Generative AI models have dazzled us with their ability to summarize and answer questions, create software, and even write poetry. These tools have practical implications for industries like financial services, where they can be used in risk identification, fraud protection, and customer service. In life sciences, they can aid in drug discovery, development, and even clinical trials. However, most organizations have yet to take advantage of systems based on these models.
The reason is complicated. The amount of compute power, data, and knowledge required to build a proprietary generative AI model creates an enormous resource challenge for many organizations. People have justifiable concerns about how these models work and what becomes of the business data used to train these models, especially for enterprises. Here, MosaicML and Oracle AI can help. MosaicML’s platform is designed to make it as easy as possible to train and deploy deep learning models, so more enterprises can take advantage of this transformative technology on Oracle Cloud Infrastructure (OCI) and other cloud providers.
This blog post breaks down the obstacles to adoption and explains why the MosaicML platform on OCI is the best solution for enterprises that want to operationalize generative AI. We focus on a class of deep learning models, known as foundation models. One subset of these models are large language models (LLMs) that power services like ChatGPT.
Deep learning and foundation models
A deep learning model is a computer program that you can teach to perform specific tasks by feeding it a vast amount of data—not once, but repeatedly—in a process called training. The result is a tool that can be queried about a vast number of topics and accessible through an application programming interface (API).
Foundation models trained on large, diverse datasets can automatically learn features and develop emergent capabilities. They can generate new content for a wide range of applications, which is why they’re commonly referred to as generative AI. What makes foundation models different from other deep learning models is that they’re trained in a self-supervised manner. Specifying what the model should learn isn’t necessary because of the many provided, prelabeled examples. We can further optimize the accuracy of a trained model for industry use cases by training on domain-specific datasets.
Resource challenges for model training
Training a foundation model requires three key resources: Models, data, and compute. Each resource presents a unique set of challenges for enterprises to tackle before they can operationalize generative AI.
Models
At the core, a generative AI is a mathematical model capable of learning abstract representations of data. A given deep learning model has an associated set of weights, or parameters, that are adjusted during the training process to learn various features of the input data. The number of parameters a model contains is typically referred to as the size of the model.
Various model architectures exist, depending on the modality of the tasks. For example, the generative pretrained transformer (GPT) is a common architecture for LLMs, capable of learning from text data. A given model architecture can contain millions, billions, or even trillions of parameters with potentially hundreds of other attributes that you can use to further customize and optimize the model.
Data
Training a high-quality LLM requires a massive volume of diverse text data. The larger the model, the more data is required to train it. To obtain this large volume of text, a common method of creating public datasets of this scale is to trawl the internet, which can have significant legal implications for commercial use.
Model quality can greatly improve by further training models on domain-specific data, a process we call domain-tuning. Ultimately, we end up with multiple open and proprietary terabyte-scale datasets, which must be securely stored, maintained, and repeatedly accessed.
Compute
To train models and process data at the scale we’ve been discussing, we need nothing short of an AI supercomputer, such as an OCI Supercluster. The supercomputer requires hundreds of specialized hardware accelerators, such as NVIDIA GPUs, all connected with high-performance networking at data center scale, powered by NVIDIA ConnectX SmartNICs. LLMs must train for several weeks or months on these supercomputers.
Building this complex infrastructure cost-effectively is extremely difficult. It requires experts who possess a deep understanding of various machine learning (ML) frameworks and tools and know how to efficiently utilize these accelerators. You must provision and maintain the computing resources, requiring complex tools to enable orchestration and coordination across multiple users. At scale, hardware failures are common, placing an even greater burden on IT departments to manage bespoke resources and diagnose complex issues.
Training generative AI, such as LLMs, is expensive and complicated. For this reason, most generative AI companies devote most of their resources and expertise to training a single model, then sell commoditized services around the capabilities of that model. Some of these companies even let you domain-tune their models to improve quality. They deal with the complexities of training and host the model behind an API while you access the benefits and get billed by use. Problem solved, right?
