many Data Flow runs back-to-back with less startup time.
-
Queueing Data Flow runs in a pool for efficient use of resources and cost control.
-
Automatic start of pools based on a schedule
-
Automatic termination of pools based on specific idle times
-
Automatic security patching without affecting runs or resources in a pool
How to set up a pool
You can create a Data Flow pool using the Oracle Cloud Console, CLI, and API. In the Console, you can navigate to Data Flow pools by selecting Analytics and AI in navigation menu and, under Data Lake, click Data Flow. On the Data Flow page, click Pools in the menu.
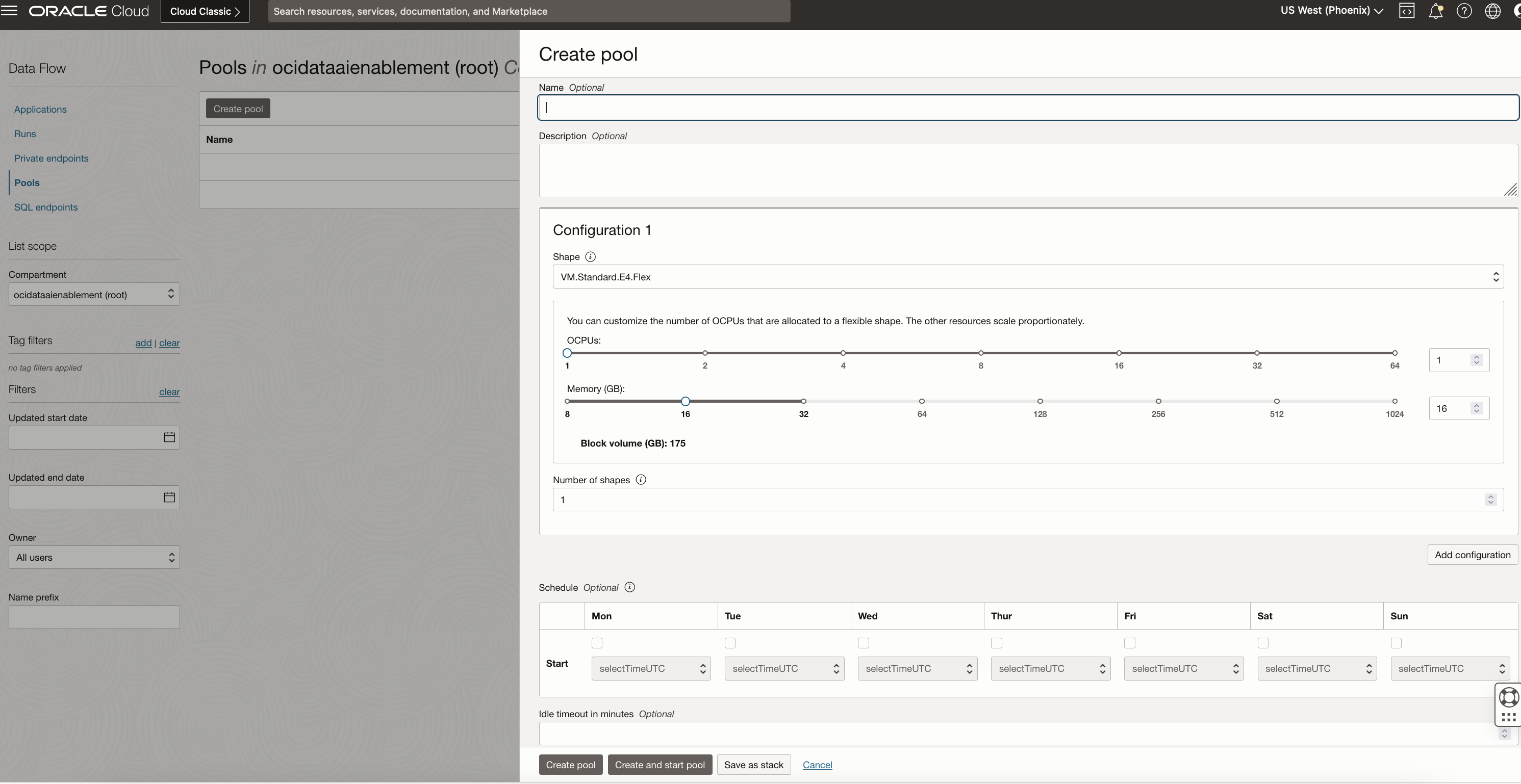
To create a pool, provide a name, description Compute shape and number (minimum 2), and optional schedule and timeout value. During the creation of pools, you can also choose to start manually immediately or schedule it for automatic start later. You can also save the pool configuration as a stack.
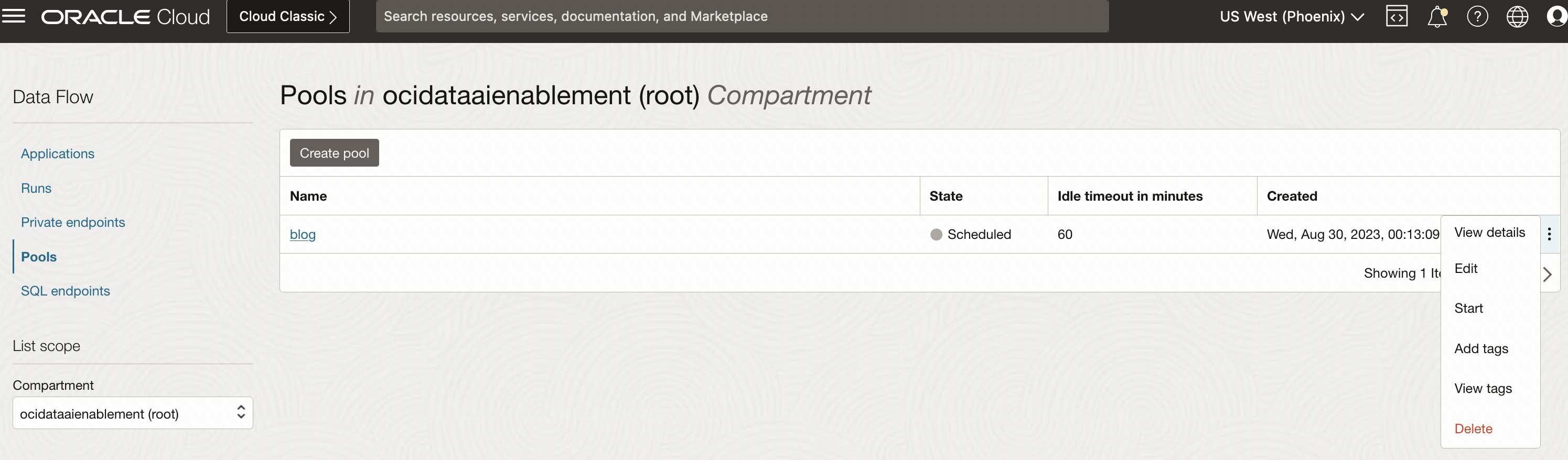
After a pool is created, you can start and stop it manually or based on a schedule. You can only edit the configurations of a pool while it’s in Stopped or Failed states. You can also start stopped or accepted Data Flow pools by submitting a run to that pool. You can create multiple pools based on your requirements.
Want to know more?
The pools functionality is critical because the scale of mission critical workloads is increasing exponentially in Data Flow and the teams collaborating in building, running, and using Data Flow based data platforms are also growing. Data Flow pools enable faster and more efficient development and better, more predictable latency of runs leading to better application SLAs. To learn more about Data Flow pools, join us at the Oracle CloudWorld 2023 session, Build an Intelligent Data Lake for Your Enterprise Data Platform.

