A common feature and value of most cloud services is that they strive to present a straightforward and simple view to their customers, while internally a complex dance of background procedures can be acting to keep the service available. However, building a service architecture that can handle these demands at scale can be difficult. In this blog post, I present the journey some of our teams have gone through using control theory and subsumption architecture while building public services in Oracle Cloud Infrastructure (OCI).
OCI offers various kinds of cloud services. Let’s define three broad groups of behavior.
-
Synchronous operations achieve their goals within the lifecycle of the user request, such as uploading or downloading objects from OCI Object Storage.
-
Workflow operations are long-running actions triggered by users which are completed later after sending an initial request, such as launching or deleting virtual machines (VMs) in OCI Compute.
-
Serverless meta behavior driven by the configuration submitted synchronously by a user, such as functions, API gateways, and network load balancers.
Many services mix and match these behaviors. Sometimes, a synchronous API request results in a background workflow that completes when it has configured serverless behaviors.
Workflows
Traditionally, OCI has tended towards building workflow-based APIs, which is common in service-oriented architectures (SOAs) because most services consume a network of internal dependencies to deliver value. The operation can’t always complete safely in line with the request and response because a crash or bug can occur at any time, which leaves the system in a corrupted half state. Figure 1 shows an example of a two-step synchronous request with a crash occurring before the second step can run. The system is left in a partial state, and the actor receives no response because a crash has occurred between steps 1 and 2.

Figure 1: Two-step synchronous request with partial state because of a crash
Most operations that interact with subservices that have side effects run this process in a background workflow. Workflow steps can utilize checkpoints and you can clean them up after the steps run their course. In this way, the system can resume after a crash or failure has occurred between steps. Figure 2 shows the same two-step operation using an asynchronous workflow, which ensures that step 2 runs even if a crash occurs.

Figure 2: Two-step asynchronous workflow that proceeds even when interrupted by a crash
When building API Gateway and Oracle Container Engine for Kubernetes (OKE), our development teams started off with workflow based designs, but they found a series of edge cases around fault tolerance and scalability, which meant that a workflow-based architecture wasn’t suitable. So, we needed some out-of-the-box thinking.
When workflows don’t work
Both API Gateway and OKE services offer serverless behaviors by their nature.
-
API Gateway allows customers to define routine behaviors and security policies for an HTTP API proxy that gets exposed into their virtual cloud network (VCN). The gateway scales with usage and is highly available when hardware or networks fail. Behind the scenes, each customer has a scalable set of containers onto which their API traffic is distributed, but it’s all intentionally hidden from the customer.
-
OKE provides a Kubernetes API server in a customer’s VCN with pools of Kubernetes nodes that can run the customers workloads. Like API Gateway, this functionality is highly available and fault tolerant.
In both services, the customer doesn’t need to act or launch a workflow to respond to a failure or reconfigure each internal replica individually. These services offer behaviors that are continuously applied, and the customer can control the configuration of those behaviors. Several problems made implementing these kinds of continuous behaviors with workflows problematic. If we look at some simplified steps for making a new API gateway available as shown in Figure 3, they look like the following example steps:
-
Validate customer configuration.
-
Find capacity for and launch a web server process for handling the HTTP requests of this customer.
-
Attach the process to a new IP address in the customer’s VCN.
-
Configure the process with the configuration from the customer.
-
Register a DNS record for the IP address.
-
And so on…
This complex multistep workflow for launching a serverless API Gateway appliance gives an example of a workflow with many effects in different dependent services and domains. Two terminal states exist: Active and failed.

Figure 3: Simplified steps of making a new API gateway
We could implement this configuration in a workflow and consider it successful when all steps are complete. If the customer wants to change their configuration, a different workflow can run to perform the updated operation. However, for serverless services, this change raises the following questions:
-
If the underlying hardware fails and affects availability, when does the service notice, and what does it do about it?
-
If we release new features or changes to the service, are all customer resources upgraded in place? Or is it only applied to new workflows?
-
What happens when these scenarios occur in the middle of a customer-initiated workflow?
Some teams attempted to work around this issue by running frequent background workflows that weren’t initiated by customers. These workflows attempted to detect and resolve problems, but they became complex as they attempted to handle arbitrary conditions while not breaking or blocking in-flight workflows by users.
We needed a better way of approaching this problem!
Moving to controllers
We broke away from workflows by reexamining the methods we use for achieving the goals of our customers. We took inspiration from how Kubernetes achieves similar goals with the following steps:
-
Break a monolithic entity into several related objects, each with their own desired configuration.
-
Allow customers to update the configuration of these objects at any time.
-
Write separate controller processes that act on these resources to achieve the wanted states.
-
Dynamically create and delete related objects as the configuration changes.
-
Propagate status up to the parent or owning resources and communicate that to the end user.
Subsumption is the process of breaking down the domain model into a hierarchy of sub-behaviors. In a subsumption architecture, each component implements a small set of behavior and delegates low levels of behavior to other components to achieve its goals. Developers use this method in robotics and control theory to break down complex systems that might have many concurrent behaviors. You can individually test and verify each subcomponent, which can sometimes fail independently of the components above it.
If you’re familiar with Kubernetes, you might recognize the following process in how Kubernetes provisions a deployment resource in its deployment controller:
-
Creating a deployment triggers the creation and modification of replica sets. The deployment becomes ready when the replica sets are in the state you want.
-
Replica sets orchestrate the creation and deletion of individual pods.
-
Pods trigger scheduling behavior and Kubernetes worker nodes run the workloads of their allocated pods.
-
If a pod crashes or becomes unavailable, the replica set replaces it using the same configuration.
This example shows subsumed behavior. The deployment controller doesn’t care how or when Kubernetes creates or updates Pods. It acts only on data returned to it by its underlying replica set objects to provide declarative and fault-tolerant behavior.
You can use the following common ways to build a subsumed architecture:
-
Controllers (as Kubernetes does), where common processes queue up and perform the same actions on all objects of a given type and signal other controllers by changing the state of a resource.
-
Actors (like Erlang or Akka) where each resource or aspect of a resource is a stateful process and receives and sends messages to other processes. Each process defines only its own behavior and may only react to the messages it recognizes.
We chose the first approach using controllers for the following reasons:
-
Familiarity: Many of our developers had worked with and debugged Kubernetes in the past or had written Kubernetes operators.
-
Dependencies: We needed a technique that we could integrate into existing projects without introducing major new external dependencies or frameworks that required an all-or-nothing approach.
-
Simpler: We needed a lower barrier to entry so that new developers approaching these projects in the future didn’t need to become experts in the pattern before contributing.
What’s a controller?
We call each component a controller because it has a control loop at its core. Figure 4 shows the steps of a basic control loop with subscribe, wait, compare, and act. After an action has been taken, the system resumes waiting on the events it subscribed to.

Figure 4: A basic control loop
-
(1) In the Subscribe step, a controller subscribes to changes triggered by the changes to a resource, the passing of time, or some other event.
-
(2) After these triggers occur, the controller compares (3) the wanted state to the actual state and decide on an action (4).
-
When that action has occurred, the controller resumes waiting for triggers on that resource or emit a triggering event itself (2).
In a service like API Gateway, for example, we used a controller that registers a domain name system (DNS) record for each gateway and removes it when it’s no longer needed. This example control loop uses the following steps:
-
Subscribe to changes on any gateway resources that aren’t fully deleted.
-
Compare the internal state to check whether we registered this record already or registered it and are now deleting the gateway.
-
Act by calling an OCI DNS PatchRRSet operation to set or clear the IP addresses.
-
If an exception occurs, inspect the error and decide whether to fail the resource or schedule the item for a retry using exponential backoff if the error can retry.
This controller also conveniently performs this work for any resources that already existed before the system launched the controller. We chose to implement this pattern in Java using multiple threads pulling items from a per-controller DelayQueue with in-memory caches for receiving events.
How we support concurrent coordination between controllers
In the earlier workflow approach, the system expects to run as though it were a single state machine with only one process writing to the resource in the database at a time. Because each workflow has many steps and workflows can interleave concurrently against the same resource, this assumption leads to complex coordination bugs when a workflow enters a state it didn’t define or expect. We found that controllers and subsumption architecture made this issue much easier to think about, because the fragmented domain model means that fewer processes are attempting to inspect or change the same resources. Additionally, each controller only acts in a small set of possible states.
We’ve used the following techniques to reduce our reliance on a single executor and allow many controllers to make progress safely:
-
Enforce read-modify-write behavior on all modifications to the database. Use a database that provides multiversion concurrency control and only accept modifications against the latest version of a row. If a controller attempts a modification using an old version, the controller retries its compare and act steps using the latest copy of the data.
-
Reject any modifications that might put the resource in an invalid state. Many teams write complex API validation logic to prevent a customer creating or updating a resource into an invalid state but don’t apply the same rules to their internal processes. We’ve found it valuable to move these validation rules as close to the database as possible and apply them to all database modifications, whether they’re by customers, internal processes, or human operators.
-
Use concurrency control mechanisms in service to service calls. When we make external API requests, we always persist and use an idempotency token to ensure these calls aren’t performed twice and follow a read-modify-write pattern. This setup protects against two copies of the same controller running the same API call and duplicating the result and against the same controller crashing and retrying.
-
Use leasing and fencing to guard sections that don’t support more lightweight concurrency controls.
If a controller requires a mutual exclusion period, it can use leasing and locks to prevent many copies of the same controller operating on the resource at the same time and making conflicting decisions. This process ensures that risky actions remain safeguarded, while controllers that are responsible for maintaining the availability or liveness can continue to run outside of this exclusion.
Leasing is a mechanism that allows a process to claim a lock for a given amount of time. When claimed, all coordinating processes can’t claim that lock until a consensus that the time has elapsed is reached. If a process holding the lease crashes, the same process applies. We implement this process using a shared database and a system clock.
Fencing is a related mechanism that ensures that actions performed by the earlier lease owner aren’t accepted after this time elapses. This mechanism is valuable in distributed systems because it can prevent unexpected race conditions when actions slow down or take effect out of order.
Figure 5 shows a simple implementation of establishing a mutual exclusion period on a specific resource by tracking revisions of the resource and marking it with a lease. In production, this lease is usually time-based and relinquished automatically if it expires to ensure that the system doesn’t deadlock. Figure 5 provides a timeline between two processes coordinating on some work in a data store. The two processes use versioned leases to establish mutual exclusion periods, so that they don’t work against the leased database row at the same time. Multiversion concurrency control ensures that the two processes can’t overwrite the database row.
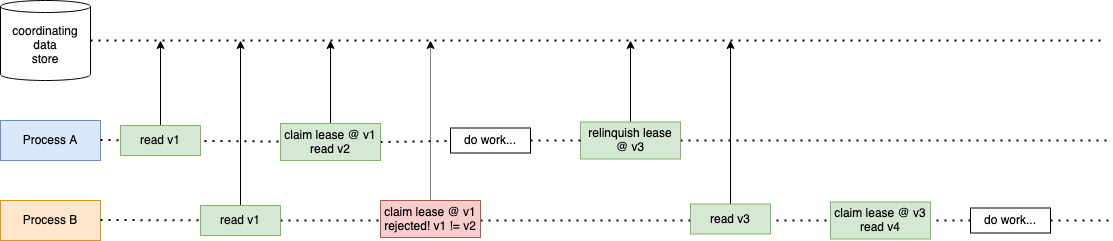
Figure 5: Mutual exclusion with leased database row with multiversion concurrency control.
Reacting rather than polling
You might have noticed that our controllers require an ability to run when their respective resources have changed or when changes have occurred in dependent services. One natural way is to continuously poll or scan the database or downstream API and process every resource that might have changed. In reality, most resources haven’t changed and don’t require any action. It might also take a long time to perform these scans and put unnecessary pressure on the system with no benefit.
So, we put effort into ensuring that we were reacting to events instead and using them to keep a cache of the data accessible to each controller and offload the read pressure from the database. This cache also has the side effect of allowing our controllers to run much faster and more often.
For data-driven events, we use a few techniques together.
-
Scan the database, cache the latest data, and notify controllers for all items.
-
Read a change data capture (CDC) stream from the database, cache the latest data as we see it, and dispatch events to the controllers that care.
-
When writing a row successfully, cache the latest result and dispatch events to the controllers that care.
By following these steps and using the read-modify-write control from before, we seldom need to perform a consistent read against the database and treat our data as eventually consistent.
We also avoid polling downstream services wherever possible. Instead of continuously calling a read operation for each item of the service, we either reverse the communication direction and have the downstream service emit an event that our service can receive, or we retrieve a batch of all items changed since the previous request.
Ideally, controllers only trigger when a resource has changed state (or time has passed).
Pulling it all together
Today, both API Gateway and OKE perform most background workflows and reconciliation using controller patterns. These patterns have proved scalable and maintainable across production environments and have successfully handled and reacted to many large- and small-scale events by driving these services back towards the configuration defined by customers without long-lasting side effects to customer resources. These services continue to scale and grow, and the flexibility of controllers allow these services to continue delivering new features and functionality.
API Gateway now contains 30 controllers, all interacting in various ways. For example, Figure 6 shows some of these interactions. Controllers operate in a network with each subscribing to data store events triggered by the operations of other controllers. Controllers are responsible for individual domains and subsume the behaviors provided by their dependency controllers.
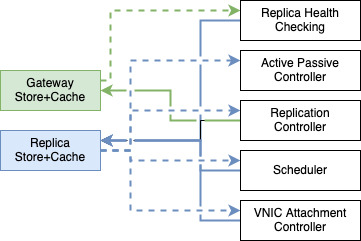
Figure 6: Two domains with behaviors provided by a network of controllers.
We have also identified the following areas that need further investment and care:
-
Diagnostic tooling: Event-based services, especially those that have many concurrent controllers, can be difficult to diagnose when the system has halted or particular control loops aren’t running or are running too frequently. We’ve invested more in diagnostics around controller event lag, successes, failures, and queue depth than we had before using workflows.
-
Testing: Controllers are more complex than state machines and have a higher barrier to entry. They often require developers to hold more of the system in their heads and predict how it reacts to events. Thorough unit testing of controllers is a boon here.
We continue to work on these patterns and iterate on frameworks to guide our developers.
Conclusion
Going down this architectural path has allowed us to build scalable and reactive systems with confidence knowing that we can extend and adapt them over time. The techniques covered have proved successful in solving long-term complex problems as systems grow.
I have the following main takeaways:
-
Writing a well-structured and tested controller feels good! Drastically reduces the risk of contributing new code and behavior to a complex system because the unit of code only runs when needed and performs its job accurately and precisely.
-
Moving concurrency primitives out of the framework and down into the underlying data access layers and protocols makes their behavior universal and reliable. So, the developers only invoke them directly when absolutely required.
-
Prevent the proliferation of polling! Read and write to the database only when necessary and provide APIs for CDC or event consumption.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep-dives as part of this Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
