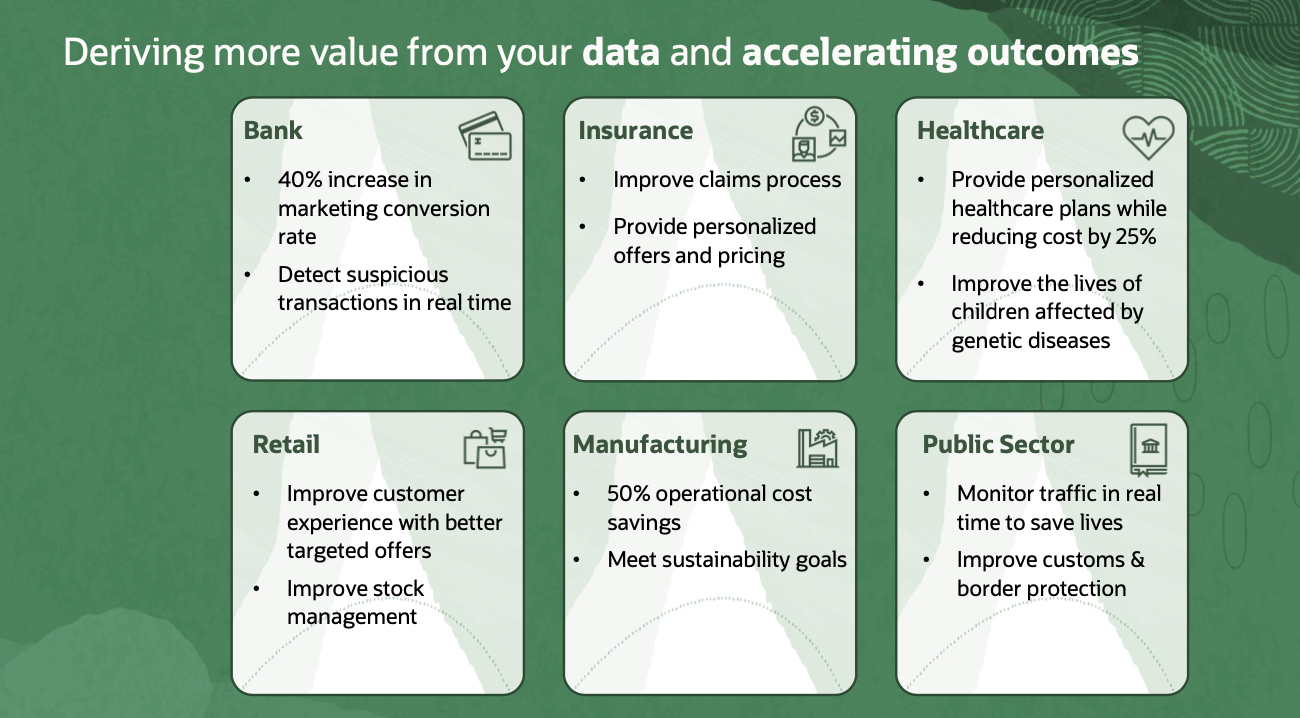
Want business success? Data is key. The right data and analytics can enable tremendous outcomes. We’ve seen a banking customer with a 40% increase in marketing conversion, a healthcare company reduce costs by 25% while still personalizing care plans, and a manufacturing customer achieve 50% savings on operational costs. The possibilities are exciting.
Despite these and many other success stories, however, we still see organizations struggling to build useful and capable data environments. This occurrence isn’t recent, with the following challenges facing companies rooted in history:
-
Data is scattered throughout business units and application systems.
-
Accessing data and moving it between systems is complex and adds latency.
-
Information lives in different formats at different stages in a myriad of business processes.
The first solution
The first solution at creating an analytic data architecture was the data warehouse. A large database consolidated data from internal databases and potentially external sources, such as market data. It used the classic strategy of centralization.
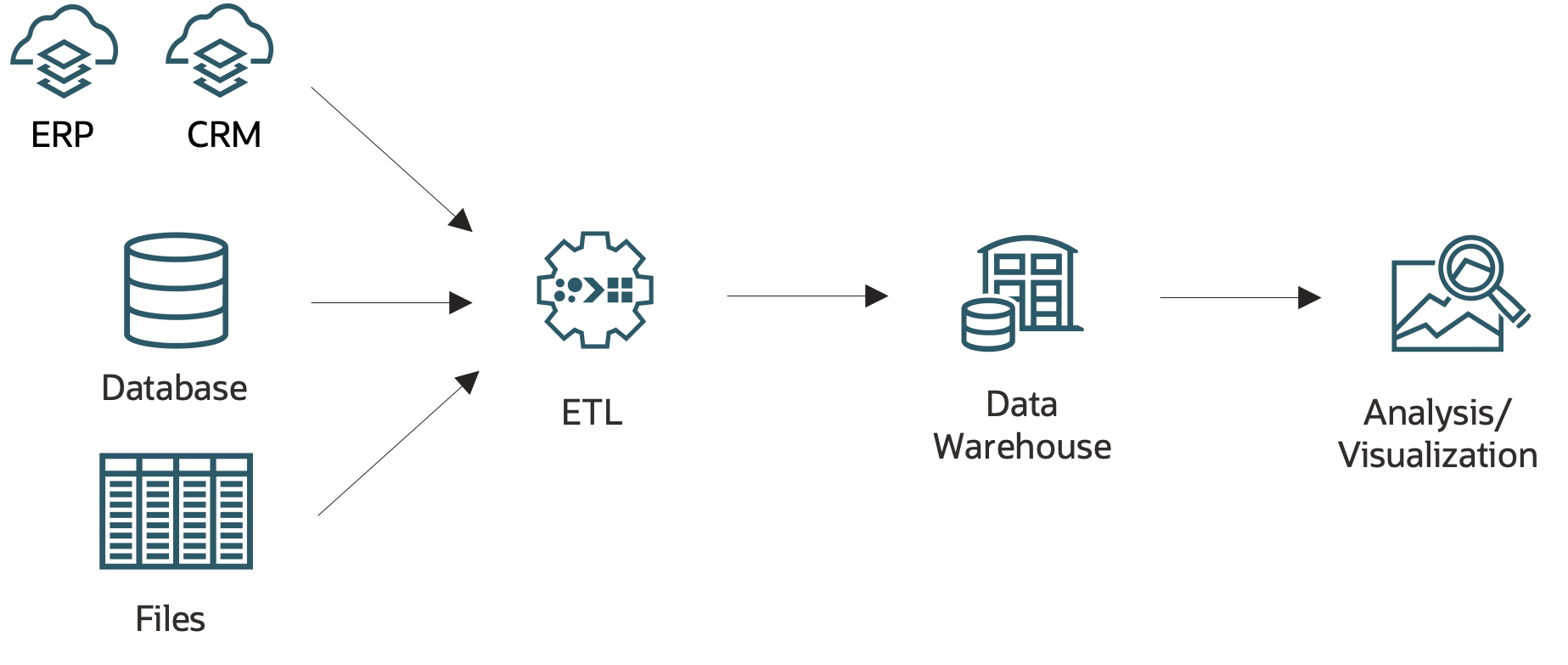
The traditional data warehouse addressed the following challenges:
-
Sparked an industry around extract, transform, load (ETL) tools and methodologies to move, cleanse, and remove duplications from the data into a consolidated database
-
Required data that originated in different systems to be standardized, which allowed for analysis
-
Spurred domain-specific views, which mapped to business processes and metrics
-
Provided a single repository for visualization tools
Unfortunately, as good as the improvement was, the data warehouse didn’t solve everything. It still had the following issues:
-
Every point of integration (every source system) required time to investigate, design, code, test, and implement. Adding a new system is an arduous process.
-
Any change in the source system required validating every step of the integration process. The data warehouse can quickly become fragile and break with application updates.
-
Moving data from source systems was weekly or daily, which meant that the data warehouse can be one or more days behind. The choice was to show the latest with missing pieces or limit the view to the last data load.
The next solution
As data warehouses multiplied, so did the scale of the data, which we referred to collectively as “big data.” Big data brought its own set of challenges (all conveniently starting with V):
-
Volume: The amount of data. We had more data than could fit on a single server. We wanted to keep it all, but we weren’t sure exactly which data was the most valuable, so we needed something that was both efficient and economical.
-
Velocity: How often the data was received. Instead of the occasional batches that rolled in monthly, data could arrive daily, by the hour, or even in real time. We needed something that could ingest data from multiple sources at different rates.
-
Variety: The diversity of data formats. Data was no longer in well-structured columns and rows but consisted of images, audio, video, logs, and so on. (According to Forbes, most data now collected is unstructured.)
The next solution for an analytic data architecture took advantage of the cloud revolution: The data lake. The data lake focuses on cost-effectiveness to store “everything” for future analysis.
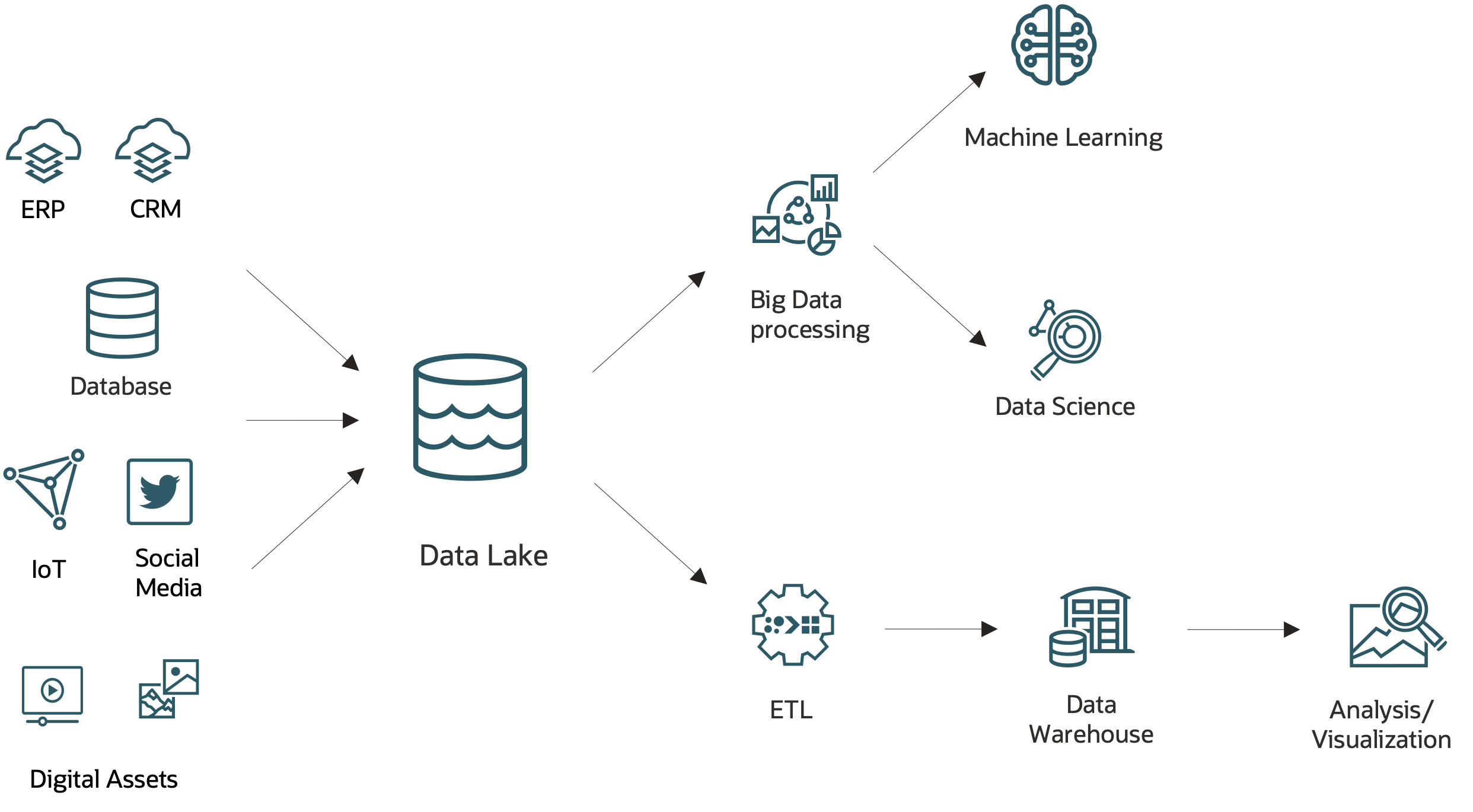
The data lake taps into the (almost) unlimited object storage of the cloud to preserve all data, regardless of immediate value. It rapidly accepts new data because object storage is a distributed service, and it accepts data in any format. Because it doesn’t enforce structure or format, the data lake removes almost all delay between data updates in the source system and data being stored in the data lake.
However, the disparate nature of the data in the data lake requires advanced analysis tools to make sense of that data. That requirement can be a big drawback. Data lakes require a higher level of expertise, such as a data scientist and machine learning models, to extract value. Otherwise, the data lake becomes a data swamp.
A solution for today
Today, our needs have increased manyfold, including the following examples:
-
A unified data platform: Today’s data management project involves the collaboration of data engineers, data scientists, analysts, and more, all typically working on disparate systems with more infrastructure and synchronization issues.
-
Support for open source: Some of the most popular analytical tools are supported by the open source community. This support encourages collaboration and sharing of best practices but can be resisted by closed source vendors.
-
Integration of artificial intelligence (AI) and machine learning (ML): The advancement of AI and ML has ushered in a revolution in capabilities. Analytical systems must support pretrained and trainable services to provide maximum value.
-
Pay-as-you-go pricing: Analytics can use a lot of storage and a varying amount of compute. Paying only for what you use helps keep costs down, while providing resources when needed.
-
Support for multicloud: No cloud has everything, and depending on one cloud can be a strategic risk. Companies prefer a best-of-breed solution where the data goes to the most capable service.
Are we doomed to live with a data warehouse that’s too rigid or a data lake that’s too incoherent? What if there’s another way?
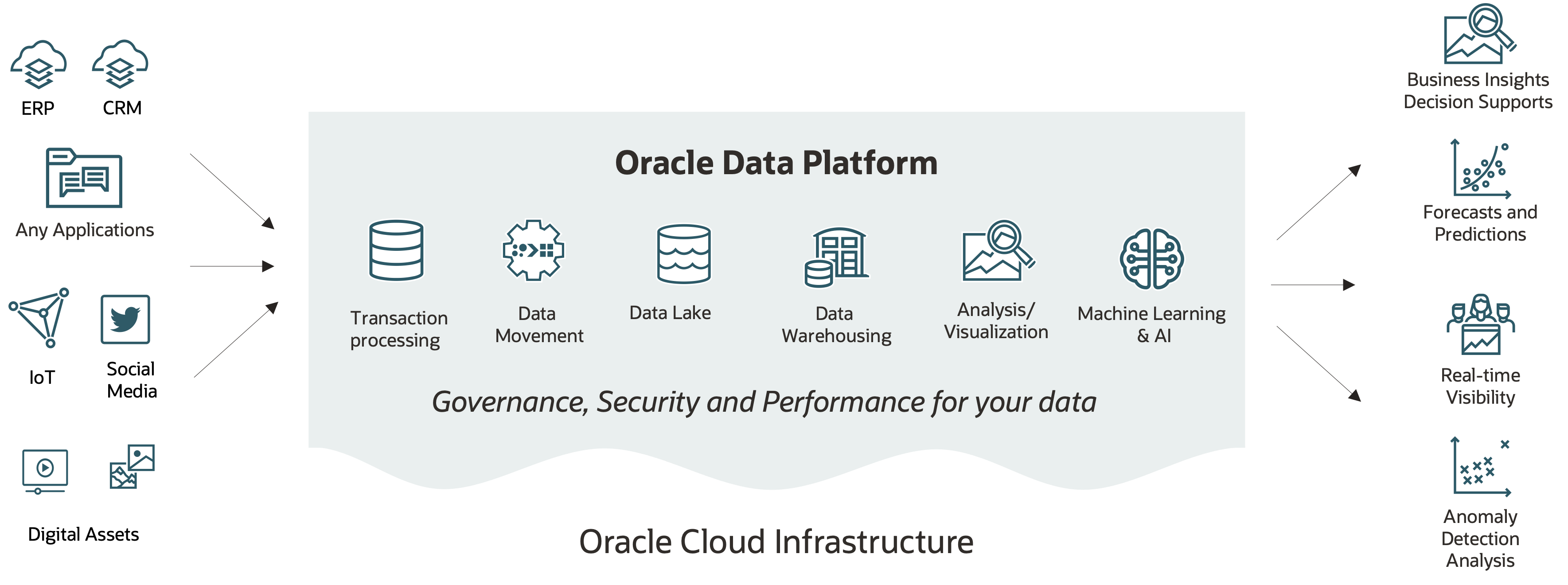
The Oracle Data Platform is a modern data cloud platform with an architecture that provides for the needs we’ve covered. It breaks down the barriers between structured and unstructured data, provides faster and deeper insights on a platform, works with other clouds, and provides pay-as-you-go pricing.
Next steps
Identifying the solution is only the first step. In the next two blogs, we look at the best practices in this architecture and then wrap up with real-life successful implementations.
Explaining Modern Data Management Part 2
Explaining Modern Data Management Part 3

