In the Oracle Cloud Infrastructure (OCI) Threat Intelligence Center we leverage internal signals like logs, telemetry, metadata and more to generate intel and produce critical security insights. We deliver these insights to security investigators as well as Oracle business and technical leaders so action can be taken. The OCI Threat Intelligence Center is OCI’s threat research security group that keeps the pulse of all threats that could affect OCI and its customers, and provides actionable intelligence about them.
In this blog, we don’t get into the fine granularity of our processes for intel collection and analysis. Rather, it’s about our team’s unrelenting focus on addressing small issues that get bigger and more problematic at scale. Surprisingly, small inefficiencies in log processing can blow up to create large, unexpected inefficiencies at cloud scale. In this instance, we talk about a seemingly humble colon character “:” in file names that prevent timely and effective threat investigations at-scale.
Reading this blog, you gain insight into how Oracle investigators leverage OCI DataFlows, OCI’s ephemeral serverless Apache Spark™ solution which can read/write data from/to OCI Object storage for expedient log analysis. While the techniques used in threat intelligence investigations are intriguing, log analysis is a common basis to many applications. When someone says, “Digital Forensics and Incident Response,” (DFIR), under the cover they mean, “log analysis.” This tiny colon “:” character can cause distraction when you’re an investigator simply trying to complete an investigation. To address the colon problem with log analysis, OCI now has a solution adapted from the method blogged about by Totango labs. Our goal is to lend readers a hand in increasing their cloud efficiency through more efficient log analysis at high scale.
Making big data smaller
Logs are often the exhaust from applications made for developers to debug service issues. Even if you’ve gone through the trouble in centralizing them, they might only contain bits of information immediately relevant to your task. Security is a priority for companies, but you can’t escape the financial realities that compel security teams to operate in a cost-effective manner. Security leaders often face the issue of balancing budgetary constraints while not infringing on investigators’ capabilities. If your company is already operating at hyperscale but your teams are struggling when faced with the challenge of maintaining effective visibility over it all, then you make that scale work for your benefit.
The high level flow in Figure 1 shows what we’re trying to accomplish: taking our large data set of raw logs and processing it enough to cut it down to a smaller volume, making it a more usable subset of relevant information. With the exponential growth of log data in the past decade, we’ve seen a greater push for efficiency around log storage and use. The adoption of LogSlash by FoxIO and Uber’s CLP, demonstrate the industry’s hunger for more efficiency by reducing log volume and increasing usability and are both approaches we recommend checking out.
A method many solutions use is log aggregation, such as the “group by” function present in most data manipulation languages. It facilitates granular control over what information is lost at the expense of overall volume reduction. Even within our own security team, generating aggregated data has played a role in cutting down latency and processing costs. Where theory meets practice is often the sticking point. Too much aggregation, and you lose fidelity. Too little, and you lose your budget.
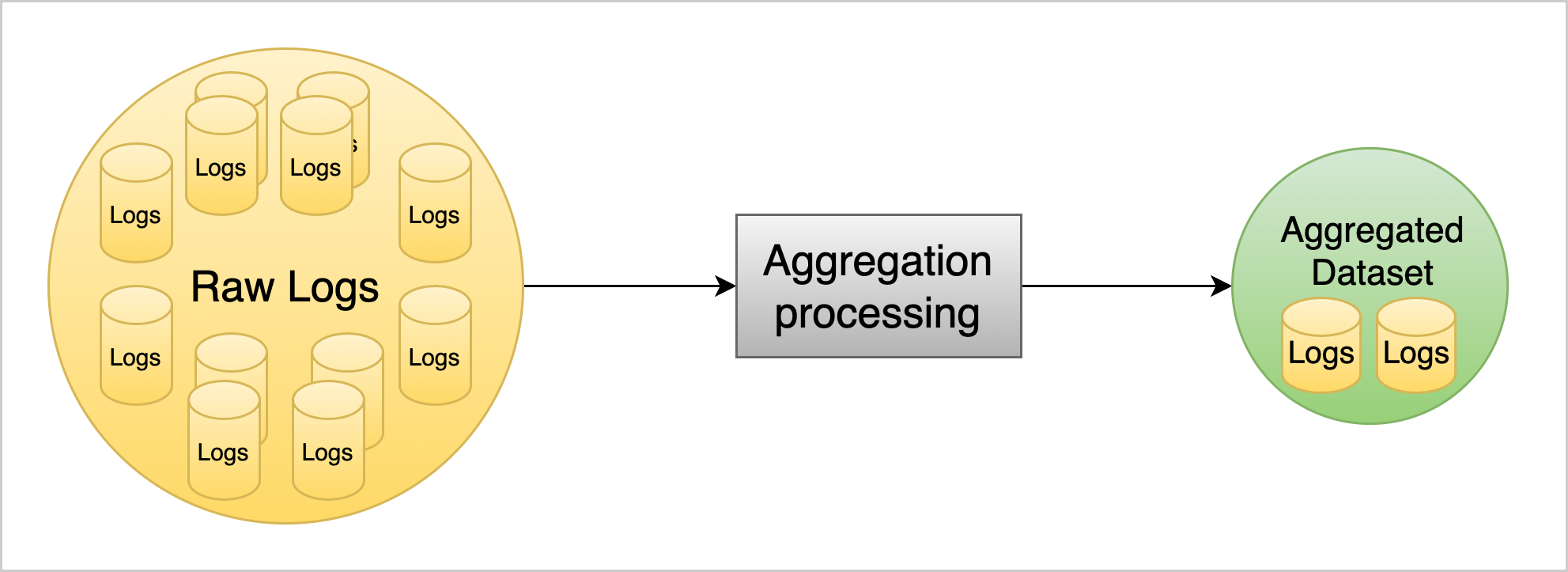
Figure 1: Raw logs are processed and converted into an aggregated dataset lowering the volume of data
Next, we discuss an OCI-made method that balances fidelity with cost.
