In today’s world where information is key to business success, data is generated faster than the capacity to process it. This gap keeps widening as raw data volumes increase. Aside from volume, there’s also the issue of how time consuming and expensive analyzing data is because analytics tools typically require it be transferred into a database. What if a solution existed that analyzed data right from object storage—the most common home for data—in record time?
MySQL HeatWave Lakehouse on Oracle Cloud Infrastructure (OCI) provides industry-leading performance and price-performance at-scale to simplify this challenge for customers. In this post, we detail some of the engineering innovations that power MySQL HeatWave Lakehouse, from massively partitioned architecture to novel lower-level optimizations.
MySQL HeatWave overview
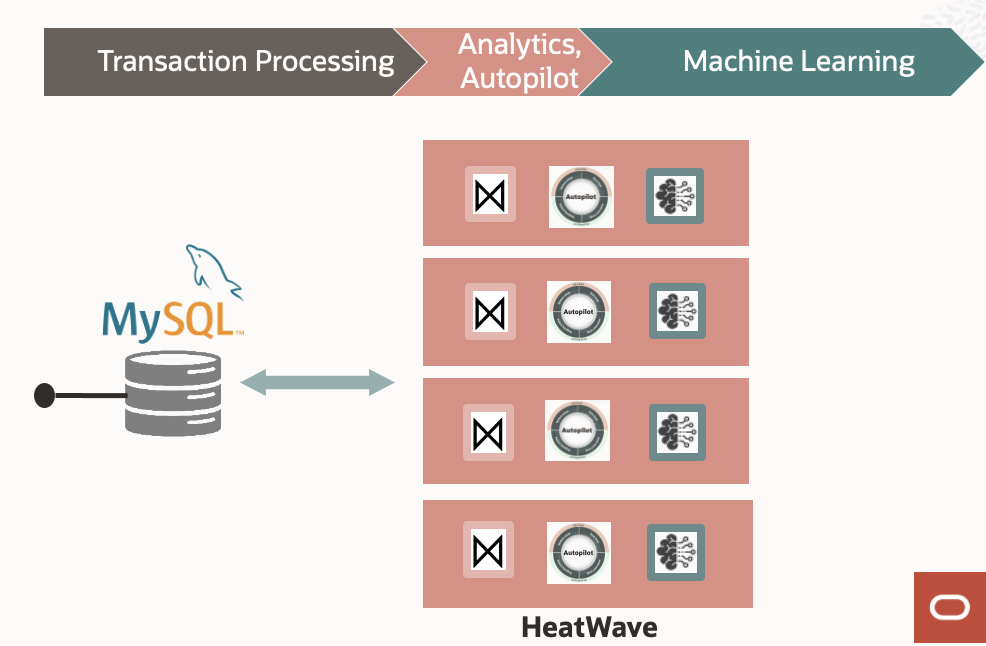
Figure 1: MySQL HeatWave Overview
MySQL HeatWave is the only cloud database offering that provides an online transactional processing (OLTP) database, a real time in-memory data warehouse, and in-database automated machine learning capabilities in a single MySQL database service.
The core of MySQL Heatwave is an in-memory query accelerator architected to run side-by-side with the MySQL OLTP transaction engine. It’s designed to boost the performance of analytics queries with various machine learning (ML)-based techniques referred to as MySQL Autopilot. MySQL HeatWave also includes data processing pipelines for ML workloads that don’t need data or the ML model to leave the database, making it secure and efficient.
Partitioned architecture
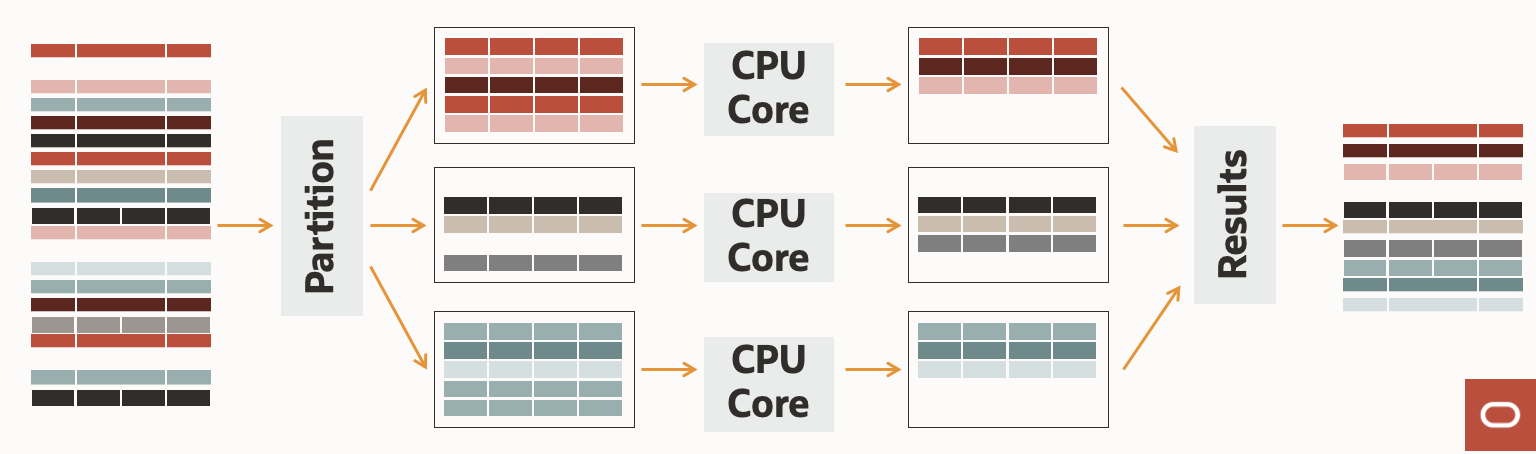
Figure 2: Highly partitioned architecture
MySQL HeatWave partitions data into fine chunks. Figure 2 illustrates data partitioning that enables parallel data loading and data processing. The data partitions use a partition key based on query predicates to load data efficiently. HeatWave tunes the partitioning strategy dynamically based on query pattern, and the partition size is selected to match the level 3 (L3) cache on the CPU to maximize the utilization of memory bandwidth. HeatWave clusters can scale up to 512 nodes to maximize parallel processing. The combination of high scale and an optimized partitioning strategy help deliver industry-best price performance.
MySQL HeatWave: Real-time analytics
One of the key differentiators of MySQL HeatWave is its real-time analytics capability, which enables customers to make business decisions on the most up-to-date data. With MySQL HeatWave, any OLTP data written to MySQL Database is available for analytics immediately without copying the data anywhere. To enable real time analytics, the in-memory data in MySQL HeatWave must guarantee that it uses the latest committed data from the database. When data comes into your MySQL Database, it persists right away.
When a change persists in your MySQL Database, it propagates to the MySQL HeatWave in-memory data representation immediately, and as a result HeatWave query processing uses the in-memory data that’s kept up to date. The data propagation takes a small amount of time, usually a few milliseconds, and if a query references an updated table for which the data updates haven’t been propagated yet, the system ensures that the changes are propagated to the in-memory representation before the query runs.
This process guarantees the use of the latest data for the HeatWave query. If a HeatWave query is in flight before the MySQL write occurs, the HeatWave query goes through completion without interruption. The HeatWave query processing engine has no effect on transactional processing in the MySQL Database.
MySQL HeatWave Lakehouse overview
MySQL HeatWave Lakehouse enables efficient data query processing in OCI Object Storage with data in MySQL Database. It uses the same scale-out query processing engine of MySQL HeatWave, enabling it to query hundreds of terabytes of data in parallel from Object Storage in various file formats, including CSV and Parquet, without users having to import data into the database.
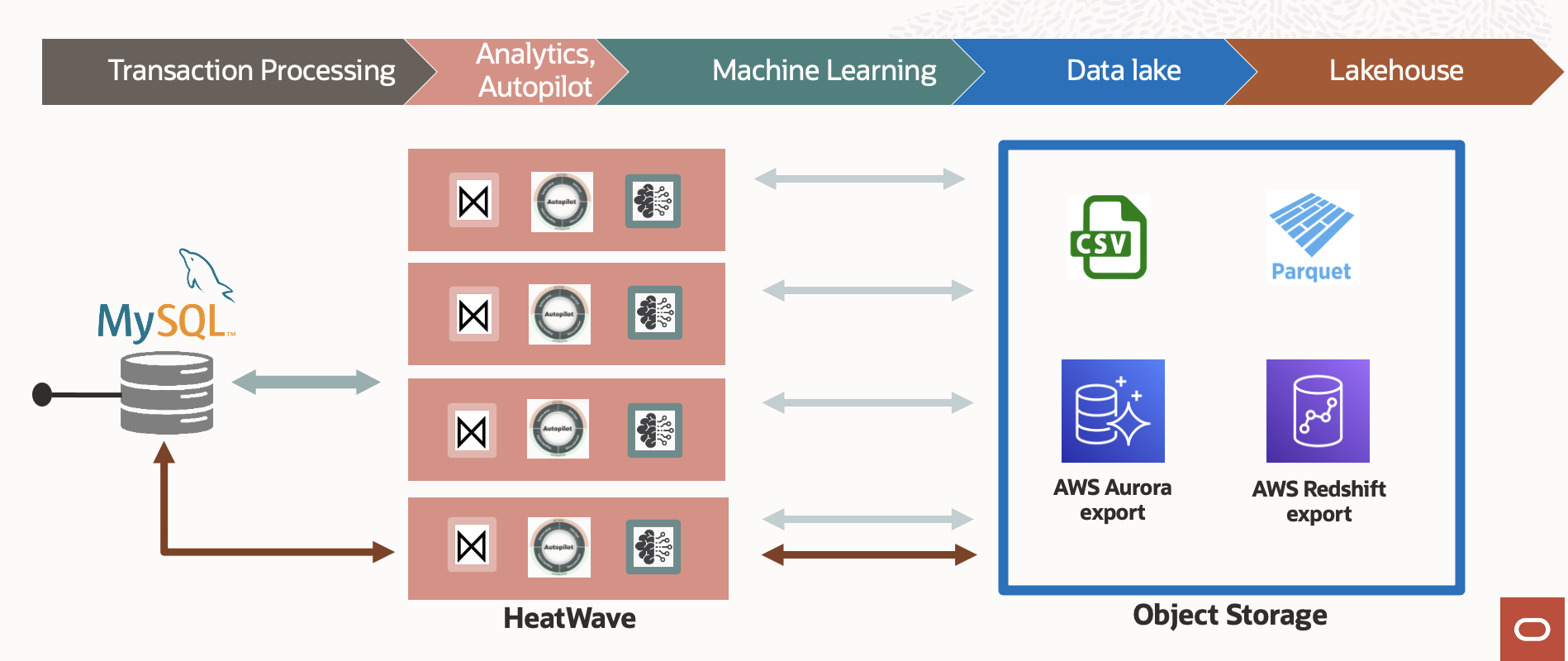
Figure 3: MySQL HeatWave Lakehouse overview
With MySQL HeatWave Lakehouse, users can utilize a single SQL-based query that combines the hundreds of terabytes of data from the object store datalake with the transactional data stored in the MySQL database. Loading hundreds of terabytes is challenging and time-consuming, but MySQL HeatWave Lakehouse uses adaptive, MySQL Autopilot-driven techniques that minimize the amount of data loading and network optimizations to increase aggregate network bandwidth for the object store data load, resulting in industry-leading data load performance.
These methods and further enhancements made to MySQL HeatWave’s highly partitioned architecture play a critical role in achieving high query performance at high scale for MySQL HeatWave Lakehouse.
MySQL Heatwave Lakehouse data load
This Lakehouse utilizes MySQL HeatWave’s highly partitioned architecture to quickly load the data from Object Storage. To load the data, users must run the MySQL Autopilot advisor, which provides helpful recommendations for system setup.
MySQL Autopilot Advisor
To load data into MySQL HeatWave Lakehouse, we first define the table schema using inference performed by MySQL Autopilot advisor. Run the heatwave_load command, triggering the Autopilot functionality to identify many metadata attributes. MySQL Autopilot recommends the create table command with appropriate data types and precisions for the columns in the files with the right MySQL constructs. An example create table command by MySQL Autopilot is shown in Figure 4. Additionally, MySQL Autopilot recommends the appropriate size of cluster based on the data, eliminating time-consuming manual steps to identify the data types of every column in every file and other parameters. MySQL Autopilot performs this analysis in less than two minutes on half a petabyte of data by using adaptive data sampling, which we cover later.
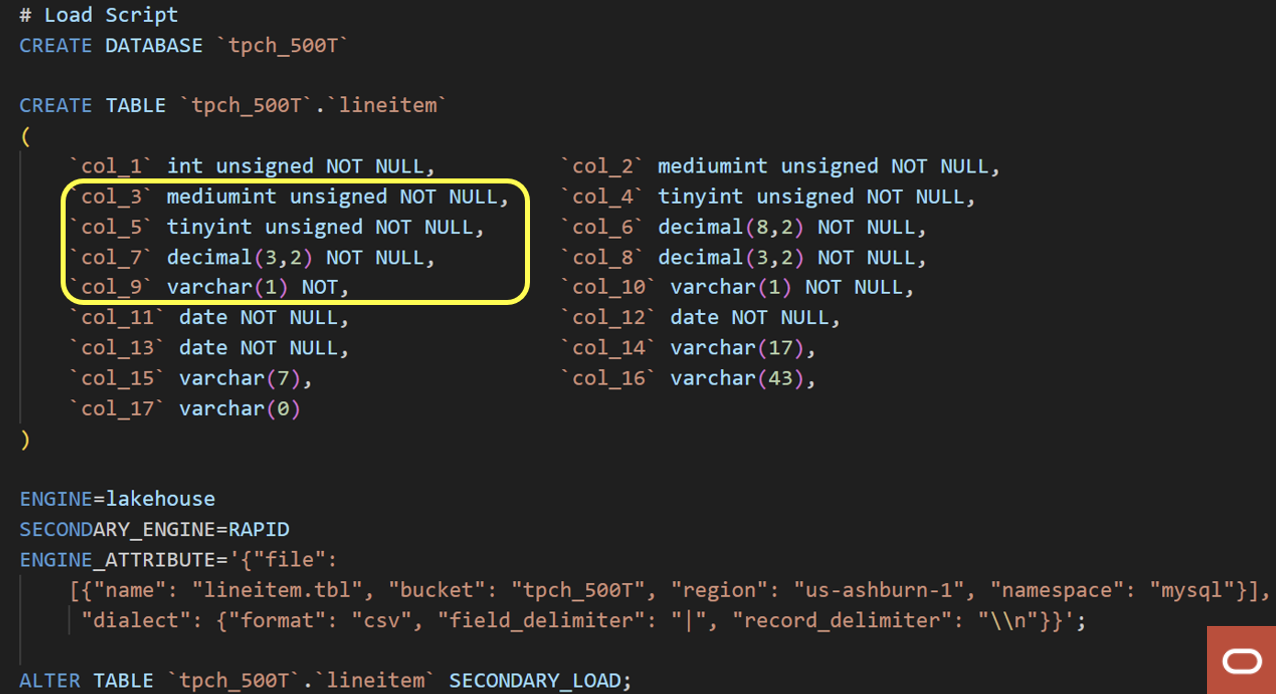
Figure 4: Schema inference by Autopilot Advisor
Data load
After creating the table and initializing the HeatWave cluster using MySQL Autopilot advisor recommendations, the user invokes the alter table command, loading the data from Object Storage into the HeatWave cluster directly. MySQL users use this command to load data from the database to MySQL HeatWave. To load the data quickly, HeatWave utilizes the scale of its cluster with up to 512 nodes for loading data in parallel. When the data load is complete, the system is ready to run queries. This data load process is powered by adaptive data flow, which we break down in a later section. The data is loaded to the HeatWave in-memory store and is not replicated to the MySQL database.
Adaptive data sampling
Adaptive data sampling is a novel ML-based approach used by MySQL Autopilot to predict the relevant metadata and statistics in petabytes of object storage data while loading only a small part of the data.
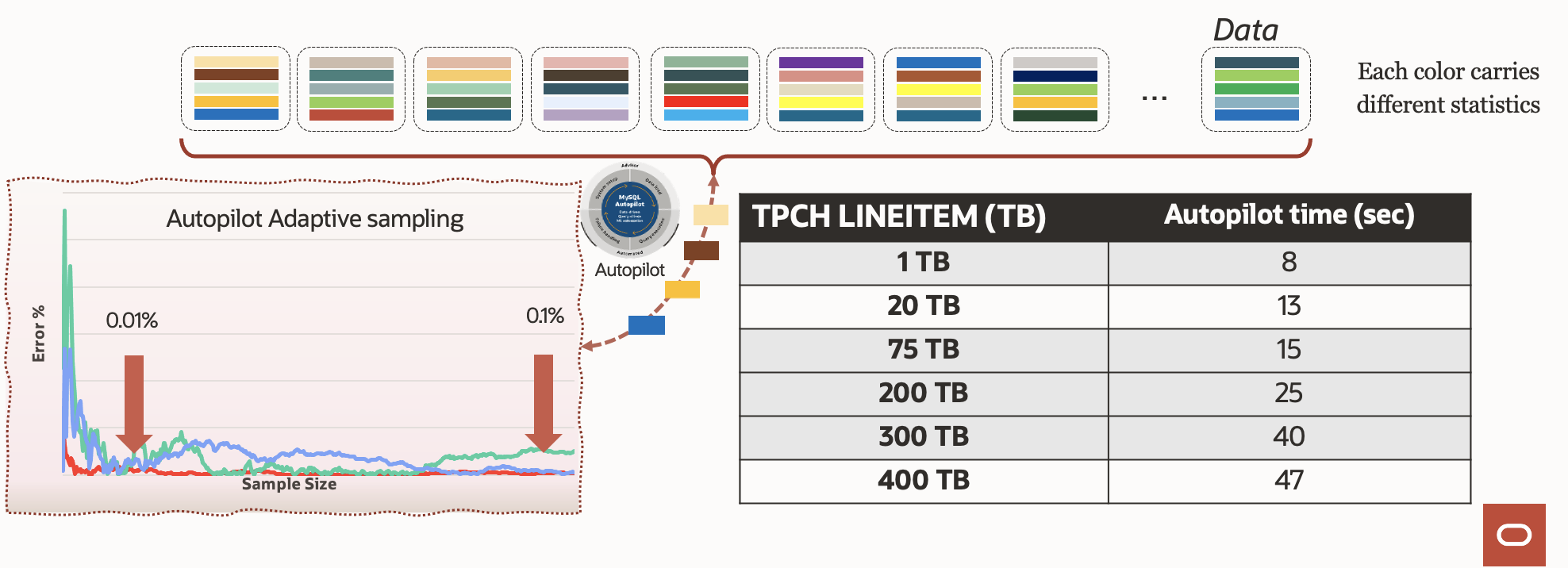
Table 1: Adaptive data sampling
The adaptive data sampling algorithm dynamically determines the right level of sampling to achieve the highest possible accuracy while minimizing the data that needs to be loaded. Let’s walk through an example of estimating the minimum value of a column. Assume we start with a default sampling rate of reading every 100th row. As MySQL Autopilot observes that the statistics gathered with new rows don’t deviate, it switches to a less frequent sampling rate, perhaps every 1000th row. On the other hand, if MySQL Autopilot observes sufficient variance in the sampled data, it adapts the frequency of sampling to every 50th row, and so on. It iteratively performs more sampling until the variance of predicted values ranges within the acceptable threshold, and from the samples gathered uses ML techniques to predict the aggregate statistics. In this manner, MySQL Autopilot completes the inference process quickly and efficiently.
MySQL Autopilot also adaptively samples the data in Object Storage to learn about the required parameters to help with schema inference and node provisioning. Some of these parameters include estimated statistics like the number of columns or rows, the memory required to load the data, expected cluster size, and more. With adaptive sampling, the relevant parameters for half a petabyte of data can be inferred in under two minutes using a single node.
Adaptive data flow
In MySQL HeatWave Lakehouse, data is loaded from Object Storage in a highly distributed manner using a unique approach known as adaptive data flow. When the data load is performed concurrently across all nodes or virtual machines (VMs) of the HeatWave cluster, the goal is to maximize request rate and network bandwidth to Object Storage to minimize data load time.
OCI Object Storage is a cloud-scale multitenanted service that implements dynamic quality of service and throttling across different customers and clients to maintain fairness and mitigate denial of service (DOS) scenarios. Instead of relying on Object Storage to throttle HeatWave, MySQL Autopilot’s adaptive data flow detects the dynamic limits and throttles the requests at the application layer, maximizing throughput and minimizing load times. Each HeatWave node employs this independently with no synchronization necessary.
Lakehouse query performance
MySQL HeatWave Lakehouse achieves the same query performance against the MySQL database and Object Storage. Table 2 shows TPC-H performance benchmark comparison for MySQL and Object Storage query performance.

Table 2: Query performance of MySQL versus Object Storage
To optimize Object Storage data query performance and achieve the same performance for querying data in MySQL database and Object Storage, MySQL HeatWave Lakehouse uses several optimizations, including a unified query engine, an optimized data format, having MySQL AutoPilot compute the necessary metadata for the data from object store, a hypergraph optimizer, and intelligent scheduling of computation and network communication cycles.
Statistics at par with Database
Query processing in the database relies on various metadata attributes of the data, including statistics and histograms about the data value distribution of key columns. This information is valuable in assessing query plan cost and identifying the optimal query plans. While structured databases have these statistics, Object Storage files don’t have them. Instead, MySQL Autopilot’s inferencing capabilities using adaptive data sampling to capture the relevant metadata, enabling unified query engine to operate on data from the MySQL database and Object Storage.
MySQL Autopilot refines the metadata and statistics continuously by learning from previous query results. Consider an address table with a column “state.” The goal is to determine a statistic number of distinct values (NDV) efficiently and other metrics, such as minimum or maximum. Typical databases generate histograms that determine the distribution for Object Storage data. These histograms are precalculated efficiently using adaptive data sampling. When users run queries that analyze the column “state,” the results from the queries are used to further NDV, min, and max metadata. As a user runs more queries, the system learns, and metadata is refined.
Outliers in query plan optimization
When evaluating the performance of a system for query processing, it’s important to consider outliers because a single bad query plan can dominate the run time of the system. MySQL HeatWave has a new hypergraph query optimizer that minimizes the chances of these outlier queries. The new Hypergraph optimizer is targeted towards determining optimal join order in queries, which are typically expensive. The hypergraph optimizer has a multidimensional cost model and traverses a bushy tree, which explores all the possible run paths, which results in optimal query execution. Furthermore, the optimizer evaluates the cost of processing both in HeatWave and MySQL. Because join queries are typically expensive and are the ones that dominate the run time, the Hypergraph optimizer helps avoid outliers. For this and other reasons, HeatWave’s performance is excellent when considering geometric average and the total execution time.
Computation and communication overlap
Source data read is transformed into an internal compressed and optimized format. This format is used in-memory and at-persistence, reducing the cost to the user. The size of data reads and writes per request is carefully tuned to maximize the overlap between data transfer network operations and the CPU-intensive operations. Figure 5 depicts how the VMs allocate CPU- and network-intensive tasks to maximize the utilization of available compute and network resources.
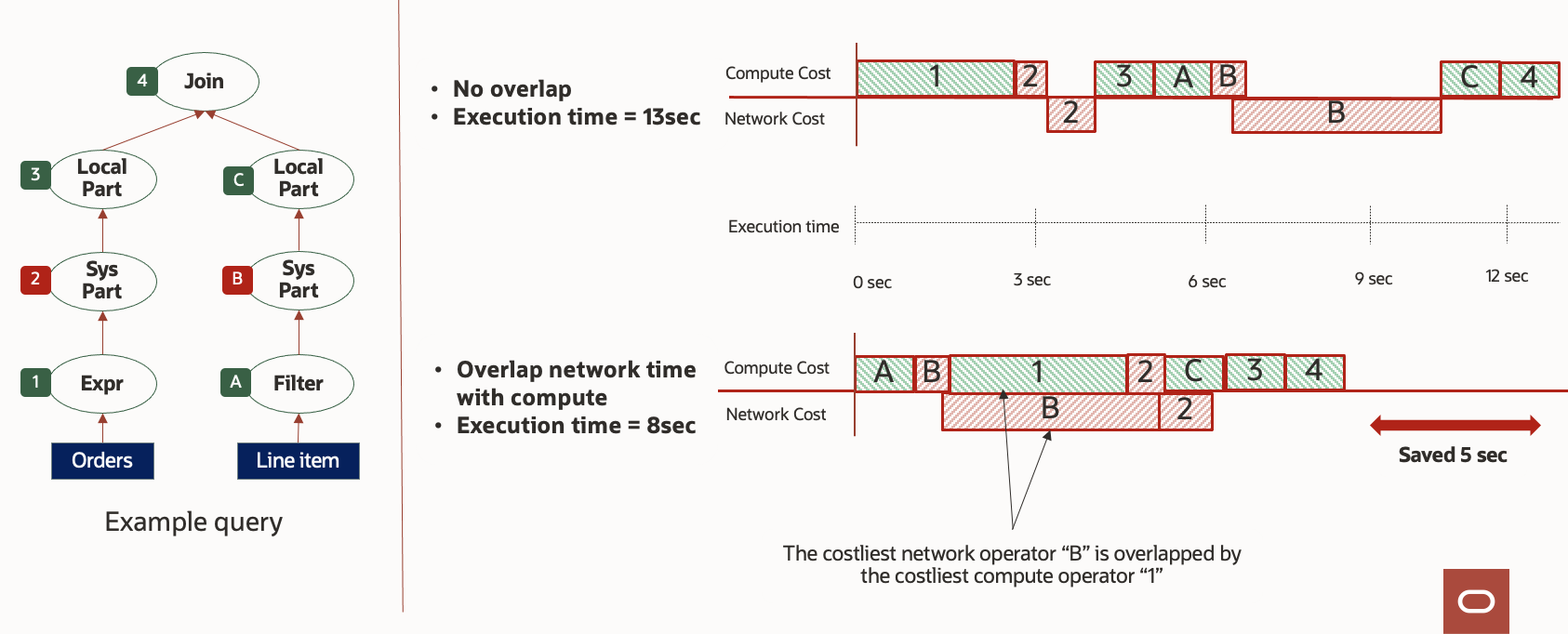
Figure 5: Computation and communication overlap
During query processing, some time is spent in data processing, and some time is spent fetching data. The query process tree in Figure 5 displays fine-grained tasks. With intelligent task scheduling techniques, you can now perform the run of previously sequential tasks in parallel. This parallel run maximizes overlap so that while a data fetch is in progress, instead of waiting for the data, CPU-intensive tasks can continue to run.
Conclusion
MySQL HeatWave achieves industry-leading performance at high scale with the following key characteristics of the architecture, plus novel techniques applied to the entire system:
- MySQL HeatWave’s massively partitioned architecture powers its high performance and scale.
- MySQL Autopilot utilizes ML-based techniques to drive various data processing optimizations, lessening the burden on developers and database administrators.
- MySQL HeatWave provides real-time analytics on top of transactional data.
MySQL HeatWave Lakehouse saves time and money for organizations looking to query data in OCI Object Storage or across their data warehouse and object storage, all with optimal performance. This dramatically reduces the time between wanting to know and obtaining the answer to a complex business problem that spans a variety of data formats.
Using HeatWave’s innovative, ML-powered techniques as part of its MySQL Autopilot system achieves the following performance breakthroughs and noteworthy optimizations:
- Adaptive data sampling provides an efficient way of gathering Object Storage statistics to generate and improve query plans, determine the optimal schema mapping, and more.
- Adaptive data flow uses highly partitioned architecture and innovative algorithms to load data from Object Storage near its bandwidth.
- The Hypergraph optimizer enables MySQL HeatWave Lakehouse to achieve top-notch query performance for processing data from Object Storage and the MySQL database while eliminating outliers.
Oracle Cloud Infrastructure (OCI) Engineering handles the most demanding workloads for enterprise customers that have pushed us to think differently about designing our cloud platform. We have more of these engineering deep dives as part of this First Principles series, hosted by Pradeep Vincent and other experienced engineers at Oracle.
For more information, see the following resources:

