We’re excited to announce a new release of Oracle Cloud Infrastructure (OCI) Data Catalog. In this release, we accelerate the cataloging of your data by automating the discovery and creation of data assets for technical metadata harvesting. We also simplify metadata enrichment with bulk upload capabilities. Data providers can easily and quickly populate their catalog with rich technical metadata and business context. Data consumers can quickly gain value from the catalog for search and discovery of assets in the enterprise.
OCI Data Catalog is a cloud native service used to discover, organize, enrich, and trace an organization’s technical and business data assets. For a business user, such as a data analyst or business analyst, the key value of a data catalog comes from the ability to identify the right business data easily and quickly. For more information on this topic, check out What is a Data Catalog?
New features of Data Catalog
Auto-discovery of data sources
OCI Data Catalog provides a holistic view of data in the organization by bringing together technical and business metadata. Considering the number and types of data sources available in organizations today, manually searching and creating data assets in the catalog can be time consuming. Plus, you might miss something, or you might make a mistake creating data assets! Why not let the system do the work for you?
OCI Data Catalog now allows for the system to automatically discover the data sources available in your tenancy. Choose the region and compartments and leave the rest to the system. You can discover Autonomous Data Warehouse databases, Autonomous Transaction Processing databases, Oracle database, Object Storage buckets, and so on. The system even brings in the configurations, so that information is prepopulated for you to create data assets and corresponding connections. Provide the remaining information like user credentials and harvest.
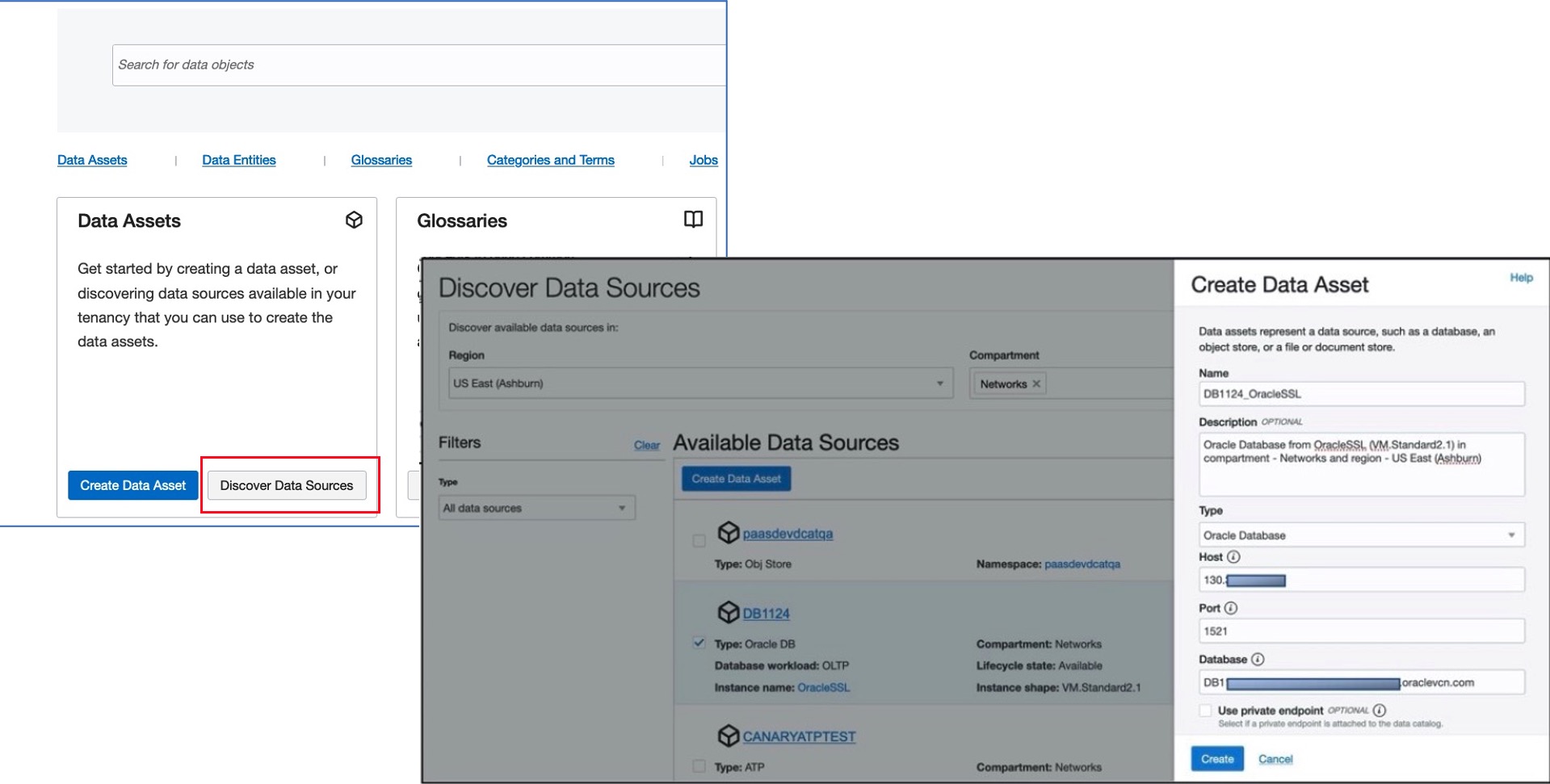
Figure 1: Discover data sources and create data assets
Accelerating metadata enrichment
Let’s first do a quick refresher on custom properties. Custom properties allow you to define your own properties for specific metadata enrichment needs. This capability helps users annotate the harvested system metadata in OCI Data Catalog.
For example, they can define business description, update frequency, data owners, providing a mechanism for data experts to contribute business context to technical metadata beyond simple tagging or linking glossary terms. When this rich information is populated for different data sets and fields, it helps with discovery, classification, and overall understanding of the data. Data providers have an organized way of sharing this information so that they don’t have to keep answering questions from data consumers. For more information, check out Better Collaboration Using Improved Metadata Curation, Search, and Discovery for Data Lakes with Oracle Cloud Infrastructure Data Catalog’s New Release.
But populating custom property values one by one for each object can be time consuming. This new release allows population in bulk in user-friendly MS Excel format, accelerating the enrichment process. It also provides simpler review of the content. The process is straightforward. First, harvest the wanted technical metadata and create the custom properties. Then, export the technical objects and the associated custom properties into an Excel file. Use this file to add and update the values for those properties and import it back into the Data Catalog.
Currently, this feature is available for data assets created using a relational database, such as Oracle Database, Autonomous Database, Microsoft SQL Server, and MySQL. You can export and import custom property values at the schema and data entity levels.
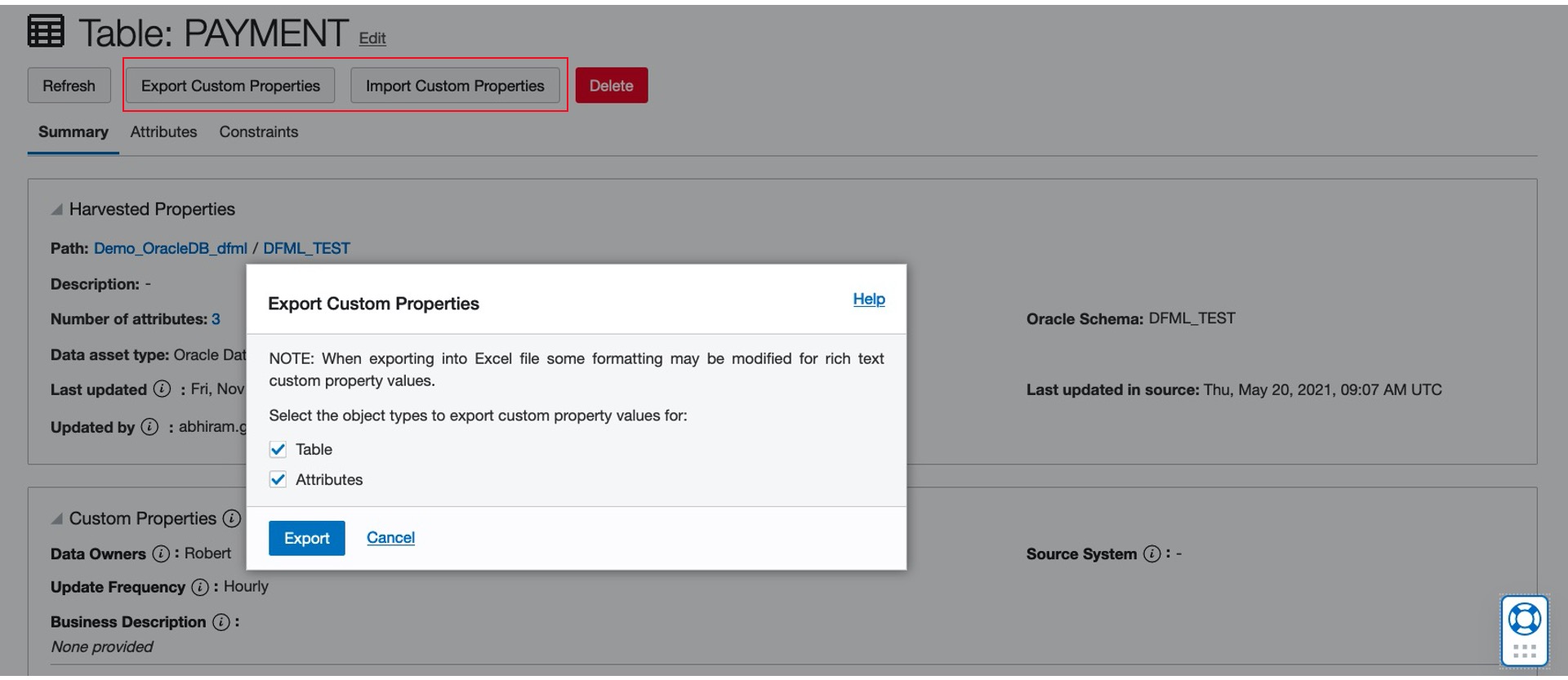
Figure 2: Export and import custom property values
Hive-compatible metastore
OCI Data Flow is a fully managed Apache Spark service that processes tasks on extremely large data sets. For OCI Data Flow to read, write, and manage operations on such large data sets, OCI Data Catalog provides a hive-compatible, persistent metastore. With the Data Catalog metastore, a Data Flow user can now securely store and retrieve schema definitions for objects in unstructured and semi-structured data assets, such as Object Storage using a hive metastore interface.
More to come on this feature in a future blog. Stay tuned!
This release also has numerous enhancements and improvements, like support for SSL enabled data sources, ability to bookmark a specific object detail page, pre-authenticated request-based connections to Object Storage buckets, and many more. Check out all the new features in the latest release of OCI Data Catalog.
Conclusion
This new auto-discovery of data assets and the extensions in enrichment of the metadata help identify data in a scalable manner, considerably reducing the time to value of the catalog for any organization.
Organizations are embarking on their next-generation analytics journey with data lakes, autonomous databases, advanced analytics, artificial intelligence, and machine learning in the cloud. Data Catalog helps support discovery, insights, and governance of data assets. The current capabilities of Oracle Cloud Infrastructure Data Catalog are available to Oracle Cloud customers at no extra cost, providing customers with great value-added capabilities! Try it out today!
For more information, review the Oracle Cloud Infrastructure Data Catalog documentation and associated tutorials.