OCI Data Flow to the rescue
The Threat Intelligence Center team selected Data Flow with Object Storage because it was the most efficient solution that scales and minimizes operational overhead. Data Flow runs Apache Spark™ in an ephemeral manner, meaning you only pay for when it’s running. You can keep the compressed data and the uncompressed reduced dataset in Object Storage where it’s cheap. Because it’s in Object Storage, you can configure automated lifecycle or retention policies to suit your needs. You can also keep data within the region it already existed in, which can help you adhere to and address compliance and data sovereignty concerns.
While you can tailor the OCI process we cover in this article to suit any log type, our security team works with OCI Audit logs. If you aren’t aware of what OCI audit logs are, you can find out more about the contents of Audit event logs or how they can be used for observability over your OCI tenancy resources.
By default, OCI Audit logs are stored for 365 days, but you can change the retention settings. You can use the Oracle Service Connector Hub to offload logs to the destination of your choosing, such as OCI Object Storage. OCI also offers you the ability to bulk export logs, where they’re added to buckets in your tenancy.
For our example, as shown in figure 2, we start by running the OCI Data Flow application in a single region with the logs spread out over multiple different tenancies across multiple Object Storage buckets. Both OCI Object Storage buckets and the OCI Data Flow applications are regional resources, meaning a data flow or Object Storage bucket with the same name in a different OCI region is a different entity.
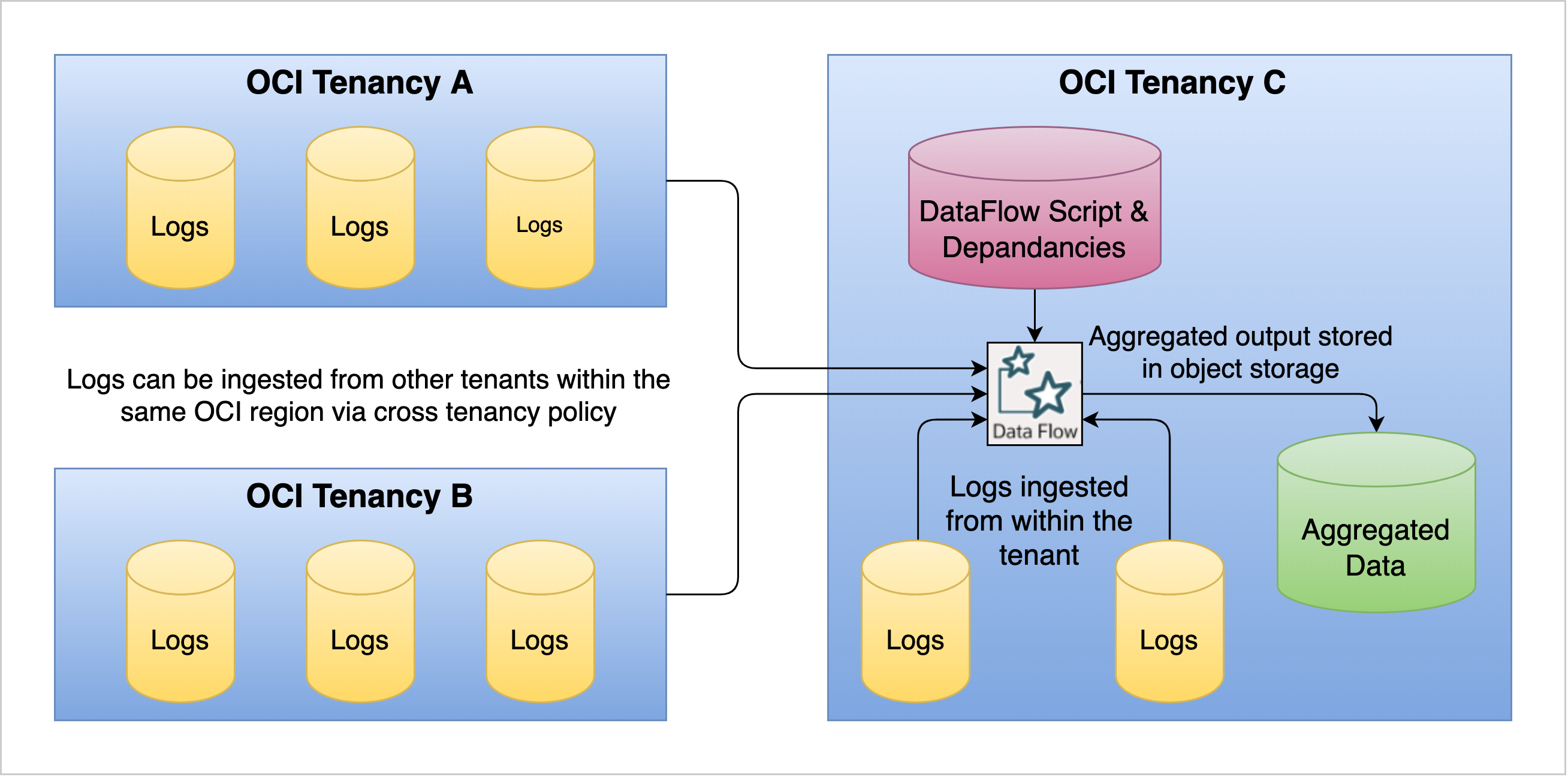
Figure 2: Three OCI tenancies with multiple buckets of logs in Object Storage are processed using OCI Data Flow.
Before we get into the Data Flow pipeline, let’s discuss the colon problem, one you’re likely to run into during this process.
Addressing the colon problem
When working with Apache Spark™ and cloud Object Storage solutions, you almost definitely must deal with colon characters. Colon characters often appear in log file name formats, specifically in time stamps, such as HH:MM. The Hadoop file system (HDFS), which Apache Spark™ uses, considers colons an invalid character. This consideration conflicts with OCI and other Object Storage systems that recognize colons as just another character. This issue can be challenging when working with Apache Spark and has been an issue that people have brought up. Both the Apache Spark™ and Hadoop teams have received the following tickets about it:
- Spark cannot load files with COLON(:) char if not specified full path
- Object Storage: support colon in object path
- Path should support colon
- fs.Globber breaks on colon in filename; doesn’t use Path’s handling for colons
- Path should handle all characters
As mentioned previously, the typical go-to solution is creating a filesystem override class as outlined in the Totango labs example. We ported the solution to work in an OCI context with colons and wildcards using the OCI ColonFileSystem class. A demonstration of this approach in action can be seen in our demo PySpark script. More details about the code can be found in our Github repo for this blog otic-blog-colon-dataflows. Our team reached out to the OCI Big Data for help on implementation, which is one of the benefits of working in Oracle. Experts are often willing and able to come to your aid.
This solution overrides the default filesystem class of the OCI HDFS connector to now accept wild cards and colons. Built and included in the archive.zip, you can refer to it in the following PySpark script:
spark._jsc.hadoopConfiguration().set('fs.oci.impl', 'com.oracle.bmc.hdfs.ColonFilesystem')
Other options to address colon problems
If you’ve read the previous section and may think that the whole “colon filesystem class dependency” thing is a lot of work, but you still want to use OCI DataFlows, we evaluated some alternative options:
- Get the log producer to change the name format and remove the colon character at source.
- Use the OCI Object Storage rename API operation: Great if you have read-write permissions to the bucket and the object count is small.
- Use the OCI Object Storage copy object API operation and edit file name to remove the colon character.
- Copy the logs using a Compute instance and edit the name before reuploading to OCI Object Storage.
- Use another solution that copies and tweaks the file name to remove the colon character.
While these options sound simple, they might not be practical for various issues like permissions, and some get worse with scale. Performing operations on millions or billions of objects is going to run up a lot of API, compute, and storage costs.
Changing the log name format is clearly the best way to negate having to do any workarounds on a continuous basis, but it’s not always an option and might have knock-on effects for systems consuming logs. It also might not be possible if you don’t control the source of the logs. Even if you accomplish a change in log name formatting, you still must change the name of previously written objects at least once. Hence, we do not recommend these options in production, however, they are good options for your initial development at low scale where cost/ efficiency is not a concern.
Creating the OCI Data Flow application
OCI Data Flow is an ephemeral serverless Apache Spark™ service that saves you the trouble of building and maintaining your own Apache Spark™ cluster. It can scale to your performance requirements, easily read in logs from one Object Storage bucket, and output the results back to another Object Storage bucket. If you’ve never run an OCI Data Flow job before, follow to the OCI Data Flow guide, which can help you set up all the required policies. We also have some sample Data Flow scripts to help you.
Data flows consist of an application and run entities. The application is the high-level static entity where the configuration is made, while runs are the individual job submissions for that application. To create your own, navigate to Data Flow in the Oracle Cloud Console and select Create Application to open the creation window. You have different options of Data Flow runs, including batch jobs, streaming, and sessions. In our example, we’re running a batch job, so you can leave the streaming checkbox unselected.
Under the resource configuration for your data flow, you can select the driver and executor shapes for OCI Data Flows, which vary depending on your tenancy. For more information about service limits, see Service Limits. OCI supports the use of different shape types, including x86, ARM shapes, and flexible shapes, where you can select the OCPUs and memory levels. For guidance on how to optimize your data flow size, see Sizing the Data Flow Application.
While you can write Spark scripts in various languages, such as Scala and Java, we’re using the Python3 version, PySpark. It takes a start and end dates as arguments, which pass into the Data Flow run submission. You can also enable your script to include all the data in the bucket. The script combines multiple objects into a single Spark dataframe.
For this script to work, you also need to package the OCI HDFS filesystem class override dependency. OCI provides a general guide on packaging dependencies. After packaging, the dependencies are bundled in a single archive.zip file, which you can upload to an Object Storage bucket and the path referenced in the spark-submit options or in the “Archive URI” text box of the Data Flow application seen in figure 3.
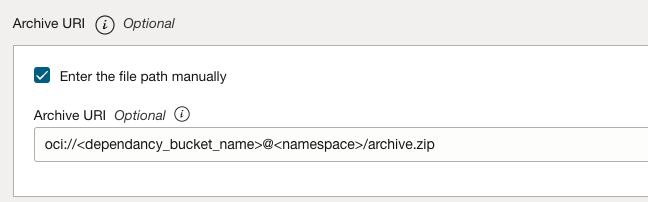
Figure 3: Specifying the path to the archive.zip dependency
Toward a total solution
After you run the Data Flow application and have the aggregated results, the options are limitless. Not only has our security team reaped the benefits of this optimized aggregation solution, multiple teams across OCI have used it to simplify their log analysis and save processing costs and latency. If you want to build a fully OCI native solution, Oracle offers a range of solutions, such as the OCI log search functionality or enabling you to build a data lake with a suite of data science tools. One solution that we recommend is loading the resulting output directly into an Autonomous Database instance. You can perform this task using the DBMS_CLOUD package because the data is already in Object Storage. For more information, see the processes described in Creating and managing Partitioned External Tables just got simple or Simple Export-Import using DBMS_CLOUD and Data Studio’s Data Load Tool. For more complex use cases where you want to use Autonomous Database, we advise using the OCI PLSQL SDK, This method allows you to trigger subsequent OCI Data Flow runs from the database as part of your data processing workflow.
Another benefit of using Autonomous Database is the ease of building an application to present your data in using Oracle Application Express (APEX). APEX allows you to build custom tools around your now reduced datasets and quickly get them into the hands of people who need them, even if they’re not familiar with SQL. Using APEX democratizes access to your data because the low-code environment allows team members not specializing in UI development to build web apps. Figure 4 takes the earlier architecture of data spread across multiple tenancies and demonstrates how you can build on to your solution, easing customer access to your data products.
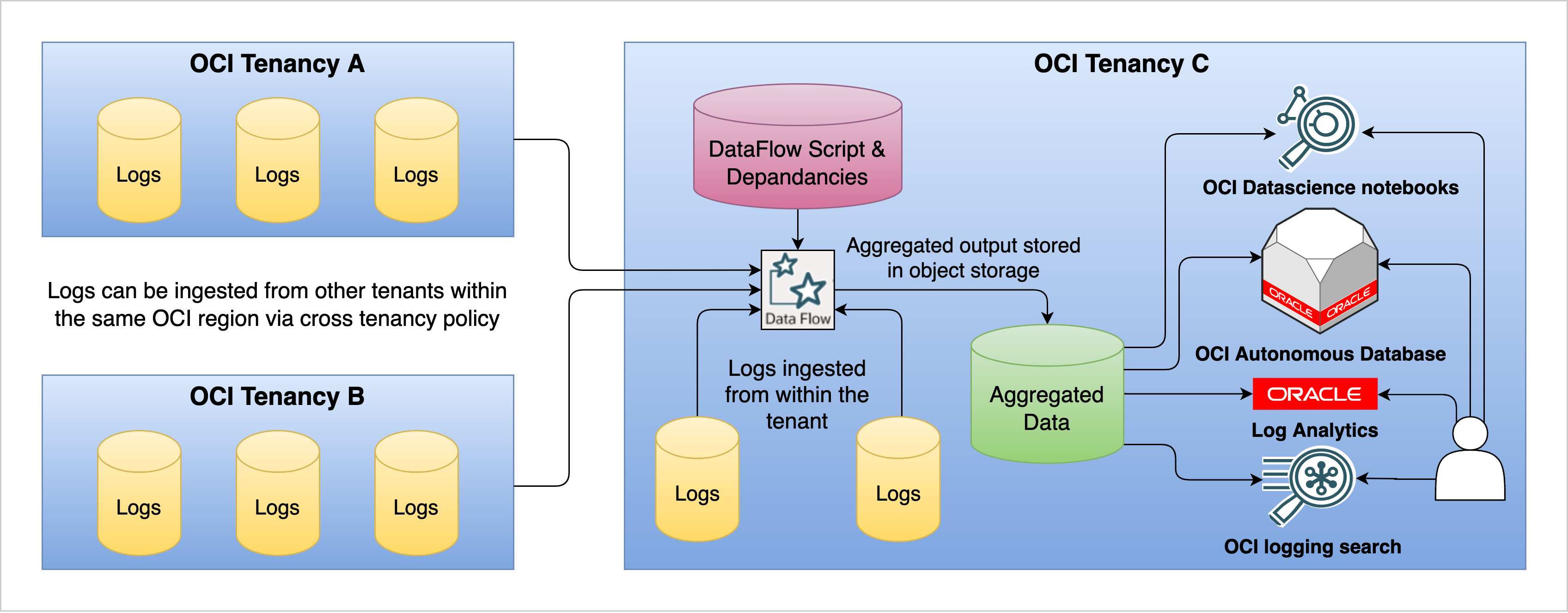
Figure 4: End-to-end architecture of a data pipeline using OCI Data Flow
Worth the effort
The processes that this post touched on have led to many successful outcomes for Oracle’s security investigations and kept up with the pace and scale of the cloud. The benefits of OCI Data Flow go beyond the security space because you can apply these methods to any type of data analysis for whatever purpose. Consider the following key outcomes:
- Observed volume reduction of 99.997% while keeping the fidelity we needed for the investigation we were working on.
- Awe-inspiring scale for single OCI Data Flow runs. In one example, a data flow primed with sufficient resources ingested more than 20 TBs of compressed logs and output 15 GB of aggregated data.
- While not covered in this post, OCI Data Flow streaming and sessions allow even more flexibility when you want to work with data closer to real time, not in batches.
- In some cases, we find that it helps to remove noise that otherwise obscures the key lead to drive the investigation to a close.
Conclusion
Small problems become bigger quickly in the hyper scale cloud environment. The OCI Threat Intelligence Center team drastically reduced log data, still ensuring the relevant log attributes necessary for not just current but also future investigations. In the process of doing this, a challenge with colon in file names at cloud hyper scale had unexpectedly large impact to business operations. Solving this challenge enabled the OCI Threat Intelligence Center team to reduce costs, and increase the scope of security investigations. One of the benefits of working in Oracle is that you can work with a wide array of experts to troubleshoot and solve even the most seemingly minor of issues in a wide array of technologies.
Thanks to the OCI Data Flow team for creating OCI Data Flow and Carter Shanklin for creating the ColonFileSystem class. Thanks also to everyone in the OCI Threat Intelligence Center team, especially to Ryan Schilcher, Chris Baker, Yashashvi Dave, and Jon Taimanglo on the Signals Engineering team, who helped with this post.
This blog series highlights the new projects, challenges, and problem-solving OCI engineers are facing in the journey to deliver superior cloud products. You can find similar OCI engineering deep dives as part of Behind the Scenes with OCI Engineering series, featuring talented engineers working across Oracle Cloud Infrastructure.
