Before joining Oracle Cloud Infrastructure (OCI), we engaged in various distributed systems projects during a cloud computing course in graduate school or through previous work experiences. Little did we know that these experiences would soon be put to the test in the ever-expanding world of OCI. Being part of OCI for several years, we quickly realized the subtleties of scaling a production service. While building a system may seem straightforward, scaling it up by ten times or hundred times can be intellectually challenging.
As Murphy’s law says, “anything that can go wrong, will,” which holds true for ever-growing distributed systems. This journey underscores the pivotal role of proactive planning and robust strategies in crafting production-ready systems, emphasizing the importance of scalability, fault tolerance, and meticulous monitoring for sustained success in a distributed cloud environment. Drawing from our previous experience with distributed systems, we spearheaded the design and implementation of distributed solutions for OCI’s Secret Management service.
Behind the scenes, the story of OCI Secret Management unfolds with challenges and triumphs. In the early days of OCI, when the customer base was smaller, the secret management service was like a simple puzzle to solve. During this time, designing the application for scale would not only increase the engineering effort and complicate the solution for this simple puzzle, but would also add unnecessary operational overhead for maintaining and diagnosing issues with replication service and shards.
However, with the increase in OCI customers, the usage of secrets exploded exponentially, where our customers would perform thousands of operations per second to store, retrieve, and manage millions of secrets in their digital vaults. All secrets and sensitive metadata are encrypted at rest with KMS HSM backed keys. Imagine the challenge of managing secrets for not just a handful of customers but for hundreds of thousands of customers, each with their unique needs and secrets to protect. It’s like upgrading from guarding a small shop to protecting a bustling marketplace.
