Hello, my name is Zachary Smith, and I’m a Solutions Architect working on Big Data for Oracle Cloud Infrastructure. You might have seen my previous blog post, Deploy Hadoop Easily on Oracle Cloud Infrastructure Using Oracle Resource Manager. Today, I’d like to share a solution that enables cross-regional Hadoop Distributed File System (HDFS) access to Oracle Cloud Infrastructure Object Storage by using our S3 Compatibility API.
The Issue
Some applications that can’t use the HDFS Connector for Object Storage have configuration issues when they try to access Object Storage by using the S3 Compatibility API. These issues occur because several things need to match when requesting access. One of these is the target regional endpoint for Object Storage access, which is also encoded into the customer secret used for authentication. If these endpoints don’t match, or a default region is specified (like us-east), then the customer tenancy home region is used as the default.
Many Hadoop distributions encounter this problem. Unfortunately, they can’t be directed to use a specific regional object store, which then “region locks” the deployment, and breaks multiple-region disaster recovery scenarios.
The Solution
I’m happy to share a solution that bypasses this limitation by using two tenancies and VCN Peering. I present two scenarios here, with the technical steps to implement them.
Local VCN Peering
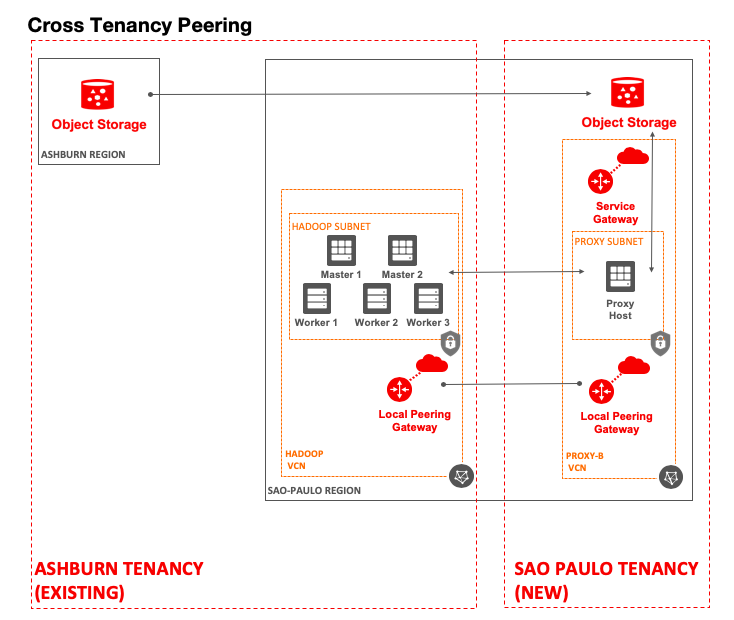
In this scenario, the customer (you) started working on Oracle Cloud Infrastructure in the US East (Ashburn) region. You have pushed data into Object Storage in the region and done some proof-of-concept work with a Cloudera Hadoop cluster. You then begin planning a production deployment in another region, Brazil East (Sao Paulo), and have requirements to access Object Storage in both the US East region and the Brazil East region from the same Cloudera Hadoop cluster.
The solution is to have a second tenancy in another region, using customer secret keys that are unique to each tenancy, along with VCN peering and the S3 HDFS Proxy.
After you have a second tenancy, you set up secret keys in the new tenancy for the Brazil East region. Then, you create a VCN in the new tenancy, with a subnet and a Linux host to act as a proxy.
Next, you add policy statements to each tenancy. This task is detailed in the local VCN peering documentation, “Task C: Set up the IAM policies (VCNs in different tenancies).”
You also need to augment the policy with statements to allow access to Object Storage in both regions. This task is detailed in a blog post by my colleague, Sanjay Basu.
After all the policies are in place, you can then set up the local peering gateways in each VCN and connect them. These steps are detailed in the local VCN peering documentation, “Task D: Establish the connection.”
With these VCNs now peered, hosts in the Hadoop VCN should have connectivity to the proxy host in the new tenancy. This proxy host can run any kind of proxy (Tinyproxy is easy). After the proxy is installed and running, the Hadoop cluster can use it with the customer secret keys from the new tenancy to access the Object Storage S3 API in the new region. The default HDFS fs.s3a.endpoint and fs.s3a.proxy.host parameters can be configured or passed at job submission.
The following diagram shows this data flow.
Remote VCN Peering
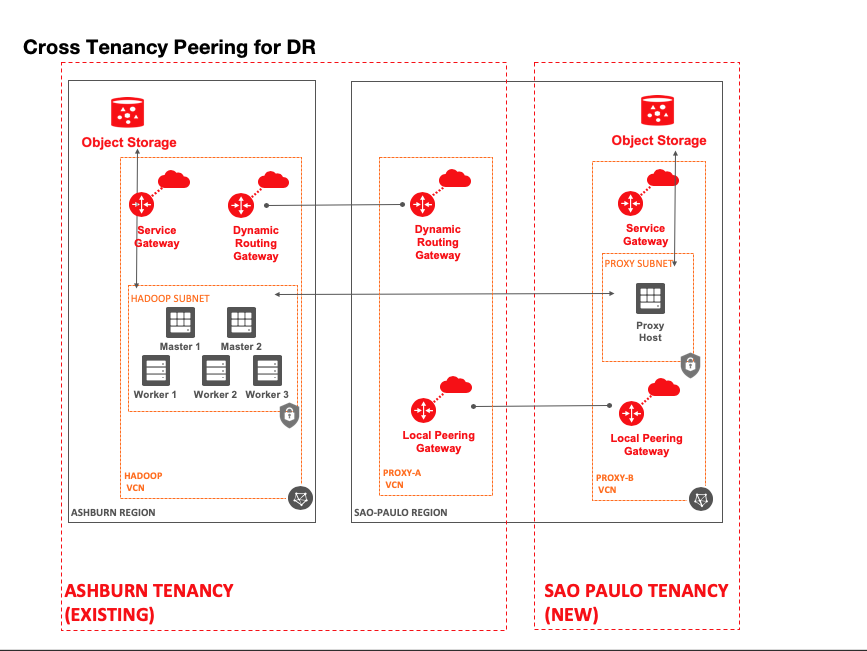
In another scenario, you have infrastructure in one region and want to access object data in another region. The solution is similar, but it requires the addition of a third VCN. The source VCN in one region would have a dynamic routing gateway (DRG) that connects to a DRG in the (proxy-A) VCN, in the target region, in the same tenancy. The proxy-A VCN then uses local VCN peering as described previously to access the proxy-B VCN in the new tenancy.
The steps for regional VCN peering are detailed in the documentation.
This is a great solution for customers who want to enable disaster recovery (DR) but are limited by their application’s configuration. In the case of Hadoop, Object Storage in another region is a great choice for backing up critical data. If a disaster occurs, a cluster in the remote region in the new tenancy can easily re-create itself from backup data that was copied using this solution.
The following diagram shows this data flow.
Oracle Cloud Infrastructure offers the best price/performance option for Big Data workloads. If you’re running Hadoop on premises or in another cloud, consider trying out Oracle Cloud Infrastructure for Big Data workloads in the cloud. Learn more about the price/performance advantages of Oracle Cloud Infrastructure and Big Data, and try it for yourself with our free tier of services.
