At Oracle Cloud Infrastructure (OCI), we aim to process large amounts of security data in near real time for our customers. We operate a hyperscale Apache Flink cluster to power Cloud Guard, our security posture monitoring service. OCI draws on Apache Flink as a data processing pipeline, processing resource configurations and activities data across regions, and presents a single-pane-of-glass view of security posture to our customers.
In this post, we provide an overview of Cloud Guard’s Flink architecture and highlight how we used Flink to successfully diagnose and overcome two specific scaling challenges. We hope customers can draw on the insights we gained to streamline and troubleshoot application scalability holistically, beyond the Flink framework.
First challenge: Weird out-of-memory errors
After our initial rollout of Flink, we built a couple of new Flink batch jobs that were scheduled to periodically ingest bounded streams of data. After several successful runs, new job submissions started failing even though the environment was unchanged. We looked at the usual suspects—CPU, heap, and disk metrics—but nothing was out of the ordinary. But the following strange error in the logs appeared:
Caused by: java.util.concurrent.CompletionException: java.lang.OutOfMemoryError: Metaspace
at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:273)
at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:280)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1606)
... 7 more
Caused by: java.lang.OutOfMemoryError: MetaspaceAfter this error was encountered, the Flink cluster refused to accept new jobs.
Before we jump into the diagnosis and solution of this problem, it is important to understand the underlying data pipeline architecture. The architecture is standard, but the scale is not. Our data pipeline currently runs in 30+ production regions and ingests billions of records per day for Oracle customers globally.
Flink Pipeline Architecture
The following diagram shows the building blocks of the Cloud Guard Flink pipeline:
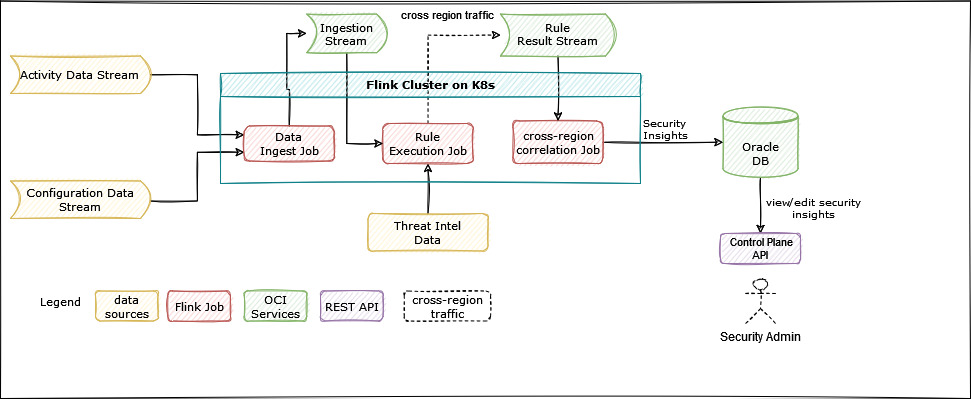
Figure 1: Flink pipeline architecture
This diagram shows the following main aspects of our design:
-
Data sources: Data sources are raw inputs of data to Cloud Guard with two main types: Resource configuration data and activity log events. We also use threat intelligence data from Oracle Threat Intelligence service to flag malicious activities.
-
Data processing pipeline: Flink jobs form our data processing pipeline. Each job is decoupled from other jobs through a stream hosted by OCI Streaming service.
-
Dependent services: We use Oracle Autonomous Database to store security posture insights and OCI Streaming to store intermediate computation results.
The following overview shows how each job contributes to the pipeline:
| Job name | Description |
| Data ingest job | An entry point in the pipeline. It consumes raw data, filters out bad records, and converts curated records into a format usable by the rule run job. |
| Rule execution job | This job performs the following tasks:
The results of the job contain information about impacted resources, activities, and actual rule run results. For example, a security posture monitoring rule can flag publicly exposed OCI Object Storage buckets. When this rule triggers, it emits a result with the bucket name, ID, region, compartment where the bucket exists, and includes a detection timestamp. |
| Cross-region correlation job | Correlation ingests cross-regional rule run results and collapses them into fewer results if necessary. The outputs of the correlation job are actionable security insights, which are stored in Autonomous Database. |
All processing happens through Flink jobs. Each job consumes data from a stream and produces data to another stream. Input and output formats for each job are well-defined, and those formats continue to evolve depending on new features and changes. All jobs share resources on the data plane Flink cluster and Oracle Database.
That’s how our Flink pipeline works. Now, back to the out-of-memory error.
Debugging Out-Of-Memory Errors
The Flink cluster accepts jobs through the job manager, which is a Flink component responsible for managing the lifecycle of jobs running on the cluster. The out-of-memory (OOM) error shown was present in the job manager logs. Usually, the job manager resource usage is low, so it was puzzling to have it running out of resources. Job manager was running but rejected new job submissions. Strangely, even if the error looked like job manager ran out of memory, it didn’t run out of heap. Instead, it had run out of metaspace.
Metaspace is where Java Virtual Machine (JVM) stores class metadata, which is information about Java classes necessary for code execution. Metaspace memory is not part of heap and is separately allocated using a JVM flag. Classes are loaded into metaspace by Classloader, a JVM component that loads necessary classes from JVM classpath to metaspace. The problem was that each new job submission required new classes to be loaded and job manager JVM was unable to load more classes into memory. This error resulted in job submissions failing.
We started watching metaspace metrics carefully and noticed a strange trend. Every job run would decrease available metaspace. As more jobs continued to run and finish, the metaspace was completely exhausted.
We reproduced the problem locally by reducing metaspace size. By attaching a profiler to the JVM and taking a clean slate memory dump before submitting the first job, we created a known baseline. Then, we looked at the metaspace state each time a job was submitted. The following image shows the details:
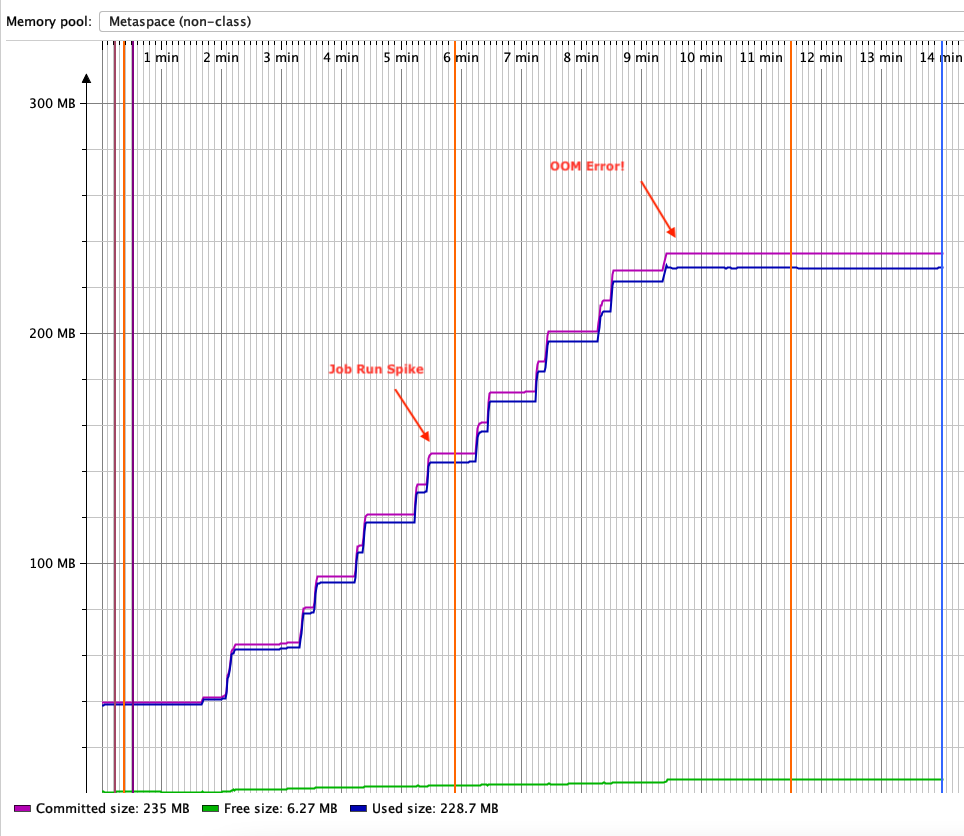
Figure 2: Metaspace OOM graph
With each job run, we would see a spike in used metaspace (marked as “job run spike” in red). Eventually, all usable metaspace was exhausted (marked by “OOM error” in red), and job submissions started to fail.
From this metric, each job run was causing classloader memory pool leakage. This leak occurs when JVM can’t remove unused class metadata from metaspace to load more classes. A common cause of classloader leaks is a dangling reference to one or more loaded classes, such as an orphan thread. The investigation of these revealed some orphan threads created out of each job run, as shown in the following image:
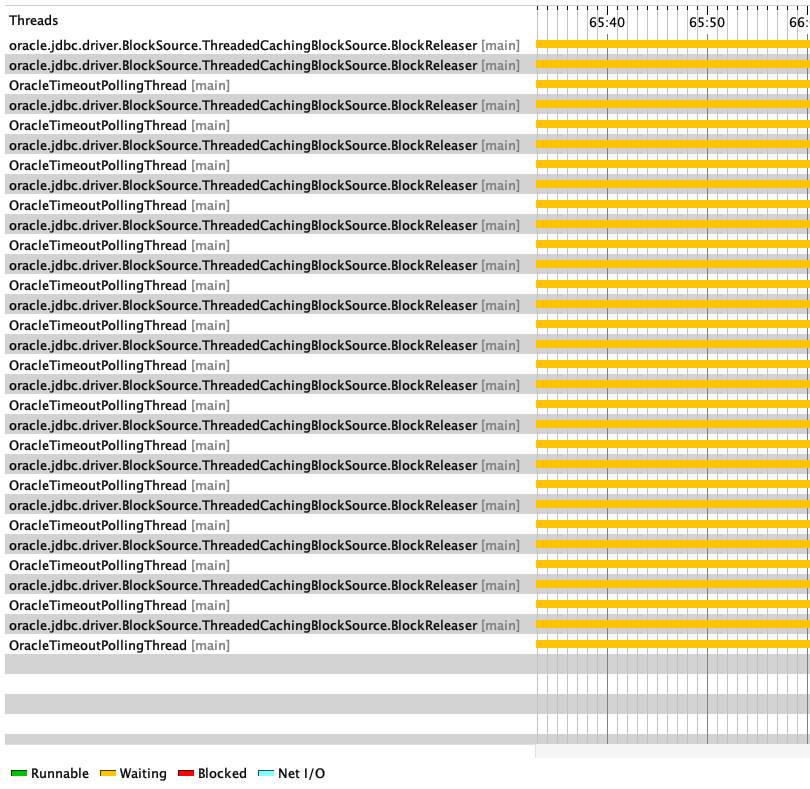
Figure 3: Orphan threads
Strangely, our JDBC driver spawned these threads, not our application threads. Because the threads outlived the job and kept running, classes that spawned those threads weren’t unloaded from metaspace and eventually caused metaspace exhaustion.
It didn’t make sense at first, but we were onto something with orphaned threads. We traced those threads back to their origins and found that, in some cases, we were leaking database connections. Some execution paths borrowed a connection from the connection pool and failed to return it. The threads that we found in thread dumps were associated with those orphaned connections, which were used for bookkeeping tasks for connection management. Each job run had some connection leaks, meaning that the threads managing those connections were orphaned.
After a review and update to all database-related code to correctly relinquish borrowed connections from the connection pool, we verified the fix reviewing metaspace usage:
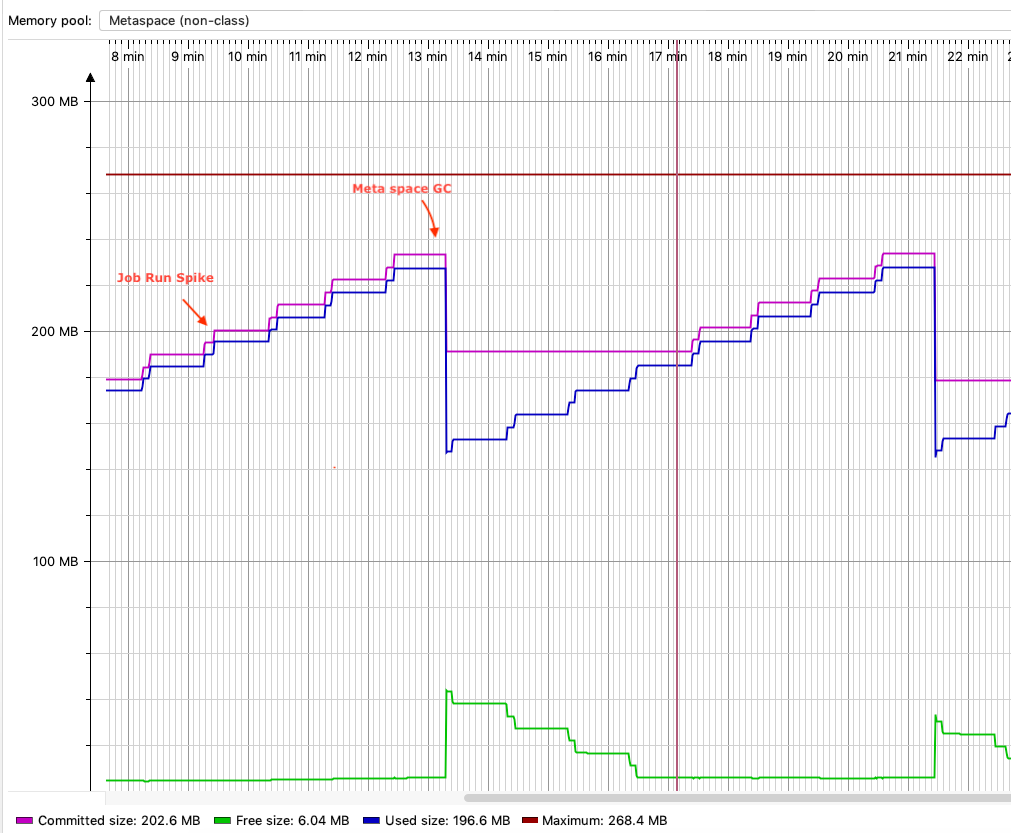
Figure 4: Metaspace graph post fixes
You can still see the spike in metaspace usage during job runs (marked as “job run spike” in red), but when the JVM determines that it needs more metaspace memory, a garbage collection is run that frees up metaspace (marked as “metaspace GC” in red). Subsequent runs continue to load more classes as needed and clean up as needed.
A key takeaway is to closely monitor the number of threads and metaspace usage in the Flink cluster. A steady rise in any one those metrics would eventually lead to stability issues and performance problems in your pipeline.
Second challenge—Strange Socket Errors
Changing our database connection pooling strategy led to a second challenge. Before we take a deep dive into this issue, it is important to understand how a Flink cluster works. Flink uses a distributed execution model to run jobs as shown in the following figure:
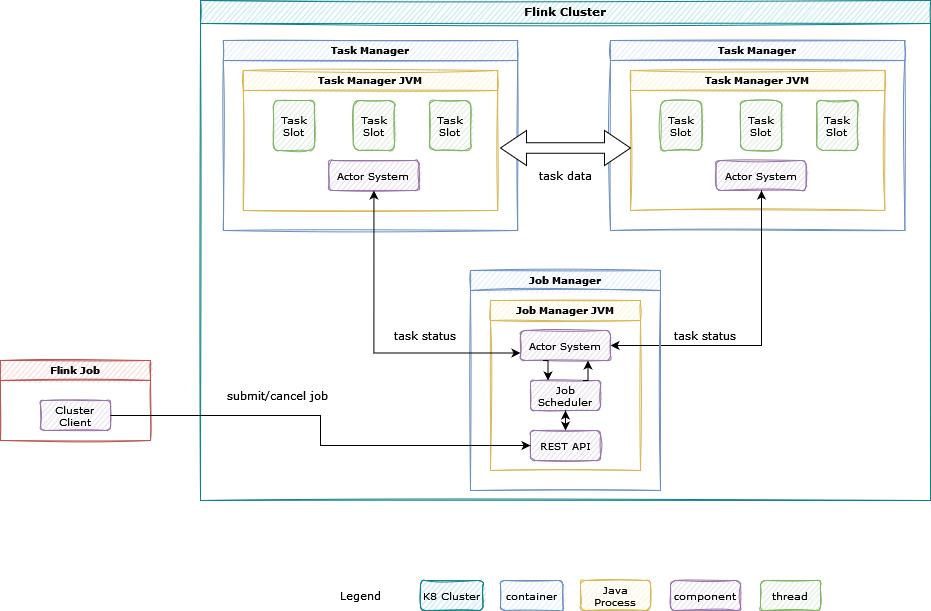
Figure 5: Flink cluster overview
The diagram shows flink cluster components, explained below:
-
Actor system: A component used to manage communication across the cluster.
-
Job manager: Manages the lifecycle and run of Flink jobs, responsible for scheduling jobs across task managers, starting and stopping jobs, and so on. It exposes REST APIs for job management.
-
Task managers: “Workers” that run one or more tasks. A Flink cluster has multiple task managers, and each Flink job that runs on the cluster is spread across available task managers.
-
Task slots: A separate thread with a fixed amount of resources. Every task manager can contain one or many task slots constrained by the number of available resources, such as CPU and memory.
-
Flink job: A Java, Scala, or Python application that creates a sequence of tasks and sends it to job manager for processing.
A Flink job is scheduled via job manager, which fans out tasks to available task managers. A job typically runs on multiple task slots.
Coming back to our connection pool strategy model—Initially our Flink jobs had limited DB interaction, so they all shared a single connection pool inside a task manager. The following diagram shows how this model works inside a single task manager:
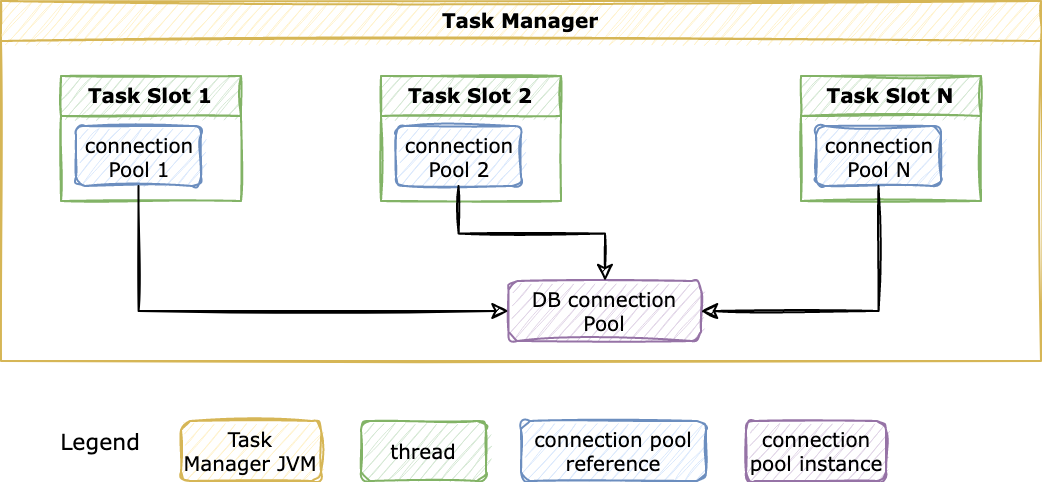
Figure 6: Single connection pool model
The figure shows components inside a single task manager. Other task managers in the cluster are also set up in the same way.
Our single pool model uses a single database connection pool per task manager, shared across all jobs. This model worked until we added new features requiring more database interaction. We thought that a single connection pool across all jobs wouldn’t scale for these features, because having more database interaction meant our jobs competed for database connections.
If each task slot has a different database connection pool, jobs don’t have to compete for database connections. So, we implemented a model where each task slot has its own connection pool. The following figure shows how it works:

Figure 7: One database pool per task slot model
If a task manager has five slots in use, five instances of connection pools exist, regardless of how many Flink applications are running on the cluster.
After testing and a pilot launch to smaller regions, it appeared to work. Based on these results, it was scheduled for broader deployment. Unfortunately, it didn’t work. One of the jobs started failing with the following error we hadn’t seen before:
Caused by: java.sql.SQLRecoverableException: No more data to read from socket
at oracle.jdbc.driver.T4CMAREngineNIO.prepareForUnmarshall(T4CMAREngineNIO.java:782)
at oracle.jdbc.driver.T4CMAREngineNIO.unmarshalUB1(T4CMAREngineNIO.java:427)
at oracle.jdbc.driver.T4C8TTIpro.receive(T4C8TTIpro.java:132)
at oracle.jdbc.driver.T4CConnection.connect(T4CConnection.java:1508)
at oracle.jdbc.driver.T4CConnection.logon(T4CConnection.java:540)
at oracle.jdbc.driver.PhysicalConnection.connect(PhysicalConnection.java:782)
at oracle.jdbc.driver.T4CDriverExtension.getConnection(T4CDriverExtension.java:39)
at oracle.jdbc.driver.OracleDriver.connect(OracleDriver.java:704)Interestingly, the error occurred for any job in the pipeline and only in the large region. Although this deployment worked in several small regions, we decided to roll it back everywhere to avoid staggered deployments.
Solution
We started investigating what caused this by going through logs and metric dashboards. The error was a generic network error and had several known causes like network timeout, inactivity connection timeout, and even incorrect Java Database Connectivity (JDBC) driver version. We knew our JDBC driver version and database version were in sync and eliminated that as an issue. Because the only major thing that we had changed was the connection pool strategy, we started to look into database connection-related metrics.
What we observed only occured in the large region. The Flink cluster was trying to create over 1,000 database connections during job initialization. The database CPU spiked and database throughput had come down. In smaller regions, the number of database connections were between 100–300 and the database CPU and throughput hadn’t significantly changed.
We realized that we had overloaded the database with our new connection pool model. Our connection pool model meant that each task slot got a new pool, which meant far too many database connections in regions using large number of task slots. Clearly, this model wouldn’t scale as it placed too much load on our database in large regions.
We couldn’t go back to the single connection pool model because that model caused contention among jobs. We needed a strategy to avoid database pool contention and reduce the load on the database at the same time.
To avoid the single connection pool model that caused contention or this scalability issue, we implemented a hybrid connection pool model, a single connection pool for each job in task manager. The following image shows this implementation:

Figure 8: Hybrid database connection pool model
In this model, each task slot requests a connection pool from a connection pool factory. The connection pool factory is a singleton class: It creates exactly one instance of a connection pool per Flink job and returns reference to it. This way, if a task manager has 30 slots in use, and we have five Flink applications running inside it, it only uses five connection pool instances.
This hybrid strategy combined the best of the approaches. It eliminated database connection pool contention and reduced load on the database by limiting the number of connection pools.
To create the singleton factory, we moved all our JDBC-related code into a separate jar file and bundled it with a Flink classpath. So, our connection pool factory class only loads once during task manager JVM creation. It also reduced metaspace usage because JDBC-related classes were loaded only once instead of loading separately by each Flink job.
Our team learned a lot during this intense analysis cycle, especially about correlating connection pool metrics to database CPU usage and performance. Having too many database connections puts much more pressure on database CPU, resulting in misleading errors. We need to correlate application usage of database connections with database metrics to correctly analyze these kinds of problems.
Final thoughts
Reliably operating large scale streaming applications running on a shared infrastructure is a challenging task. Issues like orphan threads, memory and database connection leaks hurt application throughput and stability. Visibility in those areas is necessary for identifying issues and figuring out mitigation strategies.
We hope that this article gives you some insight into how to diagnose seemingly unrelated symptoms and fix underlying scale problems. For more examples of how we fix internal issues, see our Behind the Scenes posts.