Business data and third-party APIs
While a third-party API might work well for some enterprises, it’s a non-starter for businesses constrained by strict export policies of business data. Healthcare companies are legally bound to protect patient records. Financial institutions must comply with SEC regulations around sensitive financial information. Innovative technology companies need to protect their intellectual property from leakage. These enterprises can’t easily supply their data to third parties, no matter how capable the model is.
Another complication with third party models is ownership. Many of the generative AI companies provide customization services that allow their models to be domain-tuned to improve quality. However, they still retain model ownership and access to the domain-tuned parameters, creating a host of concerns around vendor lock-in and future usage.
MosaicML platform

Figure 1: MosaicML platform architecture
MosaicML was founded on a basic tenet: A company’s AI models are as valuable as any other core IP. The MosaicML platform was built to enable companies to maintain control of their data and ownership of their models with no strings attached. Let’s dive into how the MosaicML platform on OCI solves the barriers to operationalizing generative AI for the enterprise.
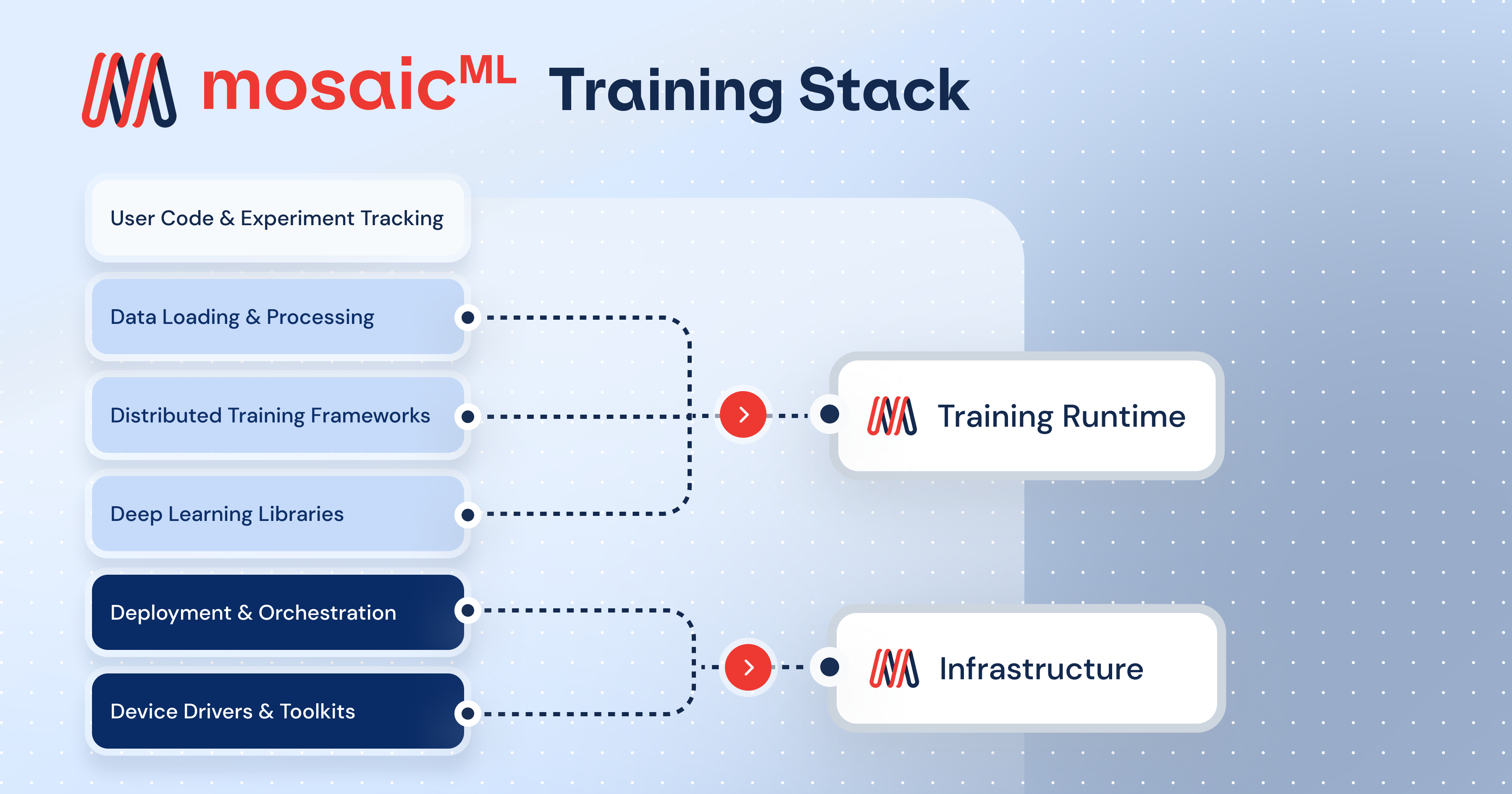
Figure 2: MosaicML platform training
The platform stack begins with state-of-the-art generative AI models. It provides easy-to-use, optimized model code and examples for large language and diffusion models. The models can be trained from scratch and come with proven training recipes crafted by world-class researchers. MosaicML also provides high-quality, pretrained checkpoints trained on diverse datasets to help you get started quickly. You can domain-tune these checkpoints on proprietary data to maximize model quality for specific use cases. You can also quickly port and train all open source, off-the-shelf, and proprietary models on the MosaicML platform.
Training a state-of-the-art model requires a framework that can feed training data to a model and implement the algorithm used to update the model’s weights during the training process, all while efficiently using compute resources. MosaicML’s Training Runtime uses the following major components to accomplish this goal:
-
Composer training library: Tested, high-performance, scalable training framework
-
StreamingDataset library: Fast, efficient data loading from any cloud object storage
-
Training Docker images: All necessary software packaged as Docker images
Together, these components make the MosaicML training runtime the most versatile and only truly cloud native runtime available for training models. Composer is a powerful and extensible trainer capable of scaling seamlessly to multiple accelerators and offers all the tools required to train a deep learning model. Composer can also load and store artifacts from cloud storage, enabling the training runtime to be deployed on any cloud.
StreamingDataset lets you stream data securely to any compute location without impacting performance. The training runtime is conveniently packaged as a Docker image that includes Composer, Streaming, and all other software needed to make training work efficiently.
Managing the vast amounts of compute infrastructure needed to train a generative model requires a sophisticated framework. The goal is to abstract away the complexity of provisioning and orchestrating compute resources and enable you to easily submit runs. To accomplish this aim, the MosaicML platform infrastructure layer is split into three parts: Client interfaces, the control plane, and the compute plane. Users interact with the platform through a simple Python API, command line interface (CLI), or a web console. The control plane manages the orchestration of the computing resources required to perform model training. It also monitors for errors and faults, enabling automatic run recovery. The stateless nature of the compute plane contains the physical accelerators that perform the training run but doesn’t persist any user data.
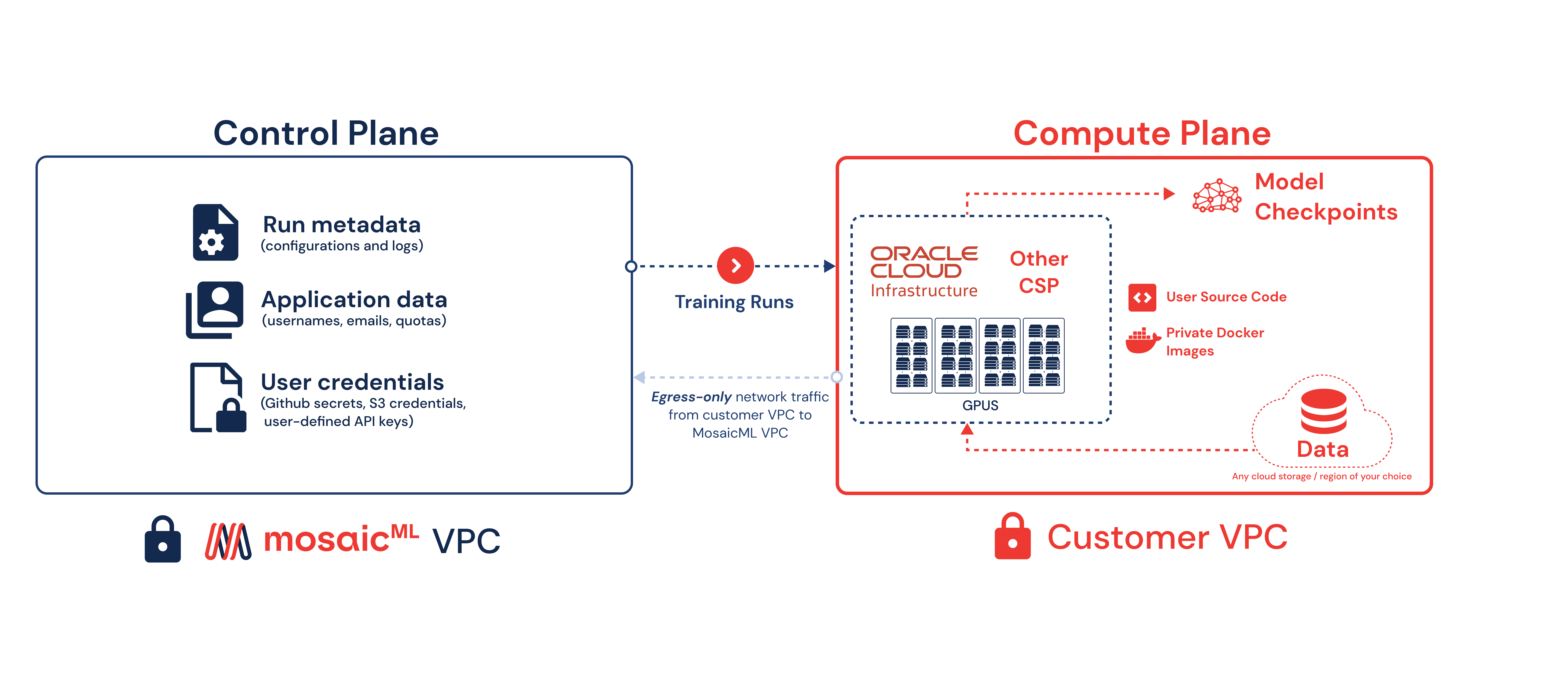
Figure 3: Interaction between the control plane and stateless compute plane
The MosaicML platform architecture ensures that critical business data is kept isolated and secure while offering the flexibility for compute resources to live in the customer’s cloud of choice, on multiple clouds or in the on-premises data center.
OCI AI
Training LLMs requires a high-performance network for coordinating and sharing information across hundreds or thousands of independent servers. NVIDIA GPUs on OCI are connected by a simple, high-performance ethernet network, powered by NVIDIA ConnectX SmartNICs, using RDMA over Converged Ethernet v2 (RoCEv2). The bandwidth that OCI provides exceeds both Amazon Web Service (AWS) and Google Cloud Platform (GCP) significantly, which in turn reduces the time and cost of ML training.
OCI includes numerous capabilities for AI, including AI infrastructure. OCI Compute virtual machines (VMs) and bare metal NVIDIA GPU instances can power applications for computer vision, natural language processing (NLP), recommendation systems, and more. For training LLMs at-scale, OCI Supercluster provides ultra-low-latency cluster networking, high-performance computing (HPC) storage, and OCI Compute bare metal instances powered by NVIDIA A100 Tensor Core GPUs and ConnectX SmartNICs.
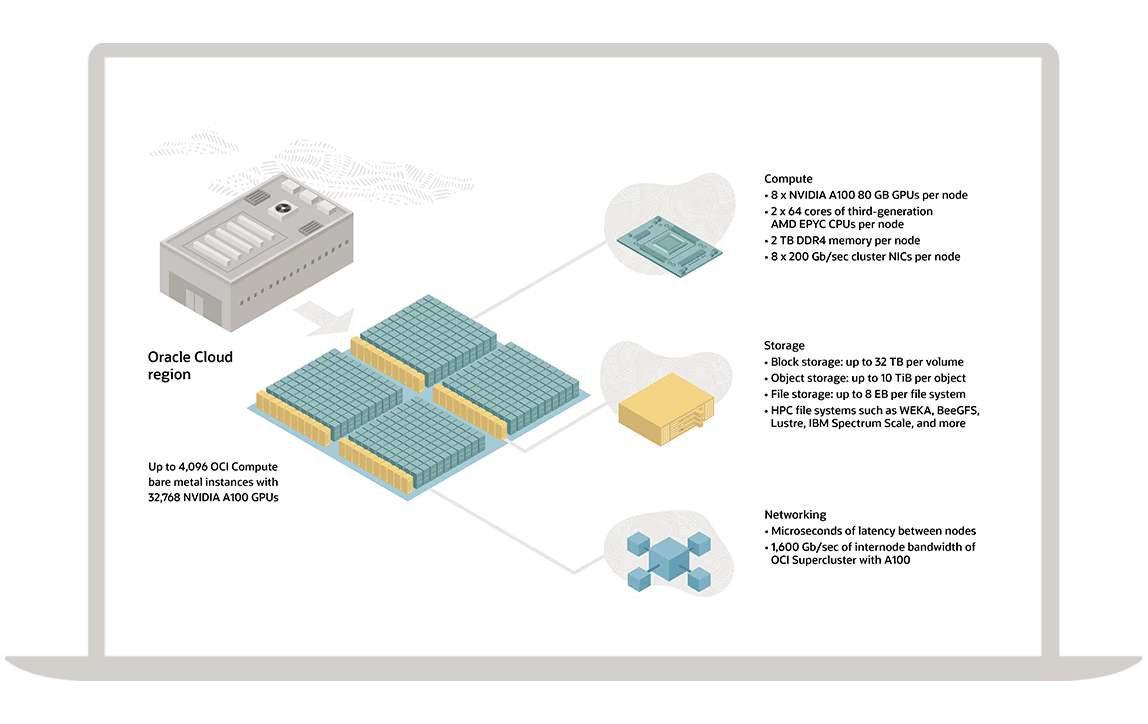
Figure 4: OCI Supercluster
MosaicML and OCI, better together
The MosaicML platform powered by OCI offers you the highest-performing, cost-effective, enterprise-ready, full-stack solution for training generative AI models. With the fastest GPU accelerators and ethernet networking from NVIDIA, OCI offers the following benefits:
-
Competitive prices for AI infrastructure
-
High-bandwidth supercluster network enabling fast data movement across accelerators and strong performance scaling
-
Large compute block sizes for scaling to thousands of GPUs
-
No egress fees within OCI for data streaming from Oracle Cloud Storage
MosaicML’s models with StreamingDataset and Composer can take full advantage of the latest NVIDIA GPUs, fast interconnections, and large block sizes to train models quickly and successfully. You can host large datasets on OCI storage and stream cost effectively to training on OCI Compute resources. Together, MosaicML and OCI enable all enterprises to realize the power of generative AI.
Want to know more? Contact us and get a demo of the MosaicML platform on Oracle Cloud Infrastructure. For more information, see the following resources:

