In this blog, we describe the full pushdown capability in Oracle Cloud Infrastructure (OCI) Data Integration data pipelines. We discuss a recent enhancement that increases throughput by extending the concurrent processing of jobs from dozens to hundreds. This enhancement translates to reducing hourly processing time and leads to cost savings. According to the current licensing model of Data Integration, we observed a 50–80% savings in the dollar cost of running a task with equivalent data volume.
Recent enhancements in OCI Data Integration improve ETL performance and reduce cost
In the latest release, we optimized the logic for determining when to do a full pushdown. The decision whether we can do a full pushdown has moved to an earlier point in the flow. The optimization is useful when we have many jobs that we want to run in a short time. We reduced the latency of running the task when a full pushdown runs. More significantly, we removed a bottleneck. We now allow hundreds of jobs to run concurrently, instead of dozens of jobs earlier. Earlier, we were using a sledgehammer to crack a nut. Now, we’re using a nutcracker.
Before presenting the performance enhancements and cost savings, we explain what pushdown optimization means. Pushdown refers to a data processing optimization technique in data integration and extract, transform, load (ETL) processes, where all applicable transformations run directly within the database. Instead of performing the transformations within the data integration service or framework, the transformations are pushed down to the database. This process uses the typically larger allocated capabilities on the database, reducing cost and improving performance and efficiency. Pushdown optimization plays a crucial role in improving job performance and reducing data movement by running transformations directly on the database server.
You can utilize the OCI Data Integration data flow to design and implement data transformations in data pipelines for their use cases around data migration, data warehousing, and data lakes within the OCI environment.

While the platform frees you from the need to write complex code for the data transformation, you can optimize the code in some cases. For example, in the example data flow, if all the tables are on the same database, you can run the transformations on the database instead of as an external job in a separate staging area.
Pushdown optimization is the capability of a Data Integration data flow to recognize and take advantage of these optimizations. In pushdown optimization, we push transformation logic to the source database. OCI Data Integration provides a general and expressive data transformation capability, while allowing optimization for appropriate cases.
Approaches to transformations in data pipelines
In data pipelines in the Data Integration world, you have two main approaches: extract, transform, and load (ETL) and extract, load, and transform (ELT).
In the ETL approach, data transformations are typically carried out in a separate staging area that exists outside of the data warehouse. This approach proves beneficial in scenarios where the transformations are complex or when the source and target databases are hosted on different servers. Additionally, the utilization of a staging area becomes necessary if the database lacks sufficient memory or storage resources. However, employing a separate staging area involves the movement of data between systems.
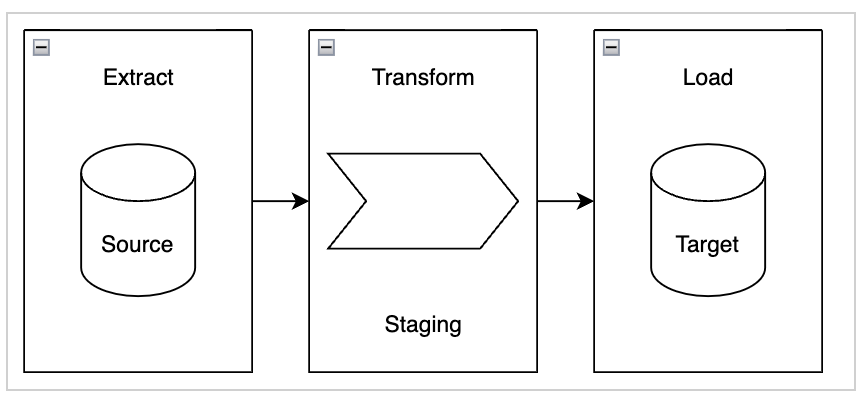
In the ELT approach, data transformation is performed in the source or target system without the need for a separate staging area. This method reduces the amount of data movement between systems. It’s best suited for cases where the source and target systems are in the same database, and the transformations are simple enough to be done within the database itself. When we eliminate the staging area, we use pushdown optimization.
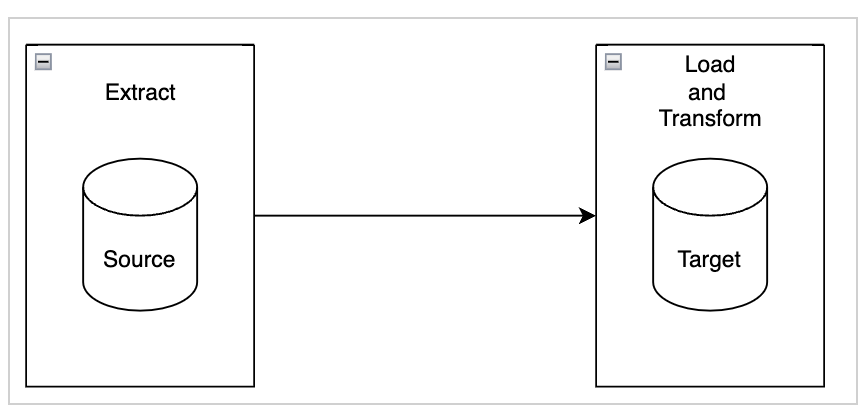
Types of pushdown optimization
Pushdown optimization has three types: Source, target, and full pushdown.
When we push down some of the transformations to the source database and run the remaining transformations in an external program in a separate staging area, we’re doing source pushdown. When we push down some of the transformations to the target database and run the remaining transformations in an external program in a separate staging area, we’re doing target pushdown. Full pushdown is where the sources and targets are on the same database and all transformations are done in the database with no separate staging area.
How to use pushdown in OCI Data Integration
By default, OCI Data Integration’s data flows use pushdown optimization. When configuring a data flow job, you have the flexibility to choose whether to enable or disable pushdown, as illustrated in the following figure. Enabling pushdown optimization enhances job performance and minimizes data movement. This flexibility enables you to adapt to varying resource capacities, such as database memory and load, and make informed decisions regarding the execution location of your jobs.
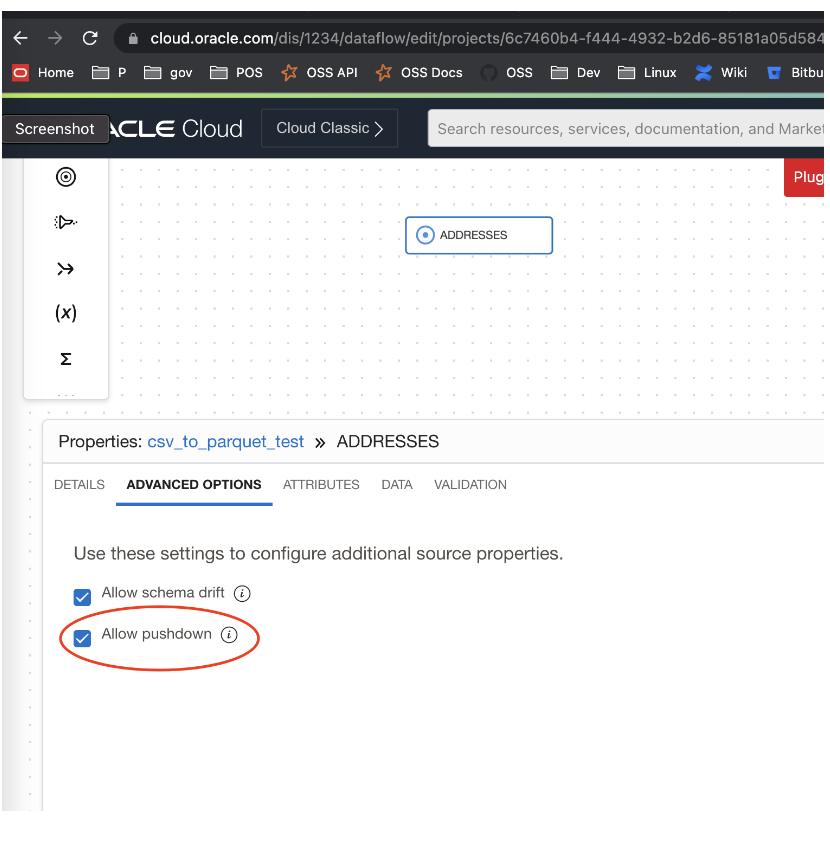
Full pushdown optimization does all transformations in the database. It loads all the data to the target database without any staging area. On the other hand, partial pushdown optimization divides the transformations, running some of them on the database server while moving the remaining transformations to a designated staging area.
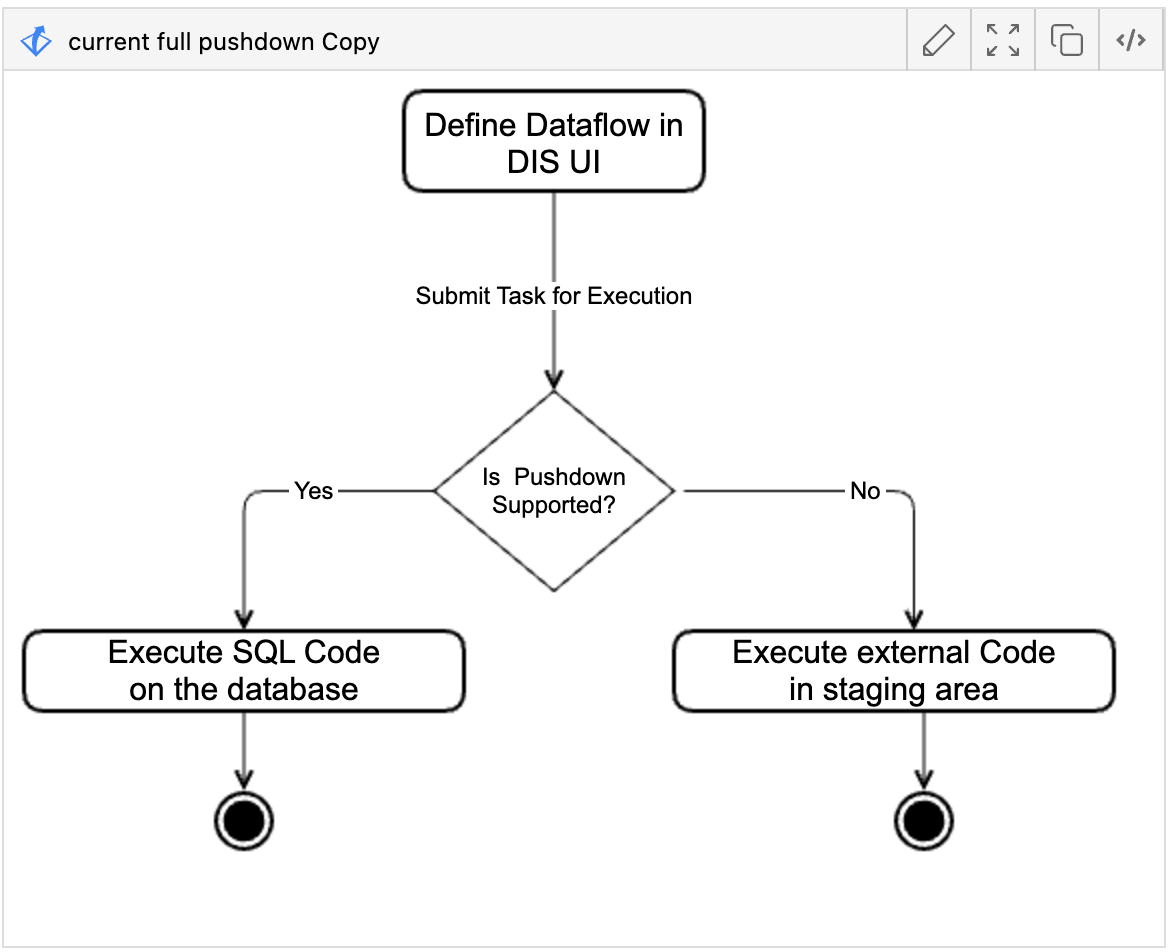
The following diagram shows the logic for deciding when to do pushdown optimization.
-
When you create a data flow job, the option to allow or disable pushdown is available.
-
When the job is submitted for processing, if pushdown is enabled, Data Integration determines if the conditions for pushdown are met.
-
If the conditions for pushdown optimization are met, we run the SQL code on the database (Left branch)
-
If the conditions aren’t met, we run the external code for the transformation in a staging area (Right branch)
Full pushdown is performed when the following conditions are present:
-
In a data flow with a single source and target, both the source and target use the same connection to a supported relational data system.
-
In a data flow with multiple sources and targets, all the sources and targets must also use the same database and connection.
-
All the transformation operators and functions in the data flow are supported in the database.
Impressive performance and cost improvements
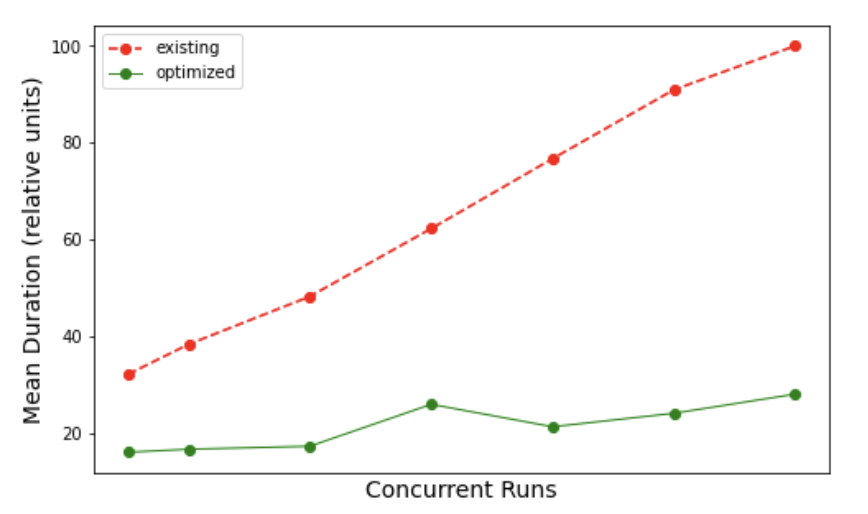
The following diagram shows the higher number of concurrent jobs that can be handled when we run the optimized code. Using the software developer kit (SDK) we submitted tasks at different concurrency levels and noted the mean task duration. We did the hundreds of runs using code prior to the optimization and repeated the same experiment using optimized code for comparison. Before the optimization, the job run mean duration increased linearly with the level of concurrency. The linear increase is caused by the throttling that was present before optimization.
By removing the throttling, we can now run many more concurrent requests. At lower levels of concurrent jobs, the optimized code demonstrates a significant 50% improvement in performance. We can attribute this notable difference to the reduced latency achieved through optimization. Moreover, the advantages of this optimization become even more apparent and increase exponentially as the concurrency levels increases, showcasing its capability in handling higher workloads with enhanced efficiency.
Because we no longer use an external server in the staging area for full pushdown optimization, the cost for running the job is also significantly lower. According to the current licensing model of OCI Data Integration, we observed a 50–80% savings in the dollar cost of running a task with equivalent data volume.
Summary
The latest release of OCI Data Integration improves the logic for determining full pushdown feasibility, reducing latency and removing bottlenecks. This enhancement enables concurrent processing of hundreds of jobs and improves overall efficiency. This optimization ensures a smoother and faster data processing experience for users.
OCI Data Integration offers the flexibility to determine whether to enable or disable pushdown optimization during job creation, allowing you to handle scenarios where the database might have more compute and memory capacity. Pushdown optimization enhances job performance and reduces data movement by running transformations on the database server. Full pushdown optimization is performed when specific conditions are met, such as using the same connection for the sources and targets in a single ETL flow, and you can implement all the transformations efficiently on the database.
Through this blog, we explained the capabilities and benefits of full pushdown in Oracle Cloud Infrastructure Data Integration, which empowers users to unleash the full potential of pushdown optimization. You can now use this powerful feature to achieve remarkable acceleration in your workloads leading to significant gains in both productivity and cost efficiency. You can now bring in more complex use cases to achieve higher levels of concurrency as described in the Data Flow documentation.
For more information, see the following resources:
-
Full pushdown reference in OCI Data Integration
-
Primer on designing OCI Data Integration data flows
-
Read more details about OCI Data Integration
-
Details on OCI Data Integration SDK