What was once easily manageable now required creative solutions to manage the digital secrets of the ever-expanding OCI customers. For us, scaling our service wasn’t just about handling more customers, but also delivering seamless customer experience. In this blog post, we delve into how we transitioned a monolith service into a distributed, replicated, and sharded system that can scale horizontally and achieve over 75% reduction in latency. This shift not only propelled our service’s scalability but also revolutionized our approach to cloud architecture.
Transitioning from monolith to scalability
As seasoned cloud architects at OCI, we’ve witnessed firsthand the transformative power of distributed computing. In early days of OCI, we had a smaller customer base, and our service was implemented as a monolith to avoid engineering complexity. While this setup served us well initially with a small customer base, it soon became apparent that OCI was growing rapidly, and we recognized opportunities for enhancement.
OCI’s culture emphasizes that if we notice something to be fixed, we move quickly but deliberately, continually iterating toward improved solutions. To address the latency issues, scalability bottlenecks and operational headaches with our monolith service, we embarked on a mission to modernize our architecture by focusing on avoiding any single point of failure and horizontally scale our service.
From an engineering perspective, addressing these problems involves a holistic approach. We set out to optimize and evolve our systems to meet growing demand, while ensuring consistent performance and reliability, by following two core tenets:
- Data sharding: Sharding our data across multiple independent shards backed by their own data store. If one shard experiences an issue, it doesn’t lead to a complete loss of availability.
- Local data store replication: On each shard, we replicated data to a local dedicated per-instance data store. This is to have the customer API calls served from the local store avoiding a network hop to the remote data store addressing the latency overhead issue. This process has no read bottlenecks because the local stores are kept consistent by asynchronous replication, eliminating the API throughput constraints. The API availability no longer depends on an external datastore on the critical path.
This resulted in a 75% reduction in the latency of the dataplane API, as illustrated in figure 2.
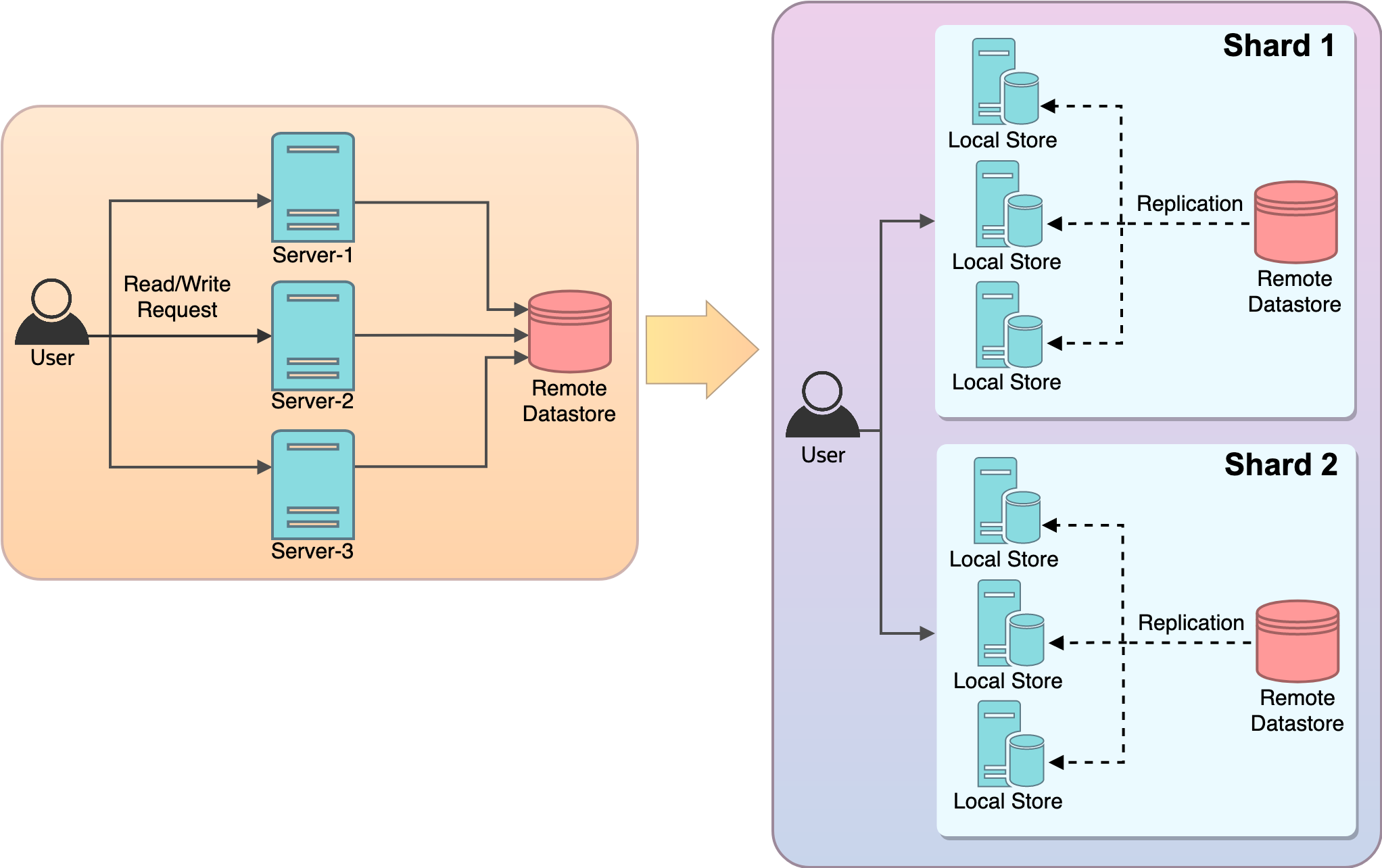
Figure 1: Transforming a monolith service to a scalable service

Figure 2: Dataplane latency improvement metric
For scaling a service, let’s delve into the intricacies of ensuring uninterrupted service availability and data integrity while migrating data from centralized to distributed data stores.
Local data store replication
Local data store replication was essential for addressing the scalability needs of our rapidly expanding service. Serving requests from local data stores required migrating data from our centralized remote data store to on disk stores on each host. This migration wasn’t routine. Millions of data records had to be migrated without compromising the availability of the upstream services. This migration went through a rigorous verification process to ensure customer’s data integrity. For more information on the formal verification process, see the blog post, Behind the Scenes: Sleeping soundly with the help of TLA+.
After migration, data in local data store is kept in sync with remote data store via asynchronous replication. Our replication design was discussed in detail in another blog post.
This migration had the following design goals:
- Ensuring no impact on API responses and availability
- Upholding the sanctity of data consistency during migration
- Avoiding schema discrepancies and maintaining backward compatibility
- Having the ability to rollback at every step in the process
To achieve the design goals, we performed the migration in four phases:
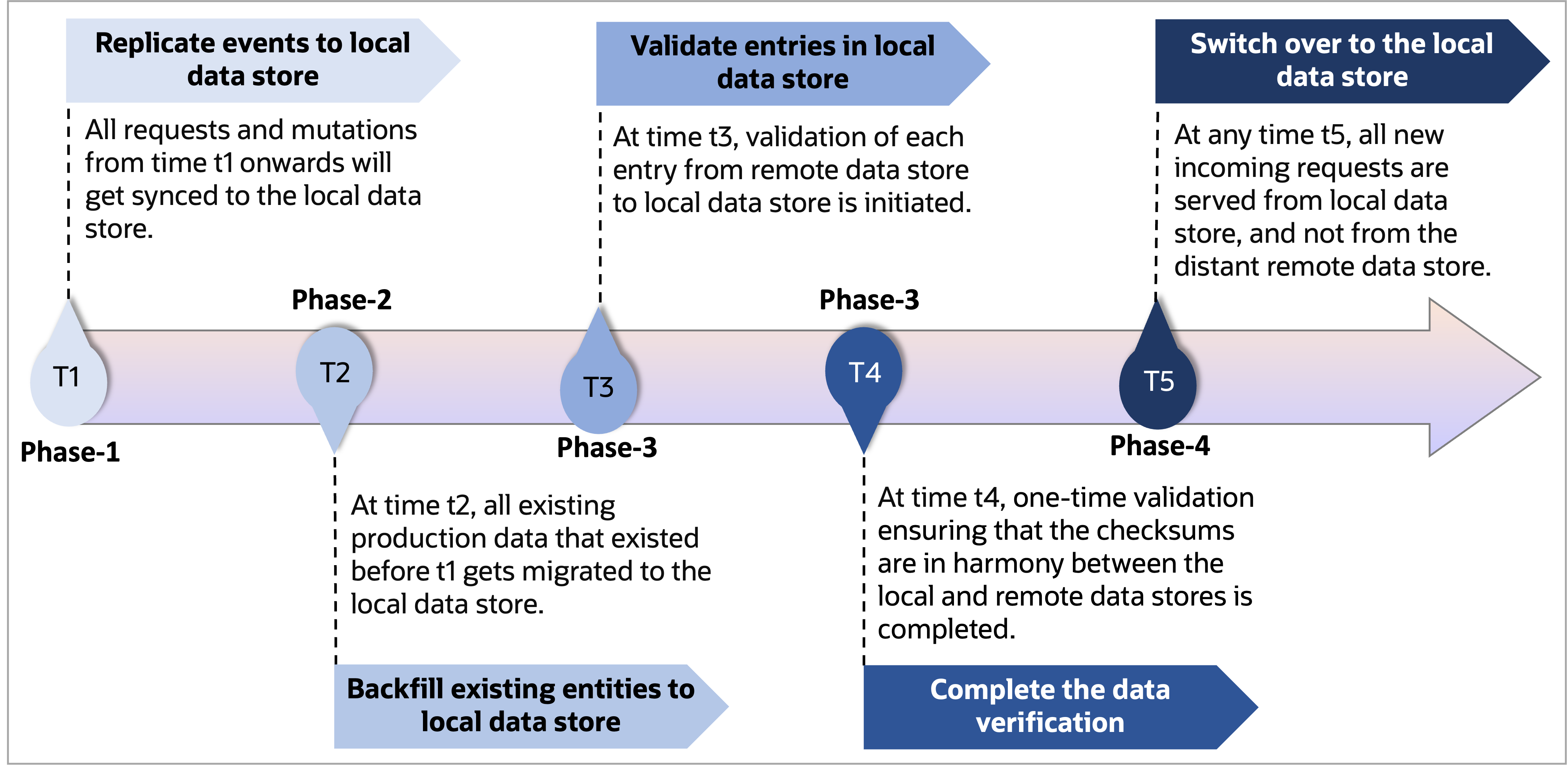
Figure 3: Timeline overview of data migration from remote datastore to local datastore
Phase 1: Sync live mutations to the local data store
In this phase, any live incoming write request became a catalyst for generating replication events. These events are like messengers, carrying the customer resources to their new home in the local data store. Consider, at time t1, the capability to generate replication events was added to our control plane. All requests and mutations from time t1 onwards are synced to the local data store.
This synchronization happens in the following stages:
- Intercepting writes: The replication interceptor’s responsibility is to intercept all mutations, whether it creates, updates, or deletes, or turn them into replication events. Replication events are fundamental building blocks of the synchronization strategy created on the remote datastore.
- Replicating to data plane: Data plane processes replication events and copies it over to local data store.
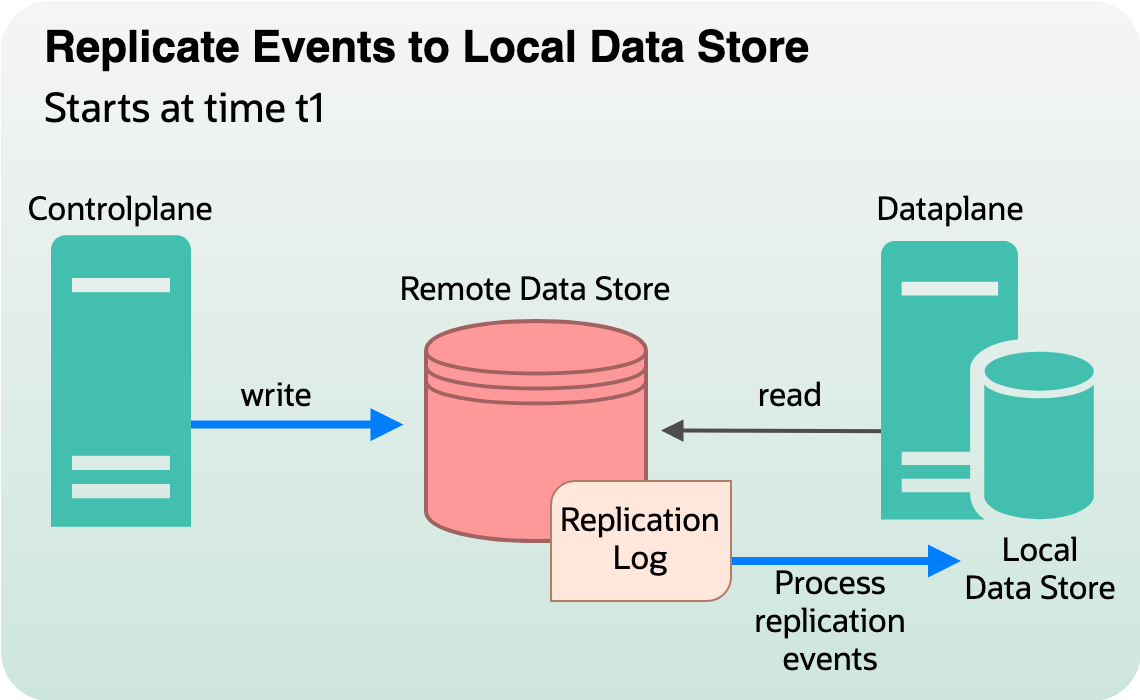
Figure 4: Intercepting writes and replication to data plane local store.
Before we concluded phase 1 successfully, we wanted to ensure that this process didn’t strain our systems with this influx of data.
Validation
To ensure our system could handle the incoming wave of write operations, we subjected it to rigorous stress testing. We needed to understand its resilience under the pressure of peak writes, ensuring that performance never faltered when it mattered most. With the data plane actively polling for data replication, we needed vigilant eyes on resource consumption. Metrics and alarms became our trusted companions, offering insights on CPU, disk, and network I/O. This step was vital for maintaining the system health.
Rollback
As with any endeavor at OCI, we prepared for contingencies to navigate back in time if needed. A rollback mechanism ensures a smooth transition to previous software version that doesn’t intercept writes and clears any traces of partial replication logs.
While implementing this phase, we ran into an interesting issue where traffic interception and mutations in a replication log caused contention at a tenancy level because of optimistic locking. All write requests must perform a transactional append to the replication log, like scanning items for a customer one after another sequentially at a marketplace. It significantly reduced our API throughput and increased internal retries resulting in increased latency. Inspecting the issue further, we discussed to move interception logic to an asynchronous processing path to avoid performance degradation and keep the API call path clear choke points.
Phase 2: Backfill all existing entities from the remote data store to local data store
In phase 2, we aimed to backfill all existing production data (data that existed before time t1) from the remote data store to the local data store. We introduced a backfiller that generates replication events for entities that had mutation timestamps from before the inception of the synchronization endeavor (t1). Any data that has been mutated after t1 or is being mutated while the backfiller gets to that entry is skipped. If migration is enabled at time t2 (> t1) and runs for x duration, by time t2 + x, all the entries should end up in local data store.
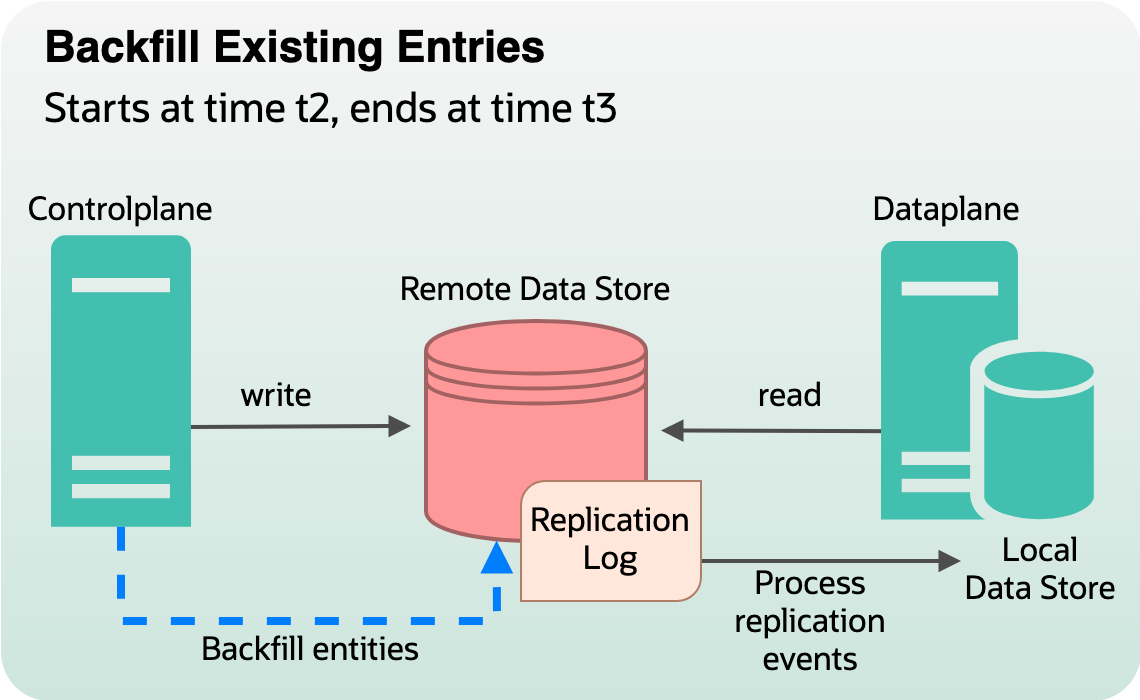
Figure 5: Backfilling existing data
Validation
Validation remained a cornerstone, building on the principles established in phase 1. Rate limiting the backfiller became a necessity to avoid overwhelming the backend data store. Having metrics and alarms around host metrics and backend data store call patterns is helpful.
Rollback
Rollback mechanisms to rewind to phase 1 was in place to deploy previous software version that stops the backfilling.
During backfiller testing, we ran into an issue with the backfiller overwhelming backend remote data store that resulted in high API latency and failures. The backfiller was competing with customers’ API requests for the data store bandwidth. Here, we applied rate limiting on backfiller to ensure that customer APIs aren’t impacted, especially when a surge in incoming traffic happens. This process is analogous to not impacting customers in a marketplace while replenishing the inventory.
Phase 3: Verification of data in local data store
When the backfilling was complete, verification of data in the local data store commenced. This phase was all about double-checking, ensuring that every entry in the remote data store had successfully made its journey to the local datastore. Consider, t3 is when we mark completion for phase 2. At time t3, we start a daemon to validate each entry from remote data store to that in local data store, ensuring that any entry in remote data store is eventually available for reading from local data store.
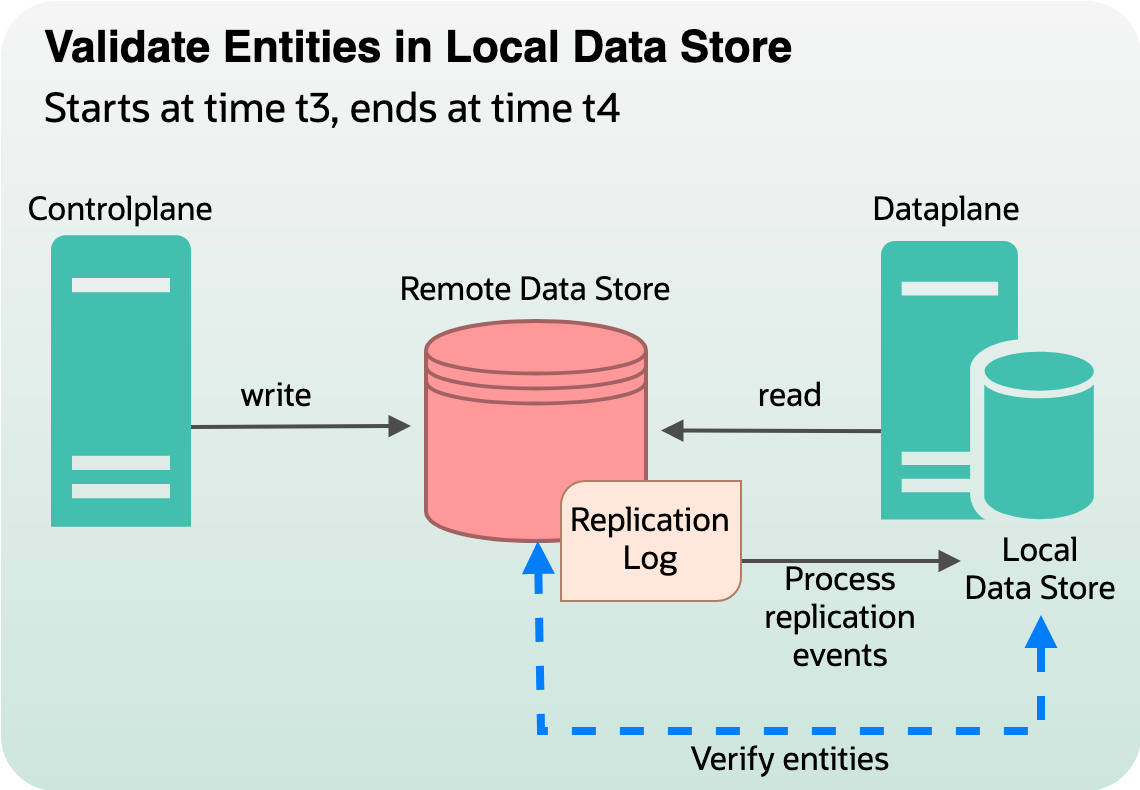
Figure 6: Validation and verification
Validation
We performed a one-time validation ensuring that the checksums were in harmony between the local and remote data stores. This validation helped fix any bit flips during backfilling. Additionally, a live verifier that shadows the API calls by comparing the checksum from local data store and emit a metric on any discrepancies with remote data store. Absence of this metric proves successful validation of this phase.
Rollback
Rollback mechanisms was in place to deploy previous software version that stops the validation and live verification and takes us back to phase 2. If successful completion of this phase happens at time t4, the data plane is ready for final switchover.
This step was all about building confidence that the final switchover to data store would work seamlessly. However, this process wasn’t smooth either! We identified a few inconsistencies due to race conditions, especially in our busiest regions, during this phase. Each time we had to retry the verifier over millions of records, we lost a lot of time. Imagine you get interrupted while tallying the stock inventory. How difficult it is to start all over again? In retrospect, avoiding local states for long running jobs and implementing proper bookmarking to eliminate duplicate processing of records was a key learning.
Phase 4: Switchover to the local data store
In this phase, configuration changes are made to flip the requests to be served from local data store instead of remote data store. At any time t5 (> t4), all new incoming dataplane requests are served from local data store and not from the distant remote data store. This step involves hybrid accessor switching to use a local store accessor, serving traffic from local data store.
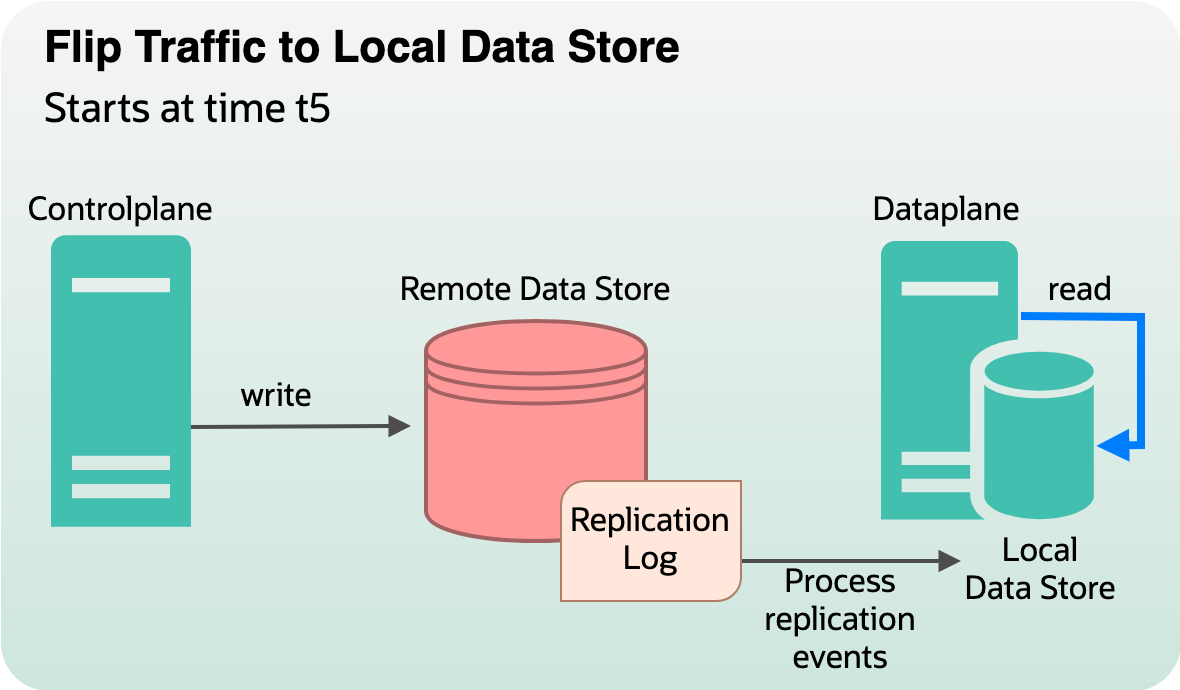
Figure 7: Switching traffic to local data store
Validation
To ensure the transition was seamless and devoid of disruptions, the testing traffic was gradually redirected to the local datastore, monitoring metrics around API latency and faults.
Rollback
A quick rollback plan for stability was in place to revert the configuration to serve traffic from remote data store so that API calls are immediately routed to remote store. At the first sign of trouble, we could easily rollback to phase 3 by deploying previous software version.
Your customers use your service in the ways you don’t expect them to. During this phase, we discovered a few customers using unideal call patterns to our services, such as trying to access a secret before it’s marked as active. A secret is marked active only if it’s replicated to all the backend hosts. We prevented any major outages for these customers by introducing a fallback mechanism to the remote data store. We also had metrics around this issue to catch the outliers. The key lesson is to have a contingency plan, recovery mechanism, and visibility built into the design for any major architecture changes.
Scaling through data sharding
Another most painful scaling bottleneck is the noisy neighbor problem. This issue hadn’t been a problem during early days of OCI because our traffic pattern was predictable. But as the customer base started growing, we wanted to avoid our large customers with bursty workloads to interfere with other customers’ requests. So, customer-specific throttling and service-wide throttling protected all our downstream dependencies and avoided a total brown out.
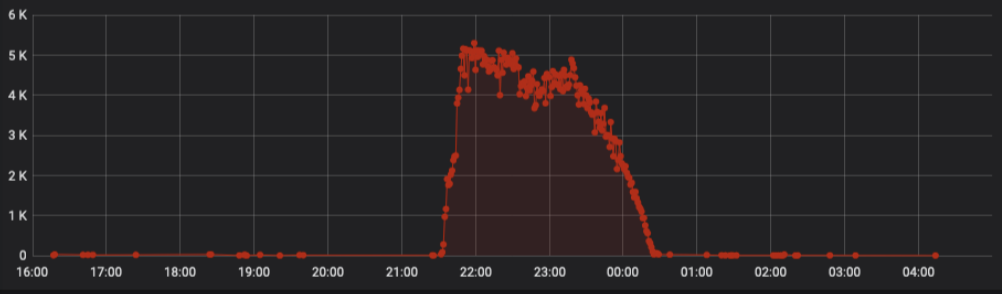
Figure 8: Control plane request spikes from a customer for a single API
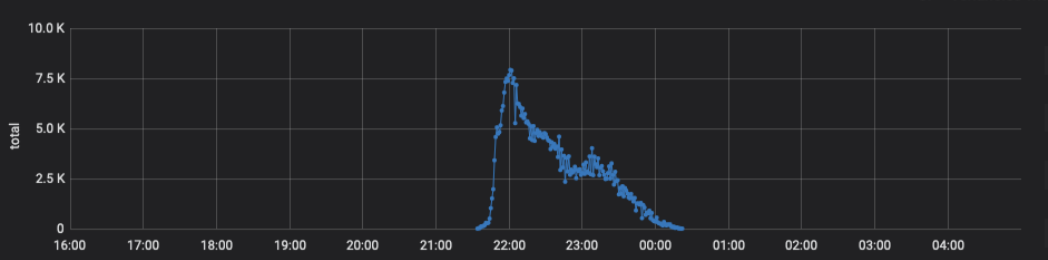
Figure 9: Throttling kicks in to protect the service
The downside of this solution was that it resulted in increased APIs, resource state transition latency, and in some cases, failures to our customers for an extended period. To solve this problem, we introduced independent shards with their own data stores. This new architecture drastically enhanced the overall service throughput as we scale horizontally adding more shards. The following diagrams illustrate the architecture before and after sharding:
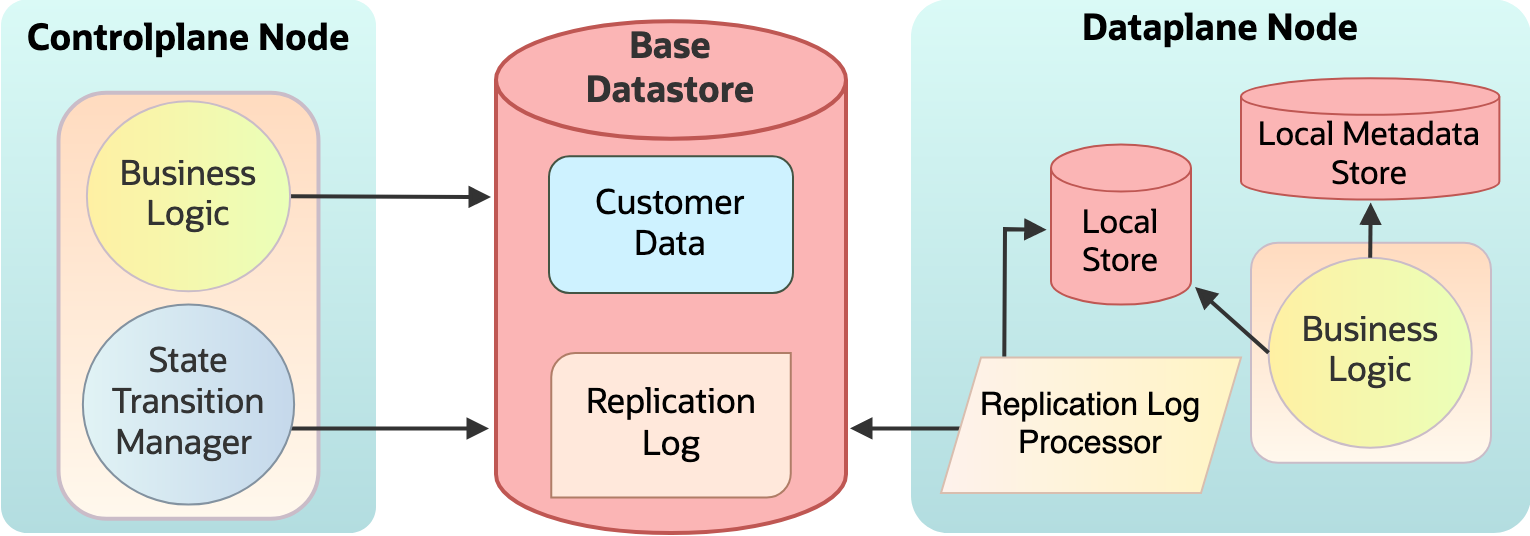
Figure 10: Before sharding: Replicated monolith service
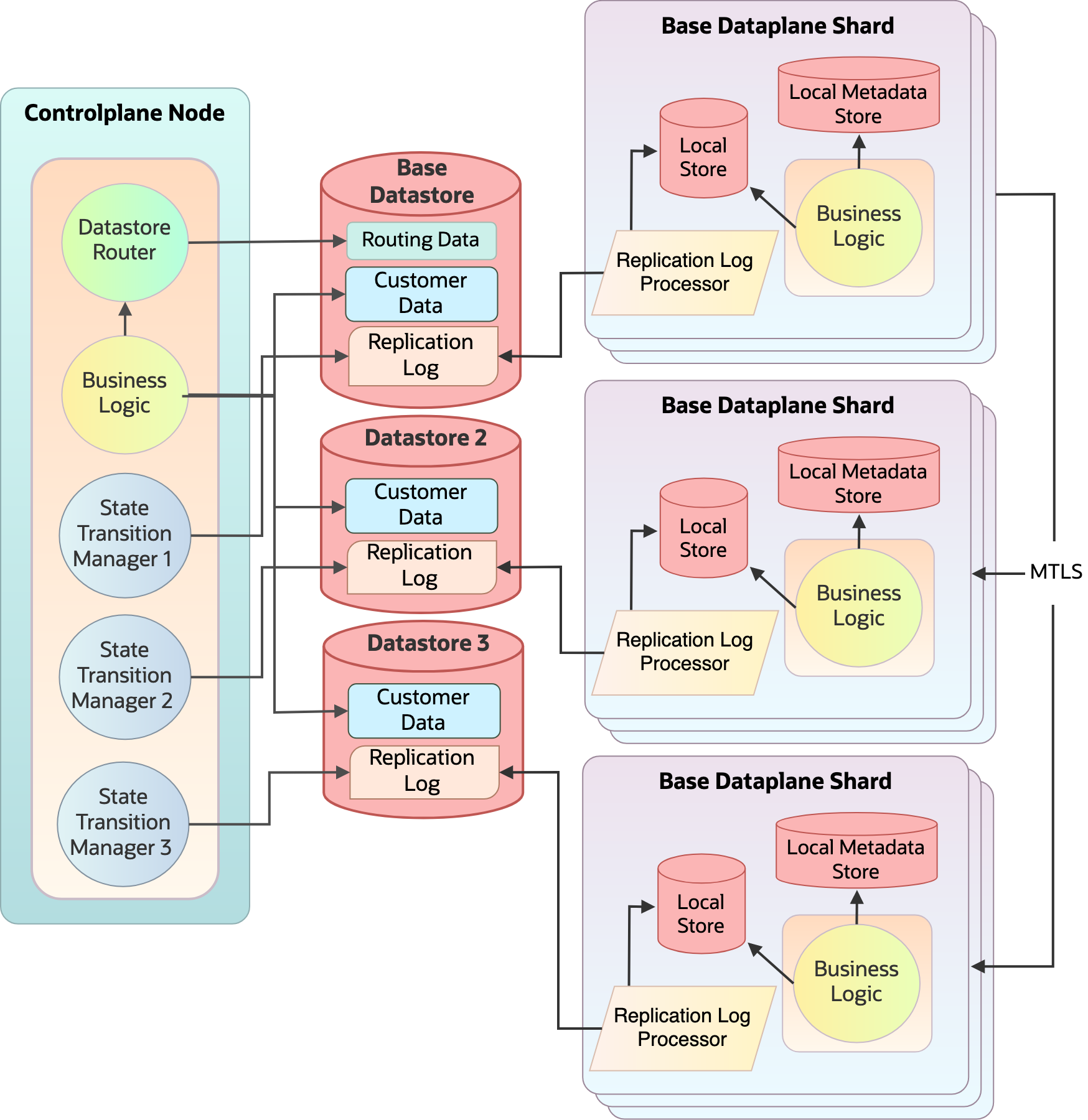
Figure 11: After sharding: Replicated and sharded
Customers’ data is created in a logical container called a vault. A customer can create multiple vaults and the data stored in these vaults are exclusive to that vault. The customer data is sharded by their vault that contains their data. We’ve implemented sharding by introducing a routing layer on top of existing data access logic that routes reads and writes to the appropriate data store using routing metadata.r
Routing metadata is created when a customer resource is created based on the vault it’s associated with. We have a base data store (base shard) and more stores one for each shard. Routing metadata is kept on the base datastore. On the dataplane side, independent cells each have their own local store containing data belonging to that shard.
Routing data
Mapping the request principal’s tenancy to the data store is the easiest way to route the transactions. However, it doesn’t work with cross-tenancy or on-behalf-of requests where the requesting tenancy might not be the owner of the resource. So, we had to find another mapping criteria. We maintain the following mapping info in the base data store:
- Tenancy OCID to datastore
- Vault OCID to datastore
- Resource OCID to vault OCID.
Depending on the incoming request type, corresponding mapping info is used to place or access the data on the right shard.
Enabling the data store router
One of our goals is to add dedicated data stores without service interruption. To achieve this goal, we need to ensure that the routing info is replicated to all data plane hosts in the base cell. We piggyback on our existing data replication to replicate the routing information across all hosts. This step helps maintain the invariant of avoiding remote datastore bottlenecks on our data plane API path. A separate data plane cell with its own hosts, load balancers, DNS, and other dependent resources is created for every shard.
To be backward-compatible with existing clients, we introduced the routing in the base dataplane cell. All the incoming dataplane requests go through the base cell and are proxied over to other cells through mutual transport layer security (MTLS). This design has a better data isolation property for disaster recovery and reduced blast radius. In the future, we plan to replicate routing information to all the shards for serving API requests.
Production readiness
Nailing the design and implementation is one of key thing but having everything rolled out to production is a whole other story. Before these changes hit our production regions, we had to collect empirical data around the following areas:
- Performance characteristics by doing a series of load and stress tests to understand our newer bottlenecks, latent issues around slow resource leaks (memory and file descriptors), memory, disk, and CPU usage patterns, various upper bounds and points of throughput, and latency degradations under stress.
- Failure behavior by doing chaos-testing to emulate various scenarios around a single host to full fleet failures, dependency failures, bootstrap circular dependency checks, data loss and disaster recovery from backups to understand time to recovery (TTR), and identify gaps in our metrics and alarming.
- Steady state behavior with canaries running continuously to gather data around throughput, latency, host metrics, and dependency call patterns.
- Backwards compatibility by performing roll forward and rollback testing of our deployments to ensure that changes are safe to roll out, especially when the fleet has inconsistent software versions during rollout.
Conclusion
Security services at OCI are growing rapidly. We constantly invest in evolving our systems to scale for our customers’ needs. Scaling OCI Secret Management is one such example. It demonstrates the engineering and operational rigor with which we operate foundational services at Oracle Cloud Infrastructure to offer our customers highest form of security, resilience, and performance.
Here are the key takeaways:
- Scaling systems isn’t a one-day task. In the cloud, it’s a phased journey from planning to results. We build, adapt, improve, and retrofit according to customer needs.
- Successful live data migrations need meticulous planning, testing, and execution with rollback capability to ensure seamless transition and minimize disruptions.
- While nailing the design and implementation is crucial, careful rollout and vigilant monitoring is the key to success in deploying features for complex systems.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
For more information, see the following resources:


