Today, data powers everything, and enterprises depend on data for their success. Data protection is one of the highest priorities for businesses. This blog reveals how Oracle Cloud Infrastructure (OCI) designed the highly durable Object Storage service to prevent data loss.
OCI Object Storage exceeds 99.999999999%, or 11 nines, durability. For customers, this statistic means the probability of data loss is less than one out of a million objects in 10 years. Commodity disks are expected to have a failure rate of 1% over a period of one year, so in an OCI region with exabytes of data, this ratio amounts to many disk failures every hour. With such high scale and high hardware failure rate, OCI had to make savvy architectural decisions to prevent any data loss. How does OCI exceed 11 nines durability with disks that have two nines durability?
This video walks through the challenges pertaining to durability and how OCI prevents data loss at cloud scale efficiently.
Durability
Data durability means not losing data even when the underlying hardware fails. OCI’s internal goal is to maintain zero data loss. Achieving high durability requires focus on the following areas:
-
Redundancy: Storing redundant data to survive multiple concurrent hardware failures
-
Failure isolation: Spreading redundant data across distributed locations so that single failure event can’t cause irrecoverable data loss
-
Fast recovery: Automatically recovering from hardware failures quickly
Redundancy
In a cloud storage service, customers need access to data even when one or more copies of the data aren’t accessible. Object Storage is designed to handle 3–5 concurrent disk failures for the same object by storing redundant copies of object data. Storing copies of exabytes of data becomes expensive and so Object Storage stores data using an efficient storage technique called erasure coding. The video explains erasure coding in detail, the tradeoffs for tuning the parameters of erasure coding, and scenarios where simple data mirroring is better.
Failure isolation
What’s the use of data redundancy if we lose access to all copies of data? A single failure like one data center outage can cause large amounts of data to be inaccessible. To eliminate customer impact from various failures, data is stored across separate disks on separate servers in separate data centers within a region. If there a disk or host failure or entire data center fails, other copies of data are available.
Object Storage is designed to allow 3–5 concurrent disk failures of the same object. Figure 1 shows that the data is divided into extents and how the data that is on the first disk in DC1 is distributed in separate disks on separate servers in separate data centers.
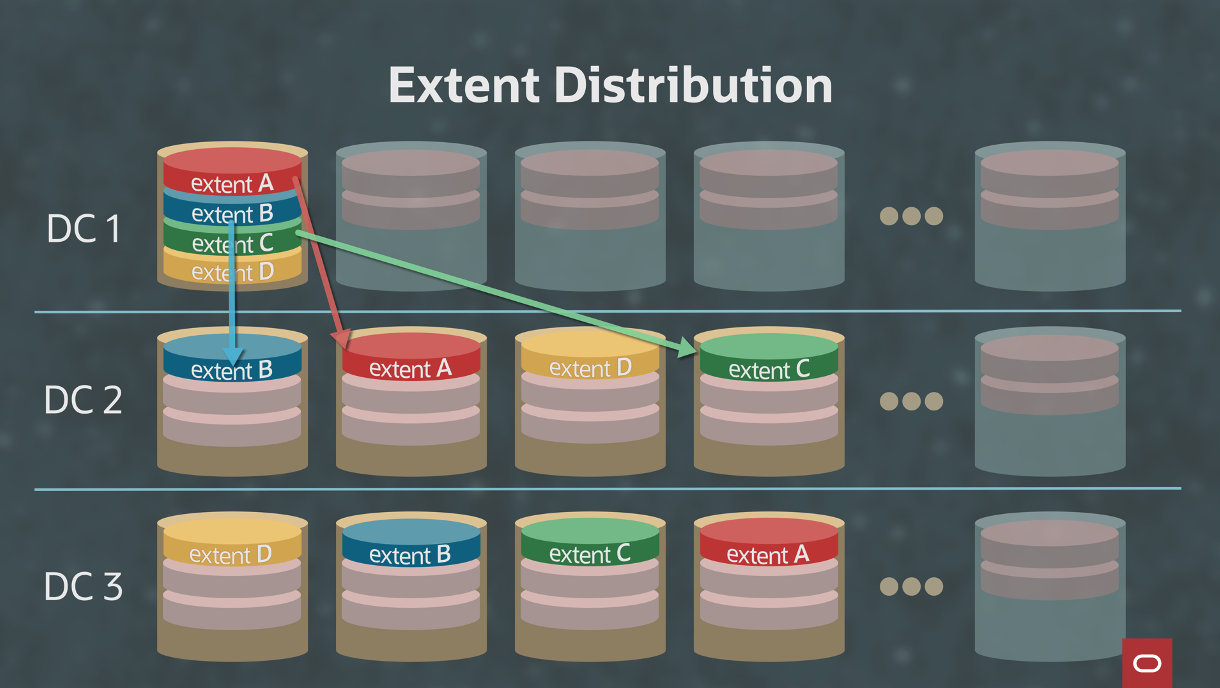
Figure 1: Extent distribution with three data centers
Fast recovery
To achieve high durability, minimizing failure detection and recovery duration to minimize probability of concurrent failures is imperative. A 20-TB disk copy takes about one day because of disk read/write latency. Object Storage detects disk failure and recovers from a disk failure in less than 30 mins. Instead of copying the data of one disk that failed to a replacement disk, the data is copied in parallel on separate disks on separate servers across multiple data centers. This method is known as distributed reconciliation. Cloud scale regions with multiple data centers allow using automated distributed reconciliation to recover from disk failures quickly. Figure 2 shows the distributed reconciliation process.
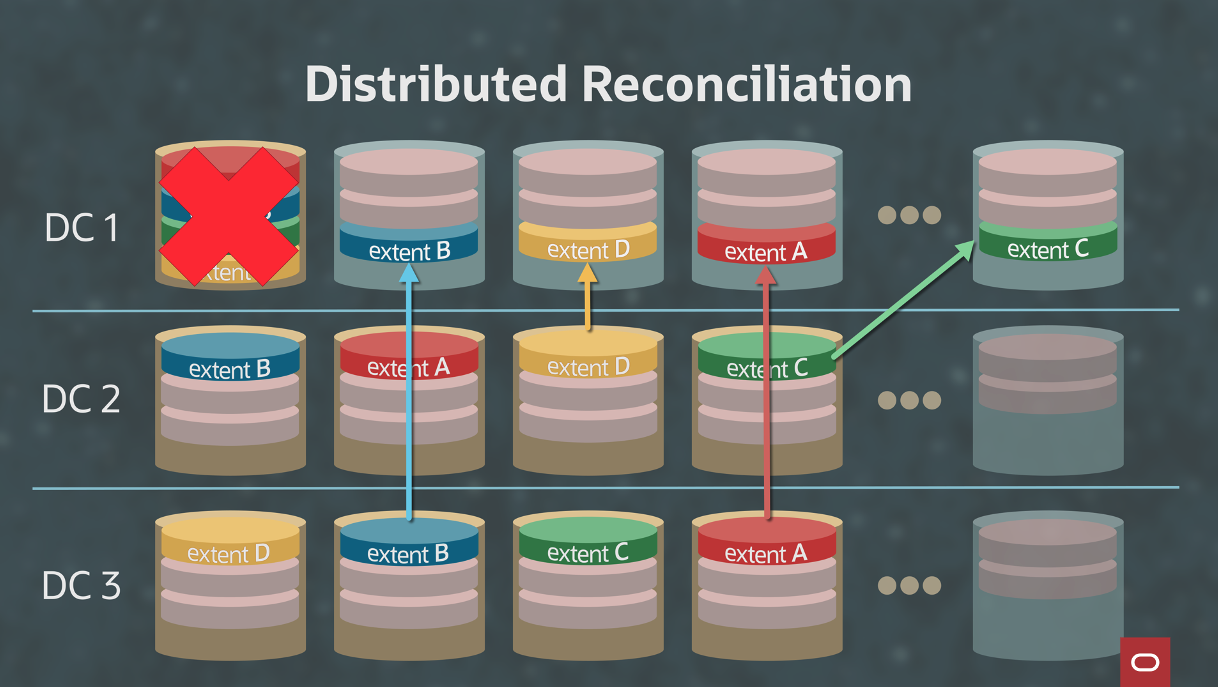
Figure 2: Distributed reconciliation with three data centers
Engineering culture
Oracle is known for reliability of data. OCI Object Storage has shaped its engineering culture around preventing data loss. All the hardware failure handling solutions will be a wash if one software bug causes a large-scale outage or any data loss. OCI storage services prioritize software quality best practices for testing and safe deployment over software feature release velocity.
Conclusion
OCI Object Storage exceeds 11 nines durability by layering sophisticated engineering techniques on top of commodity hardware. In storing exabytes of data for many customers in a region, Object Storage can employ automation with specialized techniques that can only be implemented efficiently at cloud scale. The service completes a disk recovery in less that 30 minutes in a highly automated manner to enable high durability.
Oracle Cloud Infrastructure Engineering handles the most demanding workloads for enterprise customers that have pushed us to think differently about designing our cloud platform. We have more of these engineering deep dives as part of this First Principles series, hosted by Pradeep Vincent and other experienced engineers at Oracle.
For more information, see the following resources:

