At Oracle, we build world-class database systems and services such as OCI Exadata Database Service, OCI MySQL Database Service and MySQL Heatwave Database service, a cloud scale service that we recently covered on the First Principles series. PostgreSQL is a popular open-source database and our goal is to give OCI customers the choice of database to run their cloud workloads. With the recently announced OCI Database for PostgreSQL, we brought to bear Oracle’s expertise in database technology to build a cloud scale world class OCI Database with PostgreSQL service. This blog post demystifies how Oracle adapted PostgreSQL into a cloud database service.
PostgreSQL is a popular database software that provides the atomicity, consistency, isolation, and durability, also known as ACID properties. At Oracle Cloud Infrastructure (OCI), we are opinionated about what makes a great cloud database experience. Customers should be able to add or remove database instances on demand, scale compute and storage independent of each other and the service should be architected to deliver best-in-class price performance without risk of data loss. These are the basic premises for any cloud based database service. Here are the key properties we need from an OCI PostgreSQL service:
- Zero Recovery Point Objective (RPO) and zero data loss: Customers don’t lose any data saved in the database even if there are infrastructure or system failures.
- Consistent high performance: Database performance is not affected by backend system tasks, including replication.
- Horizontal read scaling: Customers can easily scale up and down their read capacity without affecting write performance.
- Price performance: Customers’ workloads run faster at lower cost.
- Full Automation: Customers save operational overhead with tasks like software patching, health monitoring, database failover, backups and storage scaling.
Vanilla PostgreSQL Database

Figure 1: Customer Managed PostgreSQL Architecture
From here on out, we will refer to open-source PostgreSQL as “vanilla PostgreSQL”. Although vanilla PostgreSQL is powerful and popular database, here are some of the challenges that customers face with it:
- Data loss during primary failovers – non-zero RPO: As shown in figure 1, customers typically replicate database instance across Availability Domains. This replication is performed from the primary database in AD1 to the “Replica” in AD2 asynchronously. The replica database might lag behind the primary. If the primary fails and a replica is promoted to be the new primary, there is the potential for some data loss because of the lag. The amount of data loss is determined by how far behind the promoted replica was from the old primary. A solution to this problem in vanilla PostgreSQL is a synchronous replication capability, which is less popular because of its significant performance overhead.
- Complexity of manual promotions and manageability: Although you can set up replicas in different availability domains to achieve high-availability, promoting a standby replica to a primary is a manual and complex process. Picking a new candidate to promote must be done carefully in order to minimize data loss and, similarly, re-adding an old primary back into the cluster requires more manual steps. For example, the old primary might have excess transactions committed locally that need to be purged first by using tools like pg_rewind before it can re-join the cluster.
- Creating read replicas is expensive and slow: With vanilla PostgreSQL, creating a new replica requires taking a snapshot of the data on the primary and catching up to the primary. For large databases that may be in terabytes, this is an expensive and slow operation. To allow handling for bursts in read demand from applications, customers must over-provision database resources. Because each replica must have a full copy of the database, storage costs for running multiple replicas can get expensive.
OCI Database with PostgreSQL has solved these challenges.
OCI Database with PostgreSQL – High Level Architecture
Now we’ll explore how the upleveled architecture of OCI Database with PostgreSQL solves these challenges above and makes it very simple to run and manage PostgreSQL in OCI. In OCI Database with PostgreSQL, we push the problem of replication and durability to the new Database Optimized Storage (DbOS) layer, which was purpose-built to enable a high-scale, high availability and high performance database service. DbOS offers highly durable network-attached storage in which data blocks are replicated across multiple availability domains in a three-availability-domain region. In a single-AD region, data is replicated across multiple fault-domains. All PostgreSQL nodes in a cluster access the same network-attached storage. Each standby replica doesn’t have to maintain its own copy of the database anymore. The primary instance writes to the shared storage while standby replica instances read from the same shared storage and serve user queries.
Figure 2: Vanilla PostgreSQL v OCI Database with PostgreSQL
This new shared-storage architecture used in OCI Database with PostgreSQL offers a number of advantages in the form of safety, flexibility, efficiency and performance. Although OCI Database with PostgreSQL has a completely different storage architecture underneath, it’s still fully compatible with vanilla PostgreSQL. So, you can lift-and-shift your existing PostgreSQL workloads to OCI Database with PostgreSQL or move them back again with ease. DbOS is a shared file system that leverages high performance OCI Block Storage capabilities like built-in replication.
Advantages of Database Optimized Storage (DbOS)
Let’s detail why the newly embedded DbOS layer is such a powerful advantage for PostgreSQL users:
- Durability (zero-RPO): DbOS replicates data across multiple availability domains in a multi-availability-domain region and can survive the loss of an entire availability domain. DbOS uses quorum-based replication to replicate the data blocks behind the scenes. If the primary node fails, DB can failover to a different DB node that uses the replicated DbOS and this newly promoted primary PostgreSQL instance can take over with no data loss. All transactions previously committed on the old primary are present in the new primary. Because the DbOS layer performs the replication, there is no need to run multiple replica instances just for the sake of durability. For example, it is possible to run a single-node OCI Database with PostgreSQL instance without any replicas but still not sacrifice durability. You are guaranteed to have zero-RPO even in this single-node setup.
- High availability (99.99%): With OCI Database with PostgreSQL, you can failover the primary to another replica in the cluster automatically in a few minutes. Primary failover is quick and almost transparent to the applications because Recovery Time Objective only takes a few mins. To enable the failover transparently, the primary endpoint is set up as a floating IP address that is automatically moved to the new primary. Applications automatically reestablish database connections to the new primary after the failover without requiring any configuration changes to the application. Unlike in vanilla PostgreSQL, you don’t need to worry about replication-lag and data-loss while initiating a primary failover. You don’t need to hand-pick a specific replica to minimize data loss. All instances in the cluster share the same storage and so upon a failover, the new primary is guaranteed zero data loss.
- Elasticity: Because the database storage is shared across all the nodes, you can quickly create or delete replicas quickly to meet user query workload demands. Unlike in vanilla PostgreSQL, you don’t need to take a snapshot of the data on the primary and copy it to the replica node to launch a new standby PostgreSQL instance. So you can create standby replicas as quick as launching a compute instance in OCI Database with PostgreSQL.
- Horizontal scaling of read replicas: Because the replica nodes share database storage in OCI Database with PostgreSQL, you only need to maintain one copy of the database, regardless of the number of replicas in the database cluster. As a result, OCI Database with PostgreSQL provides significant storage cost savings as compared to running vanilla PostgreSQL in the cloud. Additionally, OCI’s PostgreSQL service offers a pay-per-use pricing model on the data with autoscaling to minimize your cost.
- Low replica lag: Replication lag is a major challenge with vanilla PostgreSQL read-replica setup. Because the replica must replay and persist all the changes made by the primary, it is prone to falling behind, especially with network partitions. With shared storage, the replica does significantly less work. It only needs to apply changes to pages in its cache and it never has to persist these changes. With this architecture, replication lag is typically in milliseconds, which allows the read queries to be executed or completed in near real-time.
- Efficient replication: OCI Database with PostgreSQL performs replication at the storage layer. Hence, the primary instance does not need to physically ship Write Ahead Log (WAL) records to all the replicas. Instead, it notifies replicas of new changes and the individual replicas read the latest WAL records directly from shared storage. This minimizes load on the primary and it can scale more effectively to a larger number of replicas.
In our experiments, OCI Database with PostgreSQL’s built-in replication across ADs was more than twice as fast as synchronous replication in vanilla PostgreSQL.
DbFS: Single-Writer-Multiple-Readers Filesystem
Vanilla PostgreSQL on Linux uses a standard filesystem supported by the kernel, typically ext4 or xfs. Such filesystems are not designed for a distributed setup such as OCI Database with PostgreSQL in which all the nodes in the cluster share the same underlying storage or filesystem. Let’s review some critical aspects of filesystem implementation used in OCI Database with PostgreSQL, as illustrated in Figure 3.
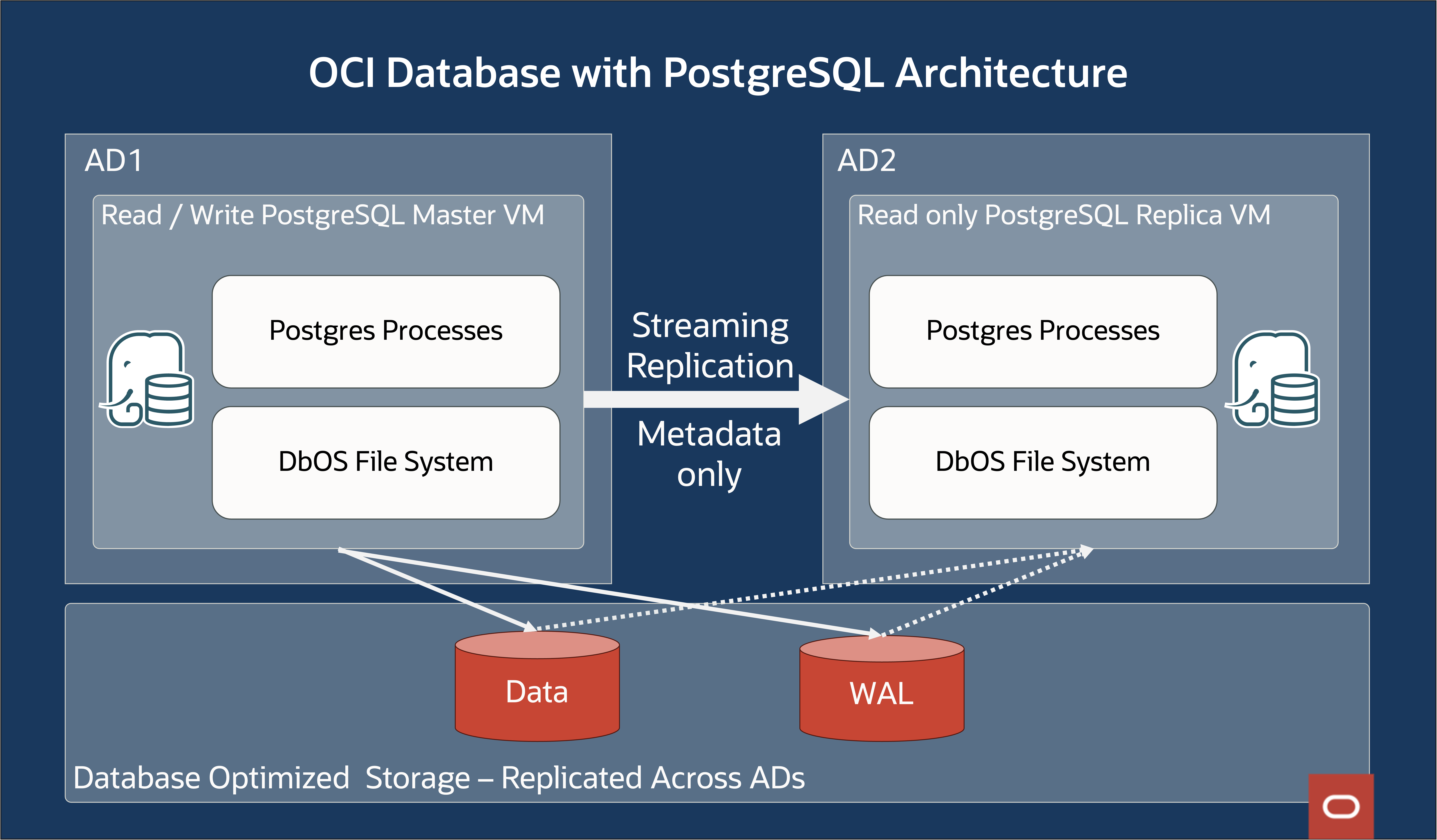
Figure 3: OCI Database with PostgreSQL Architecture
- Single-writer-multiple-readers: To run OCI Database with PostgreSQL on top of DbOS shared storage, we built a custom user-mode DbOS filesystem (DbFS) that lets multiple nodes access the filesystem concurrently. Specifically, it supports the single-writer-multiple-readers access model to support a primary database and multiple read replica databases.
- Metadata-based replication: The primary node mounts DbFS in read-write mode, and the read-replica node mount DbFS in read-only mode. Any changes to the filesystem made by the primary node will become visible to the replica nodes. The data is stored in the storage layer and file system manages the metadata. Because the storage is shared, data replication from the primary is achieved by replicating the metadata only. All the changes to the filesystem metadata, such as creating a file or allocating an extent to a file are journaled in DbFS. The journal updates are shipped to the replica nodes. The replica nodes will replay the journal entries to keep their in-memory metadata to bring it up to date; similar to how vanilla PostgreSQL does physical replication through WAL updates.
- LSN-Aware Storage: Both data and metadata changes in DbFS are tagged with the database log sequence number (LSN). Unlike traditional file systems that treat blocks like opaque data, DbFS tracks the LSN of the individual database block. It stores multiple versions of the same block at different LSNs. This allows PostgreSQL to read a block from DbFS at a given LSN to achieve “consistent read”. Metadata operations such as file creation and deletion are also tagged with the corresponding database LSN. Because the storage is shared among all the database instances, DbFS needs to handle file deletions by the primary. When a file is deleted on the primary, it can’t be immediately removed from storage because some replica nodes that are lagging behind might access those files. DbFS tombstones such files but they’re still accessible from the replica(s). When the replica’s LSN moves ahead, these tombstone files are permanently deleted in the background.
- Pay-per-use storage model: DbFS supports online resizing so you can scale the underlying storage up and down depending on the storage space use by PostgreSQL. Online resizing is quick because it’s a pure metadata-only operation. When the data storage space reduces, the storage is also automatically scaled down.
Achieving “consistent reads” from shared storage

Figure 4: Vanilla PostgreSQL Replication
For the replica to satisfy a read-query, it must be able to read the version of the page consistent as of the current ReplayLSN of that replica. This is critical when traversing index structures such as B-tree that might have concurrent structural modifications such as splits and merges. In vanilla PostgreSQL, LSN is a log sequence number and ReplayLSN is the LSN during WAL Replay activity executed as part of the replication process. In vanilla PostgreSQL, each replica has its own storage, which means that each replica can maintain read consistency independently. Figure 4 shows that vanilla PostgreSQL has separately stored data for the primary and the replicate databases. The primary has data persisted at LSN 100 and is writing the latest data at LSN 110, and the replica is trailing behind at LSN 90. When a read request for Block 0 goes to the replica, it will read its latest data at LSN 90.
Now, let’s see how this same situation is handled by DbFS, which uses a database-aware shared storage layer.
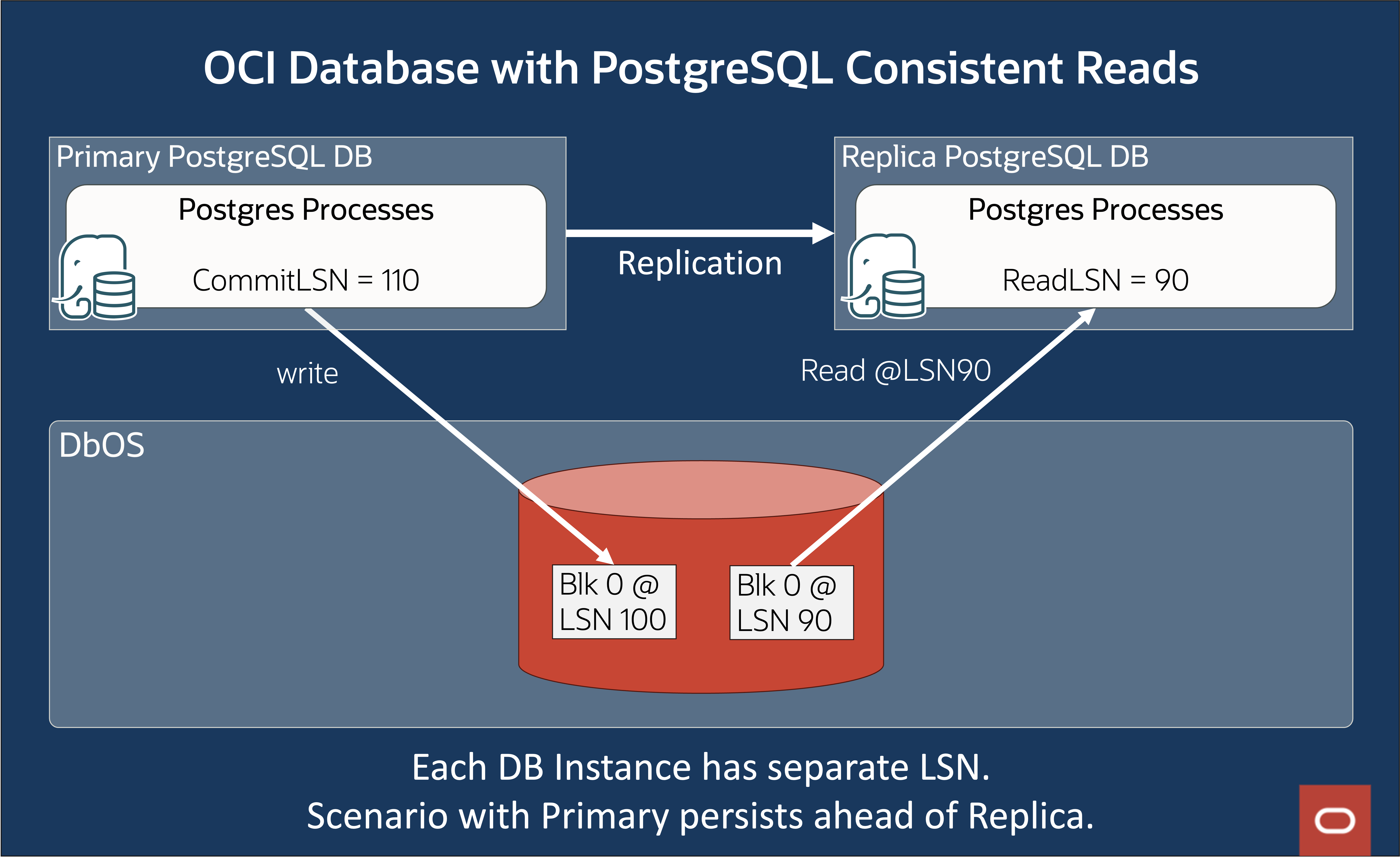
Figure 5: OCI Database with PostgreSQL – Primary Ahead of Replica scenario
To allow a replica to read a page at specific LSN, DbFS keeps multiple versions of the page at various LSNs. When the primary flushes a page either as part of a checkpoint or cache eviction, DbFS doesn’t overwrite the previous copy if a replica still needs it. In a scheme similar to a Log-structured file system, blocks are written to new offsets and multiple versions of the block are available to the read replica. Older versions are eventually discarded when DbFS determines that all replicas have moved past the LSN and the block is no longer needed.
In Figure 5, the primary has first persisted Block 0 at LSN 90 and subsequently at LSN 100. Because the replica is still at LSN 90, the primary writes LSN 100 into a separate location and doesn’t overwrite the Block 0 at LSN 90. Storing separate versions of Block 0 for primary and replica helps ensure read consistency for each replica.
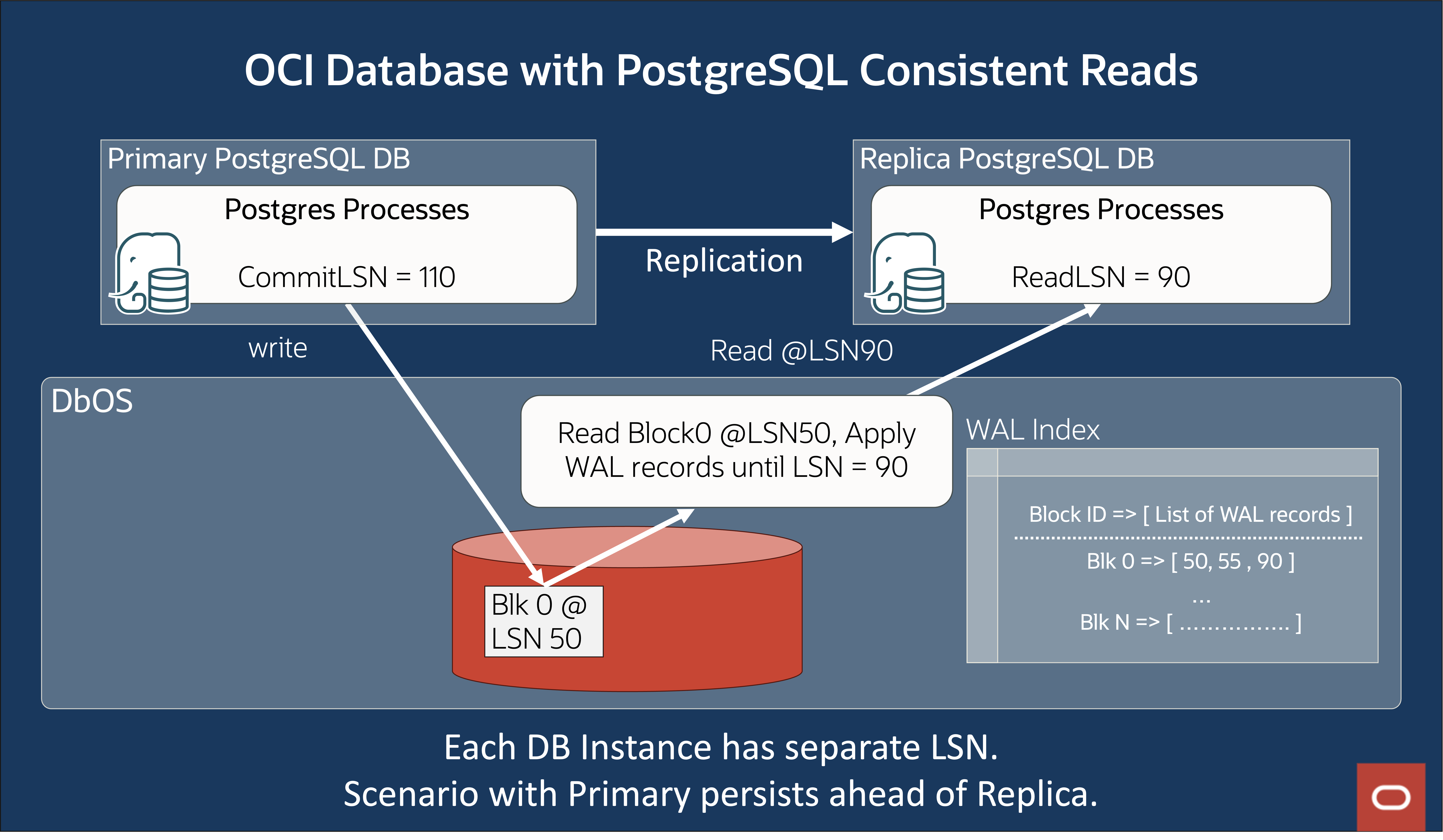
Figure 6: Figure 6: OCI Database with PostgreSQL – Primary not persisted latest data scenario
When the primary has not persisted the page as of the replica’s ReplayLSN, it reads an old version of the page from the shared disk and on-the-fly replays any WAL records applicable to this page to bring this page up-to-date as of the replica’s current ReplayLSN. To make this WAL replay efficient, each replica maintains an in-memory index of all the WAL records, which is indexed by the page number and maintained since the last checkpoint.
In Figure 6, the primary has persisted Block 0 at LSN 50, while the in-memory data for Block 0 is at LSN 110. The replica has successfully replayed until LSN 90 is in its in-memory state. As a result, the replica makes a read request for Block 0 to the DbOS at LSN 90. DbOS currently has data persisted at LSN 50. DbOS applies WAL records until LSN 90 and returns the data at LSN 90 to the replica. With the WAL Index, DbOS ensures that even if the primary has not persisted the data to storage, it can successfully return consistent data to the replica.
Primary failover
For high availability, OCI Database with PostgreSQL automatically detects unhealthy primary instances and fails over to an existing read replica or launches a new database instance if there are no read replicas. The process of fail-over must ensure not only that the unhealthy primary stops making any new changes to shared storage, but also that any in-flight I/O requests to shared-storage are canceled. In some failure scenarios that involve network partitioning, the unhealthy primary might not be reachable externally but can still modify shared storage. To handle these complex cases, DbFS uses block-layer reservation (NVMe reservation or SCSI-3 persistent reservation) to fence out the old primary and ensure that there is a single primary at any given time. With persistent or NVMe reservations, whoever holds the reservation is allowed to write to shared storage. During failover, the new primary obtains the reservation and pre-empts the old primary. When this is done, the storage subsystem rejects all requests from the old primary.
Further Storage Optimizations
Besides the shared storage optimizations, OCI Database with PostgreSQL implemented the following optimizations to further improve performance.
Atomic writes: DbOS implements optimizations for known database performance risks such as elimination of “torn writes”. Typically, most databases need some sort of protection against “torn writes”, which happen when the database uses a page size (PostgreSQL uses 8 KB) that doesn’t match the “atomic write unit” size of the underlying storage (typically 512B or 4KB). For example, PostgreSQL first writes an entire 8KB page to the WAL if it’s the first modification to the page since the last checkpoint, and then flushes the page to disk. If the page write is torn, then PostgreSQL falls back to using the full-page it wrote previously in the WAL and no harm is done. But this protection comes at a price – it causes balooning of the WAL and the problem is exacerbated by frequent checkpoints which are needed to minimize recovery time during unplanned failovers. We implemented atomic write support for PostgreSQL pages in DbOS. The storage layer never overwrites an existing page. Instead, it uses log-structuring technique to always write pages to a new location on disk and maintains a mapping layer from logical file offset to disk location. Older versions of the pages are periodically garbage collected. This avoids double writes.
Optimized page cache: OCI Database with PostgreSQL uses a purpose-built caching layer, unlike vanilla PostgreSQL, which relies on the generic Linux kernel page-cache. OCI’s page cache implementation has many optimizations such as the following ones:
- Custom prefetching logic tailored for PostgreSQL workloads.
- Avoids double-caching pages in PostgreSQL shared-buffers and page-cache
- Speeds up PostgreSQL recovery by prefetching data pages
Storage-level-backups: In vanilla Postgres, to maintain database backups, WAL is copied to object storage, and a periodic snapshot of the filesystem is taken. This process uses both network and CPU on the primary node. OCI Database with PostgreSQL delegates backups to the storage layer, eliminating network and CPU overhead for backups.
Conclusion
The OCI Database with PostgreSQL service provides significant advantages in the form of cost, performance, scale, availability, and durability as discussed in detail before. The key to achieving most of these benefits is based on the DbOS and the DbFS that are purpose-built for optimizing PostgreSQL to work more effectively at cloud scale.
Key Takeaways
- OCI Database with PostgreSQL uses a purpose-built shared-storage architecture in which all the database nodes share the same underlying DbOS.
- DbOS automatically replicates data across a region with no data loss during primary failovers (zero-RPO failovers).
- OCI Database with PostgreSQL scales read workloads horizontally and enables high performance consistent reads across all replicas in the cluster.
- Shared storage provides significant cost savings to customers because they don’t have to store multiple copies of data and the storage is automatically scaled down when data size reduces.
Oracle Cloud Infrastructure (OCI) Engineering handles the most demanding workloads for enterprise customers, which has pushed us to think differently about designing our cloud platform. We have more of these engineering deep dives as part of this First Principles series, hosted by Pradeep Vincent and other experienced engineers at Oracle.
For more information, see the following resources:

