Imagine you want to access your database to find all the employees who joined the Pacific Northwest division since the start of the pandemic. To accomplish this goal, you need an engineer to inspect the database schema to study what tables and columns contain the necessary data. They then determine how to join tables using the right keys and define all relevant filters like location = “Pacific Northwest.” The engineer fetches the data by writing SQL queries, trying them against the database and testing the validity of the results.
Now, imagine you have a tool that understands the question, generates the SQL query, and runs it against the database to display the right answer. Oracle Digital Assistant’s generative AI-based SQL Dialog skills provide this capability as part of its chatbot. This blog details the innovative engineering behind SQL Dialogs.
What are SQL dialogs?
SQL Dialog translates a user’s natural language (NL) question, also known as utterance, into SQL queries using generative AI. It runs that query on the database to gather results and display them in the chatbot. It shows the interpretation in simple NL and an SQL query so that the user can validate the results.
SQL Dialog doesn’t require users to predefine utterances for training purposes or create custom components for backend connectivity. SQL Dialog is architected to work out of the box without customer specific training process.
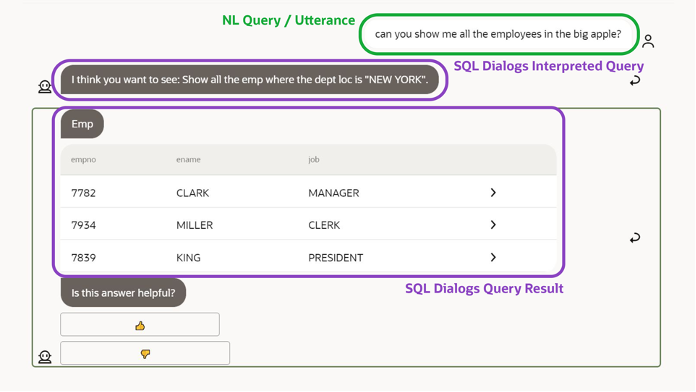
Figure 1: SQL Dialogs in the Oracle Digital Assistant chatbot displaying a user query and response
Our companion video blog is presented in two parts.
In our part one video, we discuss the core technology behind the SQL Dialogs Generative AI that provides a brief background on AI concepts like deep neural networks (DNNs), transformer models and attention.
In our part two video, we dive into the SQL Dialog model architecture and reveal how SQL dialogs generate secure and fully validated SQL that avoids hallucinations from generative AI.
Machine learning technology basics
ML models and Deep Neural Networks
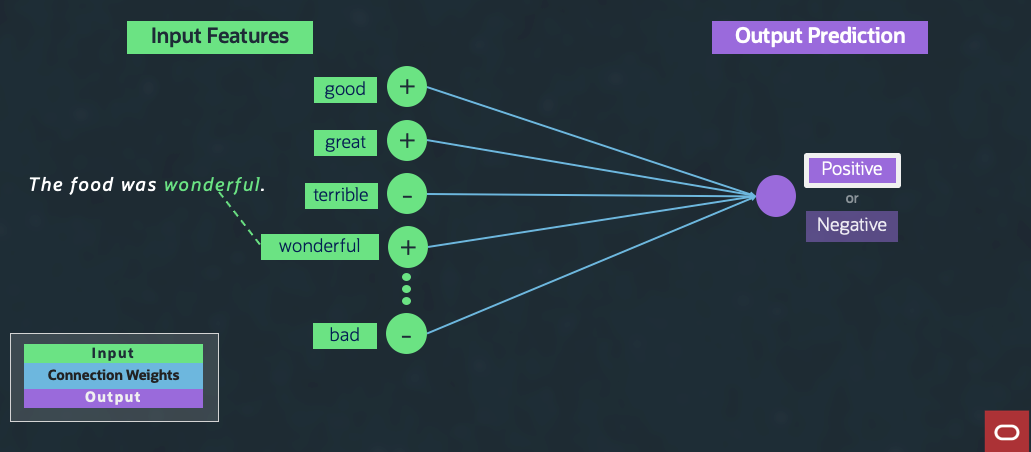
Figure 2: Simple ML model
To understand how SQL Dialogs translates NL utterance into SQL, let’s begin with a simple machine learning (ML) model shown in Figure 2. This model performs a basic sentiment analysis of sentences that categorizes the utterance based on positive or negative sentiment, called a Boolean classification model. Let’s consider the NL utterance, “The food was wonderful.” The word “wonderful” triggers the positive sentiment prediction. A more sophisticated model can generate output into various categories like strongly positive, positive, neutral, negative, and strongly negative. Such models are known as ML classifiers because they help predict a class of output values.
You can connect multiple ML models in a web to form a neural network. Each ML model represents a separate computational unit that performs a function on the input values generating an output prediction or an output value. These models are arranged in layers. Each layer takes inputs from the previous layer and sends outputs to the next layer. This web-like structure of models is inspired by animal brain compositions, which contain webs of neurons to form biological neural networks in brains.
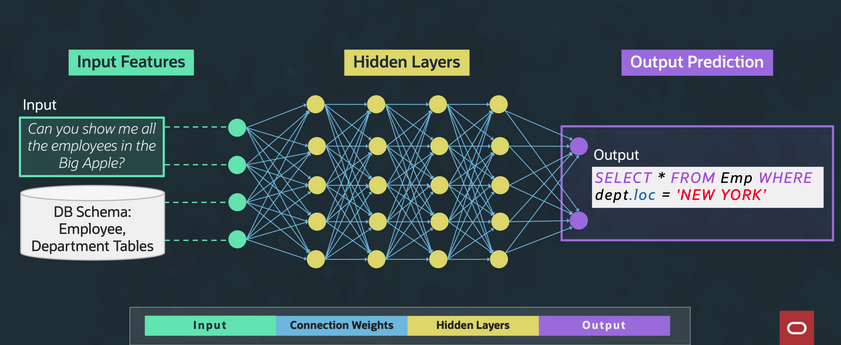
Figure 3: Deep neural network
DNNs have several layers of ML models, as illustrated in Figure 3. Each circle represents an ML model with a specific computational unit and each column represents a layer of these computational units. Different layers can perform different computations on their inputs.
DNNs can perform complex computations because they contain many layers of these ML models or ML classifiers. At each layer, these models can create relationships between their inputs, enabling DNNs to extract more complex relationships and generate more sophisticated outputs or predictions. DNNs utilize large amounts of compute and memory during the learning and inference processes as they can contain hundreds of millions of computational elements. To perform complex NL processing, we need a more advanced form of DNN, called a transformer model.
Transformer and attention
Figure 4: Transformer model architecture
Transformer models are the core foundation that enable NL processing and generative AI because they learn context and develop meaning by tracking relationships in sequential data like the words in this sentence. Transformer models are a type of DNN that use a specialized computation unit, called the attention mechanism, with the simple neural network computational units.
Attention computation units are stacked in layers in the transformer model. In a transformer model, layers of simple computation units alternate with attention computation units as shown in Figure 4. The attention mechanism allows the transformer model to interpret each input element in the appropriate context. Using the attention mechanism, the transformer model computes relationships between these inputs. These relationships play a key role in the translation of NL utterance to SQL.
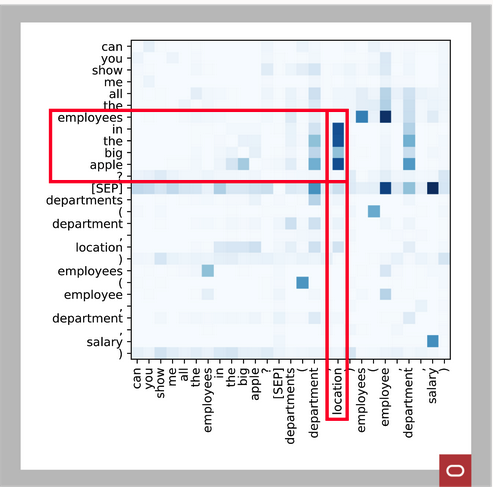
Figure 5: Sample attention matrix
The attention mechanism is designed to allow the transformer model to pay greater attention on certain factors when processing the inputs. Each input word or database schema element in the attention computation is known as an input token. Attention conveys information from one input token to another. Figure 5 depicts a two-dimensional sample attention matrix computation between the input tokens. This sample attention matrix renders the attention values between the tokens in the NL utterance and database schema at a particular layer in the DNN. The darker cells of the matrix represent the attention computed between the attributes that are listed to the left and bottom of the matrix.
The matrix shows a clear relation between ‘location’ and ‘the big apple’ (marked in red). In some other cases where we see darker cells in the matrix, no clear relationship exists between tokens. These intermediate computation memory stores are processed within the hidden layers of the transformer model. By using the transformer model, you can successfully achieve the translation between NL utterance and SQL .
SQL Dialog training
Training high fidelity NL generate AI model requires vast troves of data and the training process typically requires expertise that can be cumbersome for customers. SQL Dialogs employ the specific ML techniques of pretraining and finetuning to train the model that obviates the need for customers to do further training.
Pretraining
Pretraining refers to a process of training a model with a proxy task. Consider a generic task of translating from English to Spanish. You can train a base model for a generic task with millions of readily available training samples. This training helps set the parameters used in the actual task of translation. This model is referred to as a pretrained model. You can further train models with thousands of training samples for the actual task at hand, such as translating from NL utterance to SQL.
Finetuning
Finetuning is the process of training a whole or part of the pretrained model for a specific task. Instead of training a model from scratch, you can train a pretrained model to perform a specific task with minimal training. This process utilizes the existing parameter weights of the pretrained model to then finetune them to learn the specific task. This step significantly reduces the task-specific training data requirements. SQL Dialog skills use a pretrained model and performs finetune training, enabling the SQL Dialog model to be trained efficiently. Figure 6 shows how this process works.
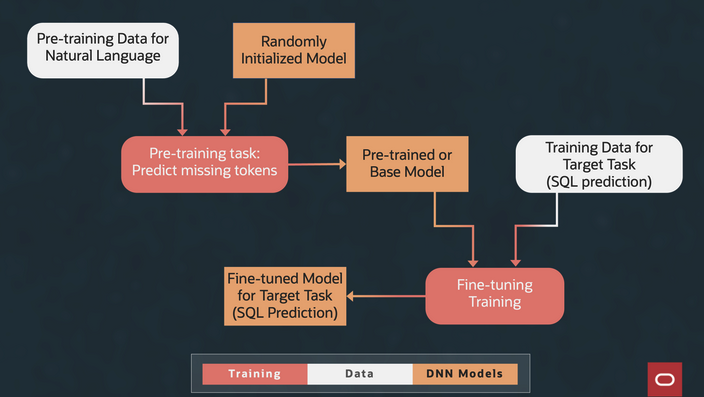
Figure 6: Pretraining and finetuning
Training SQL dialogs
With pretraining and finetuning, the SQL dialogs generative AI model takes a customer’s database schema, entities, and NL utterance as inputs. When processing the NL utterance, the model maps the NL utterance with the customer’s database schema to produce the appropriate SQL for the database. Because the SQL Dialog DNNs are trained for SQL generation and uses the database schema as input, SQL Dialogs runs without any extra training from customers.
SQL Dialog customization
While SQL dialogs don’t need customer-specific training, it offers the flexibility in customizing the model for customer specific queries. Let’s consider the case of an enterprise customer’s executive team that uses the term “most important locations” to refer to the ten locations with highest total sales in the last financial year. To interpret this terminology accurately, customers can train the model with approximately 100 samples to enable customized translations. With this training, you can meet the unique requirements of each customer.
Customers’ databases reside within their tenancies or on-premises data centers to ensure that the data remains isolated and private, and the model trained with customer specific training data remains fully private and isn’t shared with any other customer.
SQL Dialog architecture
SQL dialogs are architected using multiple ML models that operate in conjunction with a rule-based engine to maximize fidelity, minimize hallucinations, and eliminate security risks.

Figure 7: SQL Dialog model architecture
Figure 7 shows a high-level diagram of the SQL Dialogs model pipeline that powers the Oracle Digital Assistant chatbot. It takes two inputs: The customer’s database (in white), and the user’s NL utterance or question (in green). The model pipeline returns the SQL query (in purple) as output. The SQL query runs against the customer’s database to generate the displayed answer (in purple).
Two key DNNs—entity resolution and semantic parser—generate an intermediate parse tree output called Oracle meaning representation language (OMRL). OMRL is converted to SQL using a rules-based converter process called OMRL2SQL.
Entity resolution
The first ML model in the SQL Dialog pipeline is the entity resolution model. It processes the input tokens or words in the NL utterance to establish relationship with entities in the database. It recognizes common entities like dates, geo locations, and names. For example, “big apple” is recognized as a geo location and mapped to the value “New York.” “New York” maps to a column named “LOC,” which is part of the table “DEPT.” The NL utterance is augmented with these relationships between database and tokens in the NL utterance before feeding them to the semantic parser model.
Semantic parser
The second ML model in the SQL Dialogs pipeline is the semantic parser model. This DNN uses the augmented NL utterance generated from the entity resolution model as input with the customer’s database schema to produce a normalized OMRL. The input tokens are converted into an OMRL parse tree by designing the DNN to conform with the OMRL grammar.
OMRL
Instead of generating the SQL directly, the semantic parser model generates an intermediate structured output of OMRL. This intermediate form enables SQL Dialog to enforce a set of constraints on the output that are critical to solving the known challenges with generative AI. The collection of constraints applied play a key role to ensure security, usability, and accuracy of SQL dialogs.
Security: Preventing SQL injection
SQL is a powerful language for data access, but it’s also prone to abuse by malicious actors. SQL injection is a major security risk to data in databases when appropriate measures aren’t taken. OMRL’s structured object enables the use of industry best practices like parameter binding to mitigate such security risks.
The parse tree structure of the OMRL grammar is crucial towards implementing the necessary security mitigations. For example, the OMRL grammar doesn’t allow INSERT, UPDATE, DELETE, or any write statements. This exclusion guarantees that SQL dialogs can’t perform writes into the database. Consider the question “Find the avg salary of developers in ‘drop table employee’” by a nefarious user. ‘Drop table’ is SQL syntax to delete a specific table. Because of OMRL grammar restrictions, this command can’t be parsed into a SQL statement. Parameter binding detects and prevents the SQL injection from happening.
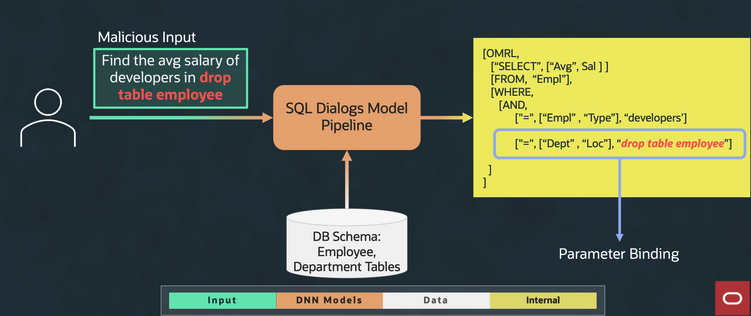
Figure 8: Preventing SQL injection
Figure 8 shows how OMRL utilizes parameter binding to prevent the SQL injection attempt by mapping “drop table employees’ to a constant value, which becomes a benign string.
Usability: OMRL interpretation

Figure 9: OMRL to natural language interpretation
Although the SQL dialogs are designed to generate secure SQL queries, you must validate that the AI hasn’t misinterpreted the NL utterance. SQL Dialog provides a way to verify the SQL intuitively. It displays its interpretation of the question by generating user-friendly natural language text that represents the SQL. Figure 9 shows an extra component in the SQL Dialog model pipeline, OMRL2NL. This rule-based process transforms OMRL parse tree to NL interpretation. Using this interpretation, a user can validate that the SQL dialog has understood the question and whether it fetched appropriate data.
The NL interpretation also serves as an added value for debugging in case of errors in SQL generation. Suppose the semantic parser mistakenly associated ‘New York’ with department instead of location. The SQL dialogs generate a list of employees from department ‘New York’ that might be an empty list or incorrect list of employees.
When the answer is a list of employees, the user has no way to identify this error from reading the results alone. Reading the NL interpretation, the user can easily verify if the query interpretation was correct. Figure 1 shows the Oracle Digital Assistant chatbot response that includes SQL Dialog interpretation and the data returned. The development team also has access to a debug console that can check the exact SQL generated, and the mapping of the entities by the entity resolution component so that they can identify any issues and get them resolved.
Accuracy: Avoiding hallucinations
Large language models (LLMs), including ChatGPT, have a tendency for hallucination. Their output might include irrelevant, inappropriate, or just plain incorrect information. The SQL Dialog system is designed to minimize hallucinations. LLMs generate unstructured outputs against SQL dialogs, which generate a structured output in the form of normalized parse tree constrained by a well-defined grammar derived from the database schema. Because the output is constrained by the database schema, it can’t generate OMRL to query data from a nonexistent table or column. This step significantly reduces the probability of hallucinations.
Next, the entity resolution model uses named entity recognition (NER) and other standard NLP technology to identify the key entities in the user question or NL utterance. This usage results in detection of entities, such as person and product names, dates, and geo locations, and links them to database entities like the tables, columns, and values. By tracking entities throughout the entire parsing process in the AI, it prevents the parser from hallucinating a value, column, or table that does not map to the original user question.
Finally, the natural language interpretation generated from OMRL allows users to confirm that SQL Dialog hasn’t misunderstood the user question. It also lets users detect scenarios where the produced output contains information not present in the original user question.
Conclusion
Oracle SQL Dialog skills simplify how customers can access data using novel generative AI-based architecture with the following capabilities and features:
-
Uses a pipeline of generative ML models combined with purpose-built rules engine specifically designed to increase the fidelity of generated SQL query, avoid hallucinations, and minimize security risk.
-
Uses pretraining and domain-specific custom training to obviate the need for customers to do any further training.
-
Generative AI models generate OMRL parse tree as an intermediate step to improve accuracy and minimize security risks.
-
Uses multiple techniques to increase accuracy and avoid hallucinations.
Oracle Cloud Infrastructure (OCI) Engineering handles the most demanding workloads for enterprise customers that have pushed us to think differently about designing our cloud platform. We have more of these engineering deep dives as part of this First Principles series, hosted by Pradeep Vincent and other experienced engineers at Oracle.
For more information, see the following resources:

