As an engineer, I’m a reluctant consumer, especially of commodity technology. I enjoy solving constraint problems, so I like to comparison shop. Then, analysis paralysis sets in. I get overwhelmed by the variables and potential tradeoffs. Once I have managed to find a solution that doesn’t get in my way, I’m reluctant to upgrade — with laptops, phones, and cars alike.
As a cloud builder, I become part of that problem. Our customers adopt the cloud for flexibility, agility, and commodify cutting-edge tech. The cloud can provide great operational and financial efficiency, but efficiency requires vigilance. Efficiency should be simple, but it’s not. To provide flexibility, agility, and cutting edge tech, the optimal configuration changes at a frequent, overwhelming pace.
I am reluctant to upgrade my work laptop–while in the interim, we have introduced five new Compute architectures since I got it. These are all big improvements worth consideration. Oracle Cloud Infrastructure (OCI) has benefited from evaluating and adopting them ourselves. But keeping up with changes in the cloud, with fast experimentation and low switching costs, isn’t easy. Software upgrade cycles often fall behind new technology releases, which makes cloud efficiency a gnarly, multi-objective optimization problem.
Benchmarks: A key to efficiency when done right
Solving multi-objective optimization problems requires a valid evaluation function of a reliable measure. Let’s define what we mean by valid evaluation and reliable measure here. A valid evaluation is one that reflects the total effectiveness of a solution. For the cloud, that might be a total cost, incorporating cost to adopt and operate as much as the billing impact, which can be hard to measure. A reliable measure has consistency of capturing performance. The most honest measure of the performance of a configuration is to use your workload. This isn’t always practical or reliable. A workload sensitive to user behavior or time factors doesn’t provide consistency, and we can’t depend on a workload that only sometimes taxes a configuration. Also, sometimes it’s not quick or reasonable to port them to work on every configuration.
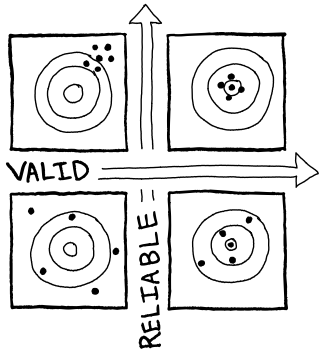
Figure 1: Valid and reliable definition: A valid measurement reflects accuracy of measurements. A reliable measurement gets repeatable observations.
Benchmarks are a common substitute for a reliable and repeatable measurement. Benchmarks run a single test designed for sensitivity to a particular performance property. We run them a bunch of times to characterize the property with statistical certainty. They’re often easy to port, quick to run, and designed to focus on performance, but we must be careful that what the benchmark measures keeps your evaluation valid.
We often work with customers on understanding benchmark results and seeking efficiency. Sometimes they are misapplied and misinterpreted. We want to help. This entry introduces real cloud benchmarking issues we’ll capture in some our Behind the Scenes posts labeled, Under the Bench.
A valid evaluation function of a reliable measure
Returning to the definitions of reliability and validity, in our first cloud benchmarking highlight, Behind the Scenes (Under the Bench): The tricky thing about SMT, Balbir Singh looks at some anomalous sysbench cpu results. The customer was characterizing performance of a new multiCPU instance configuration. They expected the performance to show consistent improvement with more CPUs in use. The instance showed 8 CPUs. They saw improvement for the first four, and then the performance measurement went inconsistent for the next three.
The blog entry from the OCI troubleshooting team explains the anomaly. Figure 2 shows this anomaly in the form of standard deviation from a CPU sysbench benchmark test performed by a customer.
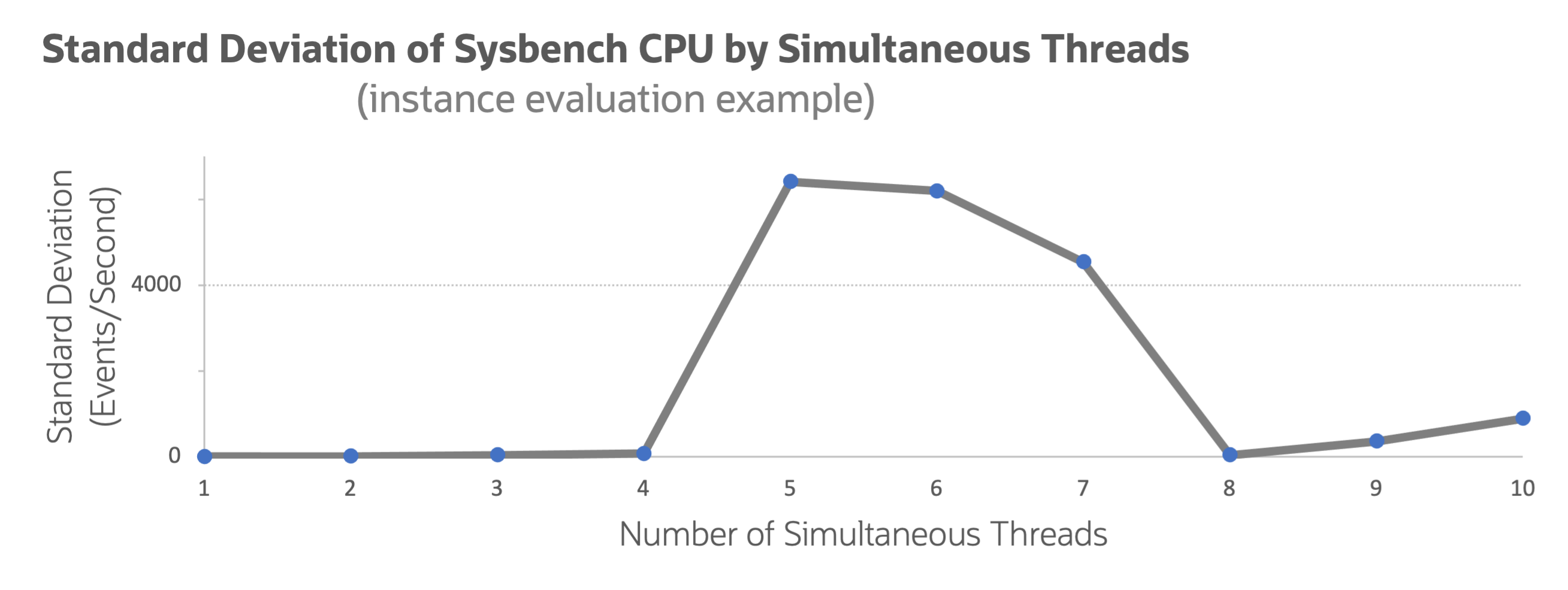
Figure 2: Standard deviation of the sysbench CPU benchmark
A couple observations might come to mind about this graph:
- It looks like Yosemite’s Half Dome, and
- this figure doesn’t chart performance. It shows standard deviation—a mark of consistency.
In any kind of benchmarking, a large standard deviation should be a red flag. It indicates inconsistent, unreliable results. These results might be caused by the benchmark or system under test. From 5–7 CPU, the benchmark quantity isn’t a reliable measure because the standard deviation is close in magnitude to the observation.
The measurement shows three consistency modes: 1–4 CPU, 4–7 CPU, and 8+ CPU. Behind the Scenes (Under the Bench): The tricky thing about SMT walks through the underlying measurement error. You might already be able to guess the cause from this figure alone. The statistical characteristics of your measurements can be as insightful as the results.
Understand your data
Going back to our valid evaluation function of a reliable measure: A benchmark should measure what matters to the observer. If a customer’s workload requires six simultaneous threads to have consistent performance, the four core instance configuration used in this test isn’t the right one. But the customer’s workload might be flexible on the number of simultaneous threads. If so, when testing a four core instance, the evaluation function must account for that configuration. The evaluation function should then consider only the four- or eight-thread results to determine if the CPU performance meets appropriate price-performance objectives.
OCI engineers often observe issues in benchmark testing application that yield inaccurate results. We offer a firehose of new cloud configuration options. The result is a certain unfamiliarity with the underlying technology and details. Do you have to be erudite subject matter experts on all these new features? I hope not!
Instead, I hope that when you see inconsistent results like the ones shown in figure 1, you pause to figure out:
-
Is the measurement reliable?
-
If not, does it still contribute to a valid evaluation?
-
Do you need to learn more about the underlying system or adjust the evaluation criteria?
Better benchmarking and better efficiency
In these Behind the Scenes posts that highlight benchmarking issues, we provide underlying details and more benchmarking theory. The cloud can provide great operational and financial efficiency, but efficiency requires vigilance. Efficiency should be simple, but it’s not. Benchmarking too can be simple and efficient or lead us astray. This series provides real and applicable considerations in benchmarking, so your system configuration is the best it can be. Here’s to better benchmarking and better efficiency with an example in Behind the Scenes (Under the Bench): The tricky thing about SMT.
Behind the Scenes highlights the new projects and challenges OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep-dives as part of this Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
